基于深度学习的嵌入式汽车内饰件装配检测①
2022-05-10王鸿亮
谭 任,唐 忠,王鸿亮,王 帅
1(沈阳化工大学 计算机科学与技术学院,沈阳 110027)
2(中国科学院大学,北京 100049)
3(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 绪论
随着信息技术不断发展,将传统制造与信息技术相结合而形成的智能制造更是取得突飞猛进的成绩,在全球范围内逐渐成为制造业发展趋势.第四次工业革命到来,智能制造站上风口,由此而衍生出新的生产方式,产业形态,商业模式.我国提出《中国制造2025》规划,把智能制造放在了主体地位,逐渐将传统制造往智能制造方向引导转型.智能制造产业链所蕴藏的巨大益处在逐渐被挖掘,高效性,便捷性,安全性为市场注入了新的活力.
在传统制造中,装配是生产过程中重要的一环,随着智能制造的不断发展,装配环节也越来越智能化.
随着中国汽车行业竞争日益增强,对生产出来的汽车质量的要求也越来越严格[1].以往,在装配环节中,装配件在经人工装配过后还需使用大量人工来进行复核,才能最后提交.这过程存在以下几点问题可以进行优化:(1)复核过程又使用大量人工,消耗太多人力资源.(2)大量复杂的装配件使人工学习的成本非常高.(3)使用人工会给装配结果带来不确定性.尤其是在人工长时间工作过后,装配精度会下降,给后续复核人员带来巨大压力.
随着深度学习的广泛应用,目标检测的精确度和效率都得到了较大提升[2],被广泛使用于智能制造领域.张丽秀等人[3]使用改进的YOLOv3 算法对汽车前脸进行识别,该算法对小目标检测效果并不好,余永维等人[4]与张静等人[5]在训练YOLOv3 算法模型的时候采用的数据集较小,有过拟合的表现.曹之君等人[6]改进的Faster RCNN 算法,与魏中雨等人[7]使用的Mask RCNN 算法识别目标的准确度较低,不适合工业生产环境.王帅等人[8]基于混合现实进行零件检测,在检测过程中使用的VR 设备较为昂贵,工业生产环境中全员配备较为困难.同时,将VR 眼镜采集到的数据传送到服务器端,再经过服务器端计算,最后将结果返回到眼镜,这一过程所消耗时间较长.为此,本文使用高性能嵌入式设备,在已有的车间装配检测的相关研究基础上,采用优秀目标检测算法,有效提高目标检测准确率,减少目标识别消耗时间,降低硬件使用成本.
随着计算机视觉技术的飞速发展,工业领域对具有识别功能的视觉识别系统的需求不断增加[9].基于深度学习的汽车内饰件装配检测系统在汽车内饰件装配过程中,可以有效的减少使用人工的数量,降低成本,提高装配件复核效率.
2 汽车内饰件装配检测架构
在传送带上方安装显示器和视像头,将显示器和摄像头与内部搭载汽车内饰件装配检测系统的英伟达开发板(Jetson Xavier NX)相连接,如图1所示.员工在传送带旁装配汽车内饰件,上方摄像头对准员工操作区域,将采集的数据传输到英伟达开发板进行实时目标检测.当员工装配完后,可以在对面的显示器中看到英伟达开发板对装配完的汽车内饰件的检测结果.如果检测结果符合预期的汽车内饰件装配结果,则通过复核,直接提交.如果检测结果不符合预期的汽车内饰件装配结果,则预警,提示员工修改.
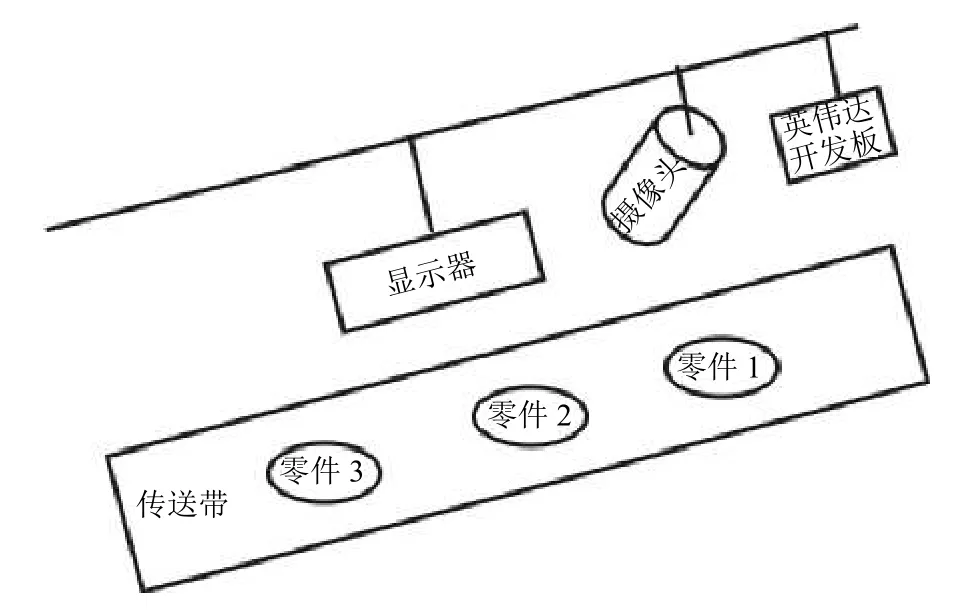
图1 汽车内饰件装配工作环境
3 汽车内饰件装配检测
优化汽车内饰件装配过程的核心是英伟达内搭载的汽车内饰件装配检测系统,系统架构设计分成3 层,分别是数据层,平台层和应用层.数据层是完成对数据的处理,先采集数据得到原始数据,再对数据进行标注,制作数据集,将数据集传入下一层供平台层使用;平台层是在嵌入式设备搭建机器学习平台,分别训练Faster RCNN 与YOLOv5,完成对两个模型的评估,选择最优模型进行目标检测;应用层主要是完成人机交互等操作.具体系统构架如图2所示.

图2 汽车内饰件检测构架图
3.1 数据集
制作的汽车内饰件数据集中包含5 847 张图片,大小1.6 GB.其中含5 种汽车内饰件,每种汽车内饰件具体特征标注情况如表1所示.

表1 汽车内饰件具体特征标注情况
3.2 运行环境部署
英伟达开发板(Jetson Xavier NX)是外形小巧的AI 超级计算机,可为边缘系统提供超级计算机性能.70 mm × 45 mM的开发板拥有高达 21 TOPS 的加速计算能力,为并行运行现代神经网络并处理来自多个高分辨率传感器的数据提供有力支持.同时,英伟达开发板拥有低功耗,散热性好的特点,即便开发板全力运行,也只要15 W 功耗.将风扇设置好参数,开发板GPU 核心位置也不会超过50 度.具体英伟达开发板外观如图3所示.

图3 英伟达开发板
首先给Nvidia Jetson Xavier NX 烧写JetPack.
官方纯净镜像文件,该镜像文件中已经自带OpenCV 4.1,Cuda 10.2,Cudnn 7.63,无需再另安装.在Ubuntu 18 系统下部署Python 3.6 环境,安装以下依赖包.具体如表2所示.
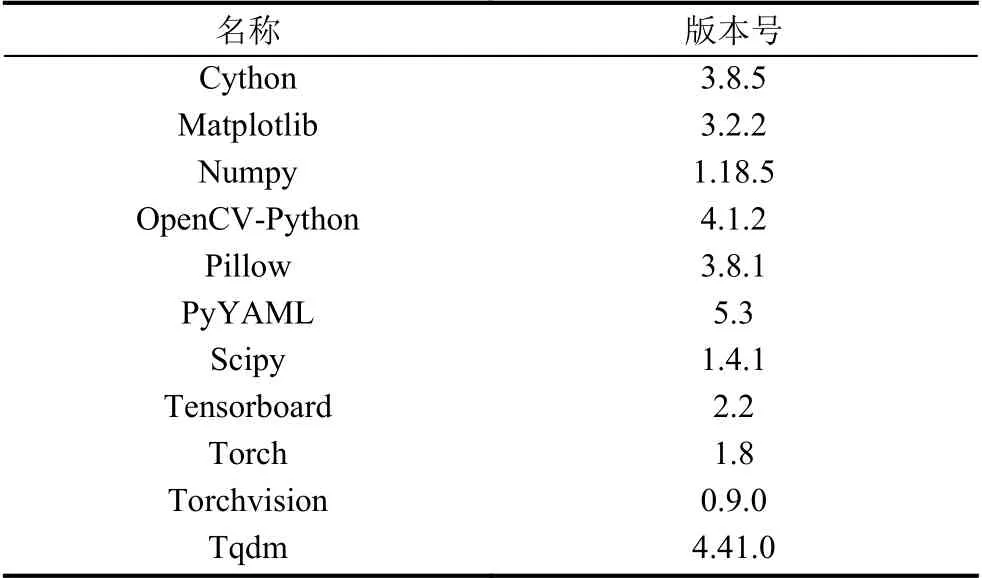
表2 环境依赖包详情
3.3 目标检测算法
系统的核心内容是对汽车内饰件的检测.以已经采集到的汽车内饰件数据为依据,训练模型得到权重文件,应用权重将工业摄像头拍摄到的汽车内饰件进行识别.
目标检测属于计算机视觉的一个基本任务,该任务可以细化为目标定位与目标识别两个任务.目前主流的目标检测方法分为两类:(1)单阶段目标检测方法;(2)双阶段目标检测方法.单阶段目标检测方法是直接回归目标的位置坐标值和目标的类别概率,主要有YOLO[10]算法和SSD[11]算法,双阶段目标检测方法是先生成一系列样本候选框,然后剔除掉框出背景的候选框,最后对候选框中的目标进行分类,主要有RCNN[12]算法,Fast-RCNN[13]算法,Faster RCNN[14]算法,双阶段目标检测算法速度相对较慢训练较困难但是准确率高,单阶段目标检测算法准确率没有双阶段目标检测算法高但是速度较快.分别选取单阶段目标检测方法中的YOLOv5 和双阶段目标检测方法中的Faster RCNN对数据集进行训练,选取较优模型作为汽车内饰件检测系统的核心检测方法.
3.3.1 YOLOv5 模型实验分析
YOLOv5 的网络结构主要由输入端、Backbone、Neck、Head 构成.YOLOv5 的输入端对数据集进行mosaic 数据增强后传入后续网络.YOLOv5 的Backbone部分是检测网络的主干,网络提取出图像的高中低层的特征.YOLOv5 的Neck 部分主要用于生成特征金字塔,特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体.YOLOv5 的Head 部分进行最终检测.
GIoU作为YOLOv5 的损失函数,具体算法是两个任意框A,B,找到一个最小的封闭形状C,让C可以把A,B包含在内,接着计算C中没有覆盖A和B的面积占C总面积的比值,然后用A与B的IoU减去这个比值.公式如下:
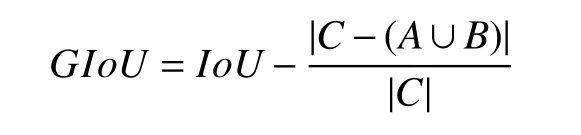
训练模型初始,参数的选择对模型的训练速度和结果的精度都有影响,甚至参数选择错误会导致模型在搭建的平台训练不下去.经过多次实验,均衡模型训练速度和结果的精确性,设置参数batch-size 为16,epochs 为300,workers 为2,使用默认超参数学习率为0.01,学习率动量为0.937,权重衰减系数为0.000 5.使用YOLOv5 训练已制作的数据集,训练过程图片如图4、图5所示.

图4 训练过程图

图5 训练过程图
使用深度学习轻量级可视化工具Wandb 查看训练结果,训练过程中的损失值变化曲线如图6所示,PR 曲线如图7所示,准确率如表3所示.

图6 训练过程中的损失曲线
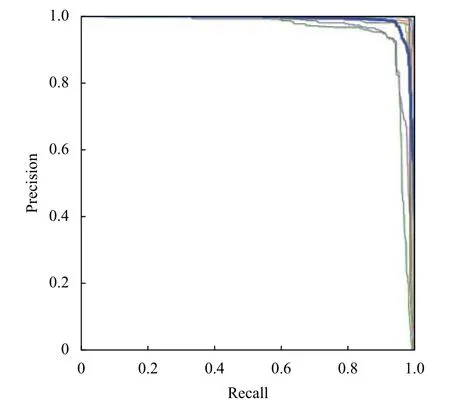
图7 Precision-Recall 曲线图

表3 特征检测准确率
从图6 中可以看出,在迭代50 次之前模型的损失值下降的非常快,在迭代50 次到300 次之间,模型的损失值下降就很缓慢了,达到迭代300 次,此时模型的损失值就已经非常小了.由此可见本次实验训练的模型是好的.
PR 曲线中,纵坐标Precision,准确率,表示预测结果中,预测为正样本的样本中,正确预测为正样本的概率;横坐标Recall,召回率,表示在原始样本的正样本中,最后被正确预测为正样本的概率.Precision 和Recall是分类性能评估的重要指标.在实际当中,我们往往希望得到的准确率和召回率都比较高.从图7 中可以看出本次的训练,准确率和召回率都很高,是比较好的结果.
从表3 中可以看出,最后的识别效果很好,13 个特征的识别率都在0.95 以上.
3.3.2 Faster RCNN 模型实验分析
Faster RCNN 有4 个主要内容.卷积层,用于提取图片的特征,输入为整张图片,输出为提取出的特征,简称为feature maps.RPN 网络,用于生成候选区域(region proposals).ROI Pooling,该层收集输入的feature maps 和proposals,综合这些信息后,提取proposal feature maps,得到固定尺寸的feature map,然后送入后续全连接层判定目标类别.分类和回归,这一层的输出是最终目的,输出候选区域所属的类,和候选区域在图像中的精确位置.
从图8 中可以看出,在模型迭代开始,模型总的损失值就快速的下降到了1.0 以下,在迭代到10 000 次之后模型总的损失值是一直在0.5 以下,在迭代完成后,可见模型总损失值非常小,模型最终实现收敛,显示出本次训练的模型是好的.特征检测准确率如表4所示.

图8 训练过程中的损失曲线

表4 特征检测准确率
从表4 中可以看出,最后的识别效果也不错,但是没有YOLOv5 的测试结果好.虽然说双阶段目标检测方法在大物体目标检测上比单阶段目标检测方法要有更高的准确率,但是在小目标检测上,却没有更好的表现.这里YOLOv5 的检测效果比Faster RCNN 的检测效果更好,是因为YOLOv5 在前面的网络中融合了更多的语义特征,对小目标检测进行了优化.
4 汽车内饰件装配检测系统
汽车内饰件装配检测系统将工业摄像头采集到的汽车内饰件图片,通过YOLOv5算法识别出汽车内饰件关键特征,将识别后的结果存入数据库中.Java Web 程序从数据库中读取,将汽车内饰件特征的检测情况展示在网页页面上,并根据汽车内饰件的特征分类及数量最终确定汽车内饰件的分类.
员工在装配完汽车内饰件后,可以实时在屏幕上看到汽车内饰件装配检测系统反馈的装配结果,如果装配后的汽车内饰件成功被识别到了预设的分类,则提交通过,否则提示员工进行修改,员工可根据识别到的汽车内饰件关键特征对未通过的内饰件修改,然后进行再一次提交.汽车内饰件装配检测系统反馈结果具体如图9、图10所示.

图9 系统运行图1

图10 系统运行图2
5 结束语
为优化汽车内饰件装配过程,减少对装配后的汽车内饰件进行质量检测所花费的时间.本系统采用YOLOv5算法,实现了对汽车内饰件的实时检测,并取得了很好的效果.虽然人工在装配过程中依然有很大的作用,无法被完全替代,但是设计的汽车内饰件装配检测系统可以辅助人工在汽车内饰件装配后立刻进行复核,不需要再额外抽调人工进行复核,很大程度上避免了人力资源的浪费,减少人工的学习成本,提高装配环节的效率及装配结果的确定性.系统对标号2 和4 的汽车内饰件检测准确率在0.98 以下,仍需要进一步优化.
