深度多模态表征学习概述
2022-05-10谢亦才易云
谢亦才 易云
摘要:多模态表征学习旨在缩小不同模态数据之间的异质性差距。近年来,基于深度学习的多模态表征学习因其强大的多层次抽象表征能力而备受关注。文章提供了关于深度多模态表征学习的全面调查。文章将深度多模态表示学习方法分为三个框架:联合表示、协调表示和编解码器。此外,还回顾了该领域的一些典型模型,从传统模型到新开发的技术。重点介绍了新开发技术的关键问题,如编码器-解码器模型、生成性对抗网络等。最后,对今后的工作提出了一些重要的方向。
关键词:多模态表征学习;多模态深度学习;深度多模态融合
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)09-0067-03
1引言
多模态数据是指描述同一对象的数据记录在不同类型的媒体中例如文本、图像、视频、声音和图形。在表征学习领域,“模态”一词指编码信息的特定方式或机制。因此,上面列出的不同类型的媒体也指模态,涉及多种模态的表征学习任务将被描述为多模态表征学习。由于多模态数据从不同的角度描述对象,通常在内容上是互补的或补充的,因此它们比单模态数据信息更丰富。例如,学者们在有关语音识别的研究中发现,视觉模式能提供嘴唇运动和嘴的关节(包括张开和闭合)之间的关联信息,这一视觉模式对提高语音识别性能有帮助。因此,弥合语义鸿沟,综合利用几种模台提供的综合语义是很有价值的。
为了缩小异质性差距,在过去的几十年中,学者们用各种方法进行了大量的研究。因此,多模态表征学习的发展使许多应用受益。例如,通过利用来自多通道的融合特征,可以在跨媒体分析任务中实现性能改进,例如视频分类、事件检测和情感分析等。此外,通过利用跨模态相似性或跨模态相关,使我们能够使用句子作为输入来检索图像,反之亦然,即跨模态检索。最近,一种新型的多模态应用——跨模态翻译在計算机视觉界引起了极大的关注。顾名思义,它将一种情态转化为另一种情态。该类别中的示例性应用包括图像标题、视频描述和文本到图像合成。
近年来,由于具有多层次抽象的强大表示能力,深度学习在有关自然语言处理、语音识别和计算机视觉等应用中取得了优良成果[1]。此外,深度学习的另一个关键优势是,可以使用通用学习程序直接学习层次表示,而无须手工设计或选择功能。在这一成功的推动下,深度多模态表征学习获得了巨大关注。
2深度多模态表征学习框架
为了便于讨论如何缩小异质性差距,将深度多模态表示方法分为三类框架:(1)协同表示,旨在学习协同子空间中每个模态的分离和受限表示,包括跨模态相似模型和典型相关分析;(2)编码器-解码器模型,努力学习用于将一种模态映射到另一种模态的中间表示。每个框架都有其集成多种模态的方式,并由一些应用程序共享。在应用多模态表征学习之前,应通过适当的方法提取特定模态的特征;(3)联合表示,它将单模态特征表示投影到一个共享语义子空间中,以利于融合多模态特征。因此,在本节中,首先介绍可能显著影响性能的单模态表示方法,然后开始讨论三种类型的框架。
2.1特定模态表征
尽管各种不同的多模态表示学习模型可能共享相似的体系结构,但用于提取特定模态特征的基本组件可能彼此有很大不同。在这里,将介绍适用于不同模式的一些最流行的组件,而不涉及技术细节。
用于图像模态特征提取的深度学习模型有LeNet[2], AlexNet[3], GoogleNet[4], VGGNet[5]和ResNet[6]等。它们可以集成到多模式学习模型中,并与其他组件一起进行培训。然而,考虑到对足够的训练数据和计算资源的需求,预训练好的CNN模型是多模态表示学习的更好选择。
至于视频模态,由于每个时间步长的输入是图像,因此可以通过用于处理图像的技术来提取其特征。除了深层特征外,手工特征仍然广泛用于视频和音频模式。此外,还开发了一些工具包来提取特征。例如,OpenFace可用于提取面部特征,如面部地标、头部姿势和眼睛注视。另一个工具是Opensmile,可用于提取声学特征包括Mel频率倒谱系数(MFCC)、声音强度、音调及其统计信息。在视频和音频的帧被编码之后,可以使用CNN或RNN网络将序列汇总为单个向量表示。
用于文本模态特征提取的深度模型有word2vec[7],Glove[8]等,它将单词映射到向量空间,在该空间中可以测量单词之间的相似性。在NLP任务中,应该考虑的一个常见问题是未知单词问题,也称为词汇表外(OOV)单词,它可能会影响许多系统的性能。
2.2联合表征
集成不同类型的特征以提高机器学习方法性能的策略长期以来被研究者所采用。这种策略在多模态环境中的自然延伸是利用融合的异构特征。根据这一策略,在许多多模态分类或聚类任务中,如视频分类、事件检测、情感分析和视觉问答等,都展示了应用前景。
融合多模态特征的最简单方法是直接连接它们。然而,这个子空间大部分是由一个不同的隐藏层实现的,在该隐藏层中,将添加转换的特定模态向量,从而将来自不同模态的语义组合起来。
除了在不同的隐藏层中进行融合过程(通常称为加法方法)之外,一些文献中还采用了乘法方法。在情感分析任务中,Zadeh等人[9]提出了基于模态内和模态间动力学建模的多模态情感分析问题,并提出了张量融合网络模型,它可以端到端地学习这两种动力学。这个方法是针对在线视频中口语的易变性以及伴随的手势和声音而定制的。
与其他框架相比,联合表示的优点之一是,由于不需要显式协同模态,因此可以方便地融合多种模态。另一个优点是共享的公共子空间趋向于模态不变,这有助于将知识从一个模态转移到另一个模态。然而,该框架的缺点之一是它不能用于推断分离结果的每种形态的表征。
2.3编码解码器表征
近年来,编解码框架得到了广泛的应用,用于将一种模态映射到另一种模态的多模态翻译任务,如图像标题、视频描述和图像合成。通常编码器-解码器框架主要由两部分组成,即编码器和解码器。其中编码器通过多层神经网络将源模态降维映射为潜在向量f,然后,解码器对向量f升维,生成新的目标模态样本。
编码器-解码器模型有一些变体包含多个编码器或解码器。例如,Mor等人[11]提出了一种跨乐器、流派和风格的翻译音乐方法。该方法基于多域wavenet自动编码器,具有共享编码器和端到端训练波形的解纠缠潜在空间。其中,共享编码器负责提取独立于域的音乐语义,每个解码器将在目标域中再现一段音乐。一个包括两个编码器的示例包括Huang等人提出的图像到图像转换模型。其中一个编码器负责对图像风格样式编码,另一个编码器负责对图像内容编码。
2.4协同表征
多模态学习中流行的另一种方法是协同表示法。协同表示框架在某些約束条件下学习每个模态的分离但协同表示,而不是学习联合子空间中的表示。由于不同模态中包含的信息是不平等的,学习分离表征有助于保持独有的有用模态特定特征[10]。通常,在约束类型的条件下,协同表示方法可分为两组,基于跨模态相似性的和基于跨模态相关性的。基于跨模态相似性的方法可以直接测量向量与不同模态的距离,而基于模态相关的方法使来自不同模态的表征的相关性最大化。
跨模态相似方法是学习相似性度量约束下的协同表示。该模型的学习目标是保持模态间和模态内的相似结构,期望与相同语义或对象相关的跨模态相似距离尽可能小,而与不同语义相关的距离尽可能大。
与其他框架相比,协同表征倾向于在每种模态中保持唯一和有用的模态特定特征。由于不同的模态编码在分离的网络中,其优点之一是每个模态的表征可以独立推断。这一特性也有利于跨模态知识迁移学习。该框架的一个缺点是,在大多数情况下,很难学习两种以上模态的表示。
3典型模型
在本节中,将总结一些深度多模态表征学习的典型模型。它们的范围从传统模型,包括概率图形模型、多模态自动编码器和深度典型相关分析,与新开发的技术相结合,包括生成对抗网络和注意机制。这里描述的典型模型可以分为上面介绍的一个或多个框架,也可以与它们集成。
3.1概率图模型
在深度表征学习领域,概率图形模型包括深度信念网络(DBN)和深度玻尔兹曼机器(DBM)。虽然它们都是从堆叠受限玻尔兹曼机器(RBM)层训练出来的,但它们的结构是不同的。前者是由有向信念网络和RBM层组成的部分有向模型,后者是完全无向模型。
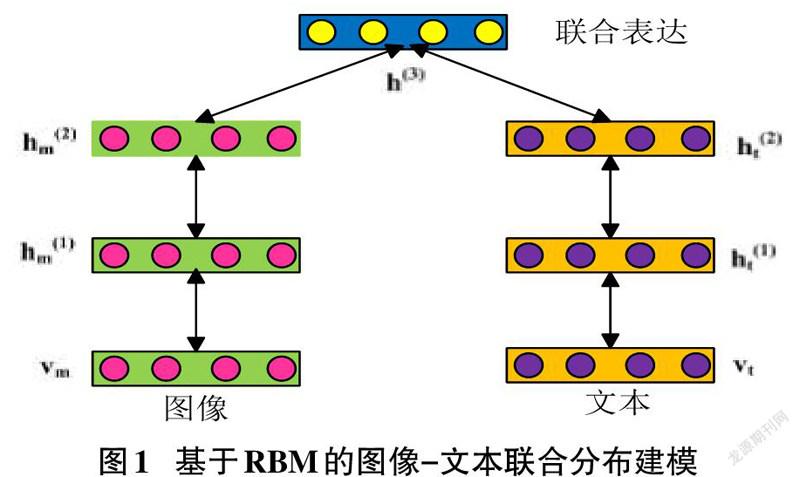
概率图形模型的一个例子是Srivastava和Salakhutdinov[12]提出的多模态DBN。通过在特定于模态的DBN上添加共享RBM隐藏层,它可以学习跨模态的联合表示。Srivastava和Salakhutdinov的另一个模型是多模深层玻尔兹曼机器,它交替使用DBMs作为处理每个模态数据的基本单元。作为一个完全无向的模型,隐藏单元的状态将在各个模式之间相互影响。因此,模态融合过程是分布式的跨越所有层的所有隐藏单元,如图1所示。
与通过共享表示层连接不同模式的策略不同,Feng等人[15]倾向于巧妙的最大化模式层之间的对应关系。在每个等效隐藏层,来自不同模态的两个RBM分别通过相关损失函数连接。通过这种方式,获取了跨模态检索的基本互模型相关性。
3.2多模态自动编码器
自动编码器因其学习表示的能力而广受欢迎,在无监督的情况下,不需要标签。这个自动编码器的基本结构包括两个组件,一个是编码器,另一个是解码器。编码器也可以将输入转换为压缩的隐藏向量被称为潜在表示,而解码器基于此潜在表示重构输入使重建损失最小化。受去噪自动编码器的启发,Ngiam等人[13]将自动编码器扩展到多模态。他们训练了一个双模深度自动编码器来学习音频和视频模式的共享表示。在该模型中,两个分离的自动编码器组合在公共潜在表示层中,同时保持其编码器和解码器独立。
3.3生成对抗网络
生成对抗网络(GAN)是一种新兴的深度对抗网络学习技巧。作为一种无监督的学习方法,它可以在不涉及标签的情况下学习数据表示,这将显著降低对手动注释的依赖性。此外,作为一种生成方法,它可以根据训练数据的分布生成高质量的新样本。自2014年以来,在Goodfellow等人[14]提出后,生成性对抗学习策略已成功应用于各种单模态应用。最著名的应用之一是图像合成,它根据随机输入生成高质量图像从正态分布中提取。其他成功的例子包括图像到图像的转换和图像超分辨率。最近,生成对抗性学习策略进一步扩展到多模态情况,如文本到图像合成、视觉字幕、跨模态检索、多模态特征融合和多模态讲故事。
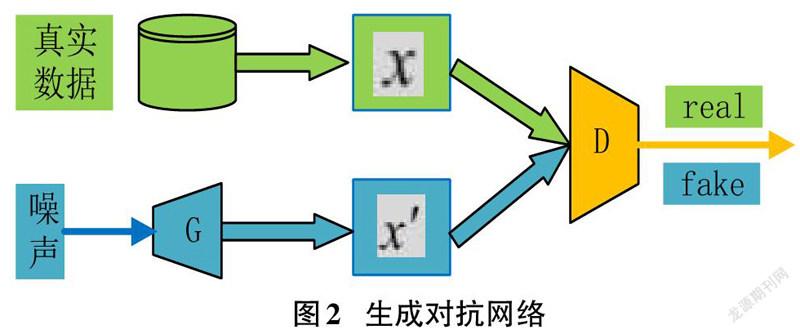
一般来说,生成对抗网络由两个部分组成,一个生成网络G作为生成器,另一个判别网络D作为鉴别器,相互竞争。网络G负责根据学习到的数据分布生成新样本。而网络D旨在区分网络G生成的实例与从训练集中采样的项目之间的差异。通常,G和D这两个分量都是通过深度神经网络实现的,如图2所示。
与经典的表示学习方法相比,GANs的一个明显区别在于数据表示的学习过程并不简单。这是一种隐含的范式。与传统的无监督表示方法(如自动编码器)不同,GANs直接学习从数据到潜在变量的映射,而GANs学习从潜在变量到数据样本的反向映射。具体地说,生成器将随机向量映射到独特的样本中。因此,该随机信号是对应于生成的数据的表示。在随机信号概率很好地拟合真实数据概率的条件下,该随机信号对于真实的训练数据是足够好的表示。
4结论和未来展望
在本文中,提供了一个全面的调查,深入研究多模态表征学习。根据整合不同模态的底层结构分为三类框架:联合表示、编解码器表示和协同表示。此外,总结了该领域的一些典型模型,从传统模型到新开发的技术,包括概率图模型、多模态自动编码器、生成对抗网络等。
长期以来,虽然注意力机制可以部分解决多模态表征学习的语义冲突、重复和噪声等问题,但它们是隐性的,不能有计划的可度量的主动控制。为此,可以通过推理机制,将能够主动选择急需的证据,并在减轻这些问题的影响方面发挥重要作用。可以预测,表征学习及其推理机制的紧密结合将赋予机器智能认知能力。
参考文献:
[1] LeCun Y,BengioY,Hinton G.Deep learning[J].Nature,2015,521(7553):436-444.
[2] LeCun Y,Bottou L,Bengio Y,etal.Gradient-based learning applied to document recognition[J].ProceedingsoftheIEEE,1998,86(11):2278-2324.[LinkOut]
[3] A. Krizhevsky,I.Sutskever,and G.E. Hinton,“ImageNet classification with deep convolutional neural networks”[C]//in Proc. Adv. Neural Inf.Process. Syst., 2012:1097–1105.
[4]Szegedy C,LiuW,Jia YQ,et al.Going deeper with convolutions[C]//2015IEEEConferenceonComputerVisionand Pattern Recognition.June7-12,2015,Boston,MA.IEEE,2015:1-9.
[5]K.Simonyanand A.Zisserman,“Very deep convolutional networks for large-scale image recognition”[C]//in Proc. Int. Conf. Learn. Represent.,2015:1-14.
[6] He K M,Zhang X Y,Ren S Q,etal.Deep residual learning for image recognition[C]//2016IEEEConferenceonComputerVisionand Pattern Recognition.June27-30,2016,LasVegas,NV,USA.IEEE,2016:770-778.
[7] T. Mikolov, K. Chen, G. Corrado, and J. Dean. (2013).“Efficient estimation of word representations in vector space.”[Online]. Available:https://arxiv.org/abs/1301.3781.
[8] Pennington J,Socher R,Manning C.Glove:global vectors for word representation[C]//Proceedingsofthe2014 Conference on Empirical Methods in Natural LanguageProcessing (EMNLP).Doha,Qatar.Stroudsburg,PA,USA:AssociationforComputational Linguistics,2014:1532-1543.
[9] Zadeh A,Chen M H,PoriaS,etal.Tensor fusion network for multimodal sentiment analysis[C]//Proceedingsofthe2017 Conference on Empirical Methods in Natural LanguageProcessing.Copenhagen,Denmark.Stroudsburg,PA,USA:AssociationforComputational Linguistics,2017:1103-1114.
[10] Peng Y X,Qi J W,Yuan Y X.Modality-specific cross-modal similarity measurement with recurrent attention network[J].IEEE Transactions on Image Processing,2018,27(11):5585-5599.
[11] Mor N,Wolf L,Polyak A,etal.A universal music translation network[EB/OL].2018:arXiv:1805.07848[cs.SD].https://arxiv.org/abs/1805.07848
[12] N. Srivastava and R. Salakhutdinov.“Learning representations for multimodal data with deep belief nets”[C]//in Proc. Int. Conf. Mach. Learn. Workshop, vol. 79, 2012:1-8.
[13] J. Ngiam, A. Khosla, M. Kim, J,et al.‘‘Multimodal deep learning,’’ in Proc. 28th Int. Conf. Mach. Learn., 2011: 689-696.
[14] I. J. Goodfellow et al., “Generative adversarial nets,” in Proc. 27th Int. Conf. Neural Inf. Process. Syst. (NIPS), vol. 2. Cambridge, MA, USA: MIT Press, 2014:2672-2680.
[15] Feng F X,Li R F,Wang X J.Deep correspondence restricted Boltzmann machine for cross-modal retrieval[J].Neurocomputing,2015,154:50-60.
【通聯编辑:梁书】