基于大数据的电动汽车报文实时分析系统设计与实现
2022-05-09周佳佳
周佳佳
(南通市测绘院有限公司 江苏 南通 226000)
1 引 言
随着新能源技术的日渐成熟,电动汽车的市场占有量越来越大,在安全以及补贴的标准上,国家明确车企需要实时监控电动汽车的电池状况、电压状况、车辆状态、温度状况和地理位置(地理位置获取只限公共汽车)等信息,对故障信息等进行分析、预警处理。而面对海量的电动汽车报文数据,常规的分析系统已无法满足其性能要求,因此本文采用基于大数据框架Flume+Kafka+Storm+HBase的组合来组建实时分析系统。Flume+Kafka+Storm+HBase的组合技术,是一个流程化的组合,涉及报文数据实时分析的完整生命流程,详细流程包含数据采集、数据缓冲、数据清洗-分析计算、结果入库四个步骤。
2 电动汽车报文实时分析系统设计
电动汽车报文实时分析系统相比较传统的分析系统,实时分析系统具备了高并发、低延时、高可扩展、高可用的特性。
系统核心结构由数据源、数据缓冲区、实时数据清洗-分析器、结果存储区四部分组成。其系统总体结构如图1所示。
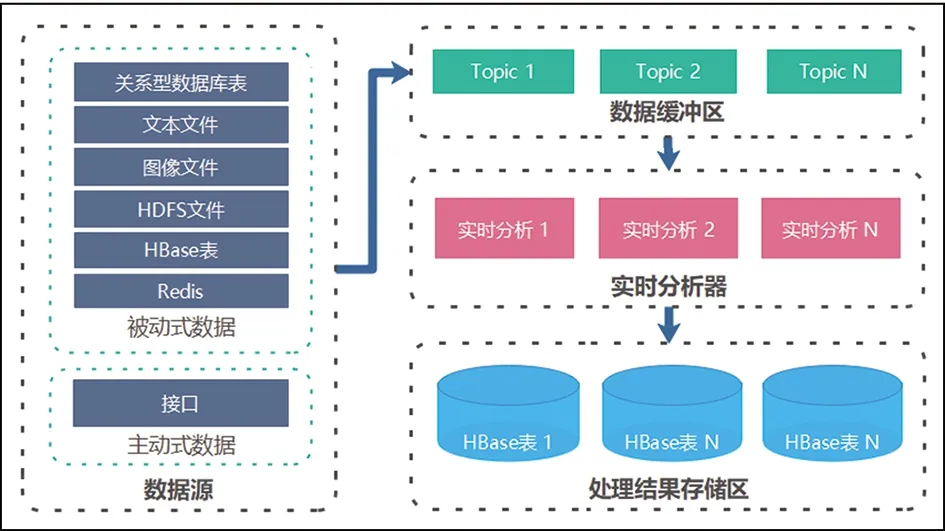
图1 系统总体结构图
系统的整个流程包含采集报文数据、报文数据缓冲、实时分析、结果入库四个步骤,其详细流程为:
(1)平台将数据源中需要处理的数据推送到数据缓冲区。
(2)实时数据清洗-分析器的入口线程以轮询的方式从数据缓冲区拉取数据。
(3)实时数据清洗-分析器的入口线程拉取数据后,转发到数据清洗线程,进行数据清洗。如遇到无效数据,则将数据转回数据缓冲区的无效数据区进行存储,实时主流程继续从数据缓冲区拉取新数据处理。
(4)实时数据清洗-分析器清洗完成后,将结果转发到分析计算线程,进行实时分析。
(5)实时数据清洗-分析器分析计算完成后,将结果数据转发到入库线程。
(6)入库线程最终将结果数据存入结果存储区。
2.1 数据源
在数据源层中,将所有数据分为主动数据和被动数据两类:
(1)主动数据:可以主动向缓冲区发送数据的称为主动数据,如坐标转换接口中需要被转换的原始坐标数据,在接口中可以直接将数据推入缓冲区。
(2)被动数据:需要借助外界手段将数据推送到缓冲区的称为被动数据。如电动汽车报文数据,它是一个不断累加的文本数据,它无法直接进入缓冲区,因此是被动数据。
当前系统采用Flume集群来对被动数据进行推送。
2.2 数据缓冲区
数据缓冲区需要满足分布式、高可用、数据容灾、高吞吐量、多计算共用数据的特点,因此实现时采用Kafka组件作为基础运行环境,在此基础上,针对不同的实时计算业务,可以建立不同的消息队列,也可以使用同一个消息队列,这取决于具体的业务。
在电动汽车报文实时分析系统中,基于Kafka建立一个Topics,该Topics负责接收数据源端的数据,进行分区存储以及被后续流程消费数据。该Topics被分为100个Partition。
2.3 实时数据清洗-分析器
实时数据清洗-分析器包含两部分:数据清洗、分析计算。数据清洗主要是将接收到的报文数据进行基本校验、完整性校验、有效性校验,分析计算主要是将数据在业务上进行分析判断、归类。
采用Storm组件作为该层的基础运行环境,其内容包含数据拉取器、数据分析线程组。分析器的执行流程为:数据拉取→报文分析→存储。
2.4 结果存储区
由于整个平台需要处理海量数据,对于计算结果,可能会比原始数据更为庞大,因此采用列式数据库HBase。实时数据清洗-分析器将数据分析后,分类进行存储在HBase中。
3 电动汽车报文实时分析系统实现
3.1 基础环境
软件基础设施包含Flume、Kafka、Storm、HBase四个功能性集群。
3.2 实时分析系统开发
3.3.1 表结构
表结构包含:主报文表、报警报文表、心跳校时报文表、错误表,其中主报文表存储所有分析后的报文数据,其结构如表1所示。
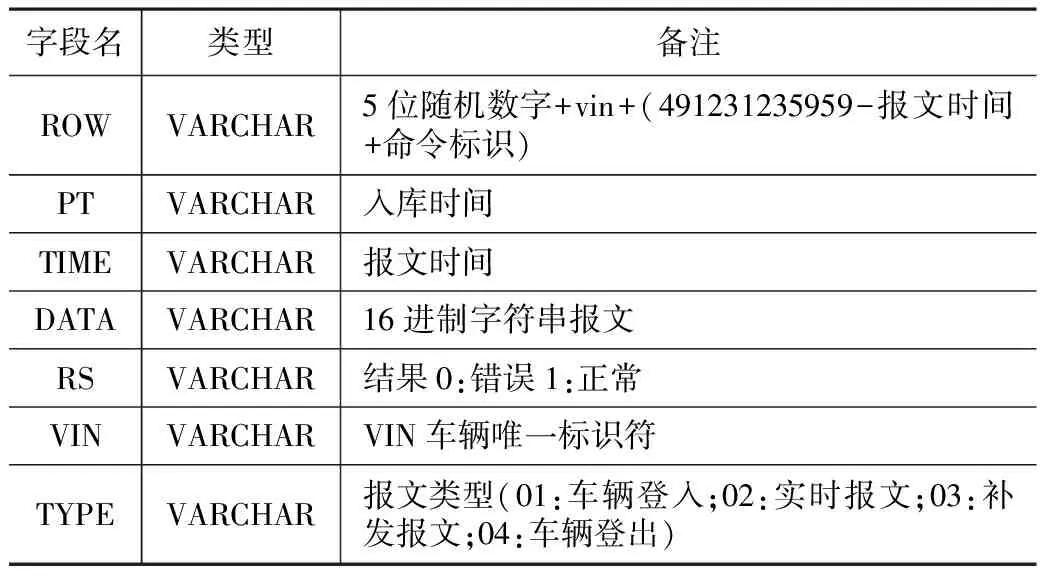
主报文表 表1
3.3.2 程序结构
程序以jar包的形式运行在Storm环境中。程序结构包含公用库(common)、实时计算(realcalcmsg)、查询接口(webapi)三部分,如图2所示。
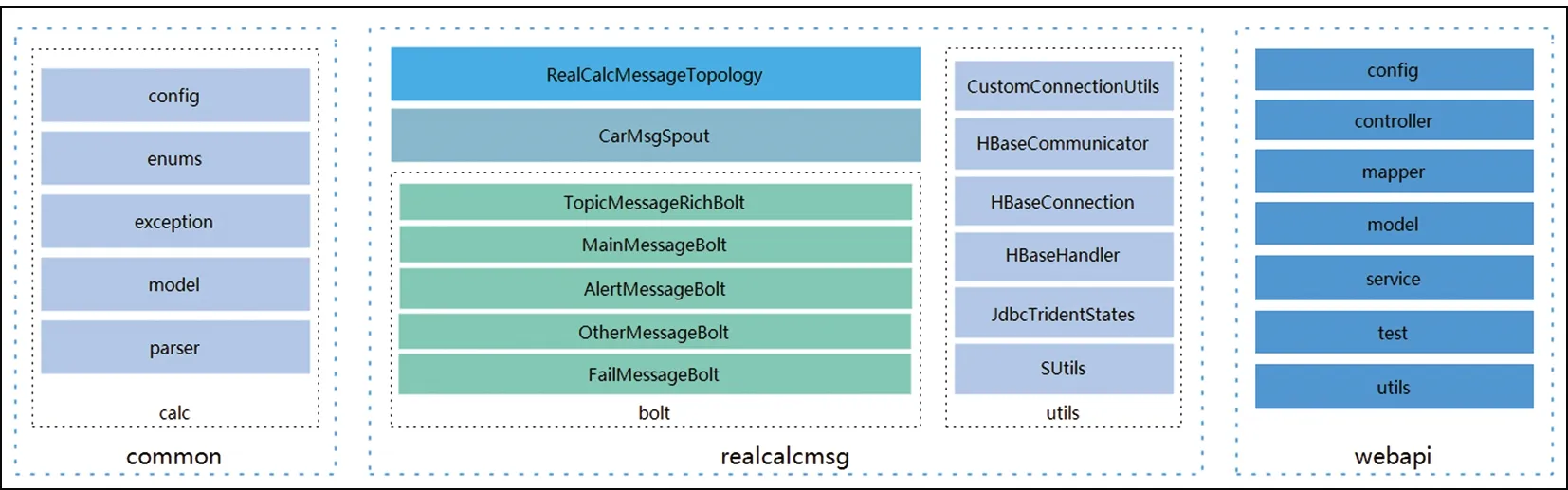
图2 结果存储区结构图
(1)公用库
公用库中包含配置项、工具包、报文解析算法。
(2)数据清洗-实时计算
实时计算中包含topology、spout、bolt、utils四类代码。
①topology为RealCalcMessageTopology类,用来组织、管理spout和bolt程序;
②spout为CarMsgSpout类,用来轮询地拉取kafka中的数据;
③bolt中分为报文分析(TopicMessageRichBolt为数据清洗-分析)、结果存储(MainMessageBolt为主报文结果存储,AlertMessageBolt为报警报文结果存储,OtherMessageBolt为心跳终端校时报文结果存储,FailMessageBolt为非法报文结果存储)两类。
(3)查询接口
查询接口中主要包含controller、mapper、model、service、test、utils六类代码,基于Spring boot、MyBatis框架为基础实现。
3.3.3 关键技术实现
(1)基于Storm的数据清洗-实时计算程序流程
CarMsgSpout程序对kafka的topic进行监听,如果topic中有新的报文数据,则取出一条,将报文数据传递给TopicMessageRichBolt程序;TopicMessageRichBolt得到数据后,对该条报文进行解析,将字符串报文拆分成多个具有业务意义的字段,再对字段进行有效性验证,根据验证结果,分发到对应的存储bolt(Main、Alert、Other、Fail)中。实时计算的流程如图3所示。
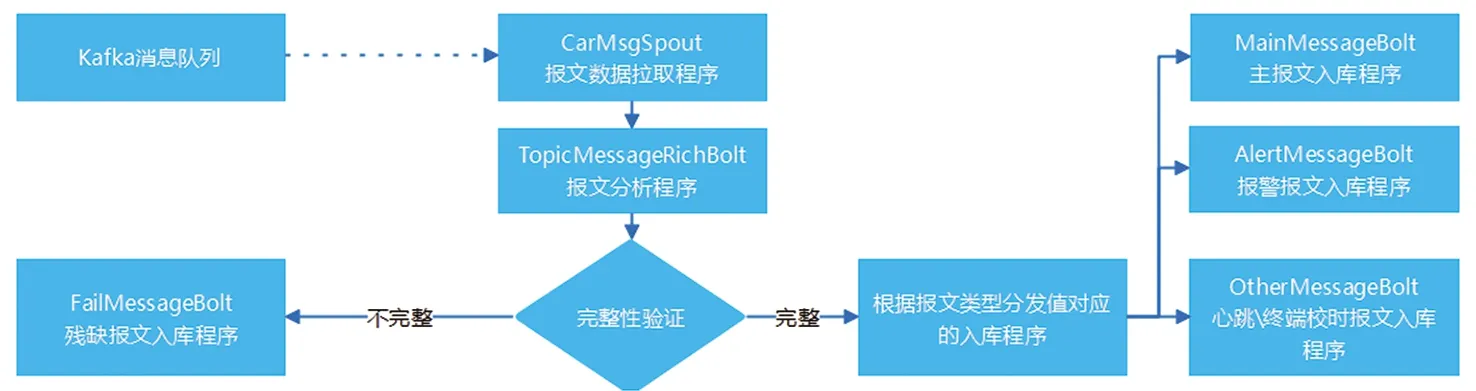
图3 电动汽车报文实时计算流程图
(2)报文解析
电动汽车报文以16进制的字符串形式进行传输。报文数据的解析基于有限状态机的思想设计程序。
解析程序的状态机有三种状态:
①CHECK_STATE_MESSAGE,解析报文;
②CHECK_STATE_HEADER,解析报文头部信息;
③CHECK_STATE_CONTENT,解析报文正文。
报文进入解析时,初始状态为CHECK_STATE_MESSAGE,每个状态下都会执行对应的解析任务,只有解析正常的,才能够进入下一个状态,否则,即解析完成。模型如图4所示。
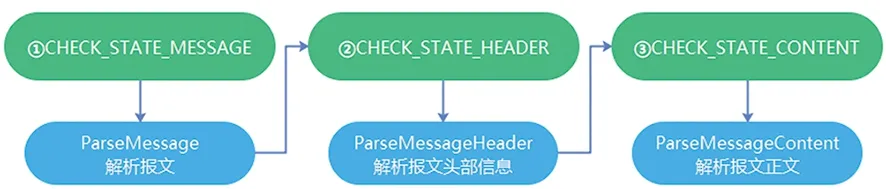
图4 基于有限状态机的报文解析模型图
4 案例应用
某车企基于本系统对电动汽车进行实时数据的监控与预警(图5),该应用综合指标:

图5 数据清洗-分析器性能监控图
(1)高并发:支持10万辆车每秒一次的频率发送报文数据;
(2)低延时:10万辆车同时在线的情况下,单条报文计算耗时 2 ms,存储小于 600 ms;
(3)高扩展性:目前计算节点3个,存储节点5个,并支持计算节点、存储节点的横向扩展;
(4)高可用性:计算节点或主控节点出现故障导致无法计算时,自动将任务转移到计算节点或备用主控节点上。
支持同时处理10万辆车的实时报文数据,其单条报文的分析耗时 2 ms,单条报文的存储 100 ms;当前计算节点3个,支持计算节点的横向扩展。
某车企基于本系统对电动汽车进行实时数据的监控与预警,如图6所示。
图6 电动汽车实时数据的监控与预警图
本文采用的组合技术方案与常用的方案进行了比较,如表2所示。
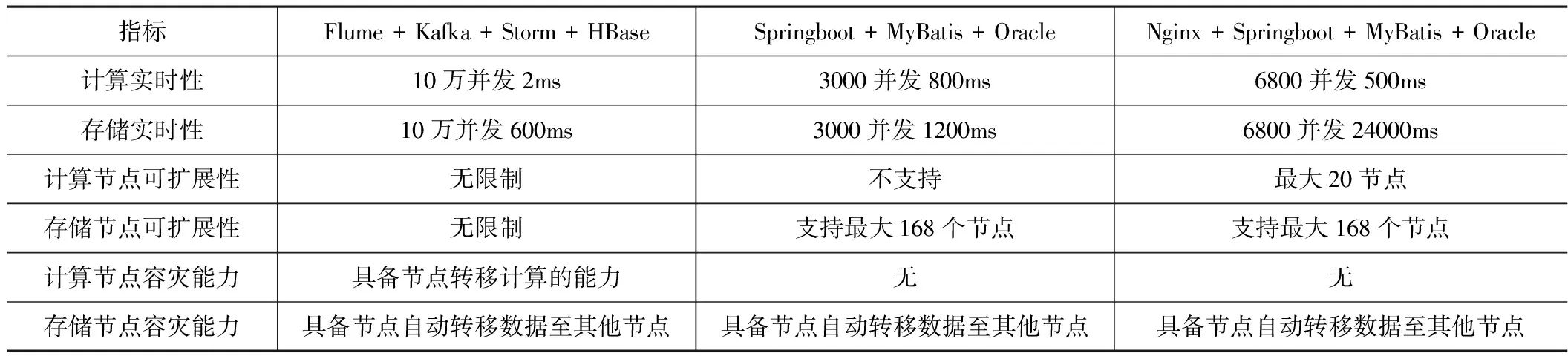
技术方案比较表 表2
经过对比发现,本文技术在实时性、可扩展性、高可用性方面较常用方案有很大的优势。
5 结论与展望
本文采用基于Flume+Kafka+Storm+HBase的大数据技术,实现了电动汽车报文实时分析系统,其优势主要有三点,一是低延时性,保证了车辆分析和预警的及时性;二是高并发性,保证了最大在线车辆监控的性能需求;三是高可用性,在某些基础设施发生故障后,依然可以保证系统的正常运行;四是高可扩展性,为将来电动汽车拥有量越来越大提供了扩展空间。
本文所阐述的技术与系统不仅仅能应用在电动汽车领域,也可应用在其他有高实时性需求的行业。
