基于注意力机制的多曝光图像融合算法
2022-05-07白本督李俊鹏
白本督,李俊鹏
(西安邮电大学通信与信息工程学院,西安 710121)
0 引言
自然场景有宽广的动态范围,如微弱星光亮度约为10-4cd/m2,恒星强光亮度范围为105~109cd/m2[1],通过数码单反相机拍摄记录时,往往因为数码相机动态范围受限,导致拍摄的照片出现过曝光和欠曝光[2]。高动态范围(High Dynamic Range,HDR)成像技术旨在扩大图像动态范围,解决由数码相机动态范围受限无法捕获高动态范围图像而产生的问题[3]。目前,生成高动态范围图像的方法大致可分为两类:基于辐照域的多曝光HDR 图像生成方法和基于图像域的多曝光HDR 图像融合(Multi Exposure Fusion,MEF)方法。基于辐照域的多曝光HDR 图像生成方法连续捕获一组不同曝光量的低动态范围(Low Dynamic Range,LDR)图像集合,实现目标场景动态范围的涵盖;然后通过求解相机响应函数(Camera Response Function,CRF)将该组不同曝光的LDR 图像集合在辐照域合成一幅HDR 图像;最后将HDR 图像直接在HDR 显示器上进行显示或者将HDR 图像经过色调映射显示在LDR 显示器[4]。基于图像域的多曝光HDR 图像融合方法使用多张涵盖目标场景动态范围的低动态范围图像集合,利用图像融合的方式将具有互补信息多张不同曝光图像直接融合为包含最多信息的单张高动态范围图像[5]。
传统多曝光图像融合算法通过三个步骤获取HDR 图像:首先采用拉普拉斯金字塔分解、小波变换或者稀疏表示等图像变换方法将输入图像转换为特征图;其次,根据定义的融合策略进行特征图融合;最后,通过色调映射得到融合更多信息的HDR 图像[6]。然而,该类算法使用人工设计生成的特征图进行图像融合,对不同的输入图像不具有鲁棒性,因此随着输入图像的改变其融合质量也受到相应的限制。
近年来,众多学者利用卷积神经网络(Convolutional Neural Network,CNN)解决传统多曝光图像融合方法不能自适应学习图像特征的不足。基于卷积神经网络的MEF 通过构建神经网络层将图像特征分层表示,从而有效提取过曝和欠曝图像局部和全局的特征信息。基于卷积神经网络图像融合主要理论研究可大致分为三类[7]:1)将传统方法与卷积神经网络相结合。例如,2016年LIU Y 等[8]提出基于卷积稀疏表示的图像融合算法,该算法的利用提出的卷积稀疏表示模块对源图像序列分解的基础层和细节层分别进行处理,然后将处理后的基础层和细节层相结合得到融合图像。该类方法利用CNN 自动提取源图像序列的特征信息,实现高低频特征信号的剥离并且对所分离的特征信号进行增强,但最终的融合规则仍需要人为设计,因此,仍然存在传统方法的局限性。2)将卷积神经网络视为一种生成权重图的方式,权重图表示了每个像素的有效性。例如,2018年LI H 等[9]提出基于预训练的CNN 模型算法,通过引入预训练的VGGNet 网络解决图像特征提取的问题,并根据提取的特征计算源图像序列的融合权重值,以构建融合图像。2020年MA K等[10]提出MEF-Net 模型,MEF-Net 的核心思想是将任意空间分辨率和曝光次数的静态图像序列进行下采样,通过卷积神经网络提取图像,再将所提取的图像特征通过引导滤波和联合上采样映射成原图大小的融合权重图,通过加权融合的方式得到融合图像。该类方法本质为像素加权融合,像素级MEF 对权重图直接融合往往会引入噪声,导致融合图像失真[11-12]。3)基于CNN 的MEF 端到端学习的方法。2017年PRABHAKAR K R 等[13]使用MEF-SSIM 无参考质量评价指标作为损失函数设计了第一个基于卷积神经网络的无监督多曝光图像融合模型DeepFuse,实现基于神经网络的MEF 端到端的学习。2020年XU H等[14]在FusionGAN[15]的基础上提出了基于MEF-GAN 的端到端多曝光图像融合,MEF-GAN 将生成对抗网络应用于多曝光图像融合,并首次引入注意力机制,通过判别器区分输入的多曝光图像和融合图像之间的差异,迫使生成器生成的融合图像具有更多过曝和欠曝图像的细节。以上方法实现了MEF 问题的端到端学习,但最终融合结果仍不够理想。此外,尽管基于学习的方法实现了MEF 自适应特征学习,但是其主要缺点在于,目前为止尚未发现一个完美的损失函数可用于融合图像的无监督学习[12]。因此,如何充分利用不同曝光图像欠饱和与过饱和特征信息,设计一个有效的损失函数仍是一个挑战。
针对以上问题,本文提出一种基于注意力机制的多曝光图像融合算法(Attention Multi Exposure Fusion Network,AMEFNet)。该算法针对MEF 数据集无真值图像而无法监督学习的问题,提出一种新的端到端卷积神经网络MEF 无监督学习算法;利用权重分离的双通道特征提取模块对目标场景欠曝光和过曝光图像进行特征提取,获得纹理信息表征能力强的特征图;将注意力机制引入到多曝光图像融合任务中,从局部到全局对欠曝光和过曝光图像的局部细节和全局特征进行聚焦,突出对融合有利的图像特征;为了更精确重建融合图像,以L2范数和结构相似性SSIM 作为神经网络的约束准则设计损失函数,获得源图像序列和融合图像之间更小的相似性差异,实现神经网络模型更精准的收敛。AMEFNet 充分利用并融合了源图像序列亮度信息与欠饱和与饱和区域图像纹理细节,改善了融合图像细节丢失、失真等问题。
1 多曝光图像融合深度学习模型
本文设计的基于注意力机制的多曝光图像融合算法网络框架由特征提取模块(Feature Extraction Module,FEM),注意力机制模块(Attention Module,AM)以及特征重建模块(Feature Reconstruction Module,FRM)三个核心计算模块组成,AMEFNet 网络结构如图1 所示。首先,将目标场景欠曝光和过曝光图像作为两个独立参数分别输入到结构相同的特征提取模块中,获得欠曝光和过曝光的高维特征图。随后通过注意力机制模块突出融合有利的图像特征,抑制欠饱和、过饱和等低质量区域的特征,得到重建融合图像所需的纯净高维特征。FRM 将AM 输出的不同曝光图像的高维特征重建为高动态范围图像。最后利用所设计的损失函数约束神经网络,提高模型的泛化能力。
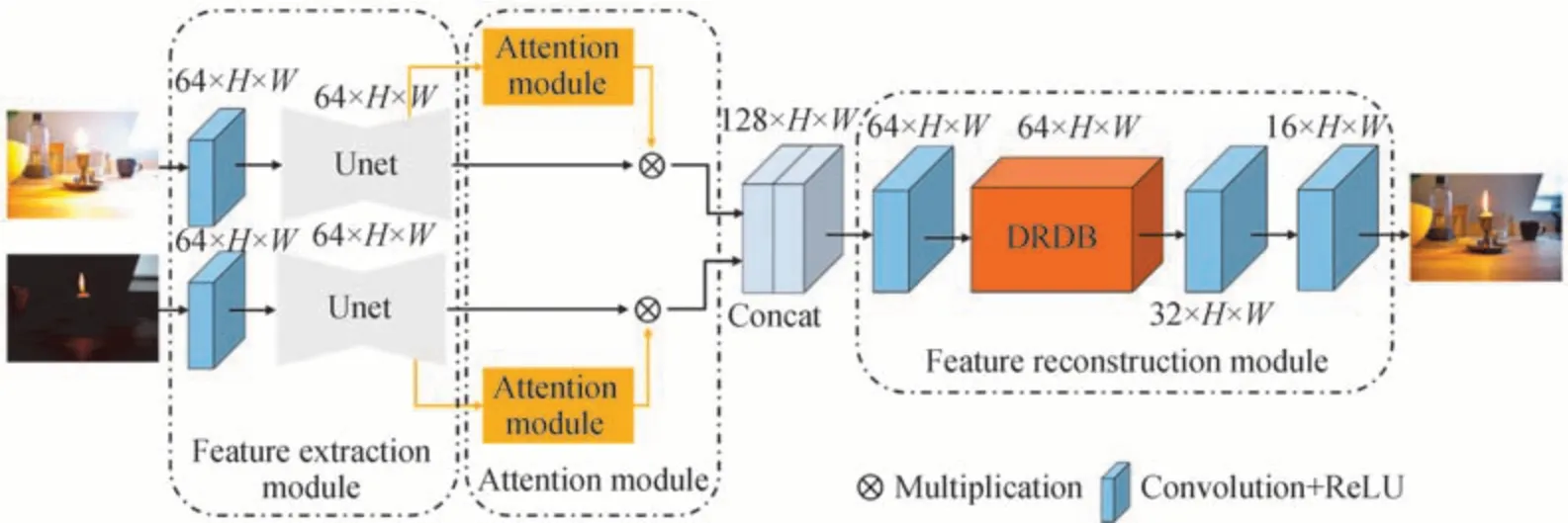
图1 AMEFNet 网络结构示意图Fig.1 Network structure of AMEFNet
1.1 AMEFNet 网络框架
1.1.1 特征提取模块
在进行多曝光图像融合之前,需要对欠曝光和过曝光图像进行特征提取。以图2 所示的Unet 网络作为AMEFNet 特征提取基础网络架构。

图2 AMEFNet 特征提取网络结构Fig.2 Feature extraction network structure of AMEFNet
特征提取模块由独立的卷积层和Unet 网络构成,其中Unet 网络包含卷积,下采样,池化,上采样以及拼接操作。首先使用3×3 大小的卷积核在提取低层图像特征的同时,将256×256 尺寸的输入图像转化为64通道的高维特征,并利用Unet 网络实现图像特征的多尺度特征提取,将浅层图像特征以及深层语义特征通过特征拼接方式堆叠,为保留图像结构和纹理特征提供了有效的解决方案。Unet 网络完成特征的精细提取后,输出64 通道的高维多尺度特征图,该特征图作为后续注意力机制模块的输入源。
由于欠曝光和过曝光图像在曝光时间上存在差异,同一场景不同曝光图像中的物体具有信息互补,以及亮度,色度,结构对应关系复杂的特点对。若将不同曝光图像直接融合,经过同一网络进行特征提取,生成的共享权值会破坏目标场景不同曝光图像的固有特征。因此,本文在特征提取模块上采用双通道架构,使用结构相同但不共享任何学习参数的特征提取模块,对欠曝光和过曝光图像同时训练。
1.1.2 注意力机制模块
不同曝光图像含有目标场景不同的局部细节特征,为保留多曝光图像丰富的细节信息,凸显融合有利的兴趣特征,抑制非兴趣特征,以校正融合图像局部失真和信息丢失,采用图3 所示的注意力机制模块针对不同的曝光图像生成相应的有益特征图。

图3 AMEFNet 注意力机制网络结构Fig.3 Attention network structure of AMEFNet
注意力机制模块分别对Unet 网络输出的不同曝光图像的特征图进行Squeeze 操作,采用全局平均池化方式将通道空间特征编码为全局特征,计算公式为
式中,i,j表示像素点坐标,Fsq(·)为Squeeze 操作,xc为C维度特征输入。之后对全局特征zc采用Excitation操作,为了降低模型复杂度以及提升泛化能力,采用两个全连接操作,全连接之间使用ReLU 激活函数进行非线性处理,最后通过归一化函数Sigmoid 输出权值向量,Excitation 操作使得网络学习各通道间的关系,也得到不同通道的权值,Excitation 操作计算方式为
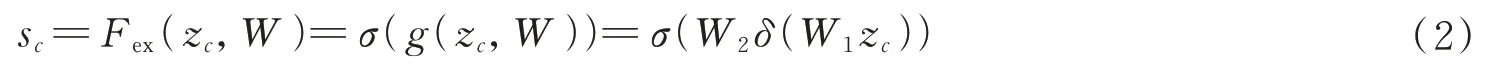

1.1.3 特征重建模块
完成不同曝光图像的高维特征过滤后,通过拼接操作保留过曝和欠曝图像的高维图像特征得到特征图F0,再以图4 所示的特征重建模块将拼接的特征重建为高动态范围图像。
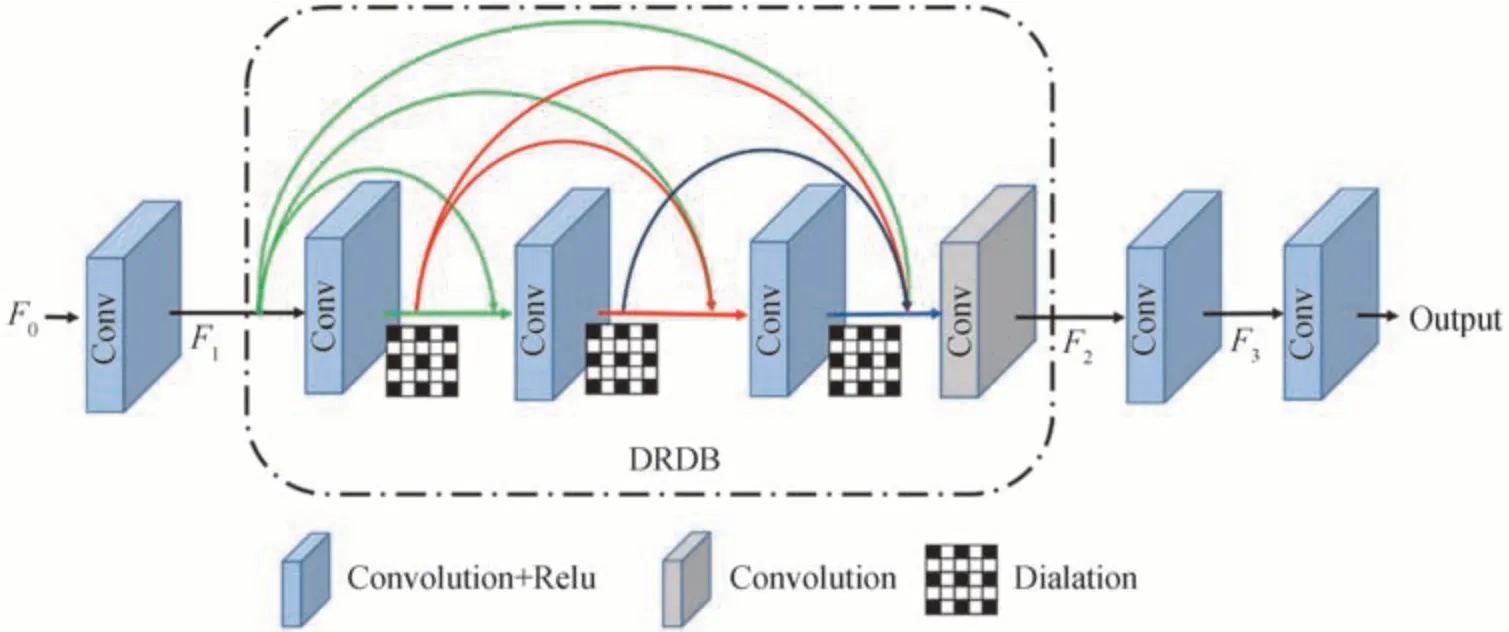
图4 Unet 特征重建网络结构Fig.4 Feature reconstruction network structure of Unet
特征重建模块由3 个独立的卷积层与1 个扩张残差稠密单元(Dilation Residual Dense Block,DRDB)组成。首先第1 个卷积层将拼接的特征图F0转化成64 通道的特征图F1,其次将特征图F1提供给DRDB 单元输出特征图F2,其中DRDB 单元是基于扩张卷积改进残差稠密单元(Residual Dense Block,RDB)得到的,所使用的DRDB 充分利用不同网络层级的图像特征,在保留LDR 图像细节信息的同时利用更大的感受野去推测饱和区域丢失的细节[16]。此时F2已有足够的信息去重建高动态范围图像,最后利用2 个卷积层依次卷积特征图F2得到特征图F3和高动态范围图像。
1.2 损失函数
损失函数决定了所提取的图像特征类型以及不同类型的图像特征之间的比例关系[12]。为了满足融合图像在包含不同曝光图像细节和结构信息的同时,又符合人眼的视觉感知特性的要求。本文设计了基于L2范数的内容损失和基于SSIM 的结构损失的多损失函数。
结构相似性度量指标SSIM 从亮度,对比度和结构三方面衡量源图像与融合图像相似性程度。设x为输入图像,y为输出图像,其数学表达式为
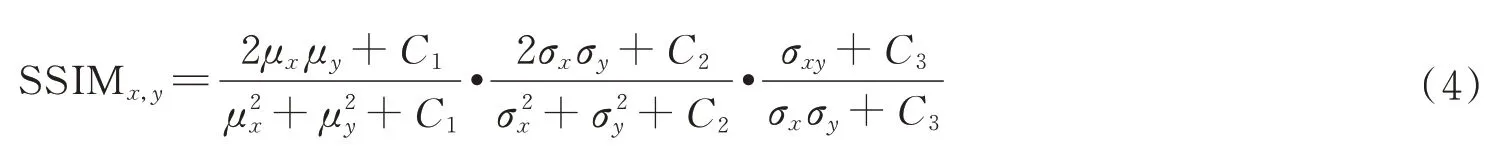
式中,μ和σ分别表示均值和标准差,σxy表示x,y的协方差,C1,C2和C3为常数系数。以结构相似性SSIM 为基础,针对多曝光图像融合任务设计子结构损失LSSIM,O,U和F分别表示过曝图像,欠曝图像以及融合图像,则LSSIM的数学表达式为

SSIMO,F,SSIMU,F分别表示过曝图像O和欠曝图像U与融合图像F的结构相似性。在多曝光图像融合任务中,过曝和欠曝图像的具有相同的纹理细节,但其亮度强度过大或过小。所以对权重系数αO和αU设置相同的权重进行平衡,以获得适当大小的亮度强度和纹理细节,可表示为

内容损失Lcontent在保证多曝光图像序列和融合图像的纹理细节信息失真最小的同时避免了噪声的干扰,内容损失的计算表示为

式中,计算输入图像x与输出图像y像素点之间的欧式距离,其中为L2范数。内容损失可以定义为

与结构损失相似的,βO和βU具有相同的权重系数。为实现结构损失函数与内容损失函数之间权值平衡,通过赋予结构损失相应的超参数λ提高模型的泛化能力。综上,AMEFNet 整体损失函数可表示为

2 实验及结果分析
2.1 实验环境及相关参数
本文基于CAI J 等[17]提供的公共可用数据集SICE 进行无监督学习的训练。其中训练数据集包含589组不同曝光的LDR 图像集合。训练硬件平台为配置为Inter(R)Core(TM)i5-9600k 3.7GHz CPU 和NVIDIA Geforce RTX 2080ti GPU 的PC,配置环境为Unbuntu18.0.4,网络模型的编写语言为python3.7,配合Pytorch1.5 与Opencv3.2 作为辅助高级API,并且选用Adam 优化器以参数β1=0.9,β2=0.999,初始学习率为10-4,学习率每迭代50 次便以0.5 倍进行衰减,进行模型优化。
通过图5 可以看出,AMEFNet 在训练过程损失函数具有较好的收敛,未出现梯度消失或梯度爆炸情况,验证了所设计的多曝光图像融合模型的合理性与可行性。完成多曝光图像融合模型训练后,为验证本文算法模型的有效性,本文选取ZHANG X[12]提供的基准数据集MEFB 部分图像作为测试集,其中包含室内、室外、白天和黑夜等静态场景,涵盖了广泛的真实环境,更能展现出真实场景信息。为比较所提算法和其他算法的性能,选取三种传统算法:GFF 算法[18],DSIFT 算法[19],SPD-MEF 算法[11]和两种基于深度学习的算法:MEFNet 算法[10],MEF-GAN 算法[14]从主观和客观两种不同维度进行比较。上述算法的融合图像均由公共可实现代码生成,并且基于深度学习的训练模型由原作者提供。
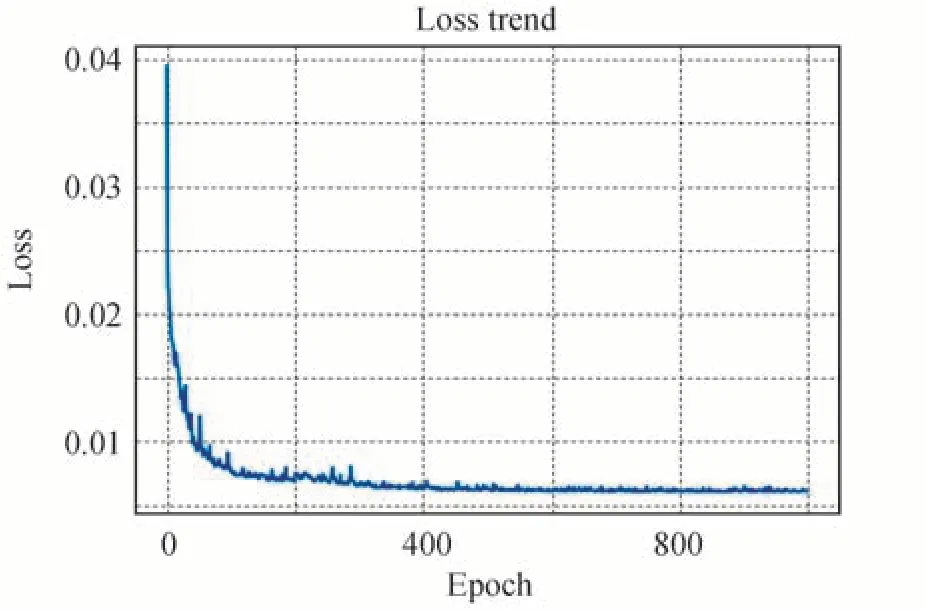
图5 AMEFNet 损失函数曲线Fig.5 Loss function curve of AMEFNet
2.2 主观评价
首先从视觉感知的角度对不同融合算法进行主观对比分析,House 多曝光图像序列,TableLamp 多曝光图像序列的融合结果效果图如图6、图7 所示。

图7 TableLamp 图像序列算法结果比较图Fig.7 Comparison of TableLamp sequence algorithm results
图6 为House 图像序列融合结果,图6(a)、图6(b)为源图像,图6(c)、图6(h)为不同算法融合结果。由图6(c)、图6(d)可知,与原图像序列相比,GFF 和DSIFT 处理后的融合图像,虽然能有效提高图像质量,但仍然存在部分区域图像失真的现象,如图6(c)、图6(d)中红色框区域,过曝图像中亮度最强区域融合图像具有明显的暗区;SPD-MEF 算法整体过于明亮,如图6(e)红色框区域可以看出,在窗外部分可视信息模糊,视觉效果欠佳;通过图6(f)红色框区域可以发现,MEFNet 存在亮度不均匀的问题,导致融合图像细节不清晰,亮度失真;而图6(g)中,MEF-GAN 算法可以较好均衡亮度信息,但图像局部出现了失真现象,如图6(g)红色框区域,远景树木和门框轮廓都出现伪影现象。而本文算法(h)在保持高清晰度和对比度的同时,有效避免了亮度不均匀和局部区域细节失真的问题。

图6 House 图像序列算法结果比较图Fig.6 Comparison of House sequence algorithm results
图7 为Table Lamp 图像序列融合结果,图7(a)、图7(b)为源图像,图7(c)、图7(h)为不同算法融合结果。通过图7(c)、图7(d)可以看出,GFF 和DSIFT 算法虽然能较好提升视觉效果,但局部区域仍存在亮度偏低的问题,如图7(c)、图7(d)红色框区域中台灯后的墙体具有明显的暗区;SPD-MEF 算法虽然获得更好的视觉增益,但部分区域原始结构信息有所丢失,如图7(e)蓝色框标注区域中台灯的轮廓出现伪影现象,导致融合图像缘结构信息丢失;MEFNet 算法处理后的融合图像细节和色彩信息具有明显的改善,但如图7(f)红色框区域所示,MEFNet 具有与GFF 和DSIFT 相同的问题,存在局部暗区,明暗过度不平滑;由图7(g)所示MEF-GAN 算法的融合图像存在较为严重的失真现象,如图7(g)红色框区域中花朵和台灯区域出现伪影,导致融合图像不够生动自然,视觉效果欠佳;由于过曝图像相比于欠曝图像具有更大的亮度数值,因此过曝图像在多曝光图像融合中具有更高的权重比,导致上述算法局部区域亮度过度不够自然,如绿色框所示,而本文算法7(h)在一定程度上解决了上述算法的缺点,使得融合图像更加清晰,亮度过渡更加自然。
2.3 客观评价
由于人眼的主观感受判断融合结果存在一定的误差,融合图像在保留欠曝光与过曝光图像的梯度信息和空间频率信息,同时融合图像要尽可能自然,使人眼能够快速、准确的从融合图像获取综合信息,因此本文选用峰值信噪比(Peak Signal Noise Ratio,PSNR)、平均梯度(Average Gradient,AG)、空间频率(Spatial Frequency,SF)、信息熵(Entropy,EN)以及视觉信息保真度(Visual Information Fidelity,VIF)进行客观评价。
1)峰值信噪比(PSNR)。PSNR 表示融合图像峰值功率与噪声之间的比值,用于测量融合图像的畸变情况,PSNR 定义为

式中,r表示融合图像的峰值,MSE 表示均方误差。较大的PSNR 意味着融合图像与源图像更加接近,拥有更小的失真,所以PSNR 越大,融合性能越好。
2)平均梯度(AG)。AG 用于量化融合图像的梯度信息,衡量融合图像的细节和纹理信息的保有量,AG定义为

3)空间频率(SF)。SF 通过对融合图像的行频率和列频率求均方得到,反映了融合图像空间频率信息,SF 定义为

4)信息熵(EN)。信息熵作为图像量化标准,反映图像包含的平均信息量多少,定义为

式中,L表示灰度级数,Pl表示融合图像相应灰度的归一化直方图。信息熵大小表示融合图像携带信息量的多少。但是,信息熵很容易受到噪声的影响,因此通常用作辅助指标。
5)视觉信息保真度(VIF)。VIF 是基于人眼视觉信息保真度的质量评价指标,主要通过建立视觉模型计算源图像和融合图像间的信息失真。计算融合图像基于VIF 的总体度量,VIF 值越大,融合性能越好。
为了方便观察,本文将测试集的5 个客观质量评价指标平均得分在表1 中列出(粗体值代表了每列的最佳值)。从表1 中数据可知,本文算法融合图像虽然在PSNR 指标上获得第二高的得分,但最高得分的SPDMEF 算法融合图像具有肉眼可见的伪影现象。而在EN 指标上获得第四高的得分,但得分最高的前三算法融合图像均出现由于融合不完全导致的不同程度黑影,并且本文算法与最高得分的差距仅为2.6%。而本文算法在AG,SF 和VIF 性能指标结果均优于其他对比算法,因此可以表明相比于其它算法本文算法的融合图像蕴含了更多原图像序列的场景细节与边缘信息,符合人眼的视觉感知特性的要求。
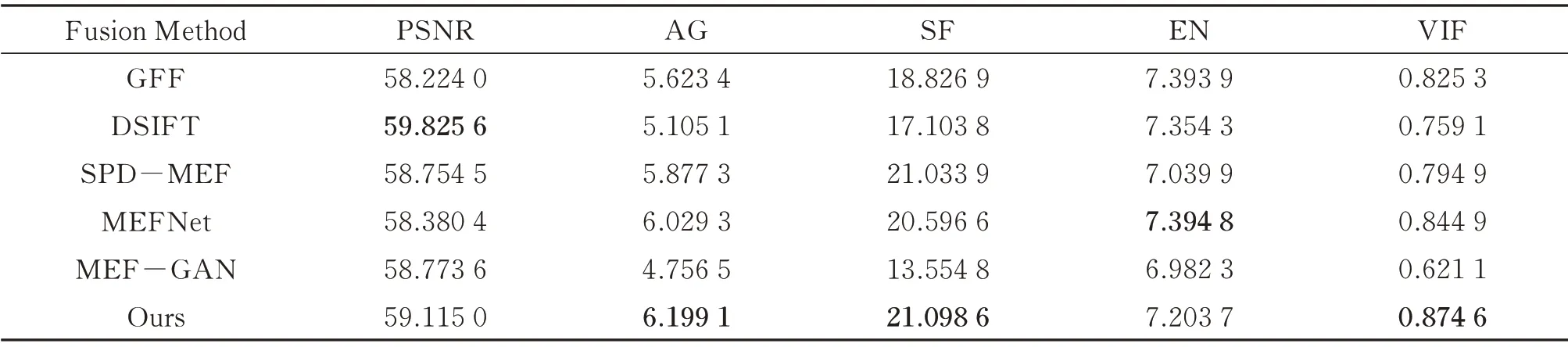
表1 测试集融合图像的5 个客观评价指标的平均值Table 1 The values of five quality metrics averaged over the fused images on test set
2.4 算法复杂度与运行时间
复杂度是体现算法优劣的一个重要指标。因此,在这一节中,将对MEF 算法的时间复杂度进行讨论。设m表示图片的行数,n表示图片的列数,N表示源图像序列中的图像数量,因此传统算法的复杂度均为O(Nmn)。对于深度学习算法将以具体的浮点运算数(Floating Point Operations,FLOPs)进行比较,FLOPs主要衡量模型的复杂度,FLOPs 值越大,模型需要更多的运行时间,因此模型的复杂度越大,其中1GFLOPs表示109次浮点运算。不同算法复杂度将在表2 列出。从表2 中可以看出,本文的FLOPs 值最大,这是由于特征重建层中使用了扩张残差稠密单元,扩张残差稠密单元的使用提高了AMEFNet 网络图像重建的性能,但代价是算法复杂度的增加。
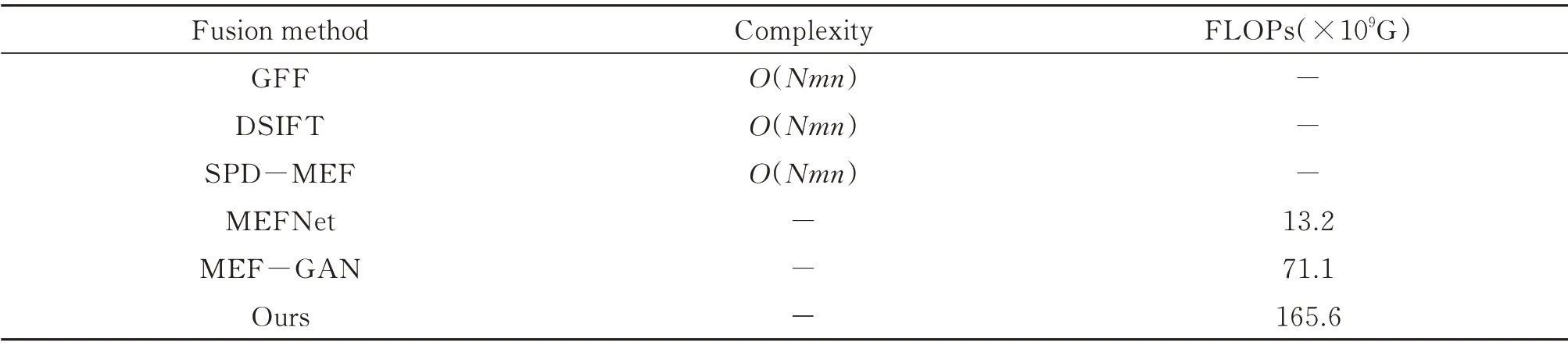
表2 不同算法的复杂度Table 2 Time complexity of the different algorithm
为更直观的评估算法复杂度,将不同分辨率多曝光图像序列在不同算法运行时间在图8 进行绘制,其运行时间测试平台为i5-8265u CPU 环境。从图8 可以看出,本文算法的运行速度快于SPD-MEF 与DSIFT两种传统算法,但慢于MEF-Net 与GFF 两种算法,其中MEF-Net 运行最快,而在低分辨率图像运行时间比较中,本文算法与MEF-GAN 算法运行时间接近,但是本文算法的融合结果相比于MEF-GAN 具有更好的鲁棒性,比MEF-Net 与GFF 算法具有更高的饱和度,更好的视觉效果。综上所述,本文算法的复杂度适中,能够较好融合不同曝光图像。
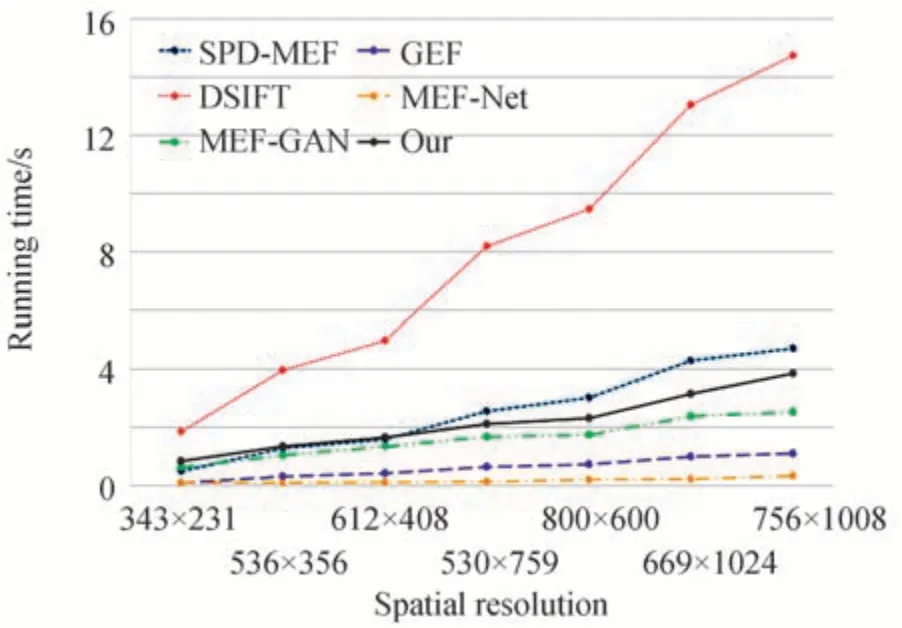
图8 不同算法的运行时间比较Fig.8 Comparison of running time
2.5 消融实验
为验证所提AMEFNet 网络框架在多曝光图像融合任务中的有效性,从两个方面进行消融性分析:1)证明注意力机制模块的有效性;2)证明超参数λ的有效性。从上述两个方面,设计具有相同设置的基本网络用于探索不同模块的有效性。设计网络分别称之为:RAMEFNet(移除AMEFNet 中的注意力模块)和AMEFNet-λx(网络结构与AMEFNet 一致,不同之处在于超参数λ数值)。
2.5.1 注意力机制有效性实验
AMEFNet 中引入注意力机制模块,从局部到全局的方式聚焦于目标场景不同曝光图像的细节特征,从而校正融合图像局部失真和图像畸变,得到更好的融合效果。为验证注意力机制的有效性,将AMEFNet 的注意力机制模块移除,即将图1 中的AM 模块移除,称之为RAMEFNet,其余设置与AMEFNet 保持一致。
在主观评价中,图9 展示了Studio 图像序列有无注意力模块的可视化结果。其中图9(a)、图9(b)为欠曝和过曝图像,图9(c)是MEF-Net 融合结果,图9(d)是AMEFNet 融合结果。从图9可以明显看出,RAMEFNet 虽然能融合过曝和欠曝图像部分互补信息,但在部分区域存在细节模糊的问题,如图9(c)中红色框区域灯泡未显示出应有的轮廓信息以及远景树木存在一定程度的模糊现象。RAMEFNet 与本文算法相比,本文算法融合结果不仅能够融合不同曝光图像的细节信息而且图像整体更加自然,这是因为注意力模块能够有效聚焦源图像序列的局部细节和图像特征避免细节丢失等现象发生。

图9 Studio 图像序列各融合结果Fig.9 Exposure fusion results of Studio sequence
在客观评价中,表3 展示了有无注意力模块在PSNR,SF,AG,EN 和VIF 五种客观质量评价指标下的结果。从表3 可以看出相较于RAMEFNet,对于测试集,AMEFNet 均取得了最优结果。表明AMEFNet 的融合图像具有更多图像细节和纹理信息,更符合人眼的主观视觉特性,这也与可视化结果相匹配。

表3 有无注意力模块的5 个客观评价指标的平均值Table 3 Evaluations of attention module on five quality metrics average
在运行时间比较中,图10 展示了有无注意力机制在不同分辨率多曝光图像序列的运行时间。从图10中可以看出去除注意力机制模块后减少了相应网络的参数,增快了RAMEFNet 运行时间,但是RMEFNet运行时间与本文算法相差不大,并且本文算法融合结果能够保留更多的图像细节,进一步说明了注意力机制在本文算法应用的有效性。
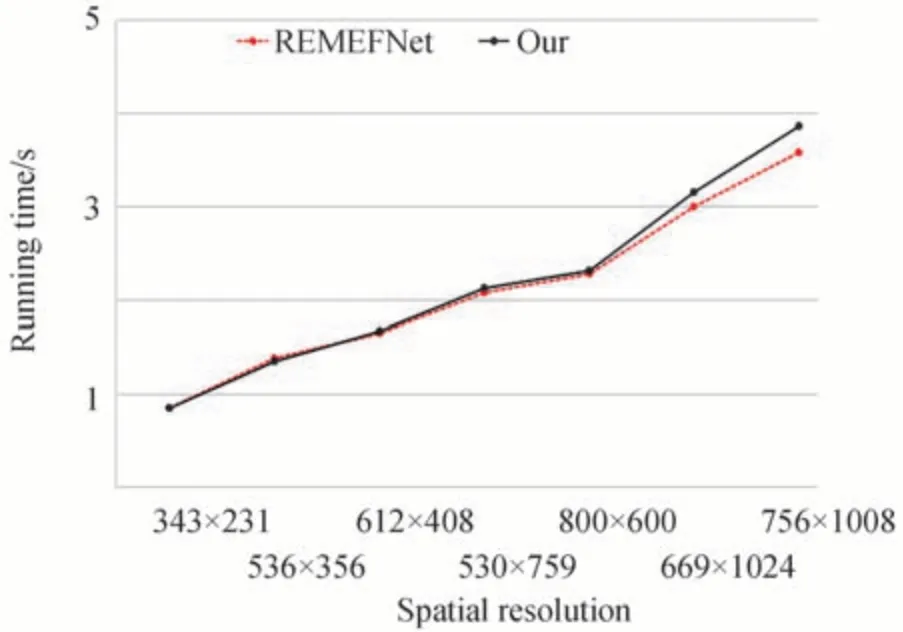
图10 不同算法的运行时间比较Fig.10 Comparison of running time
2.5.2 超参数λ有效性验证
在1.2 小节介绍了损失函数的设计,除了使用经典的L2范数作为内容函数之外还引入了基于SSIM 的结构损失,为验证不同超参数λ对网络的影响,将AMEFNet 中超参数λ设置为不同的数值,称之为AMEFNet-λx。
由于融合结果相近,图像视觉感知效果几乎一致,因此对超参数λ的有效性不做主观分析。在表3 展示了不同超参数λ在PSNR,SF,AG,EN 和VIF 五个客观评价指标上的结果。从表4 可以看出当超参数λ太高或太低时,融合图像在一定程度丢失了部分细节信息,导致融合图像指标偏低,而中间值λ=0.2 的融合图像拥有更多梯度和细节信息在五个指标中占据了三个最优结果,因此本文将λ=0.2 作为AMEFNet 网络默认设置。

表4 不同超参数λ 的5 个客观评价指标的平均值Table 4 Evaluations of different hyperparameter λ on five quality metrics average
3 结论
本文提出了一种基于注意力机制的卷积神经网络(AMEFNet)用于多曝光图像融合。AMEFNet 引入了注意力机制模仿人类视觉机制,从过曝和欠曝图像中突出对融合有利的图像特征;此外,为了捕获更多源图像序列的结构和内容信息构建基于L2范数和SSIM 的多损失函数。上述操作使得本文网络可以捕捉更多细节信息,生成质量更好的融合图像。对比实验和消融实验均表明本文所提的AMEFNet 在多曝光图像融合任务中具有显著的优越性。
