基于注意力机制的生物医学文本分类模型
2022-05-06李启行廖薇
李启行,廖薇
上海工程技术大学电子电气工程学院,上海201620
前言
近年来,随着互联网技术的不断发展,如何让数据更好的为人类服务变得越来越重要。医疗机构每天都会涌现出大量的医疗数据资源,仅仅依靠人力已经远远无法对这些数字资源进行有效分类,因此,实现生物医学文本的自动分类已经成为目前医疗健康领域重要的一部分,其中最基本的一个应用就是网络问诊。网络问诊主要是患者通过互联网的方式来查询自身疾病并找寻答案,这个过程涉及到科室选择。如何将患者的疾病文本进行准确的分类,进而为患者正确匹配就诊科室的类别,是目前的一个研究热点。
在对生物医学文本进行分类时所用到的分类模型主要有两大类,第一类是采用支持向量机(Support Vector Machine, SVM)[1-3]、隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)[4-5]和朴素贝叶斯[6]等传统的分类方法,这种方法有两个主要缺点,一是在训练时特征空间稀疏,并且特征的维数较高,这就导致模型的性能偏低,另一个缺点就是在文本特征的提取过程中更偏向于人工提取,整个过程费时费力[7-8]。第二类就是由卷积神经网络(Convolutional Neural Networks,CNN)[9]与循环神经网络(Recurrent Neural Network, RNN)[10]构成的基于深度学习的分类模型,相对于第一类分类模型,该类模型具有很大的应用优势。
本文旨在解决对生物医学文本进行科室分类问题,输入为一系列疾病文本的描述句子,输出为该疾病文本对应的科室类别。为缓解现有文本分类模型架构的局限性,提出一种基于注意力机制的双层次文本分类模型(Dual layer R-CNN,DR-CNN),用于解决医院中预检分诊的科室分类问题。在DR-CNN中,通过层次化的方式,结合词嵌入、双向长短期记忆网络(Bi-directional Long Short-Term Memory, Bi-LSTM)、双向门控循环单元网络(Bi-directional Gate Recurrent Unit,Bi-GRU)、注意力机制以及CNN 的优势,来获取生物医学文本中的全局序列信息与局部特征,既考虑了文本的前向和后向上下文依赖关系,又进一步关注了文本中的重要特征。
1 研究基础
文本分类技术是自然语言处理领域的核心内容之一[11],主要任务是将文本快速准确地分配到对应的标签。目前,随着深度学习方法的不断发展,深度学习模型在文本分类上的应用取得了很好的进展[12-14],在意图识别、问答系统以及舆情分析等多个领域都有着广泛的应用[15-17]。
CNN 与RNN 在对疾病文本进行文本分类的相关研究中较为常见,这是由于CNN 可以提取疾病文本中的局部特征,RNN 可以提取疾病文本中的全局序列信息。尽管RNN 适用于对文本特征的提取,但是当文本数据中存在长期依赖关系时,会出现梯度爆炸或消失的问题[18],为解决这一问题,长短期记忆网络(LSTM)和门控循环单元网络(GRU)被引入。同时考虑到上下文,Bi-LSTM 和Bi-GRU 被提出,通过组合前向与后向隐藏层,可以更好地解决顺序建模问题[19]。
刘勘等[20]构建一种基于CNN 的文本分类模型,并将该模型用于辅助解决医院科室分配问题,结果表明了单一深度学习模型的有效性,解决了医院分诊的实际问题。张强强等[21]提出了一种基于CNN和SVM的疾病症状分类模型,模型结合了CNN与SVM的优势,最终通过与传统特征提取方法的对比实验得出,基于深度学习的分类模型具有更高的准确率。陈德鑫等[22]通过构建基于混合深度学习模型CNNBi-LSTM,来探究模型对医疗数据的实体抽取结果,并用对比实验证明了使用混合模型比单模型取得更好的效果。虽然Bi-LSTM 和Bi-GRU 在文本分类中得到了广泛的应用,但它们不能集中提取文本中上下文信息中的重要部分,同时增加了文本特征的维度,使得模型难以优化。
2 DR-CNN模型的构建
2.1 模型结构
本文所提的DR-CNN 模型结构如图1所示,以疾病文本作为输入,科室类别作为输出,实现端对端的中文文本分类任务。整个模型可以分为以下4 个部分。(1)词嵌入层:将分词后的疾病文本向量化表示;(2)第一层次:该部分包括Bi-LSTM+Attention 与Bi-GRU+Attention 两个模块,获取文本序列的上下文语义信息,同时引入注意力机制来关注文本中的重要特征;(3)第二层次:该层次由CNN构成,获取文本序列的局部特征,通过最大值池化降低特征空间的维数;(4)Softmax 层:对融合后的特征进行分类,获取分类结果。
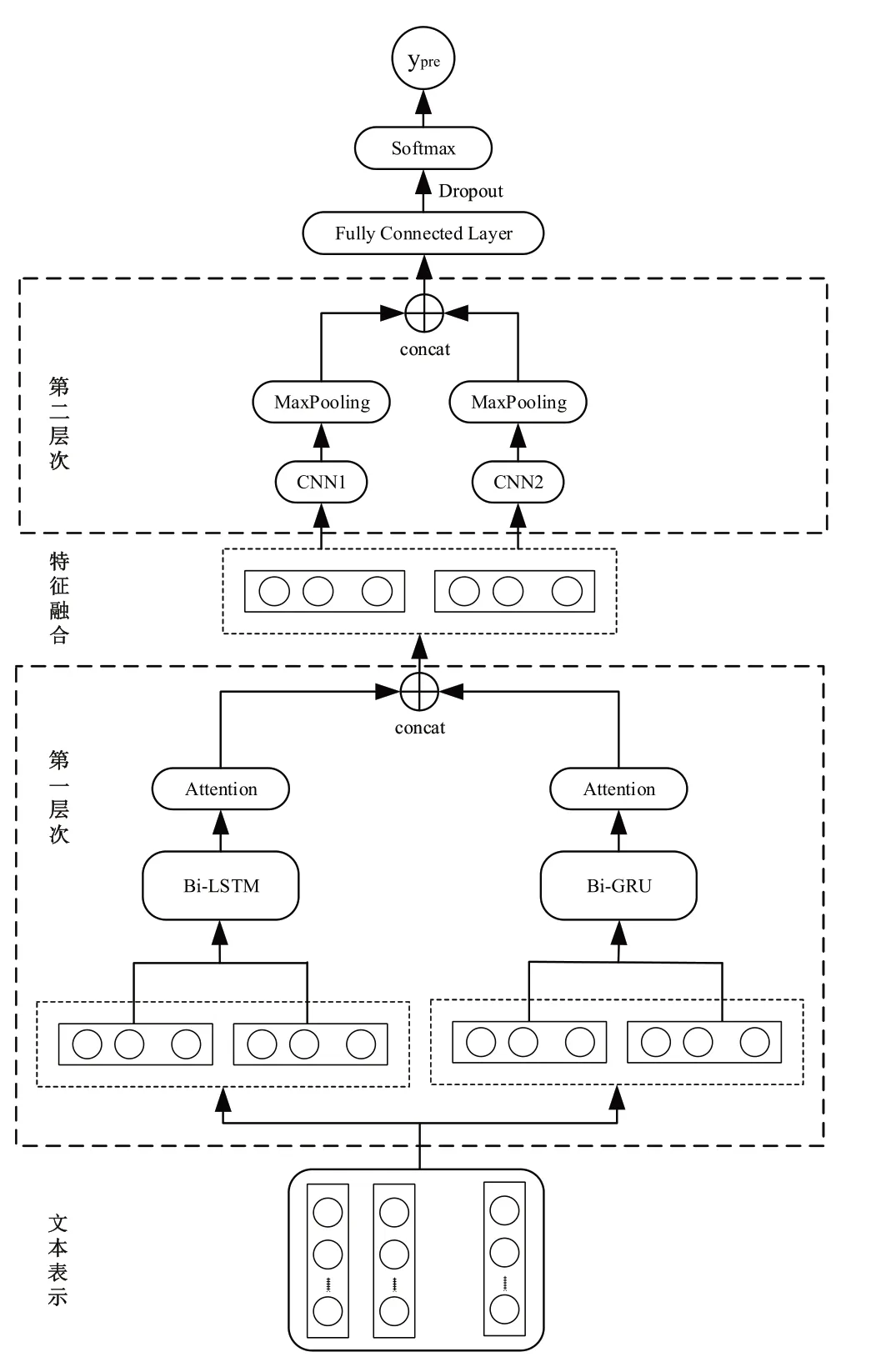
图1 DR-CNN文本分类模型Figure 1 DR-CNN text classification model
2.2 文本表示
词向量的生成方式一般分为两种,一种是随机生成的,另一种是通过神经语言模型学习到的,后者生成的词向量包含了不同词语之间的语义联系,可以进一步增强文本表示的表达能力。本文使用Google 开源推出的Word2Vec 工具包进行词向量训练,Word2Vec 中包含CBOW 和Skip-gram 两个模型,这两个神经语言模型均属于浅层神经网络,在对生物医学文本数据库中的文本使用结巴分词工具处理后,使用Word2Vec中的Skip-gram模型进行词向量的预训练。Skip-gram 模型简单来说就是通过目标词来预测上下文,同时可以学习到词语与词语之间的联系。假设一个句子S的长度为N,整个文本可以向量化表示为下式:

2.3 第一层次
模型的第一层次采用Bi-LSTM 和Bi-GRU 两个并行通道对任意长度的文本序列进行处理,提取出前后两个方向的依赖关系。我们使用GRU 和LSTM同时学习文本的长序列特征和短序列特征,并在两个并行通道中引入注意力机制来强化模型的特征提取能力。
LSTM 是一种特殊的RNN,主要为了解决RNN面临的梯度爆炸或消失等问题。每个LSTM 单元由3 个非线性门组成,包括遗忘门、输入门和输出门,这些门有各自的功能,遗忘门决定从单元中需要遗忘哪些信息,输入门决定将哪些信息更新为单元状态,输出门决定整个单元的哪些部分被输出。整个过程中的节点状态由式(2)~(7)决定:
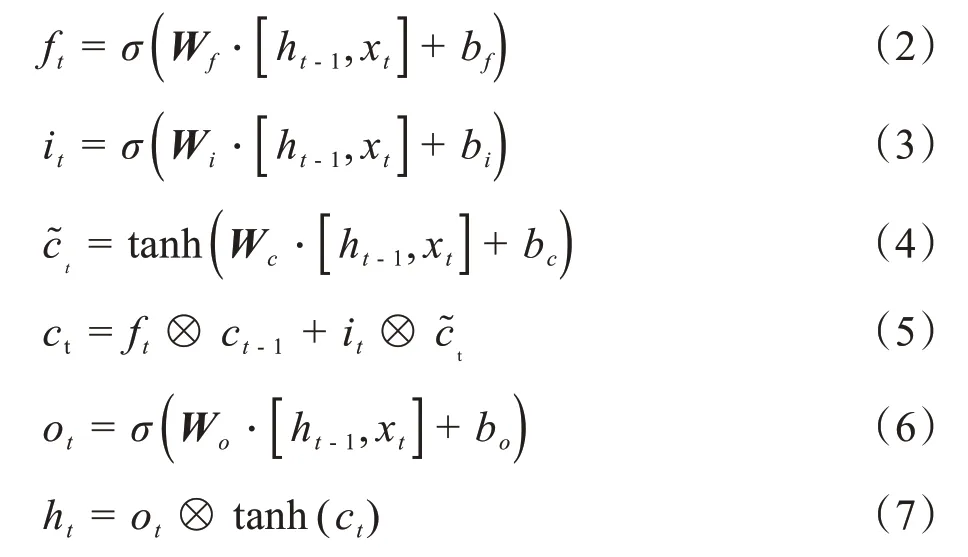
其中,σ表示Sigmoid 函数,ft、it、ot分别表示t时刻的遗忘门、输入门与输出门的节点操作,W为权重矩阵,b为偏置向量,ht-1表示前一步产生的状态,ct-1表示上一步输出的单元状态,ct是当前单元的状态,xt和ht为时间t的输入向量和隐藏状态向量,运算符⊗表示逐元素乘积。
GRU 是LSTM 的一个变体,它只有更新门和重置门两个门,其中更新门结合了LSTM的遗忘门与输入门,GRU 相对于LSTM 来说更简单,更新和重置的过程见式(8)~(9):
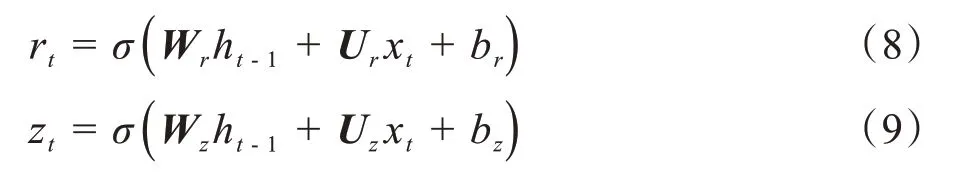
其中,σ为Sigmoid函数,W和U表示权重矩阵,b表示偏置向量,xt为第t层的输入,ht-1表示上一时刻的状态。重置门决定什么时候应该忽略当前的隐藏状态,更新门决定应该传递到当前状态的信息量。候选状态和当前状态ht可以表示为:
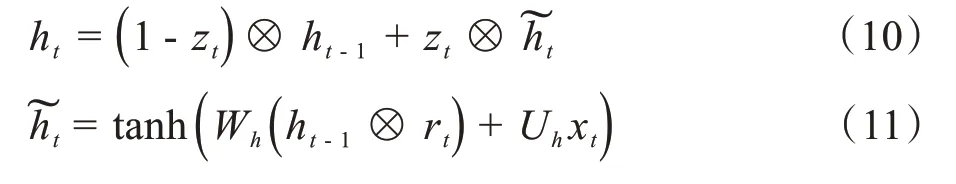
其中,运算符⊗表示逐元素乘积,zt为更新门获取的信息表示当前候选状态,其他同上。
标准的LSTM 与GRU 网络均为单向的神经网络,这就表明当前的状态只能按从前往后的顺序来进行输出,但对于文本数据来说,当前时刻的输出与过去和未来的整体信息均存在联系,因而本文采用包含前向隐藏层与后向隐藏层的Bi-LSTM 与Bi-GRU 来处理两个方向的序列,双向网络结构图如图2所示。Bi-LSTM前向隐藏层的输出为,后向隐藏层的输出为,Bi-GRU 前向隐藏层的输出为后向隐藏层的输出为,则Bi-LSTM 的输出HtL与Bi-GRU的输出HtG可以表示为:

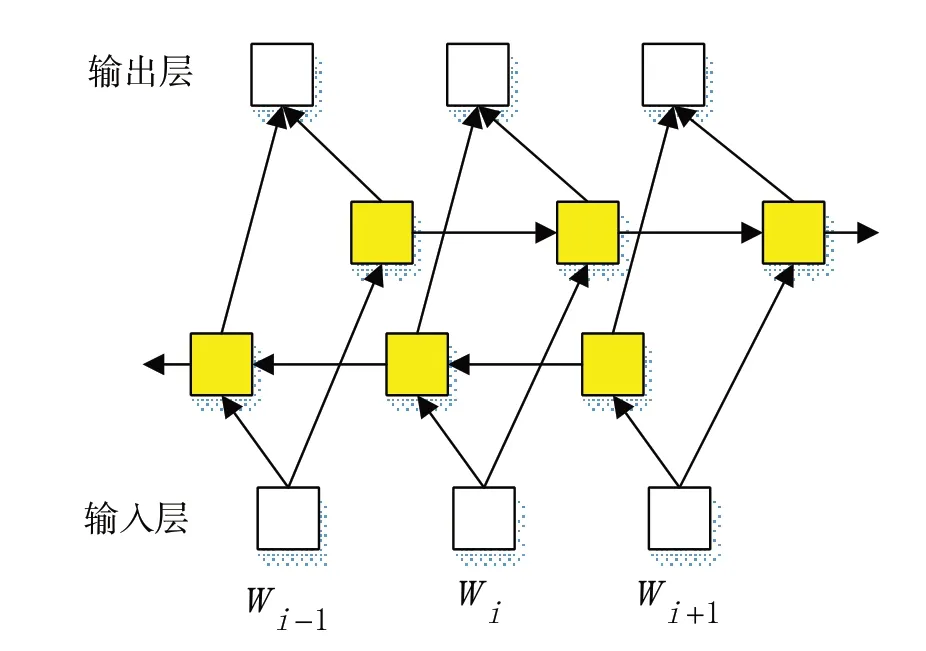
图2 双向网络结构图Figure 2 Structure diagram of bidirectional neural network
注意力机制可以被用来为不同的词赋予不同权重,因为文本中不同的词语对文本所表达的意思有着不同的贡献,不同的权重可以体现出每个词语对整个句子语义的贡献程度。通过注意力机制来捕获句子中词语之间的句法特征或者语义特征,可以进一步提高模型对文本的理解。对Bi-LSTM 和Bi-GRU两个并行层添加注意力机制的数学计算公式如下:
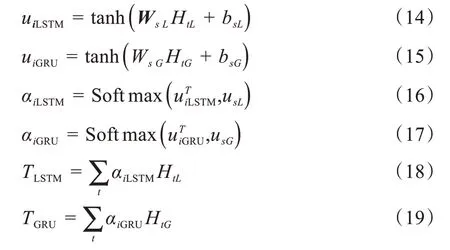
其中,Ws为权值矩阵,ui为Ht的注意力隐层表示,αi是ui通过Softmax 转换后的归一化权值,然后通过将权值αi与隐藏层的输出Ht进行点乘与累加操作,最后将Bi-LSTM 和Bi-GRU 两个并行层的输出进行合并,合并过程如下式,得到第一层次的输出T:
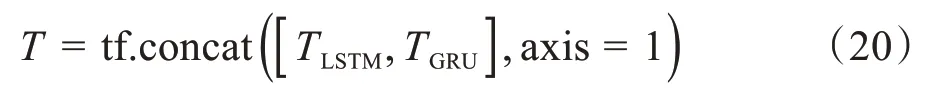
其中,tf.concat 的作用是对TLSTM与TGRU进行拼接操作,axis = 1 表示对TLSTM与TGRU进行横向拼接,不改变词向量的维度,只改变词向量的个数,因而大大增加了模型捕获文本特征的能力。
2.4 第二层次
该层次由CNN 模型构成,CNN 模型主要由输入层、卷积层以及池化层组成,其中卷积层为CNN模型的核心,用于提取局部特征,本模型采用两个不同尺寸的卷积核作为卷积层,分别为CNN1 与CNN2。池化层位于卷积层之后,可以对高维特征进行降维操作,本模型采用最大值池化(Max-pooling)来提取特征值。取卷积核W=[w0,w1,…,wβ-1],卷积过程的数学计算公式如下:
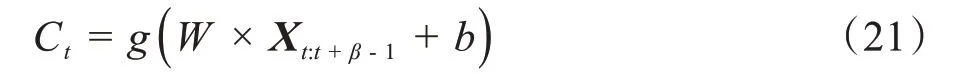
其中,g为非线性激活函数,本模型采用ReLU 激活函数,b为偏置项,t表示卷积核滑动窗口的位置,Xt:t+β-1为窗口从t移动到t+β- 1所包含的词向量矩阵。
将第一层次输出的结果T进行输入,使用两个不同尺寸的卷积核进行特征提取,并通过最大值池化的方法提取出对应的文本特征C1与C2,最后将C1与C2进行拼接操作,可以得到输出向量C:
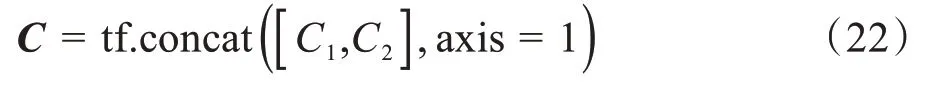
2.5 Softmax层
全连接层将输入的向量特征重新拟合,在全连接层之后引入Dropout 机制,防止训练过程中出现过拟合现象。接着将处理后的向量特征作为Softmax分类器的输入,模型最终由Softmax 分类器输出类别的概率分布。将x分类为类别j的概率公式如下:
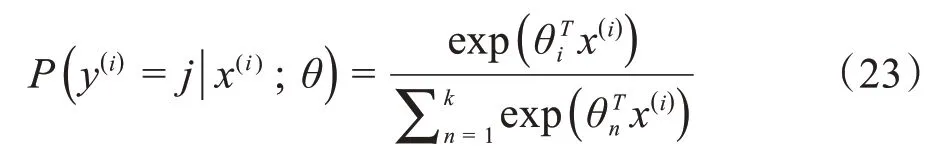
3 性能评测与分析
3.1 实验数据
本文使用中文医疗对话数据集进行实验,用来测试DR-CNN 文本分类模型的分类效果,该数据集来自网络问诊平台,本文选用其中8个类别的样本进行实验,科室类别如表1 所示,每个类别选取5 000 条样板作为训练集,500 条作为验证集,1 000 条为测试集。
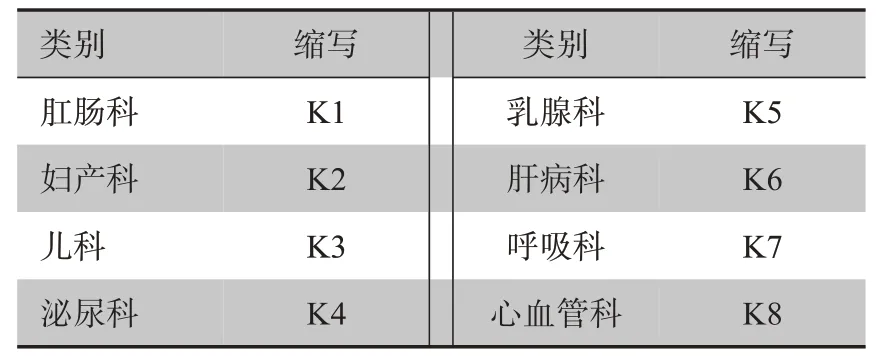
表1 数据集类别统计Table 1 Data set category statistics
3.2 实验平台与参数设置
本文实验环境配置如下:操作系统为Windows10,显卡为Quadro M6000,CPU 使用的是Intel Xeon Silver 4114,开发框架、开发语言以及开发工具分别为TensorFlow-gpu 1.12.0、Python3.6 与Pycharm。
本文模型参数如表2 所示,其中kernel_size 设为(3,4)表示两个卷积核的尺寸分别为3 与4,使用Adam作为模型优化器。
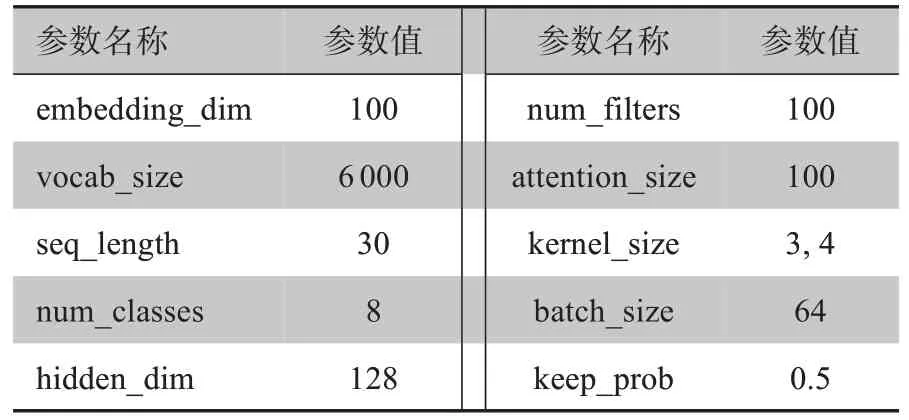
表2 实验参数设置Table 2 Experimental parameter setting
3.3 实验结果与分析
3.3.1 模型性能分析 分类模型的评价指标主要采用准确率(Acc)、精确率(P)、召回率(R)和F1 值。为了验证DR-CNN 模型在生物医学文本分类任务上的分类效果,对DR-CNN 模型及其变体DR-CNN-A 模型进行测试,两者的区别在于后者在第一层次内未引入注意力机制。测试时使两个模型的实验参数保持一致,测试结果如图3 所示,纵坐标为这些类别在测试集上的精确率,单位为%。
通过图3 可以看出,DR-CNN 模型在该项测试中取得了很好的分类效果。其中5 个科室类别的精确率超过了95%,乳腺科与肝病科的分类精确率更是达到了97%以上,只有呼吸科的分类精确率处于85%以下,造成这种状况的原因可以归纳为两种,一是数据集中涵盖了许多专业词语,另一个就是数据集中包含了大量的非正式语言,这都使得模型不能充分的学习到相应的文本特征,从而影响了分类性能。此外,从图3中可以明显的发现DR-CNN 模型比未引入注意力机制的DR-CNN-A 模型具有更好的分类效果,其中妇产科类别的精确率更是提高了4%以上。以上结果不仅证明了注意力机制可以改善模型的分类性能,更是体现了本文模型具有良好的分类效果。
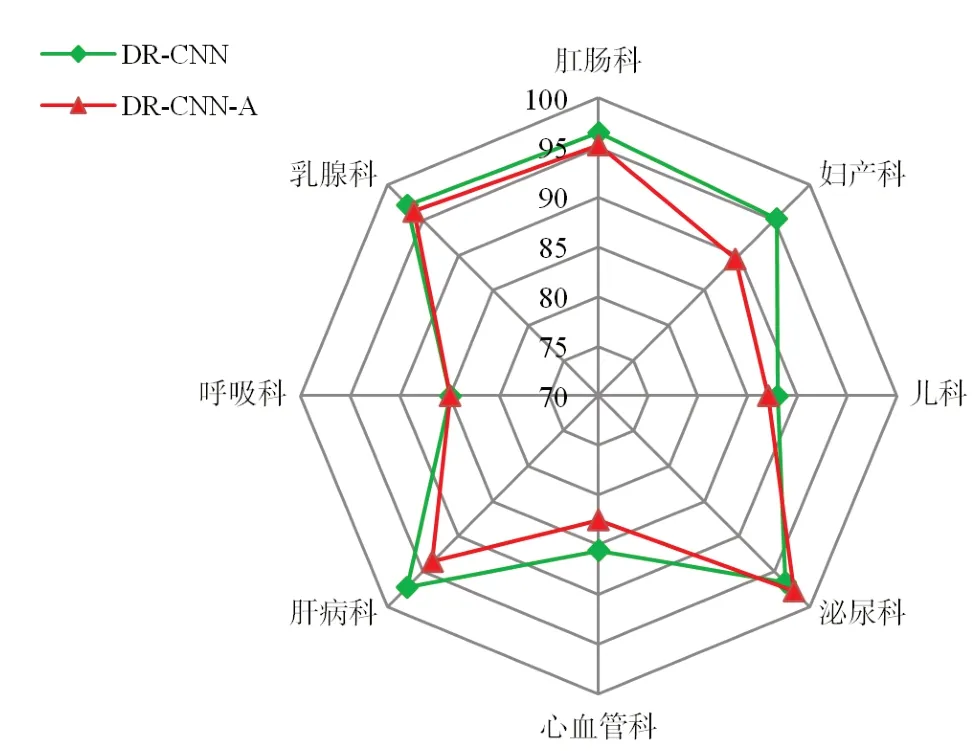
图3 性能测试结果(精确率,%)Figure 3 Performance test results(Precision rate,%)
3.3.2 各层次对模型性能的影响 为了更清楚的探究模型中两个层次对模型性能的影响,本文在中文医疗对话数据集上设置对照实验,分别设置单独的层次一模型与层次二模型,测试结果如表3所示。
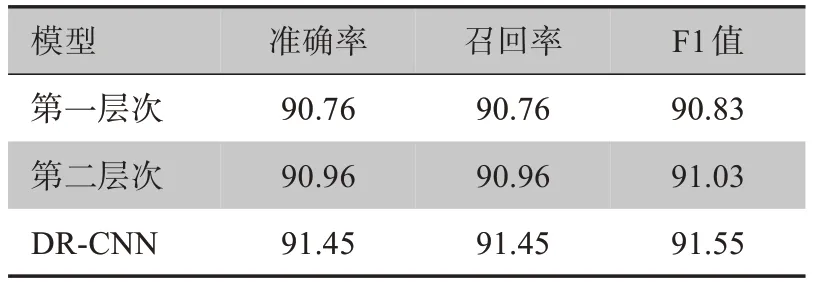
表3 各层次对模型性能的影响(%)Table 3 Effect of each level on model performances(%)
从表3可以看出,使用第一层次和第二层次的单模型对疾病文本进行分类时模型的分类性能偏低,这表明同时使用两个层次对疾病文本进行特征提取时能够学习到更加充分的特征。因此,上述测试结果更能说明本文所提出的DR-CNN模型具有很好的分类可行性。
3.3.3 对比实验分析 为了进一步验证本文所提模型在文本分类方面的性能,本小节设置多个分类模型进行对比实验,实验均在中文医疗对话数据集上进行。本节设置的对比实验,不仅包括了基于深度学习的单模型,也与其他的混合模型进行了对比。基线模型包括:CNN、LSTM、Bi-LSTM[23]、Bi-LSTM+Att 模型[24]、CNN-LSTM 模型[25]、Bi-LSTM-CNN+Att模型[26]。其中Bi-LSTM+Att模型在Bi-LSTM 模型的基础上引入了注意力机制;CNN-LSTM 模型采用单通道的形式将CNN 与LSTM 进行结合;Bi-LSTMCNN+Att 模型结合了Bi-LSTM、CNN以及注意力机制的优势对文本进行特征提取,参数与DR-CNN 中对应参数保持一致。实验结果如表4所示。
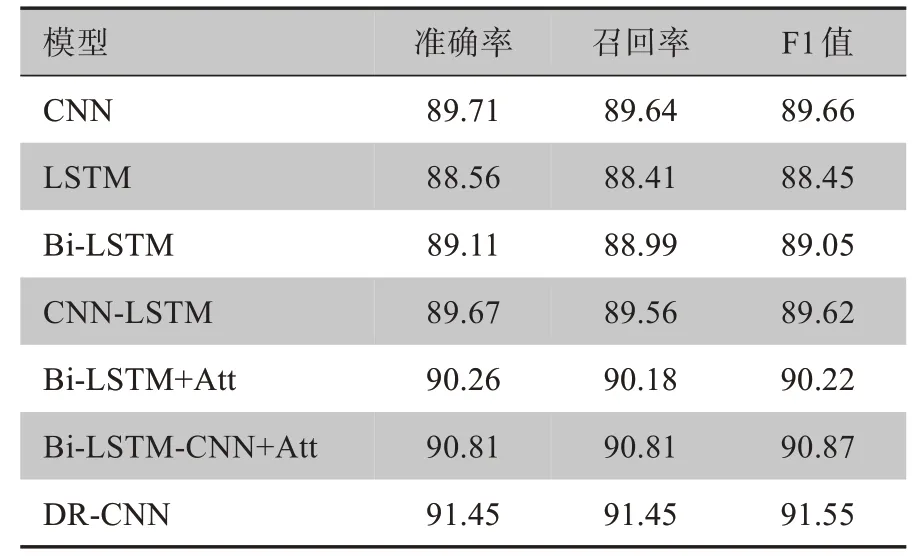
表4 各模型准确率对比(%)Table 4 Comparison of accuracy among different models(%)
从上述结果可以看出,本文所提模型与CNN、LSTM 等基于深度学习的单模型相比,准确率分别提高了1.74%与2.83%,通过比较CNN-LSTM 模型与单模型的分类结果,可以清晰的证明CNN 与RNN 结合后的深度学习神经网络,更能够充分提取文本中的关键特征。对比模型Bi-LSTM+Att 与模型Bi-LSTM的测试结果,分类准确率、召回率以及F1值分别提高了1.15%、1.19%以及1.17%,证明注意力机制的引入可以大大改善模型的分类效果。将本模型DR-CNN的测试结果与模型Bi-LSTM-CNN+Att的测试结果进行对比,DR-CNN 模型的分类准确率、召回率以及F1值高达91.45%、91.45%以及91.55%,模型DR-CNN第一层次是由双层的Bi-LSTM 与Bi-GRU 构成,并在其中引入了注意力机制,对比测试结果,本模型的准确率比Bi-LSTM-CNN+Att 模型提高了0.64%,由此证明了Bi-LSTM 与Bi-GRU 结合后可以显著地提升模型的特征提取能力。综上所述,通过在同一数据集下与基线模型的分类效果进行比较,进一步验证了本文所提出的DR-CNN 模型在进行文本分类任务时有更好的性能。
4 结束语
本文旨在解决对生物医学文本进行科室分类问题,利用深度学习模型,进一步缩小预检分诊时分配对应科室的误差,输入的是一系列疾病文本的描述句子,输出为该疾病文本对应的科室类别。为解决现有文本分类模型架构的局限性,提出一种基于注意力机制的生物医学文本分类模型(DR-CNN)。该模型通过层次化的方式,结合词嵌入、Bi-LSTM、Bi-GRU、注意力机制以及CNN的优势,来获取生物医学文本中的上下文关联信息与局部特征。通过与其他文本分类模型进行对比实验,结果表明,本文所提模型取得了更好的分类效果。在接下来的研究中,可以从数据库的完善、文本分类模型的优化以及分诊系统的构建出发,进一步解决患者初检时能快速找到对应科室的实际问题。