基于近红外光谱技术的普洱茶生熟茶判别及产地溯源
2022-05-06姚春霞蒋智林钱群丽周佳欣宋卫国
刘 星,范 楷,姚春霞,蒋智林,钱群丽,周佳欣,宋卫国*
(1上海市农业科学院农产品质量标准与检测技术研究所,上海 201403;2普洱学院农林学院,普洱 665000)
普洱茶为国家地理标志保护产品,是以云南大叶种茶树鲜叶为原料,经杀青、揉捻、毛茶干燥,再以自然的方式陈放或经过渥堆转熟等制成具有独特品质的普洱茶生茶或熟茶[1]。普洱茶中含有茶多酚、茶多糖、游离氨基酸、咖啡碱等营养活性成分[2-3],具有抗肿瘤[4-5]、抗氧化[6]、降压减脂[7-8]、降血糖[9]等功能,受到不同年龄层次消费者的青睐。普洱茶生茶和熟茶的生产工艺不同,消费者通过肉眼就很容易辨别新茶的生茶(灰绿、墨绿色为主)和熟茶(深褐色或褐红色为主)。但随着贮藏时间的延长,生茶挥发性组分逐渐发生变化[10-11],颜色也逐渐变为深褐色,普通消费者通过感官评价很难识别老生茶和熟茶。由于不同产地普洱茶的营养活性成分、风味物质等组分存在差异[12],普洱茶的价格差距很大,这就为不法商家谋取利益提供了可能[13]。因此,迫切需要建立科学精准的方法,对普洱茶生熟属性和产地进行溯源鉴别。
目前,已有学者利用化学成分分析和近红外光谱技术(NIRS)实现了普洱茶生熟茶的有效识别[12,14-15]。这些前期研究中的样品直接来自普洱茶厂家,虽然保证了样品来源的真实性,但与市场上销售的普洱茶可能存在差异。因为市场茶叶经过运输、仓储的过程,使得普洱茶的组分发生了变化。消费者实际接触到的普洱茶产品与在厂家直接获得的普洱茶,尤其是生茶,在风味上会有一定差异。由于化学成分分析方法一般较繁琐,不能满足市场快速识别的需求,因此,借助NIRS对市场上普洱茶进行生熟茶的识别可能更具有实际意义。
当前普洱茶的产地溯源技术包括信息溯源技术[16]、多元素溯源技术[17]、红外光谱技术[18]、拉曼光谱技术[19]等。信息溯源技术依赖于主观的信息记录真实性,多元素溯源技术测定过程较繁杂,限制了这两种技术在市场监管中的实用性。前期应用红外光谱和拉曼光谱技术进行普洱茶溯源,仅仅是针对熟茶或未区分的生熟茶,所建模型用于市场上实际普洱茶样品(包括生茶和熟茶)产地溯源的适用性有待验证。
近红外光谱主要反映食品各组分中含氢基团振动的倍频和合频,具有快速、无损、绿色等优点[20],已经在普洱茶发酵程度判别[21]、多糖含量预测[22]、真假识别[23]及其他茶类[24-25]的产地溯源上广泛应用。因此,本研究以普洱茶主产区普洱市、西双版纳傣族自治州和昆明市的普洱茶生茶和熟茶为对象,应用NIRS结合化学计量学方法,开展普洱茶生茶和熟茶的判别及不同产地普洱茶的溯源,以期为普洱茶的真实性判定和市场监管提供技术支持和基础数据。
1 材料与方法
1.1 样品采集
于2018年在市场上采集普洱茶样品65个。其中,不同年份的生茶样品23个,不同年份的熟茶样品32个,未知类别普洱茶样品10个。所有样品中,来自普洱市的样品18个,西双版纳傣族自治州的样品18个,昆明市的样品4个,未知产地样品25个。已知类别和产地的普洱茶样品用于建模,未知样品用于模型预测能力的验证。将普洱茶样品用粉碎机粉碎后,过40目标准筛,备用。
1.2 主要仪器与设备
IS50红外光谱仪,配近红外积分球附件(美国Thermofisher公司);FW177型高速万能粉碎机(上海本亭仪器有限公司)。
1.3 光谱采集
采用漫反射积分球模式采集近红外光谱,光谱扫描波数范围10 000—4 000 cm-1,扫描次数32次,光谱分辨率8 cm-1,数据点间隔为0.965 cm-1,近红外光谱数据变量为6 224个,扫描数据由仪器自带的OMNIC软件以吸光度形式存储。每个样品平行试验3次,取其平均光谱作为最终样品光谱。整个试验过程保持室内温度在25℃左右。
1.4 数据处理
为尽可能地利用光谱中的样品信息,在光谱全波长范围内,应用无监督学习算法主成分分析(principal component analysis,PCA)和有监督学习算法偏最小二乘判别分析(partial least squares discrimination analysis,PLS-DA)方法开展普洱茶生熟茶判别和不同产地普洱茶的溯源判别。PCA可以把光谱中的多个变量(总变量数为6 224)转变为少数几个有代表性的综合变量(即主成分),这些主成分含有原始变量的大部分信息,能够代表原始变量,且含有的变量信息互不重叠、互不相关,可以排除变量相关性的影响[26-27];PLS-DA可以借助变量的权重找出不同类别的差异,进而可以对普洱茶的不同类别进行区分[27-28]。PCA和PLS-DA分析过程由SIMCA 14.1软件(瑞典Umetrics公司)完成。
2 结果与分析
2.1 普洱茶生茶和熟茶判别
由图1可知,在近红外谱图的10 000—9 000 cm-1波数处可以清楚地区分大部分普洱茶生茶和熟茶,但在9 000—4 000 cm-1波数,熟茶与生茶出峰位置一致,谱图重叠,难以辨别生熟茶,且存在2个普洱茶熟茶谱图在10 000—9 000 cm-1波数处与生茶谱图重叠,需要借助化学计量学方法进行不同产地生熟茶的识别。如图2所示,在PCA中,取普洱茶生茶和熟茶前两个主成分时,对原变量解释能力(R2X)累积为0.968,大部分普洱茶生茶和熟茶可以明显区分开,且由于贮存年份对生茶的化学组分影响较大,生茶较熟茶更分散。但是有2个生茶与熟茶相聚集,有2个熟茶的位置与生茶更接近,甚至有1个生茶与熟茶近似重叠(箭头所指),证明老生茶化学组分中所含氢基团综合与熟茶差异并不明显,普通消费者通过感官很难识别老生茶和熟茶,也说明了通过PCA难以实现所有生熟茶的识别。因此,需要运用有监督学习算法PLS-DA来提高生熟茶的识别正确率。
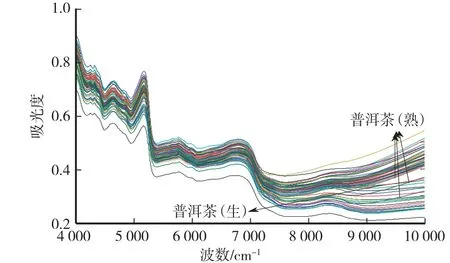
图1 普洱茶的近红外原光谱图Fig.1 Near infrared spectra of Pu’er tea
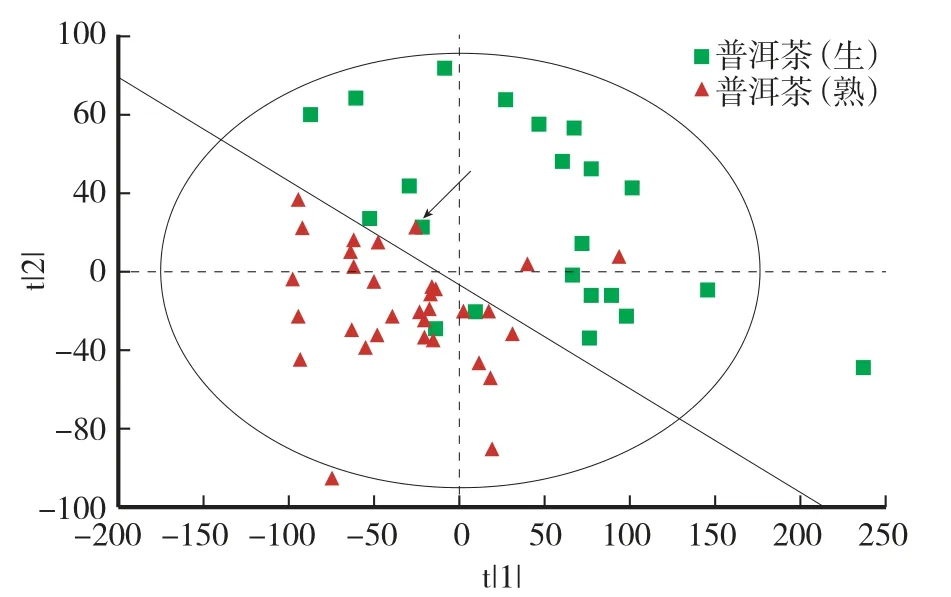
图2 普洱茶生茶和熟茶的PCA得分图Fig.2 Principal component analysis score chart of raw and ripe Pu’er tea
普洱茶生熟茶PLS-DA模型的主成分数、主成分数对原变量的解释能力(R2X)和生熟茶识别正确率见表1。第一个主成分对原变量的解释能力为0.714,对普洱茶生熟茶的识别正确率为81.82%,有8个生茶被错判为熟茶,2个熟茶被错判为生茶,说明第一个主成分包含原变量信息最多,且有些老生茶所含氢基团综合可能与熟茶更相近[12]。当取前两个主成分数时,对原变量的解释能力为0.964,模型对生熟茶的识别正确率为90.91%,有3个生茶被错判为熟茶,2个熟茶被错判为生茶(图3)。PLS-DA模型的前两个主成分得分图与PCA前两个主成分得分图(图2)相似,但PLS-DA可以更好地将组间差异不明显的变量加以区分[27],图2中箭头所指相互重叠的生熟茶样品,在图3中则被很好地区分(圆形部分)。当主成分数增加到3时,R2X累积增加到0.994,此时,模型对生熟茶的识别正确率为94.55%,有2个生茶被错判为熟茶,1个熟茶被错判为生茶。当主成分数增加到4,R2X累积增加到0.995,模型识别正确率为96.36%,熟茶的识别正确率为100%,仍然有2个生茶被错判为熟茶,可能增加的主成分中包含更多的熟茶特征成分。当主成分数由4增加到10时,R2X累积逐渐增加,最终增加到1,但是模型对生熟茶的识别正确率没有发生变化,均为96.36%。当主成分数由10增加到13时,R2X累积和模型识别正确率均无变化。当主成分数增加到14,R2X累积为1,模型识别正确率为98.18%,只有1个生茶被错判为熟茶,说明所增加的主成分含有更多与生茶特征成分相关的信息。当主成分数增加到15时,模型对生熟茶的正确识别率达100%,说明利用有监督学习算法PLS-DA可以将普洱茶生熟茶完全识别。

表1 普洱茶生熟茶PLS-DA模型的主成分数与生熟茶识别正确率Table 1 Principal component number of PLS-DA model and recognition accuracy of raw and ripe Pu’er tea
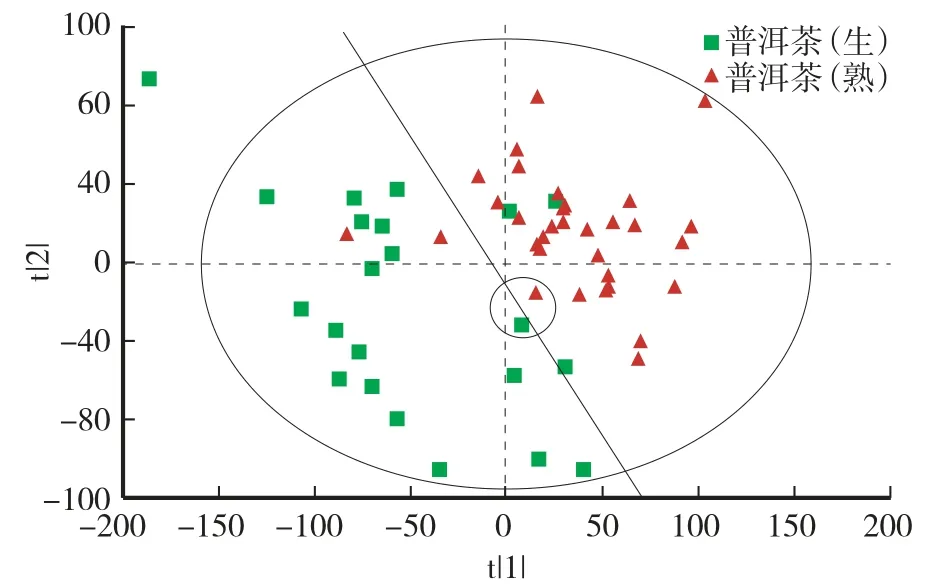
图3 识别普洱茶生熟茶的PLS-DA模型前两个主成分得分图Fig.3 The score chart of the first two principal components of PLS-DA for identifying raw and ripe Pu’er tea
2.2 不同产地普洱茶产地溯源
由于不同产地普洱茶光谱的主要峰形相似,谱图存在重叠现象,普洱茶的原光谱(图1)并不能直接识别普洱茶的产地,本研究运用PCA和PLS-DA来辅助实现。
由图4a知,第一个主成分对原变量的解释能力为0.818,说明第一个主成分包含原变量的信息最多,前两个主成分对原变量的解释能力累积为0.977,说明前两个主成分已包含了样品的大部分信息。虽然图4a中生熟茶分别聚集,但是3个产地的普洱茶分散无规律。再将生熟茶分开考察不同产地的溯源情况,由图4b和4c可知,3个产地的普洱茶也不能被正确溯源。结果表明:不同产地自然环境、种植方式等对普洱茶的影响在光谱中的综合反映没有生熟茶中化学组分的影响大,仅通过无监督学习算法PCA的前两个主成分并不能实现3个产地普洱茶的溯源。
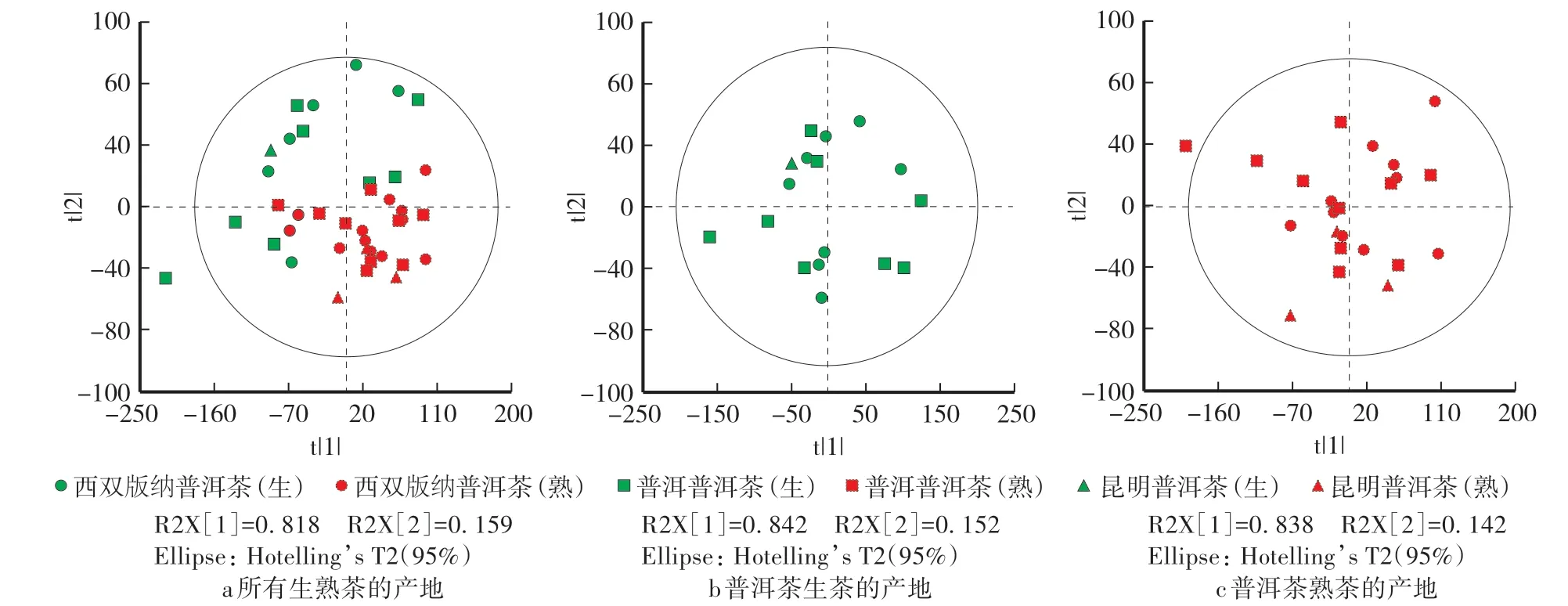
图4 不同产地普洱茶的PCA得分图Fig.4 Principal component analysis score chart of Pu’er tea from different geographic origins
使用有监督学习算法PLS-DA进行普洱茶不同产地的溯源。不同产地普洱茶的PLS-DA主成分数、主成分数对原变量的解释能力(R2X)和模型产地溯源正确率见表2,其前两个主成分得分见图5。PLS-DA的第一个主成分R2X为0.787,模型的溯源正确率仅为47.5%,因此,需要继续增加建模的主成分数。当取前两个主成分时,对原始变量解释能力的累积为0.976,但是溯源模型的正确率反而降低为42.5%,说明第二个主成分可能包含了产地溯源不相关的信息,且图5可以进一步说明不同产地的普洱茶混合分散,并没有呈现聚集现象,这与PCA的前两个主成分得分图(图4a)相似。当主成分数继续增加,对原始变量解释能力的累积逐渐增加,模型溯源的正确率也在缓慢增加。当主成分数取6时,R2X累积达到约1,但是模型的溯源正确率仅为62.5%,这可能与不同产地普洱茶的含氢基团综合差异小有关,且光谱数据的原变量数为6 224个,即使主成分数大幅度增加,但其所包含的与产地相关的信息增加量却缓慢增加。最终当取前26个主成分数时,模型的溯源正确率达到100%,虽然主成分数较多,但这是与光谱原始变量数相对应的,证实了PLS-DA可以实现不同产地普洱茶的溯源。
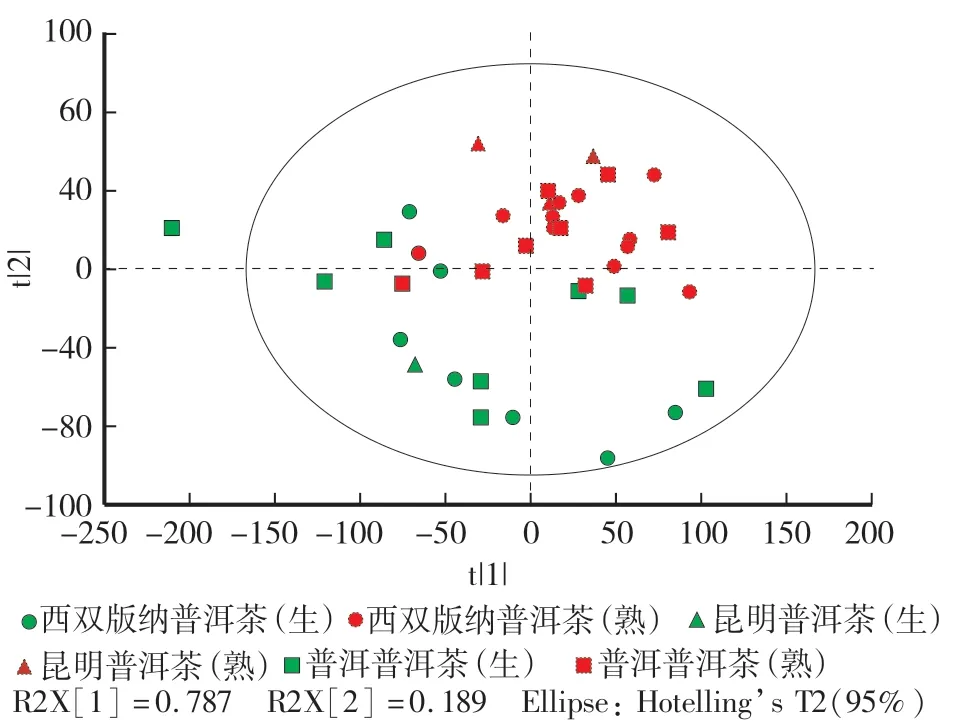
图5 不同产地普洱茶的PLS-DA模型前两个主成分得分图Fig.5 The score chart of the first two principal components of PLS-DA model of Pu’er tea from different geographic origins

表2 不同产地普洱茶的PLS-DA模型主成分数与溯源正确率Table 2 Principal component number and traceability accuracy of PLS-DA models of Pu’er tea from different geographic origins
2.3 未知类别的普洱茶生熟茶预测和未知产地的普洱茶产地溯源
对于所建模型的预测能力和稳健性,通过市场所采集的未知样品进行验证。从图6可见,PCA和PLS-DA前两个主成分得分图中均将10个未知类别普洱茶中的1个判为生茶,其他9个判为熟茶,且表3也证实了当PLS-DA模型的识别正确率为100%时,10个未知类别普洱茶中有1个为生茶,9个为熟茶。以上结果表明,在判别普洱茶类别时,PCA和PLS-DA模型均表现出优良的预测能力和稳健性,可以将模型用于普洱茶生熟茶的识别。

图6 PCA(a)和PLS-DA(b)对普洱茶未知类别样品的预测结果Fig.6 Prediction results of PCA(a)and PLS-DA(b)models for unknown class samples of Pu’er tea

表3 PLS-DA模型对普洱茶生熟茶的预测Table 3 Prediction of raw and ripe Pu’er tea by PLS-DA model
由图7可知,由于已知产地普洱茶的PCA和PLS-DA前两个主成分得分图不能很好地将三地普洱茶进行溯源,且未知产地的样品也与3个地区已知的样品混杂,因此,利用PCA和PLS-DA的前两个主成分得分图不能实现未知样品的溯源。由表2可知,当PLS-DA的主成分数增加到26时,已知样品的溯源正确率为100%,此时,PLS-DA模型对25个未知样品的溯源结果为5个样品来自西双版纳,13个样品来自普洱,7个样品来自昆明(表4),说明可以利用PLS-DA模型来实现普洱茶未知样品的产地溯源。

图7 PCA(a)和PLS-DA(b)对未知产地样品的预测结果Fig.7 Prediction results of PCA(a)and PLS-DA(b)models for unknown geographic origin samples

表4 PLS-DA模型对普洱茶产地的预测Table 4 Prediction of geographic origin of Pu’er tea by PLS-DA model
3 结论
本研究基于普洱茶因生产工艺、产地等造成的其化学组分中含氢基团综合存在差异,利用NIRS结合无监督学习算法PCA和有监督学习算法PLS-DA进行普洱茶(老)生熟茶类别识别及普洱茶产地的溯源。结果表明:PCA和PLS-DA模型均可很好地实现普洱茶生熟茶识别,且PLS-DA最优模型的识别正确率可达100%;但PCA模型不能实现三地普洱茶的溯源,而PLS-DA最优模型的溯源正确率为100%,说明PLS-DA模型可以实现西双版纳、普洱和昆明三地普洱茶的溯源。
通过10个未知生熟茶类别的普洱茶和25个未知产地的普洱茶来验证PCA和PLS-DA模型的预测能力和稳健性。PCA和PLS-DA模型对10个未知类别的普洱茶预测结果一致,说明这两种模型的预测能力和稳健性均优良,可以用于市场上未知类别普洱茶的预测。对于25个未知产地的普洱茶,PCA模型暂不能很好地进行预测,PLS-DA的预测结果显示有5个样品来自西双版纳,13个样品来自普洱,7个样品来自昆明,说明最优的PLS-DA模型可以初步实现市售未知产地普洱茶的溯源。为了提高所建模型的适用性和预测能力,后续需要进一步增加不同产地普洱茶的数量,尤其是昆明样品。
