基于FPGA的YOLOv3-tiny卷积神经网络加速设计
2022-05-06梅志伟丁兴军刘金鹏
梅志伟,丁兴军,刘金鹏
(中国船舶集团有限公司第八研究院,江苏 扬州 225101)
0 引 言
YOLO(You Only Look Once)是用于目标检测的一种卷积神经网络模型,与网络模型区域卷积神经网络(RCNN)、单步多框检测算法(SSD)等相比,YOLO在确保检测精度的前提下,大幅度提升检测速度。在2018年提出的YOLO第三代版本中,包括了YOLOv3和YOLOv3-tiny,相比YOLOv3,YOLOv3-tiny精简了网络层数,减少了计算量,属于轻量级的神经网络模型,更适合应用在嵌入式终端进行硬件加速。
卷积神经网络模型包含训练和推理2个过程。训练包含forward和BP(backward propagation)2个步骤,通过对已知大量样本的学习,迭代计算损失函数更新网络节点权重得到最终网络模型,训练过程包含大量的数据计算,通常在高性能的图形处理器(GPU)上运算。推理只包含forward过程,没有迭代计算和反馈,计算量相对较低,适合应用在计算资源和存储资源相对受限的嵌入式终端。现场可编程门阵列(FPGA)开发周期短,性能高,编程灵活,通过设计合适的硬件电路对卷积神经网络进行推理加速,能够取得大幅度的性能提升。
对于卷积神经网络硬件加速,国内外学者进行了广泛研究。通过设计大规模的乘加阵列,谷歌团队的张量处理器(TPU)引进脉动阵列,增加数据复用,减少数据流动,提升计算性能,但对不同规格卷积核的数据重组难度高,代价大,效率偏低。麻省理工学院(MIT)的Eyeriss为了减小能耗,最大化局部数据复用,通过数据复用与编码压缩数据来减少数据搬移,从而达到能效优化的目的,但不同的网络计算需要重新配置映射到阵列,而且乘加阵列中扇出较多,阵列时序和规模提升难度较大。针对YOLO系列算法的卷积神经网络硬件加速,重庆大学张丽丽基于高级综合(HLS)开发工具对YOLO算法进行定点运算,探索网络结构并行和卷积计算并行,速度上提升6~7倍,但在设计上脱离了硬件架构,加速性能有进一步提升的空间。华南理工大学罗聪研究了数据复用和网络二值化处理方式,达到了高运算性能,但在检测精度上有所下降。电子科技大学张雲轲等研究了压缩网络结构,利用流水线和并行运算,达到了车辆检测的实时性要求,但它只针对车辆检测,相对原YOLO算法其应用面较窄。针对上述情况,在保证通用目标检测应用场景的前提下,根据YOLO-tiny网络层设计精度可变的定点量化,对定点数进行重训练,同时设计特定而高效的硬件架构,在保证检测精度的情况下,减少了资源使用,提升了加速效率。
1 YOLOv3-tiny网络特性分析
YOLOv3-tiny网络层结构如表1所示,YOLOv3-tiny一共包含13个卷积层(conv)、6个池化层(pooling,均为最大值池化)、1个上采样层(upsample)、2个路由层(route)和2个yolo层。其中对于weight和output列中数据量计算中选取的均为量化后的8 bit定点数。网络结构中yolo层主要是对数据做logistic变换。logistic变换是一种非线性变换,其计算中包括指数等运算,不适合在FPGA上实现。考虑到其在网络前向计算过程中的时间消耗较少,因此加速模块中不包含对yolo层的加速,将这一层计算放到CPU中完成。网络结构中route1层是将前面某一层的输出作为下一层的输入操作,route2层是将前面2层在通道数上进行拼接,硬件实现上控制读取数据的地址即可进行拼接操作。池化层与上采样层计算模式简单,池化层都是对输入特征图中的2×2个数据进行比较,得到一个最大值,保存到输出特征图中。上采样层将输入特征图中的每个数据复制4次,得到2×2的数据,保存到输出特征图中,这2种类型的网络层在硬件上进行数值比较和数据复制,即可完成加速。

表1 YOLOv3-tiny网络层结构
卷积层是YOLOv3-tiny网络的核心网络层,YOLOv3-tiny的计算量绝大部分集中在卷积层。卷积层中包含大量的乘累加运算和一部分非线性运算。非线性运算在FPGA中均可通过查表法实现,硬件加速重点关注卷积层中的乘累加运算。与AlexNet网络的卷积层比较,YOLOv3-tiny网络的卷积层在结构上卷积核有3×3和1×1 2种规格,卷积核步长(stride)均为1,结构较为规整,输入输出通道数均为16的倍数。输出特征图的宽和高经过最大值池化后,整体呈下降趋势,最大的规格为224×224,最小的规格为7×7。从数值上分析,为了提升计算性能,增加输入输出维度上的并行计算设计。为了提升乘加阵列的计算效率,设计基本乘加阵列计算单元,适应特征图尺寸。
2 YOLOv3-tiny硬件加速设计
2.1 可变定点数量化
卷积神经网络往往存在数据冗余,在训练时通常使用32 bit浮点类型来表示权重参数,数据在参数精度上存在冗余。神经网络对低精度权重值有非常高的容忍度,较低精度的权重值也不会降低神经网络的性能。在推理时将32 bit浮点参数量化为低比特定点数,可以在几乎不损失网络性能的条件下,显著降低参数存储需求和数据传输带宽需求。YOLOv3-tiny原始的权重参数用32 bit浮点数表示,其平均精度(mean Average Precision,mAP)为59.16。测试了权重由不同位宽表示下的性能损失情况,如图1所示。可见,当位宽减少到12时,性能略微下降,从8 bit开始,位宽每减少一位,性能下降明显。根据不同数据位数的网络检测精度和计算机中常用的存储位数,选择将32位浮点数量化为8位定点数。

图1 不同参数位宽下的性能下降情况
定点数是指小数点位置固定的数值表达方式。一个位(一般为2的整数幂)定点数可以表示为(-1)××2-,其中是符号位,是(-1)位的数值部分,代表了十进制小数点的位置,起到比例因子的作用。例如,一个8 bit的整数,当=0时,表示范围为-128~127,精度为2=1;当=5时,表示范围为-4~3.968 75,精度为2=0.031 25。在8 bit情况下,不同下的数值表示范围和精度不同。在位宽确定的情况下,定点数的数值范围和精度相互矛盾,需要合理选择比例因子。
为了保证网络检测精度,在量化时要选择合理的比例因子。对YOLOv3-tiny网络每层的权重参数和输出特征图的范围进行了统计,每层输出特征图的原始数值范围和量化后可表示的数值范围如表2所示。针对YOLOv3-tiny中各个网络层不同的数据分布,选择可变精度的定点数表示量化后的数据,对每层的权重参数、批归一化参数等进行了统计,并确定了比例因子。

表2 YOLOv3-tiny网络每层的输出特征图数值范围
2.2 定点数重训练
当量化后参数位宽下降至8时,网络性能也存在小幅度下降。引入了重训练机制,对量化后的权重参数进行重新训练,可将性能恢复至与高精度参数性能相当的地步。将二值化神经网络的重训练方法应用在YOLOv3-tiny卷积神经网络上,对8 bit量化参数进行重训练,训练流程为:
//1.forward propagation
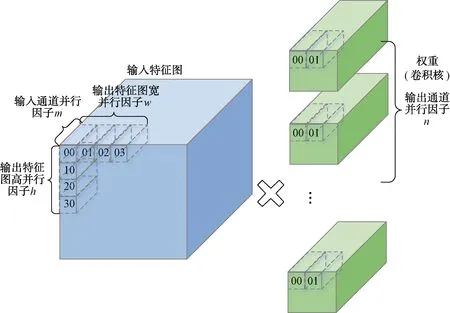
for(=0; { } //2.backward propagation and update for(=layer_max;>=0;--) { } 并行计算设计是硬件加速模块设计的关键。为了提升硬件加速模块的性能,在卷积神经网络加速上需要尽可能让基本计算单元同时进行计算,同时还要兼顾FPGA的资源消耗、硬件加速模块的工作效率和数据吞吐量。并行计算设计是以上各个因素综合考虑的结果。并行设计可在卷积计算过程中参与的数据维度上进行选择设计,卷积核的宽和高在YOLOv3-tiny网络中有3×3和1×1 2种尺寸。在并行设计上兼容2种尺寸会导致效率的下降,因此选择在输入通道、输出通道、输出特征图宽和输出特征图高4个维度同时进行并行计算设计。在输入通道和输出通道2个维度上,通道数多为16的倍数且数值相对较大。同时考虑到资源消耗和数据吞吐,在输入通道和输出通道2个维度上,并行因子均选择8,能够让基本计算单元取得较高的计算效率。类似综合考虑后,输出特征图宽和输出特征图高选择的并性因子均为4。并行计算对应的示意图如图2所示。 图2 并行计算示意图 大规模的并行计算需要对应大量数据同时参与。在YOLOv3-tiny网络conv7中参与计算的权重经8 bit量化后为4.7 MB,数据量较大,每一层网络层的权重等参数储存在外部双倍数据速率同步动态随机存储器(DDR SDRAM)中。数据通过AXI总线从外部存储器DDR输入到FPGA片上缓存。为了方便计算,单元从FPGA片上缓存读数后直接参与运算,选择与英伟达深度学习加速器(NVDLA)类似的数据存储格式对数据进行储存,减少数据转换。图3为权重的存储格式示意图,其中为卷积核宽高,为输入通道数,为输出通道数,为输入通道并行因子,为输出通道并行因子。在设计中、均为8。在数据复用上,由于在YOLOv3-tiny网络前3层卷积层中,特征图参数量大于权重参数量,选择进行输入特征图复用。不同输出通道上的卷积核复用同一输入特征图,输入特征图复用次数为输出通道数次。在YOLOv3-tiny网络后10层卷积层中,权重参数量大于特征图参数量。选择进行权重复用,在输入特征图上的不同卷积窗口中的数据复用相同的卷积核,得到输出特征图平面维度的不同点,权重复用次数为输出特征图宽高乘积×。 图3 权重存储格式 在FPGA上对YOLOv3-tiny卷积神经网络进行推理加速时,设计与网络结构紧密结合的硬件模块能够提升运算的计算效率,相比于CPU能够大幅度减少运行时间,相比于GPU能够降低能耗,更适合在移动端进行应用。针对YOLOv3-tiny网络设计的硬件加速结构如图4所示,主要分为3个部分:数据通路、计算模块和控制逻辑。在数据通路上,FPGA内部缓存分为对应输入特征图、权重和输出特征图的片上缓存,FPGA片上缓存作为外部存储器DDR和计算模块数据的缓冲桥梁,通过双缓冲机制与数据复用方法,使得取数与计算以流水的方式不断进行。各级缓存之间的传输通过握手的方式进行,当读写双方的valid与ready信号同时拉高时,数据按照指定方式进行传输,当传输完成指定数量的数据后,complete信号拉高,完成传输任务。 图4 硬件加速架构 在硬件加速结构,计算模块完成对conv层、pooling层、upsample层的硬件加速,计算模块重点在于对卷积运算的加速。卷积运算可以拆分为六重循环的乘累加运算和非线性运算,非线性运算Non-Linearity模块主要包含了3个步骤:Batch Norm、Add Bias、Activate。在神经网络训练过程中,一般会引入Batch Norm(批归一化)操作,将输入数据进行归一化处理,使数据均值变为0、标准差变为1的分布。Batch Norm可以加快训练速度,提高模型训练精度。Batch Norm主要是以下的计算: (1) 式中:为输入数据;为输出数据;和为当前输入批次的数据分布均值和方差;为一个为了避免除数为0的很小的常数;和为训练过程中需要学习的参数。 在推理过程中,往往是输入单个样本,因此和为训练阶段记录下来的均值和方差,和为训练得到的参数。第2步Add Bias操作对输入数据加上一个偏移量bias。第3步Activate是对数据进行非线性的激活操作,常见的激活函数有ReLU、Sigmoid、LeakyReLU等。YOLOv3-tiny网络使用到了LeakyReLU激活函数,公式为: (2) 乘累加运算涉及6个数据维度上的乘累加计算,计算方式简单,但涉及数据量大。其中3个数据维度上是乘累加计算,3个维度上是并行计算。乘累加运算在硬件加速结构的计算模块中,分为乘累加阵列(MAC阵列)和累加器2个部分。为了适应在输入通道、输出通道、输出特征图宽和输出特征图高4个数据维度上的并行计算设计思想,乘累加阵列分为16个8×8的块计算阵列,每一个块计算阵列为8个并行的乘加树结构,块计算阵列映射为输入通道和输出通道。每个块计算阵列的行做乘累加运算,计算结果输入到累加器中,累加器中通过计数器计算完成3个数据维度上的乘累加运算后得到输出特征图二维平面上的点,送入输出特征图片上缓存,通过AXI总线将输出结果传输到片外DDR。 在卷积神经网络硬件加速结构中,由于数据量和计算量过大的原因,通常是每一层网络层进行加速,输入数据从片外DDR中输入,在FPGA上完成加速运算后输出到片外DDR中。但对于pooling层和upsample层,运算模式相对简单,主要操作为对数据的比较、筛选和复制。通过对该2类网络层的硬件加速与卷积层加速模块进行融合,可以减少一次网络层数据与片外DDR的往返传输,减少了数据传输总量。在硬件加速结构计算模块中,完成卷积层的乘累加运算和非线性运算硬件加速后,加入上下采样计算模块完成对pooling层和upsample层的加速运算。route层操作主要对已完成计算的2层网络层在输入通道上进行拼接计算,在片外DDR中预留专用route操作层存储区域,利用控制模块完成对route操作的拼接运算。控制逻辑的主要分为分块传输控制和网络层控制2个部分,分块传输控制是根据数据复用方式划分数据从片外DDR到FPGA片上缓存的分块传输大小和次序,网络层控制将需要加速的网络层分为conv层、conv+pooling层、conv+upsample层和route层4类,根据不同类型网络层调用计算模块中加速单元完成对应的硬件加速。 在量化重训练上,在YOLO系列网络的训练过程中,对不同输入图像尺寸的YOLOv3、YOLOv3-tiny网络进行了量化重训练,结果如表3所示。可以看到,量化后的网络性能损失在可接受范围内,但是其参数量却仅为原来的1/4,降低了存储需求和数据传输需求。 表3 量化前后性能对比 经过用8-bit可变精度定点数对32-bit浮点数量化后,代入到YOLOv3、YOLOv3-tiny卷积神经网络进行重训练后,我们发现在YOLOv3-tiny网络检测精度上,224×224输入尺寸的图像比416×416输入尺寸的效果更好,网络检测精度下降到仅为0.19 mAP,网络性能下降基本可以忽略。224×224输入尺寸的图像不经过重训练后,网络检测精度为55 mAP,精度下降为4 mAP;经过重训练后,量化后的低精度参数网络的性能可以恢复到和原始高精度网络相当的性能。 选择在FPGA上对224×224输入尺寸的YOLOv3-tiny卷积神经网络进行硬件加速。YOLOv3-tiny硬件加速结构设计基于Xilinx公司的FPGA开发平台VC707。开发平台有Virtex-7型号的FPGA和1 GB容量的DDR3,FPGA具体型号为xc7vx485t2ffg1761C,开发环境为Vivado2 017.04,开发语言为Verilog硬件编程语言。下面从FPGA资源消耗、网络加速性能和乘加阵列(MAC)计算效率3个方面评估设计的硬件加速结构对YOLOv3-tiny卷积神经网络的加速效果。对设计的硬件加速结构,设置FPGA的运行时钟为125 MHz。经过Vivado综合与实现后,得到的资源消耗如表4所示。其中使用块随机存储(BRAM)数量为136,数字信号处理模块(DSP)数量为576,Vivado实现相应电路后给出的功耗为2.952 W,硬件资源消耗少。 表4 FPGA资源使用情况 在硬件加速结构内部设置计数器,在网络层数据从片外双倍数据速率存储器(DDR)传入FPGA片上缓存时开始计数,在网络层硬件加速完成后,所有输出特征图数据传出到片外DDR后停止计数,统计网络层在FPGA上运行时间和网络层总的乘累加数量,计算得到网络层的加速性能和MAC阵列计算效率。各个网络层的加速运行时间和MAC效率汇总如表5所示。YOLOv3-tiny卷积神经网络中除yolo网络层外,conv、pooling、upsample和route网络层均可在设计的硬件加速结构中运行。从表5中可以看出:网络层MAC计算效率为37.03%~99.21%分布,各个网络层效率相差较大,主要原因在于不同的网络层分块计算划分带来的差异;除此之外,数据传输、非线性运算也会占有一定的影响因素。分析conv1+pooling1网络层的37.03%,由于输入通道数为3,在输入通道并行因子为8的MAC阵列中,理论上最高效率只能达到37.5%;对于conv10网络层,7×7×75的输出特征图在对应并行因子维度为4×4×8的并行维度上,实现MAC计算效率仅为50.28%;而conv3+pooling3网络层,各个并行维度都能整数划分;MAC阵列在分块计算时不存在资源的浪费,对应计算效率能达到99.21%。 表5 YOLOv3-tiny网络层加速性能 YOLOv3-tiny在设计的硬件加速结构上运行的网络层总乘累加数量为0.793 2 G,网络加速时间总共约为8.5 ms,所有加速的网络层算力约为186.6 GOPS,加速网络层MAC计算效率平均值达到74.54%。在对轻量级yolo网络进行加速的研究中,将本文设计的硬件加速结构与其他文献的加速结构在性能上进行比较。对比张丽丽、黄智勇的加速研究,本文结构在硬件上专为YOLOv3-tiny网络设计,从大规模并行计算设计到大范围数据复用,加速设计更为深入,相比1 s的运行时间提升了2个数量级;对比张雲轲的加速结构40.8 ms的加速时间,本文加速结构使用的MAC阵列并行度大,运行频率高,运行时间有4.8倍的提升,并且不局限于车辆检测,应用范围更广;对比罗聪的研究,相比二值化YOLO网络后的加速时间仅为6.88 ms,与本文加速结构8.5 ms的加速时间相差不大,但网络检测精度相比其在mAP上有5%的下降,本文加速结构相比原网络检测精度基本保持同一水平。 本文对YOLOv3-tiny卷积神经网络硬件加速进行研究,在深入分析网络特性后,提出一种基于FPGA的YOLOv3-tiny硬件加速结构。本文通过对YOLOv3-tiny网络参数进行可变精度定点量化来减少网络计算量和数据存储量,针对量化后出现网络精度下降的问题采取量化重训练的方法保证量化后的网络精度,数据从32 bit浮点数量化为8 bit定点数,数据存储和计算量下降,网络检测精度基本不变。本文在输入输出通道和输出特征图宽高4个维度上进行并行计算设计,设计了4×4×8×8规模的计算阵列,提升网络加速性能,加速算力约为186.6 GOPS;通过沿用类似NVDLA的数据存储格式,针对不同网络进行不同类型的数据复用,减少数据传输,网络加速时间约为8.5 ms;对网络层提取共性、区分不同特性,设计了除yolo层外的YOLOv3-tiny高效网络加速硬件架构,MAC整体计算效率为74.54%。本文基于FPGA设计的针对YOLOv3-tiny卷积神经网络的硬件加速结构,在综合性能上优于目前出现的研究方案,并且计算资源和存储资源相对较少,在移动端人工智能加速应用是一个相对不错的选择。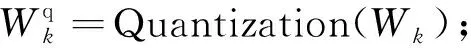



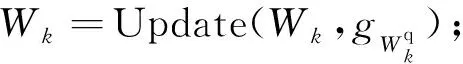

2.3 并行计算与数据存储

2.4 硬件加速架构

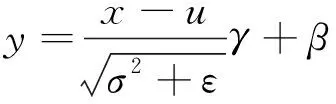

3 实验结果与分析



4 结束语
