有偏随机游走改进吸收中心性识别关键节点
2022-05-05武志峰
宁 阳,宁 晴,武志峰
(1天津电子信息职业技术学院 计算机与软件技术系,天津 300350;2北京联合大学 信息服务重点实验室,北京 100101;3天津职业技术师范大学 信息技术工程学院,天津 300222)
0 引 言
在电力交通、社交、生物、政治经济等领域,复杂网络中的关键节点识别具有实际应用意义。如:复杂网络中的关键节点识别,可以在电力交通网络中挖掘枢纽节点,进行重点保护,达到降低经济风险的目的;在社交网络中最有影响力的人,能够被准确的挖掘出来,使广告效益得到最大化的同时,可以有助于流言传播的控制;在蛋白质网络中可以对关键蛋白质进行挖掘,这些蛋白质在机体再生和生存时是不能或缺的;在生物网络中,为医药发展提供有价值的理论和方法。
复杂网络重要节点识别这一问题,从网络局部、全局信息方面考虑,可以将其划分为基于邻居节点的结构化指标、基于路径的结构化指标、基于节点移除及收缩的中心性指标、基于迭代寻优的中心性指标进行节点重要性研究。在无向网络,度中心性方法、介数中心性方法、接近中心性方法等,都是比较经典的关键点识别方法。度中心性方法存在节点的度值与重要性不一定成正比问题,而介数中心性方法和接近中心性方法具有较高的时间复杂度,研究人员通常与典型算法进行比较,改进算法的有效性。在有向网络,使用迭代寻优的中心性指标PageRank算法,以及在此基础上改进的关键点识别方法(如;引入背景节点的LeaderRank算法、倾向于入度(出度)节点大的邻居节点转移的Pro_PageRank、DPRank算法等等),均存在参数问题。加权网络中,利用节点的边权信息,重新定义边权的节点移除及收缩方法进行关键节点识别,其算法时间复杂度随着网络规模的增加而增加。融合其他理论,基于证据理论和TOPSIS、灰色关联度分析、层次分析法、相对熵等方法进行多属性决策,对各指标的权重重新分配,来综合判别关键节点;也可与社区划分、图着色理论、投票算法、聚类算法等相结合,用于识别一组关键节点。此外,文献[20]中提出了一种将游走相似和表征节点重要性进行叠加的方法,对节点度、邻接节点的属性以及节点在网络中的位置加以融合,基于的随机游走是等概率的,但未对实际网络中游走的倾向性进行考虑;文献[8]利用理想状态下等概率的随机游走计算首次到达时间,提出吸收中心性算法,其中未将随机游走向节点转移的概率纳入研究机制。
综上所述,本文在文献[8]的基础上进行扩展研究,结合邻居节点的度(出度、入度)信息,在无向网络和有向网络中考虑信息传播的倾向性,利用随机游走首次可达时间构建转移概率矩阵,用以识别网络中的关键节点。
1 相关概念
1.1 网络表示


1.2 随机游走
随机游走是一个很有用的工具,借助这个工具可以对复杂网络的结构进行研究;有时也将随机游走模型称为布朗运动,其是一种理想的数学状态。随机游走可以理解为无法基于过去的行为对后续的发展步骤和方向进行预测。假设当前节点有4个邻居节点,该节点向其周围邻居节点的转移概率均为1/4,这是一种无限制的等概率随机游走。若将节点之间转移的倾向性考虑进来,就成为了一种无限制的有偏随机游走。
1.3 关键节点识别算法
根据网络是否具有方向性,将关键节点识别算法应用的网络类型划分为无向与有向两种。在无向网络中,衡量节点的重要性,主要基于邻居节点的信息和路径;有向网络中主要通过迭代寻优的方法,改进PageRank算法,利用节点的点权信息扩展到加权网络,以及将多属性进行融合,结合局部信息和全局信息进行关键节点识别。
1.3.1 无向网络关键节点识别
度中心性(Degree Centrality)考虑节点的局部信息,认为节点的重要性取决于中心性,其高低取决于节点度的值。在无向图中,公式(1)为节点的度中心性:
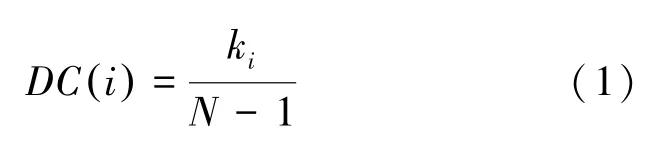
式中,为节点总个数,()为v的度中心性值。
介数中心性(Betweenness Centrality)方法,对节点的全局信息进行考虑。认为信息传播时,经过的是最短路径。刻画节点的重要性时,采用每个节点的最短路径数目。但该节点不一定是网络中度最大或者是网络的拓扑中心。公式(2)为v的介数中心性:

式中,n()为经过v的v和v之间的最短路径数;n为v和v之间的最短路径总数;()为v的介数中心性值。
接近中心性(Closeness Centrality)是衡量节点重要性指标时的最短路径。借助网络对其它节点施加影响的能力来反映节点,反映网络的全局结构,该方法只能应用于连通网络中。v的接近中心性如公式(3):

式中:()为节点的接近中心性值。
1.3.2 有向网络关键节点识别
PageRank是一种可以按照重要性对网页排序的方法。一个页面是否质量高,在于其输入是否有很多高质量的页面。也就是说如果有很多概率比较大的节点指向同一个节点,则通过某个节点到达该节点的概率也会高。为了使悬挂节点的问题得以解决,PageRank算法中每一个节点均以一定的几率跳转到网络中的任一节点,经过不断迭代,使每个节点的值趋于稳定,如公式(4):
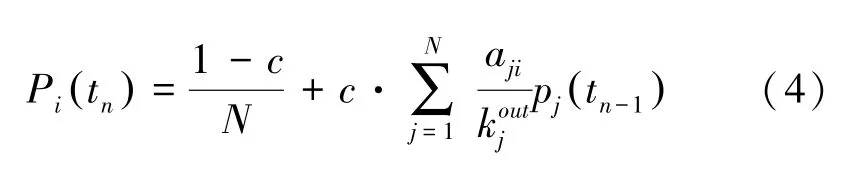
式中:P为节点的值,1是跳转概率,也称阻尼系数,通常085。
LeaderRank在解决出度为0的悬挂节点问题时,添加了一个虚拟背景节点,使网络中所有节点与其两两双向连接,当迭代达到稳定,将虚拟背景节点的权值平均分配给每一个节点。该指标值与节点重要性成正比。如公式(5):

其中,t表示稳态时刻。
Pro-PageRank方法是在节点转移过程中,更倾向沿着权重大的边游走。边的权重通过出度节点的入度邻居信息衡量。即节点转移时更倾向于沿着入度大的节点进行,如公式(6):
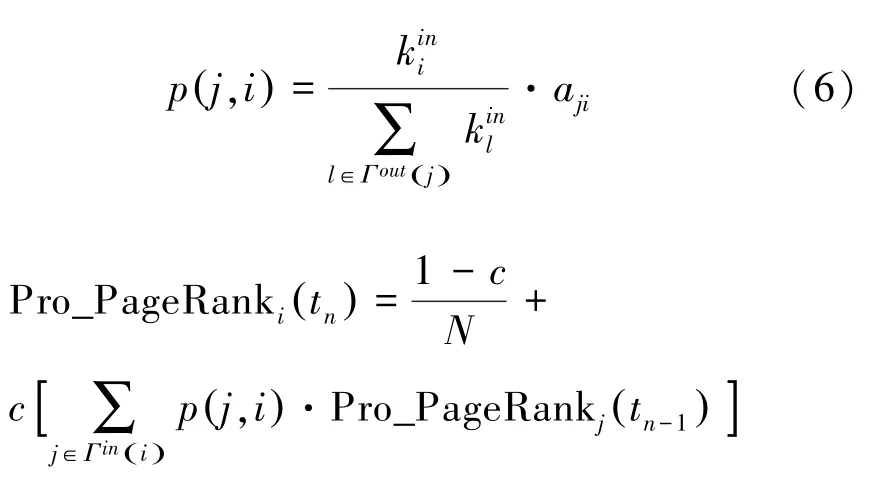
DPRank方法考虑两步转移节点信息,节点更倾向于出度大的节点转移。DP方法构建的转移概率矩阵如公式(7):
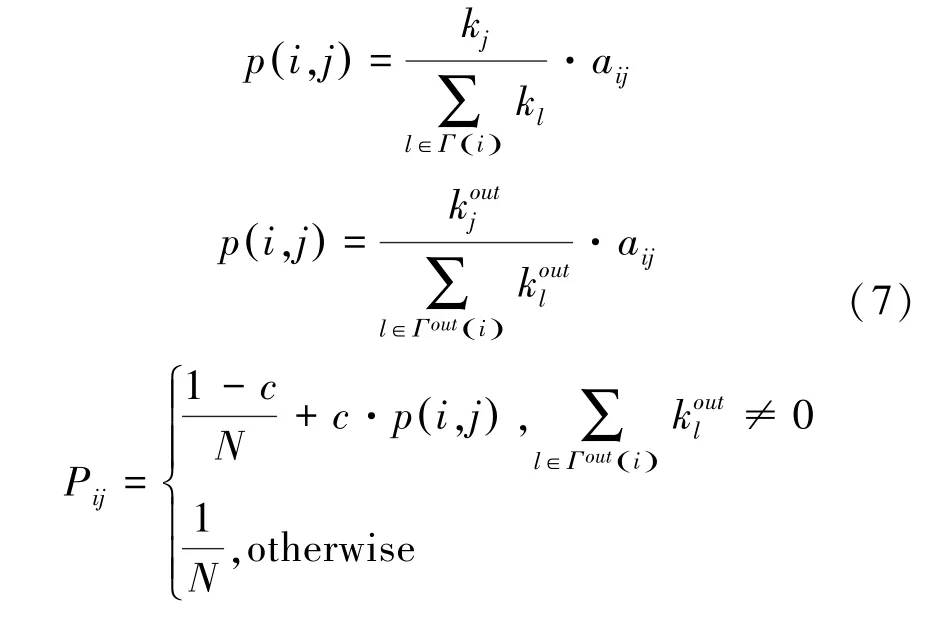
1.4 评价指标
1.4.1 Kendall tau距离
Kendall tau距离用来计算两个排序列表之间成对分歧数量,即两个完整列表和,(,)表示两个列表之间的差异性。

∈[0,1],值越大,则相似性越小。Kendall距离归一化处理得到:

将其用于比较一个序列与另一个类似标准答案的排序序列的相似性,得出排序序列有效性,K值与两个列表之间相似性成正比。列表与列表计算Kendall tau距离相似值的二元组集合,表1中分别列出列表的所有二元组组合。当()()且()()或者()()且()()时1,否则0。
例:{1,2,3,4},{1,3,2,4},其中表示标准序列。

表1 σ列表与τ列表二元组集合Tab.1 Two tuple sets ofσlist andτlist
由上表可知值,进而得到两个列表之间的相似性:K=12∗14∗30833
1.4.2 SIR传播模型
本文使用SIR传播模型,模拟信息在网络中的传播过程,用于表示节点的传播能力。在典型的传染病模型中,可将个节点的状态分为如下3类:
(1)(易染状态):在初始条件下将所有节点均定义为该状态,该节点被邻居节点感染的概率为;
(2)(感染状态):说明该节点已经感染某种病毒,已成为传染源,感染其直接易感邻居节点的概率为;
(3)(移除状态):感染状态节点以概率将邻居易感节点转变为感染状态后,以概率变为移除状态,不再具有感染能力和易感特性。
本文采用SIR为多源感染模型,初始时刻假设网络中的节点为个,其余均为个体。一个单位时间内,所有处于节点以概率将其周围邻居节点感染之后,以值为1的概率转变为,在不存在易感节点时达到稳定状态。此时对处于的节点个数进行统计,用于衡量初始感染状态节点的传播能力,记为。为减少、参数带来的随机性,每个节点计算100次,利用平均值进行计算。对网络中的所有节点均执行以上操作,节点传播能力的大小即为网络中节点的重要度。
2 有偏随机游走改进吸收中心性算法
基于网络中的随机游走原理,利用到达吸收节点时间提出的吸收中心性方法,由于其在研究随机游走机制时,仅考虑理想状态下的等概率随机游走,并没有考虑网络中信息流传播的复杂性问题。针对于此,本文将信息流在随机游走时向节点转移的概率纳入研究。在无向网络中,节点信息倾向于度大的节点转移;在有向网络中,节点的转移分别倾向于沿着出度、入度大的节点,将节点的重要性进行分析对比。
2.1 算法原理
吸收中心性方法(AS)是一种随机游走机制,这种机制是基于网络中等概率的,是利用网络中节点的吸收过程提出的一种识别重要节点的方法。吸收节点是在网络中任意选择一个节点,对网络中其他节点等概率的随机游走到节点的首次到达时间进行计算。该方法采用信息流的效率评估标准是首次到达时间,该节点的重要性衡量指标,是网络中其它节点到吸收节点的平均首次到达时间。平均吸收时间越短,其它节点到该节点的距离就越小,节点越重要。算法公式(9):

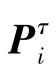
本文提出对算法的改进工作,是在无向网络中根据邻居节点的度信息重新设置边权。邻居节点的度越大,信息越倾向于向该方向进行转移,为此提出了_算法;在有向网络中,基于邻居节点的出度和入度信息,分别提出了_、_算法。
无向网络重新构建转移概率矩阵,采用文献[8]提出的设置吸收节点的方法,衡量节点重要性,定义为_:
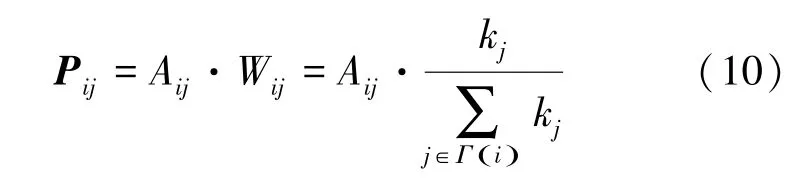
式中:()为的邻居节点集合;P为转移概率矩阵的值;W为节点、之间边的权值。
在有向网络中,本文定义的_D中心性指标中节点间的转移概率矩阵如式(11):

考虑网络节点的方向性,该指标中存在设置的吸收节点。由于吸收节点和出度邻居节点间存在直接连边,为避免转移概率为0的情况,采用每个节点的出度均加1,同时避免了分母为0的问题。
在有向网络中,公式(12)为本文定义的_D中心性指标中节点间的转移概率矩阵。在吸收节点的邻居节点均为边界节点时,v向每个邻居节点随机游走的概率均为1/k,该指标等同于等概率的随机游走。
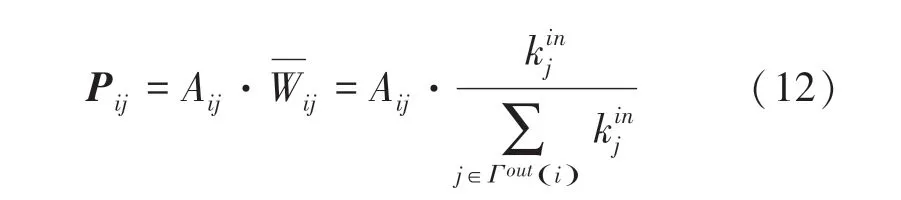
为了方便计算分析,按照最大值,将各节点的中心性值归一化处理,如式(13):

2.2 案例分析
本节通过计算实例,对算法的计算过程进行解释,如图1所示。其中包含9个节点12条边的无向网络,假设吸收节点为节点1,将其代入式(9)、式(10),计算所有节点有偏随机游走到吸收节点1的首达时间。各中心性方法的中心性值见表2。
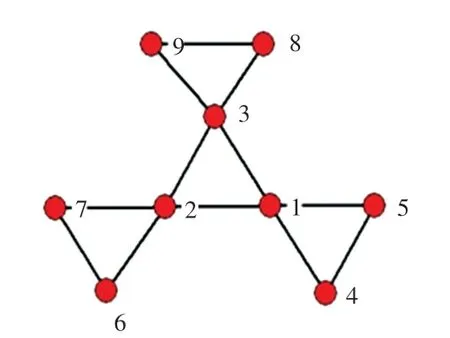
图1 案例网络Fig.1 Case network
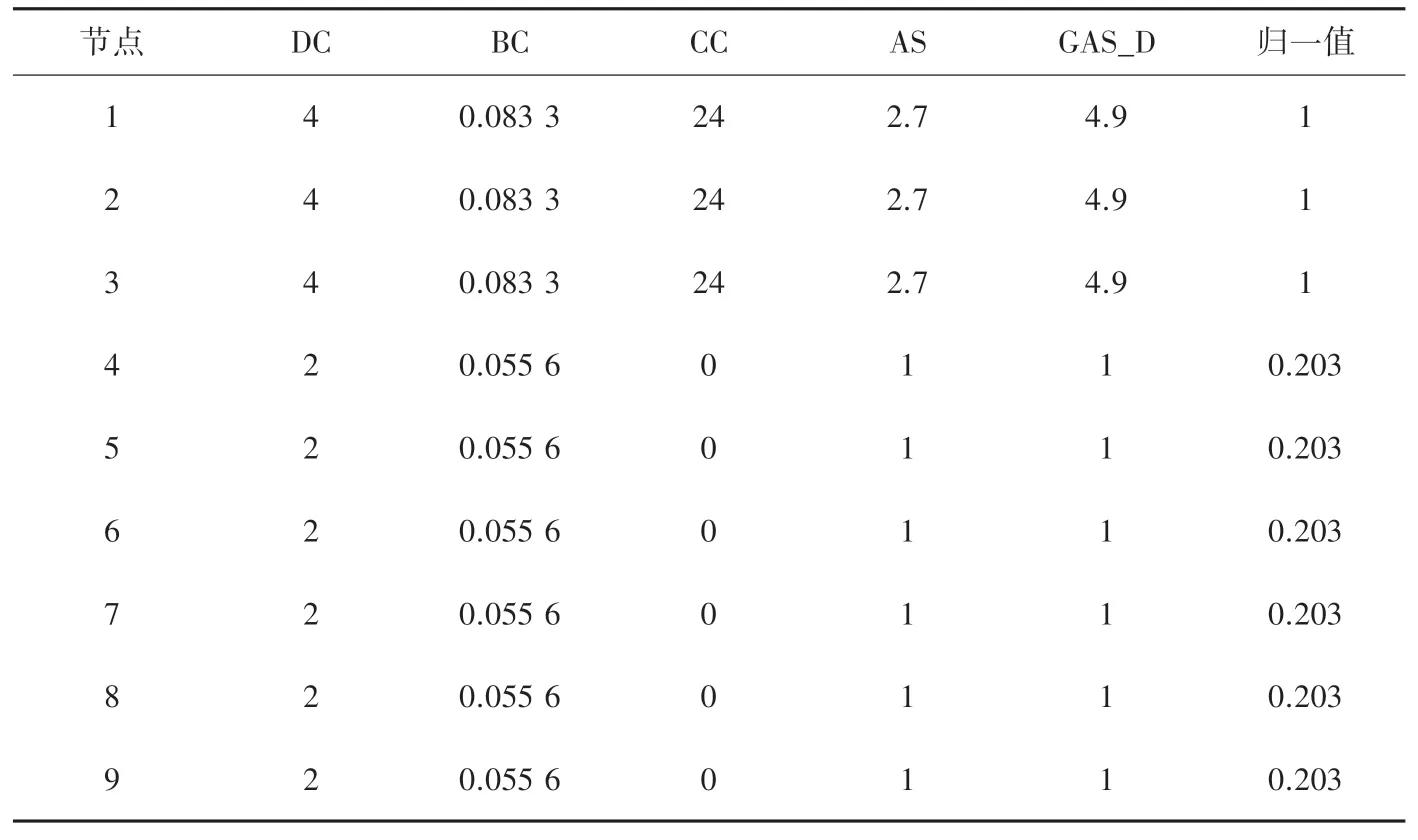
表2 各中心性方法所有节点的中心性值Tab.2 Centrality values of all nodes in each centrality method
3 实验分析
根据上述分析,为验证本文提出基于有偏随机游走改进的吸收中心性算法(GAS_D、GAS_Dout、GAS_Din),识别关键点的有效性,对无向网络(karate、USAir、911terriset、Email)、有向网络(Freemans、Organisational、Celegansneural)进行仿真实验,实验数据集的网络参数见表3。
表3中,表示节点数;表示边数;表示节点平均度;max表示节点最大度;表示网络节点间最短路径平均数;表示聚类系数,用来评估节点聚集成团的集聚程度;表示同配系数,用来反映邻接节点间的度相关性;表示异质系数,衡量网络中节点度分布的异质性。
实验环境为:Intel(R)Core(TM)i3-2367M CPU@1.40 GHz、4 GB内存、Windows7、python3.2.732位,使用Python语言实现算法。共设计3组对比实验,对算法的有效性和准确性进行验证。
实验内容如下:
(1)对比分析本文提出的改进算法与其它中心性算法中心性值的相关性。单调性表现越明显,算法之间的相关性越好。
(2)采用数学计算,度量Kendall tau距离计算相关系数。以本文提出的改进算法为标准,对该算法与其它方法之间的相似性量化分析,相似性越大说明算法越有效。
(3)基于SIR多源传播感染模型,在不同感染概率下,对各算法识别出的TopK节点在稳定状态下平均感染的节点数进行比较。
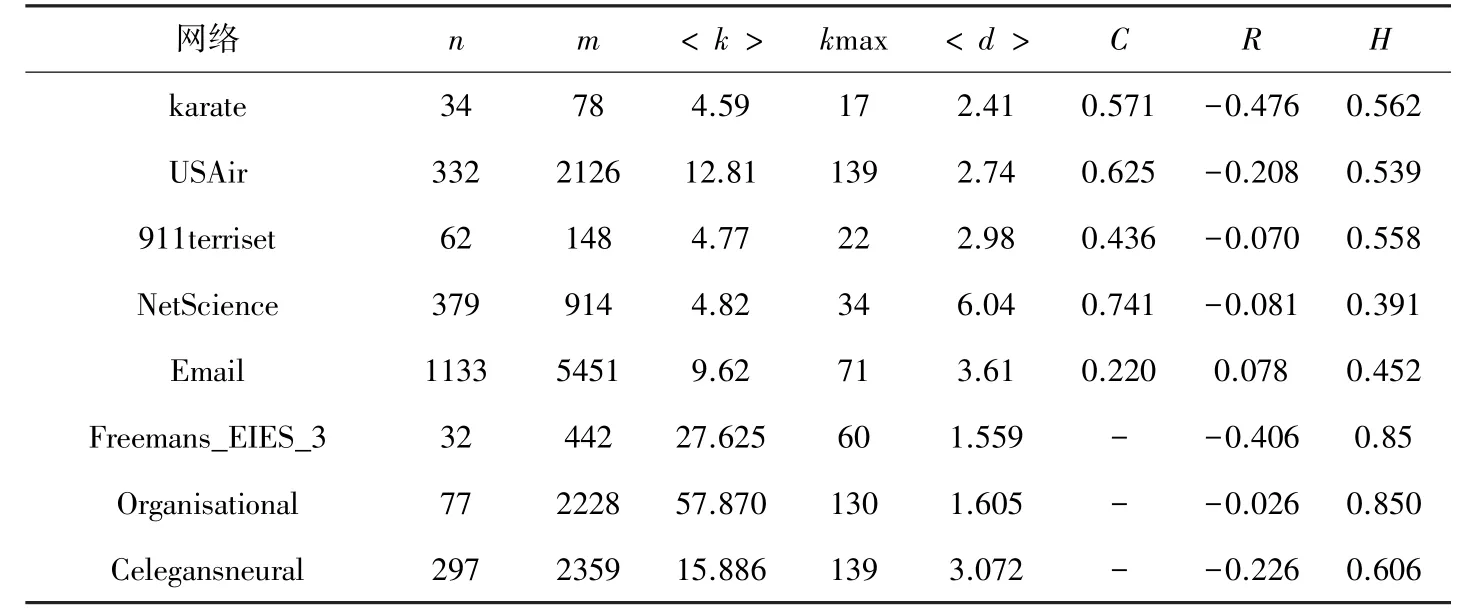
表3 数据集参数Tab.3 Parameters of datasets
GAS_D算法在5个无向网络中,各算法的中心性值与其它中心性算法之间的相似性分析图,以及Kendall tau的相似性系数如图2所示。与其它3种中心性算法相比,本文提出的改进算法GAS_D与改进前的AS算法相关性最强,单调性表现最明显,kendall tau的相似性值最大,与DC、CC算法的相关性次之。通过对单调性表现进行观察,GAS_D与CC具有更明显的相关性,与BC算法的相关性最不明显。GAS_D与DC、CC算法共同考虑了节点的度信息、节点间的最短路径,表现出了明显的相关性。在5个不同的数据集下,本文提出算法与改进前AS、DC、BC、CC算法的平均相似性见表4。karate数据集包含32个节点,且各算法识别出的Top10节点差别不大,故而基于SIR传播模型,进一步讨论其他4个数据集各算法识别出的Top10节点在不同感染概率下达到稳定状态的感染节点数占节点总数的百分比(式(14)),以此衡量Top10节点的感染能力(如图3所示)。
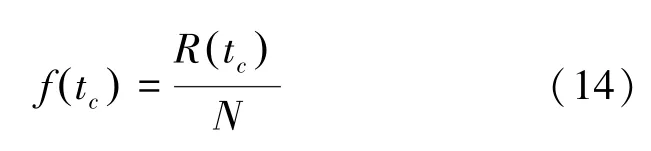
在4个数据集中均可以明显看出,当感染概率足够大的情况下,各方法识别出的Top结果在稳定状态下均可以覆盖整个网络;各中心性算法识别出的Top10节点不同的感染概率∈(0,1]下,达到稳定状态的结果趋势一致,没有表现出明显差异,说明了算法的有效性;在感染概率0.5左右,911terriset、Netscience数据集中,改进的GAS_D算法均优于改进之前的AS算法,感染节点数更多,说明本文算法的有效性,并且优于改进之前的算法。
文献[8]提出的吸收中心性方法并没在有向网络中进行拓展研究,本文将其拓展方法记为ZAS,并与提出的有偏随机游走改进之后的GAS_Dout、GAS_Din算法,在3个真实的网络进行对比研究,各算法之间的相关性及Kendall tau相似性系数如图4~图6所示。在Freeman、Organisational、Celegansneural数据集中,ZAS算法识别结果更接近于PageRank、LeaderRank;GAS_Din算法识别结果更接近于Pro_PageRank算法;GAS_Dout算法识别结果更接近于DPRank。在3个数据集下,ZAS、GAS_Din、GAS_Dout分 别 与 PageRank、LeaderRank、Pro_PageRank、DPRank的相似性见表4。
由表4中数据可见,ZAS、PageRank、LeaderRank均为等概率的向邻居节点进行转移,而GAS_Din、Pro_PageRank更倾向于向入度大的节点进行转移,GAS_Dout、DPRank更倾向于向出度大的节点进行转移,故算法之间表现出更强的相关性。Top10节点在不同感染概率下达到稳定状态下的感染节点率如图7所示,各算法识别结果的总体趋势相同,一定程度说明了ZAS、GAS_Din、GAS_Dout算法的有效性,GAS_Dout的识别结果也明显优于GAS_Din、ZAS算法,GAS_Dout的准确性更高。
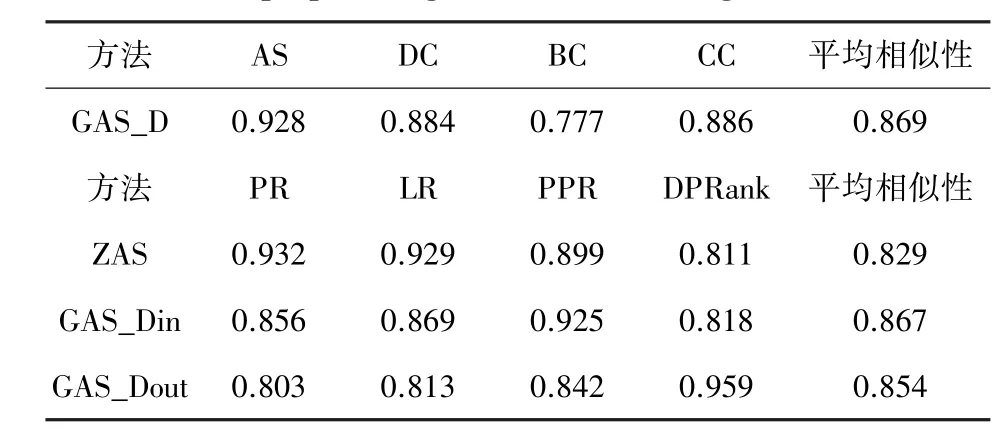
表4 本文提出算法与其他算法识别结果的相似性对比Tab.4 The similarity comparison between the recognition results of the proposed algorithm and other algorithms

图2 不同网络中GAS_D算法与其它中心性算法的相关性及Kendall tau相关系数Fig.2 Correlation between GAS_D algorithm and other centrality algorithms and Kendall tau correlation coefficient in different networks
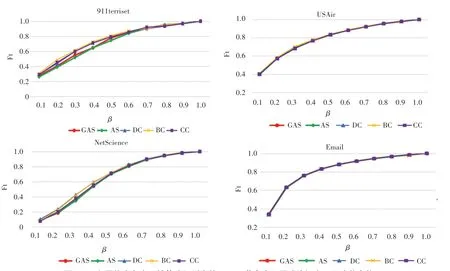
图3 无向网络中各中心性算法识别出的Top10节点在不同感染概率下平稳状态值Fig.3 The stationary state values of top 10 nodes identified by centrality algorithms under different infection probabilities in undirected networks
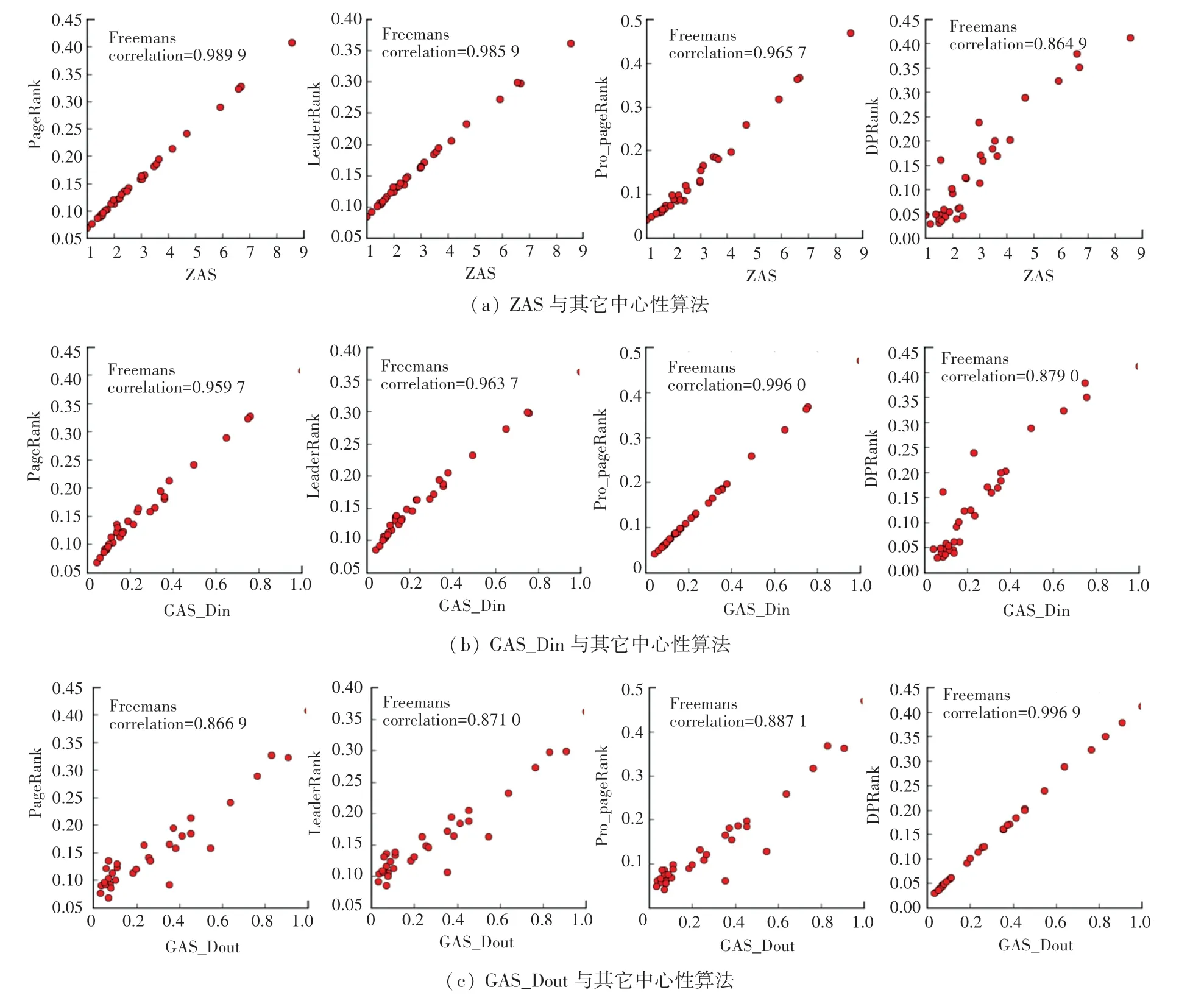
图4 Freemans中ZAS、GAS_Dout、GAS_Din算法与其它中心性算法的相关性及Kendall tau相关系数Fig.4 Correlation between ZAS、GAS_Dout、GAS_Din algorithm and other centrality algorithms and Kendall tau correlation coefficient in Freemans

图5 Organisational中ZAS、GAS_Dout、GAS_Din算法与其它中心性算法的相关性及Kendall tau相关系数Fig.5 Correlation between ZAS、GAS_Dout、GAS_Din algorithm and other centrality algorithms and Kendall tau correlation coefficient Organisational

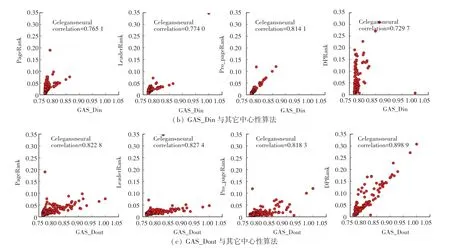
图6 Celegansneural中ZAS、GAS_Dout、GAS_Din算法与其它中心性算法的相关性及Kendall tau相关系数Fig.6 Correlation between ZAS、GAS_Dout、GAS_Din algorithm and other centrality algorithms and Kendall tau correlation coefficient in Celegansneural

图7 有向网络中各中心性算法识别出的Top10节点在不同感染概率下平稳状态值Fig.7 The stationary state values of top 10 nodes identified by centrality algorithms under different infection probabilities in directed networks
4 结束语
本文基于无向网络中等概率的吸收中心性方法,基于节点的度信息,提出适用于无向网络的GAS_D算法进行不等概率有偏的关键节点识别,并与节点的出度信息结合,将AS算法拓展到有向网络,结合邻居节点的出度和入度信息,提出GAS_Dout、GAS_Din算法。通过真实的无向网络和有向网络设计仿真实验证明:在无向网络中,本文提出的考虑现实网络中信息转移倾向性的改进算法优于改进之前的算法;在有向网络中,考虑邻居节点的出度节点信息对信息的扩散更有利,本文算法在有向网络中的扩展,也解决了PageRank及其改进算法的参数问题。后续工作将边值的权重考虑在内进行进一步的拓展研究。
