汉语方言自动聚类与分区及相关计算方法
2022-04-30江荻
江 荻
一、方言自动分区研究方法概述
确定方言之间关系是个极为复杂的事情,除了社会历史文化因素,主要涉及词汇异同、语音对应关系和词形借用,这是一个费时费力的缓慢发现过程。为此,近30年来,方言学界探索了一系列数学统计和计算机算法辅助研究方法来改善相关研究,称为方言关系计量法。计量法一方面试图取得更精细的方言关系数据,另一方面尝试简化研究手续和加快获取研究结果。迄今,主要有以下三类计量方法:特征统计法、词源统计法、词汇相似度计量法。
(一)特征统计法
分类学中,特征是事物分类的基本依据。由于特征能反映事物的结构和形式,同时特征又是人们在事物比较研究中普遍熟悉的内容,因此提取特征来反映事物之间的异同产生了特征统计观念。最早开展汉语方言特征统计的学者有郑锦全(1988)和陆致极(1987)等学者,我们以前者的研究为例。郑锦全(1988)的目的是考察汉语方言之间的亲疏关系,通过对汉语方言多个特征进行观察和统计来实现方言分类。郑文考察的特征主要有词汇异同、语音异同,后者又分为声母特征、韵母特征和声调特征。
依据特征分类有以下几个步骤,选择特征、特征赋值(量化)、特征相关关系分析和聚类分析。郑锦全(1988)以《汉语方言词汇》为统计材料,其中收录了905个普通话词条和18个方言的相应词汇形式,并由这两个参项构成二维数据表,即横行为方言点,纵列为词汇形式。然后用1/0(“有/无”)对字段赋值,例如“太阳”,北京、济南的赋值为1,西安、太原的赋值为0;“日头”,北京、济南的赋值为0,西安、太原的赋值为1。参见表1。

表1 为方言词汇赋值举例
由于各方言词汇差异,905个词条分解为6 454个词汇变项。最后,将赋值数据代入相关度计算公式(本文略),得出方言之间的系数,进一步绘出相关关系树图,参见图1。
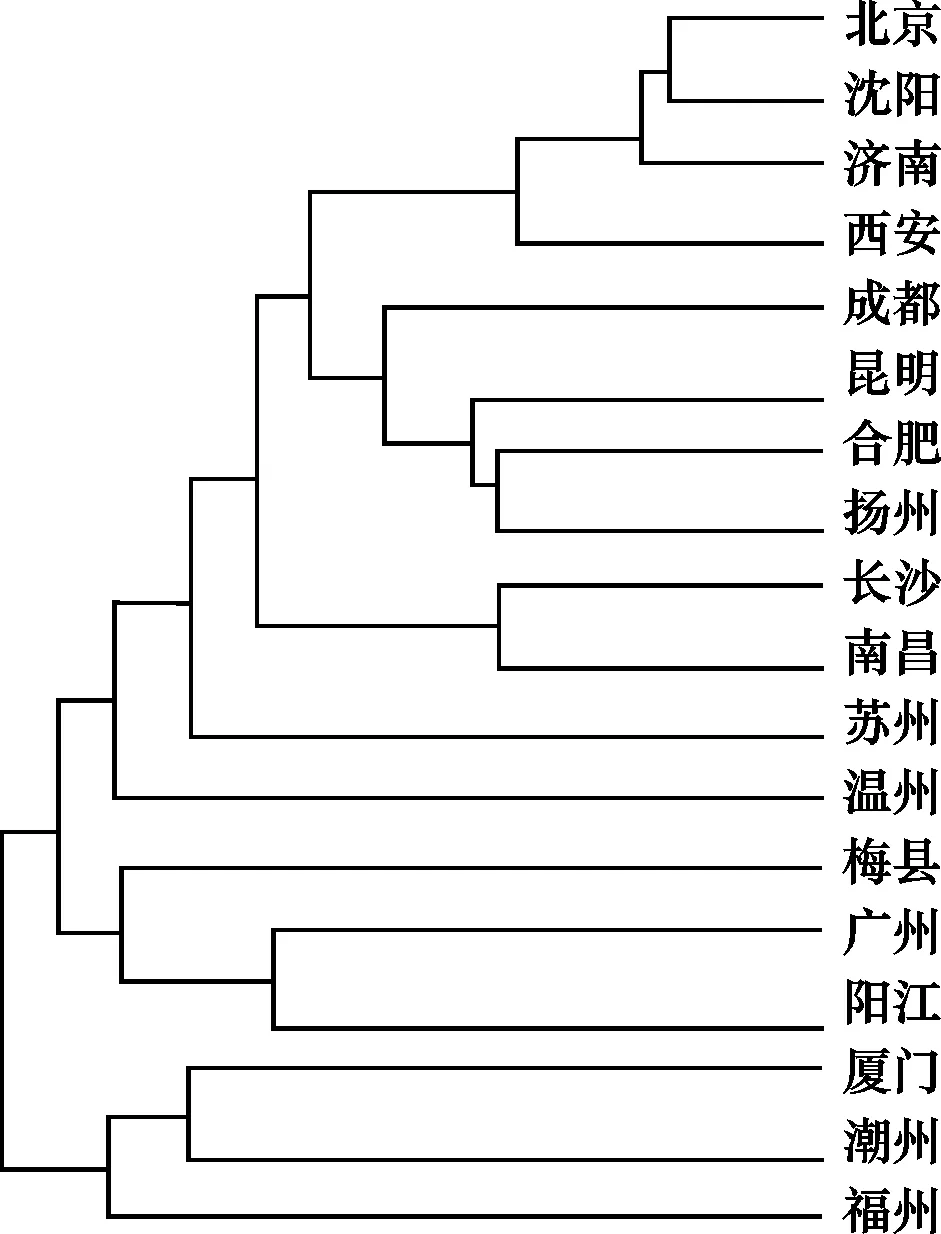
图1 《汉语方言词汇》词汇特征相关树图
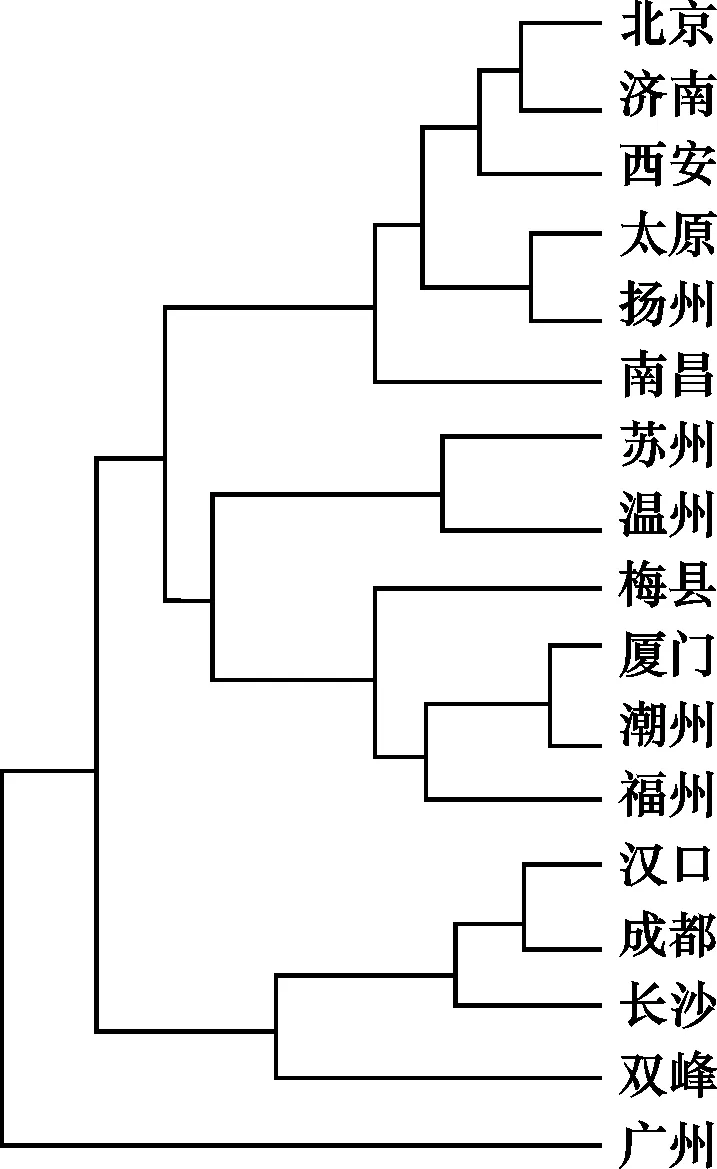
图2 《汉语方音字汇》声母特征相关树图
统计语音特征的时候,由于词汇长度特征不同,用词不一,郑文改用《汉语方音字汇》为材料。对每个声母特征按照出现频次进行统计,这跟上文词汇赋值方法不一样。郑氏还特别注意共时语音跟古代语音的衔接关系,这一点是采用共时音值跟历史音类对比方式开展的。例如来自中古p的方言p跟来自中古b的p分为两类。观察表2:

表2 郑锦全的汉语方音字汇声母出现频次统计(举例)
竖列第一个声母表示历史音类,第二个声母表示方言声母音值,横行是方言点,代表《汉语方音字汇》17个方言点,表内则是声母在方言点出现的次数。然后计算各方言声母相关系数,最后绘出根据声母特征得出的方言关系树图。参见图2。
特征统计法是一种显性方法,因此一直为人们所重视。例如,杨鼎夫、夏应存的《闽方言分区的计量研究》(1994)是一篇以声韵母特征为对象的方言分区论文,涉及35个闽方言点的亲疏关系研究以及分区。杨蓓(2003)虽然还是以语音特征为主,但采用的是吴语方言的声学信号作为实验对象,并辅以词汇相关度予以论证。王士元、沈钟伟的《方言关系的计量表述》(1992)是一篇概述性论文,以吴方言的44个亲属称谓词汇形式为例讨论分类分布现象,较为全面地对特征选取、计算方法和操作过程做了详细叙述。项梦冰的《聚类分析在汉语方言研究中的运用》(2015)也是很典型的特征统计,但文章焦点却是对聚类分析方法的检测,判断其有效性。谢建猷、张宗(2014)以广西方言为对象开展方言分区研究,并将分析结果与人工分区进行对比,结论是,对方言特征的人工统计分区跟计算机计量分区可以实现殊途同归,即二者都可实现分区目的。这项对比研究肯定了计算机分类和分区的作用和价值,是一次相当有益的尝试。
(二)词源统计法
词源统计法源自语言年代学(glottochronology),用来衡量相关语言从共同母语来源分离出来的程度,由于它是对假定有亲缘关系语言中一组组词汇项目的变化速度进行定量比较,从而推算这些语言分离后的时间差距,因此也叫做词汇统计法(lexicostatistics)。
语言年代学最初由斯瓦迪士(Swadesh 1952)提出,他受到化学上发明的碳-14年代测定法的启示,认为,一定存在一组基本的词来描述存在于各种语言中的普遍现象。这种基本词汇包括表示身体部分的词(头、手等),表示自然物体的词(月亮、山脉等),表示共同活动的词(来、睡觉等),以及表示一些其他范畴的词。实际上,要确定这样一种基本词汇是相当困难的。斯瓦迪士先提出了200词,后又减少到100词。相对于历史语言学的比较法,语言年代学算是一门新的技术。语言年代学自20世纪50年代初提出后,由于其本身固有的一些严重缺陷,长期以来该方法一直未获得较大成功案例的支持,加之用途有限,引起的争议也不少,所以往往被人们忽视,使得该方法未得到广泛运用。进入21世纪以来,由于生物学种系发生树理论的不断完善和计算机的巨大进步,从语言年代学概念派生出更单纯的词源统计法又开始受到历史语言学家的重视。
词源统计法是借用生物学上关于物种进化关系的分析方法来分析语言的亲缘关系。理论基础是有亲属关系的语言在演化过程中,其基本词汇的演变转化程度不同。词源统计分析不仅可以显示各种语言的亲疏关系,更可以显示出语言之间的亲缘距离。国内开展过此类研究的有邓晓华、王士元(2009)对于苗瑶语族、藏缅语族和壮侗语族的分类研究,林天送等(2010)对闽方言所做的语言或方言的计量分类研究。
词源统计分析的基础和前提是同源词的选取。如何优选同源词,设计一种通用基本词汇表是词源统计分析的最重要步骤之一。这个问题一直存在较大争论。同源词同样有历史文化层次的差别,有的同源词较容易被借用,有的同源词被借用的概率较低。其次,择词依赖于专家经验,也容易引起争议。词源统计研究常见的选择是斯瓦迪士100词表或200词表。
开展汉语方言词源计算研究影响度较高的是徐通锵的研究(1991),他在《历史语言学》专著中独辟一章(17章:语言年代学)介绍斯瓦迪士的语言年代学及其计算公式,又以汉语方言词源讨论分区和分类。徐文提出:“可以利用(斯瓦迪士100词)这个修正表计算汉语在发展中的词汇保留率,以检验斯瓦迪士、李兹的保留率常数的可靠性。计算的对象以基本词根语素(Basic-root-morphemes)为准,不算前缀、后缀等词缀,只要某一词根语素(不管是单用还是保留在复合词中)的意义古今没有什么变化,就算是同源的成分”。经过计算,获得古今汉语同源词根语素比率为66%。对古汉语年代初步拟为距今2 300年,即先秦汉语年代。再将这些数据代入斯瓦迪士语言年代学公式,则计算出古今汉语一千年词根语素保留率为0.834 74。最后,据此测算汉语方言之间的同源词比率,发现厦门话和苏州话的共同保留率为59%,北京话跟厦门话之间的共同保留率是56%。

表3 百词表中汉语七大方言同源词比率(徐通锵 1991)
再用李兹(R.B.Lees 1953)公式测算分化的年代,得到如下结果:


(三)词汇相似度计量法
近十余年,以词汇相似度为题的研究陆续开展起来。邵慧君、秦绿叶(2008)在词汇相似度上不仅以语素为统计对象,同时增加了构词法参项的统计。文章认为,如果比较对象的语素部分相同,构词法不同,则它们相关关系的区分主要体现在构词法的不同。构词法差别越大,则相关系数越小。这是一个很有意思的创新,其中可能蕴含了词源的差异。如果两个方言共同继承自早期方言,则不同构词结构要么来自第三方言的借用,要么是各方言自身词汇创新。无论哪种来源,二者都产生差异,需要人工判定。文章在赋值上完全以方言语素为单位,甚至考虑了有音无字的情况。依照通用的Jaccard分类方法,方言之间语素和构词法出现的情况有“双有”、“有无”、“无有”、“双无”四种,赋值则以0和1对应“有”和“无”来赋值。对于两种方言中同一词项的多种反映形式,文章处理强于徐通锵(1991)仅选择对应第一项的僵硬办法。文章提出:“当两种方言中同一词项有多种反映形式时,先找两种方言中所有的形式,综合考察它们的词素和构词法在两种方言中的‘双有’、‘有无’、‘无有’的情况,然后确定这三个系数的值,最后根据公式从而求得这个词项中两种方言的相关系数。”在此基础上,文章分别计算了广州粤语跟梅州客家话的词汇相关关系,廉江粤语跟廉江客家话的相关关系。参见表4和表5:
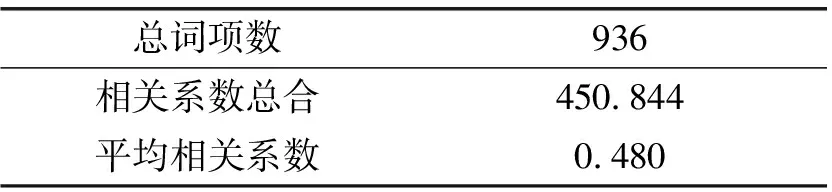
表4 广粤—梅客词汇相关关系

表5 廉粤—廉客词汇相关关系
文章分析说:廉江地区粤客方言的平均相关系数高于广梅的粤客方言平均相关系数,说明廉江地区粤、客方言由于接触频繁,使得其词汇的融合程度加深,它们的相关系数也因此增大。文章最后对廉江粤客词汇相似的结果做了历史文化方面的解析,探讨了词汇相似度与方言接触的关系和接触程度。
类似的研究还有粟春兵、王文胜(2011),所使用方法与上述邵文基本一致,通过方言词汇相关度的计量,对梧州话和倒水话1 300多词项进行定量统计分析,讨论了梧州粤语和周边勾漏粤语的相似程度。郑伟娜的《四邑方言词汇相似度比较分析》(2017)是一篇纯粹以词汇形式为对象的相似度计量文章,文章主要贡献是指出王士元、沈钟伟(1992)的计量法和加权平均法均存在不足之处,提出语素加权法,即将每个词目权重设定为1,并根据词中语素的重要程度为每个语素加权,又在语素加权的基础上,将构词法纳入考虑,计算其相似度。其中,构词法参数纳入应该是参考了邵慧君等的方法。加权方法则涉及词源价值。例如,文章提出:“阿公”和“阿爷”的附加语素相同、核心语素不同,而“红薯”和“番薯”的修饰语素不同、核心语素相同,在不加权的情况下,两组词相似度一致;若是加权,则可能反映出第二组词在语源上更加接近。文章具体加权操作等技术问题此处不赘,其结论是:粤语四邑方言七个点与广州话的亲疏远近关系可以通过词汇相似度计算获得。
以上三种计量方法各有侧重,特征统计限定于单一特征的考察,覆盖面相对较窄;词源统计过于依赖专家的同源经验择词,包含可能的主观偏差;词汇相似度统计多用汉字,本质上也是一种特征分析,甚至会受到汉字同形符号的影响。为此可以说,这三类计量方法都是客体受限的、非整体的对象考察方法。针对这样的状况,学术界开始寻找更适合的计算模型,其中数学上的Levanstein Distance(莱文斯坦距离,或称编辑距离 1966)对两两语言之间字符串的语音相似性和词汇对应性都有效用,可计算性较强(M.Serva 2008)。其次,Levenshtein算法数理逻辑上称为“动态规划”,逐项计算字符串单元时会同时调用之前单元运用的数值,即动态规划的子问题之间不完全独立,一个子问题可能会影响后续不同阶段的状态。总之,Levenshtein算法是动态规划思想的经典算法,每对子字符串的距离都由之前数个距离值共同决定。这意味着方言之间关系可以通过词项的全局性算法加以解决。
二、聚类分析的方法和理据
(一)序列比对方法
人们说的话记录下来呈现为符号的线性序列,两个符号序列是否相同需要对比分析。这种方法在本实验中称为词形序列比对或序列对比。序列比对是通过将两两语言或方言的词形相互比较来寻找词形可能具备的特性和对应关系。也可以说,序列比对是运用某种特定数学模型或算法,找出两个或多个序列的最大匹配符号,比对的结果反映了序列之间的相似关系,即词形的相似关系和程度。再进一步可以判断序列之间的同源性,推测序列之间的演化关系。
比对一般采用双序列方式,即对两个词形的构成音素进行比对操作,在各个音素之间建立对应关系。两个音素是否构成相似对应需要事先设置规则,这样就能在确定的序列位置判断两两音素是否相同、相似,或者相异。本文双序列比对采用动态规划中较为成熟的Levenshtein距离,又称编辑距离,该方法由俄国数学家Vladimir Levenshtein(1966)提出,用来衡量两个字符序列之间的差异程度。Levenshtein距离的计算方法是统计一个字符串变化成为另一个字符串所需要操作字符的次数,一般取最小操作次数,字符操作包括增加字符、删除字符、替换字符。操作次数表现为一种客观量,可以直接作为符号序列之间差异的赋值数或权值,即每种操作的成本(即距离)为1。例如,源字符串cat与目标字符串hat,比对二者,从cat变化到hat需要将字符c替换为h,因此Levenshtein距离为1;又如cat与cafe,将后者设置为目标字符串,则需要将前者t替换为f,再增加字符e,共需要经过1次替换和1次增加,因此距离值为2。Levenshtein距离计算公式如下:

通常,Levenshtein距离计算过程采用矩阵方式逐步分解,并用回溯路径加以验证和理解。此处我们用简单比对方式对源字符串saturday转变为目标字符串sunday略作说明。序列比对有一条原则是“获得序列之间最大的相似性排列”,因此图3中只有c是合适的比对,操作赋值为3,a和b的赋值都大于3。字符下的下划线代表该字符经历过替换、增加或删除操作。

saturdaysunday

saturdaysunday

saturdaysunday



(二)构建系统发生树
在理解Levenshtein距离计算方法的基础上,我们进一步考察系统发生树的构建方法。语言之间相似距离计算的结果产生后,人们常用一种直观的图形方式来表示语言之间的相似关系,这种方式借鉴自生物分类学和当代分子生物学,称为种系发生树(phyligenetic tree),也称进化树或演化树(evolutionary tree)。语言系统发生树蕴含了语言演化的渊源关系,因此也被看作是语言之间的亲缘关系树。系统演化树可以呈现语言之间的相关距离数值,如果能够将历史事件时间或者考古等其他反映的历史时间与语言关联起来,作为计算的参数加入系统发生树的构建,则可以将距离数值转化为历史时间,由此估算语言起源和演变发生的真实时间。本文暂时未将真实历史时间加入其中,因此仅讨论方言之间的距离关系。
构建系统树的方法目前主要采用计算机来完成。较为常见的进化树构建软件很多,采用不同的数学模型。例如UPGMA(Unweighted Pair Group Method with Arithmetic Mean,平均连接聚类法)、ME(Minimum Evolution,最小进化法)和NJ(Neighbor-Joining,邻接法)等。本项实验采用MEGA软件对数据进行处理并构建语言演化树。MEGA是美国学者开发的一款功能极为强大的分子进化遗传分析软件,全称是Molecular Evolutionary Genetics Analysis。它最强大的功能是计算遗传距离、构建分子系统树,适合用于分析语言演化,算法模型包括最大简约法、最大似然法等统计学方法。
目前,世界范围内,Levenshtein距离方法已广泛用于各种科学研究领域,尤为计算生物学领域所采用。在自然语言处理领域,人们也开始采用该方法,并取得很好的效果,例如机器自动分词、术语识别和提取、语义内容计算等等。特别应该提到的是,德国马普研究院(Max-Planck-Gesellschaft)的进化语言学研究所(Institute of evolutionary Linguistics)在20世纪90年代就设立了ASJP项目(The Automated Similarity Judgment Program,自动相似性判断),利用世界数千种语言采集的40个基本词汇来自动重建语言之间的关系和世界语言分类,并取得积极的效果,引用面相当广泛(Holman et al. 2011)。
近年来,国内以Levenshtein距离方法研究语言和方言的成果还不多,例如江荻(2017)、赵志靖、江荻(2018)、冉启斌、索伦·维希曼(2018)。汉语方面则只有索伦·维希曼、冉启斌(2019)。
Levenshtein距离算法模型对方言语音数据、特征和结构进行分析和归纳,将相似程度最大的字符串(词语)聚为一类,相似程度最低的聚到另外的类,多个聚类之间就会形成相似程度的队列。这就是我们所说的方言关系的远近亲疏关系。计算机聚类算法实际上给人们提供了关于方言分类或分区的数据,在这个基础上,人们结合传统分类来观察算法的优劣。如果聚类结果与传统分类完全不吻合,或者完全不相干,则可以怀疑算法设置不合适;如果聚类结果与传统分区大致吻合,又有不同,则需要考察其他因素。例如不同方言数据编码符号不规范不统一,或者计算参数设置不合理,或者方言点选取地理上疏密度差距过大等等。总之,检查数据规范性,调节算法细节设置,平衡方言选点数量,通过反复实验达到算法模型的最优状态。
还应该提到,按照系统发生树理论,我们运用的MEGA软件也提供了“树根”或外类群设置功能。本实验也以俄语和法语作为根或外类群对汉语方言聚类进行测试,但非常明显的是,无论是否采用树根测试,汉语方言内部聚类(或分区)并未受到影响,这是汉语方言同属一种语言的证明。下文第3节的实验不纳入根和外类群数据。
三、汉语方言的自动聚类和分区
(一)方言数据
本文采集的数据大致按照学界观点分布于各个分区,总计186个方言点。按照现有分区可作如下归类,并列出方言点名称,名称后括号内列出该分区的数据文件代码和方言点数量。
东北官话(HDB:9):长春、哈尔滨、海拉尔、黑河、佳木斯、锦州、齐齐哈尔、沈阳、通化
北京官话(HBJ:7):北京(西城)、承德、朝阳、门头沟、密云、平谷、延庆
冀鲁官话(HBF:12):保定、沧州、德州、济南、聊城、石家庄、泰安、唐山、天津、潍坊、邢台、淄博
胶辽官话(HJL:7):大连、丹东、蓬莱、青岛、烟台、营口、诸城
兰银官话(HL:10):哈密、酒泉、兰州、山丹、乌鲁木齐、武威、吴忠、银川、张掖、中卫
晋语(HJ:12):长治、大同、呼和浩特、离石、临河、吕梁、绥德、太原、吴堡、忻州、阳原、张家口
西南官话(HN:23):毕节、常德、成都、重庆、大理、达县、桂林、贵阳、汉源、吉首、昆明、黎平、柳州、蒙自、南充、天门、武汉、襄樊、西昌、宜昌、昭通、自贡、遵义
中原官话(HZ:28):宝鸡、蚌埠、郸城、敦煌、阜阳、赣榆、固原、淮北、开封、临洮、临夏、漯河、洛阳、门源、南阳、濮阳、睢宁、宿迁、西安、西宁、信阳、新沂、西峡、许昌、徐州、延安、郑州、驻马店
江淮方言,简称淮(HS:9):合肥、淮安、南京、如皋、泰州、芜湖、盐城、扬州、镇江
赣语(HG:9):东乡、高安、吉安、黎川、南昌、上高、万载、修水、余干
徽语(HH:10):淳安、建德、绩溪、流口、秋口、歙县、寿昌、遂安、屯溪、溪口
吴语(HW:10):崇明、杭州、黄岩、溧阳、宁波、衢州、上海、苏州、温州、永康
闽语(HM:10):潮州、福州、海口、建瓯、雷州、泉州、台北、文昌、厦门、中山
粤语(HY:11):东莞、封开、广州、迈话、南宁、韶关、台山、藤县、香港、新会、阳江
客家话(HK:9):北流、从化、柳城、龙南、梅县、宁都-客、石城、铜鼓、新竹
湘语(HX:10):长沙、衡阳、娄底、宁乡、双峰、武冈、湘潭、湘乡、永州、株洲
各方言选点上有两个特点,一是代表性方言点,例如省市自治区中通常会选择省会城市;二是各方言点数量上大致相近,唯中原官话和西南官话地理分布太广,选点数量较多。
少量方言区或方言点的归属传统分区和分片存在一定争议。例如,徽语究竟独立为与吴语、赣语平行的方言区还是归入吴语下划片(如吴语徽严片)。本文以《中国语言地图》的分区为准,将徽语列为分区方言。
(二)全部方言聚类图
本文从186个方言获取的聚类如图4所示。全部材料设置为16个方言分区,北方方言有8个分区,108个方言点,南方方言有8个分区,78个方言点。图中列出参与分区的方言点名称,包括分区代码和方言点地名的拼音形式,代码所指参见3.1节分区名称约定。例如HBJ代表北京官话,HG代表赣语,HG_nanchang表示赣语南昌话。
本项实验基本是共时平面聚类,这是因为我们不设立方言根概念。根据历史语言学原则,如果各方言之间存在可能的母语或母语方言,就有可能把方言分区看作母语方言的演进和分化。但在实践上,人们已经十分明确,汉语各地方言虽然可能存在早期的起源区域,但总体上是历史人口迁徙和方言接触逐步造成的(葛剑雄,1997)。
聚类图中有一个值得指出的现象是,北方方言和南方方言出现交互混淆的现象。图4显示出,湘语中的新湘话,包括长沙、株洲、湘潭这个城市群的方言间入了西南官话群。再就是江淮方言,该方言基本是在吴语基础上跟不断南下的历代北方人的方言长期融合而逐渐形成的(詹伯彗、张振兴,2017)。不过,江淮方言的综合性特征使其在图4中处于南北方言交界位置。可能既有南方方言特征,也吸收了北方方言特征,本文不称“官话”,改称江淮方言(或淮语),暂并入南方方言。图4中,我们用具体方言名称标示出混入其他方言分区的方言点,请注意带框方言点名称。

图4 186个方言点聚类图(分区)
(三)南方方言分区实验
这一节我们观察南方方言的分区。Levenshtein距离算法聚类如图5所示。
该项分区的一项重要特点似乎颠覆了我们习惯的观念,即南方方言差别大,相混情况严重。实际上,本项实验中的南方8大方言分区,多数方言点未发生特别的互混现象。
本项实验展示出南方8大方言相互之间的层次或关联关系。根据本次实验,南方方言总体框架之下,又可分出两个集群,一是粤语—客家—闽语群,其中粤语和客家更接近;其次是吴语—湘语—徽语—江淮群,而赣语则与吴、湘、徽均有关联。大致呈现为图6所示状态:
从地理上看,赣语跟粤、闽、客也存在密切关系。据《中国语言地图》,赣、客主要是不同时期历史移民形成,而客家话地理上处在赣南、闽西、粤北、湘东之间,赣语则西接湘语,湘语又历史上跟吴语密切。为此,赣、客地理分布的独特性把所有南方方言串联起来了。
吴语跟徽语的关系主要来自移民影响。据葛剑雄(1997),徽州地区秦汉时期属于吴语区,西晋永嘉之乱导致北人大量迁入,此后唐代以来又有大量移民,加之该地四面环山,语言封闭发展,逐渐与吴语差别拉大,形成新的方言。

图5 南方方言聚类与分区(右图接续左图)

图6 南部方言关系
湘语最早源头可能是古代楚语,“是‘楚语’的嫡系或支系,同时也是吴语的近亲”(袁家骅,1991)。甚至还有“吴湘一体”的说法(桥本万太郎,1978)。只是后来赣客迁入和形成,将吴语和湘语分隔开来,各自独立发展,造成不同方言区域。
本文主要目的是探索汉语方言自动聚类和分区的可能性,但是,我们也发现,如果算法模型设置恰当,对于分区之下的方言片,本系统也具有较好的自动分类价值。下面举例讨论。仔细观察各分区内部方言,也会发现十分有趣的现象。(1)海南省三亚市迈话的归属一直存在争议,有人认为可归为闽语(梁猷刚,1984),或作为混合方言(黄谷甘、李如龙,1987),有人则归为粤语(欧阳觉亚、江荻、邹嘉彦,2019)。在本实验中,迈话处于粤语最边沿,正与迈话的地理分布相应,也算是粤语西南部分布的末端。(2)上文3.2节提到长沙—湘潭—株洲新湘语城市群混入西南官话,本次单独南方方言运行后,则该群回归湘语,说明这些方言点还是拥有大量湘语特征。(3)据林伦伦、陈小枫(1996)研究,广东省中山县隆都等地有少量居民说闽语,这是十分典型的粤语包围中的闽语方言岛。由于粤语长期的影响,该地闽语已吸收大量粤语词汇语音特征,分辨不容易。本项实验对这类具有混合特征的方言也具有较强的区分作用,中山闽语的分类位置处于广东和广西闽语的最边沿。
总体来说,南方方言的聚类和分区中没有任何一个方言点的归属与传统分区不一致。说明Levenshtein距离模型具有较强的聚类分析功能,而本实验的设置也符合汉语方言事实。
(四)北方方言分区实验
北方方言地理分布面积远超南方方言,共分出8类。观察图7不难发现除了晋语,其他各类方言分区都有相互间入的其他分区方言,本图已将主要间入其他分区的方言点标出(带框方言点)。

图7 北方方言聚类与分区(右图接续左图)
以下针对某些间入其他分区的方言点逐个说明,没有互间或轻微混间的分区不加讨论。
(1)东北官话聚类。这个分区中插入了胶辽官话的丹东和大连。但是,十分明显的是,这两个方言点地理位置紧靠东北方言。换句话说,传统分区将地理上与东北方言相连的部分方言归入胶辽方言是否合适?因为这两大分区之间隔着辽阔的渤海。当然,这个问题极为复杂(大连、营口、丹东甚至是不同分区小片),涉及历史移民现象。下文还会看到渤海北面的辽宁营口(盖桓片)与渤海南面山东蓬莱、烟台(登连片)构成聚类,这都涉及选择分区标准问题。上文曾讨论词汇的一致性和语音的对应性,我们相信更有利的决策应据此权衡。
(2)东北官话的海拉尔和哈尔滨、锦州分别间入冀鲁官话(河北群)和北京官话。已知的情况是,东北官话与北京官话语音上的相近多于二者的相异,估计重要的区别可能来自词汇。我们推测哈尔滨和锦州词汇上与北京官话相差不大可能促成这样的混入。海拉尔间入胶辽官话的原因还需进一步研究。
(3)中原官话聚类。该分区横贯中国中部地区,分布区域是:江苏、安徽、河北、河南、山西南部、陕西大部、甘肃、宁夏、青海、四川、新疆,从东至西大约在北纬34±2°范围之内,其跨度之广,远远超过其他方言分区,本实验采集了28个方言点,是分区实验中数据最多的。正是由于中原官话形成一条长形地域,它的北南两面均受到其他官话方言挤压,不可避免有一些其他方言的间入,或者其自身方言也可能间入其他方言。例如它的南面与西南官话相交,其中武汉、贵阳、湖南的常德就混入进来,还有胶辽官话的蓬莱、烟台和营口也穿插进来,其中的原因还需考证。反过来,最东面的徐州等徐淮片的中原方言点混入冀鲁官话,原因应从地理上解读。
(4)兰银官话聚类。兰银官话方言点集中在甘肃、宁夏,因移民原因也出现在新疆北部地区。兰银官话与中原官话有不少共同区域,因而也有相互混入的方言点。青海的西宁和门源按照语言特征一般归入中原方言,本实验间入兰银官话,说明受到周边兰银方言接触的影响。但也有部分间入兰银官话的中原方言点还不容易解释,例如河南的西峡和南阳邓州点。
(5)冀鲁官话聚类。本实验的冀鲁官话分为两个小聚类,一是河北聚类,一是山东聚类。后者之中混入了胶辽官话的青岛和诸城两个方言点,其中原因应该不难解读,与方言相邻和接触有一定关系。
以上讨论只是对自动分类模型产出结果的初步观察,不能作为分类正确与否的标准。这里特别需要提出一条经验:本实验经历了上百次方言点数量调整,发现增减方言数量是调节分区准确性的重要手段。这是因为每个方言,甚至每个词都是影响方言关系紧密程度的一环,相近方言点数量多,内部关联密切就更容易聚类,数量少则聚类就松散。例如我们在总数为70左右方言点计算时,曾针对信阳归属中原官话还是西南官话进行实验(信阳地理位置处于两个分区边沿),通过增减或替换信阳周边这两个分区方言点数量,发现如果西南官话数量增多,勾连信阳话中的西南官话特征增强,信阳有可能转而归入西南官话。这说明信阳方言点自身包含了两个分区的特征,并形成一定的均衡性。
四、结 语
方言原本是在历史过程中形成的,有历史演变因素,也有方言共时接触影响因素。汉语方言之间的亲疏远近关系通常表征为分区和划片,分区和划片实际上是将语言亲缘关系映射为地理分布,将语言的历时演变关系转换为共时平面呈现。这种事实让我们有机会采用数学或计算机算法对方言之间的关系开展研究,本文采用Levenshtein距离数学模型和聚类分析实现了传统依赖方言特征比较的分区,其中的原因之一就是方言产生过程中自身发展的逻辑性、规律性和相似性。虽然实验结果与传统分区对照是判断本算法模型效度和精度的准则,同时却又能反过来为分类设置的分区标准提供新的思路。
我们相信,本文采用的Levenshtein距离算法对汉语方言分区划片,乃至具体单个方言的区片归属均能提供参考意见,为汉语方言研究提供了新的研究方向。
