基于数字孪生的医保宏观决策深度强化智能应用研究
2022-04-29吴永飞王彦博解立伟杨璇刘曦子徐奇宫雅菲何姗巨春武
吴永飞 王彦博 解立伟 杨璇 刘曦子 徐奇 宫雅菲 何姗 巨春武
摘要:医疗保障体系的健康发展一直以来都是事关国计民生的重要工作。基于此,提出医保宏观决策的“4S”框架,聚焦“基本医疗保险基金的定额分配”应用场景,构建数字孪生仿真模拟环境,并将智能围棋机器人AlphaGo Zero底层的深度强化学习技术进行了优化改进,将该类人工智能技术应用于医保领域。运用构建在数字孪生仿真模拟基础之上的深度强化学习技术,旨在解决由道德风险和逆向选择所导致的医保基金运行风险问题,探索实现该领域社会资源分配达到社会效用最优的智能化解决方案。
关键词:数字孪生;仿真模拟;深度强化学习;医保;宏观决策
0 引言
我国现行社会医疗保险体系由2种制度组成:一种是城镇职工基本医疗保险制度;另一种是城乡居民医疗保险制度。2021年,全国基本医疗保险参保人数达13.64亿人,参保率稳定在95%以上。2021年,全国基本医疗保险基金(含生育保险)总收入达28 710.28亿元。本文聚焦城镇职工医疗保险制度,探索如何智能化地合理分配医保基金,以期为医保基金的合理运行及风险规避提供借鉴。
1 医保业务背景概述
1.1 我国主要医保支付制度
当前我国主要医保支付制度为总额预付制和DRGs预付制2种[1]。总额预付制是指在考虑宏观经济因素的前提下,根据一定区域内参保人数、年均接诊总人次数和次均接诊费用水平等信息,对区域内年度统筹费用总额进行测算。DRGs预付制全称为诊断相关组—预付费制度(Diagnosis Related Groups-Prospective Payment System),是指在国际疾病诊断分类的基础上,对各个分类组别的付费标准进行科学测算,并进行预先支付。该机制由美国率先研究,已在我国北京进行试点,近年来在全国范围内逐渐推广。
1.2 医保行业中的道德风险和逆向选择
医保行业中的道德风险和逆向选择问题自20世纪60年代以来就成为困扰人类社会的世界性难题。自诺贝尔经济学奖得主肯尼斯·约瑟夫·阿罗于1963年提出社会医疗保险存在逆向选择和道德风险的问题以来[2],全球各国的大量实证资料不断印证了上述难题的存在。
道德风险主要体现为事后风险。在医保资金充足的情况下,对于医疗服务的需求方,即患者来说,医保基金的慷慨支付会导致参保人员过度医疗,浪费医保基金资源;对医疗服务的供给方,即医疗机构来说,可能存在凭借信息垄断优势增加患者医疗支出的情况;更进一步,还可能催生供需双方合谋的道德风险,即医疗机构与参保人员通过合谋骗保,以套取医疗保障资金等情况。
逆向选择主要体现为事前风险。对医疗服务的需求方来说,共付制作为一种个人与社会医疗保险机构共同负担一定比例医疗费用的机制,参保人的医疗费用在起付线以上、封顶线以下部分主要由统筹基金支付,但个人仍需负担一定比例,在医保资金不足的情况下,可能导致部分健康人员参保意愿下降;而对医疗服务的供给方来说,在医保资金有限的条件下,医疗机构在医疗技术和设备方面投入不足往往使服务质量下降,参保人员住院困难,会导致患者不愿意到水平较低的医疗机构就医,从而导致该类机构的投入浪费。同时,逆向选择也会引起医保基金的道德风险和运行风险,因此在预付制环境下构建一套可以精确分配并可通过极端压力测试的资源配置机制是当前降低医保基金运营风险的破局之道。
2 基于数字孪生的医保宏观决策深度强化智能解决方案
2.1 医保宏观决策“4S”框架
为进一步清晰定义医保行业业务需求,本文首先从医保行业全局视角出发,提出医保宏观决策“4S”框架,将医保体系划分为4个领域,即业务经办体系(Standard operation & supply chain)、公共服务体系(Social service)、业务监管体系(Supervision & regulatory affairs)和决策分析体系(Strategy making & decision support)。其中,业务经办体系侧重医保行业主要的业务流转和管理环节;公共服务体系侧重医保体系面向接受服务的社会公众及利益相关机构的交互路径与信息传导机制;业务监管体系从防控医保资源滥用、减少欺诈的立足点出发,对医保领域业务监管事务进行梳理;决策分析体系立足服务于医保决策机构,对医保体系中涉及宏观决策和分析的重要课题进行难点梳理。
当前,随着信息科技的不断发展,人工智能针对医保领域上述四大体系的需求均可提供针对性解决方案——医保全流程中涉及的业务经办、公共服务、业务监管和决策分析四大体系分别对应了该领域“业务流程精细化”“用户体验便捷化”“欺诈识别自动化”“宏观决策智能化”四大核心需求。当前,“业务流程精细化”和“用户体验便捷化”2项需求已在市场环境中得到了较充分的满足。然而,对“欺诈识别自动化”和“宏观决策智能化”2项需求的充分满足一直以来都是痛点和难点。
本文聚焦“4S”框架中的决策分析(Strategy making & decision support)领域,针对“城乡居民基本医疗保险筹资标准”“医保支付管理”“基金监督管理”等一系列典型医保宏观智能决策场景展开针对性研究,基于数字孪生和深度强化的通用智能解决框架,为上述工作提供全新的策略及解决方案。
2.2 数字孪生环境构建
数字孪生仿真环境的构建是开展深度强化学习的基础[3],深度强化智能适于解决医保宏观决策中的多层次动态博弈决策问题,本文以服务医保体系完成年度定點医疗机构医保基金费用配置为起点展开研究。相关方案可迁移至如下场景:医疗保障局对于总额预算管理的定点医疗机构进行年度医保基金资源分配;定点医疗机构内设的绩效运营办公室等部门通过科主任联席会等方式在医院内部进行分配;定点医疗的科室内部将医保基金的资源配置到每位医生身上,确保总额控制等。
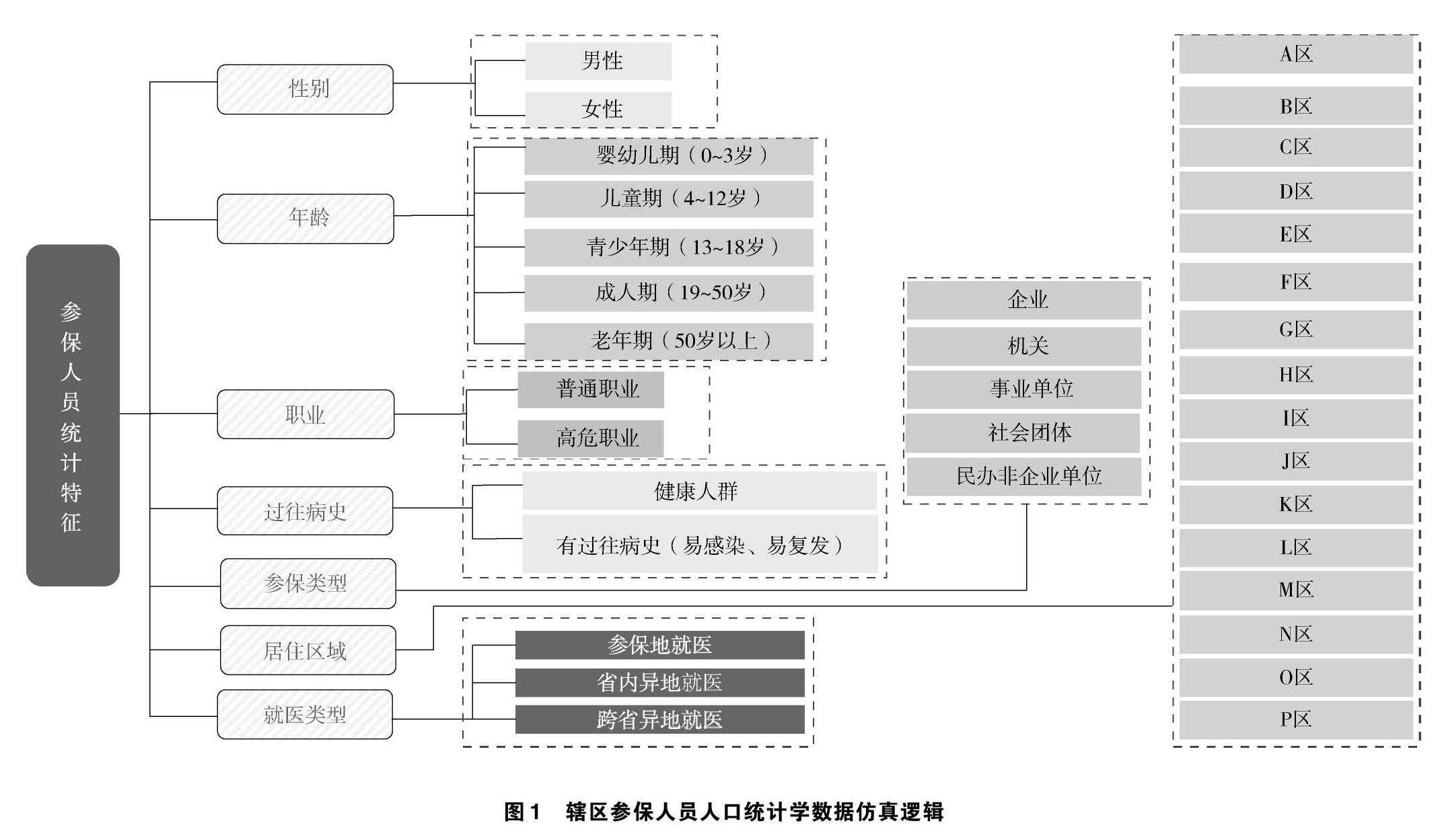
基于情况调研和现有数据,本文分别构建了辖区参保人员人口统计学数据仿真、定点医疗机构医疗资源数据仿真、医疗保障涉及疾病及医疗资源消耗数据仿真3种数字孪生仿真环境。在辖区参保人员人口统计学数据仿真方面,本文根据参保人员的统计学特征,从性别、年龄、职业、有无过往病史、参保类型、居住区域及就医类型7个维度构建参保人员的数据仿真体系,见图1。
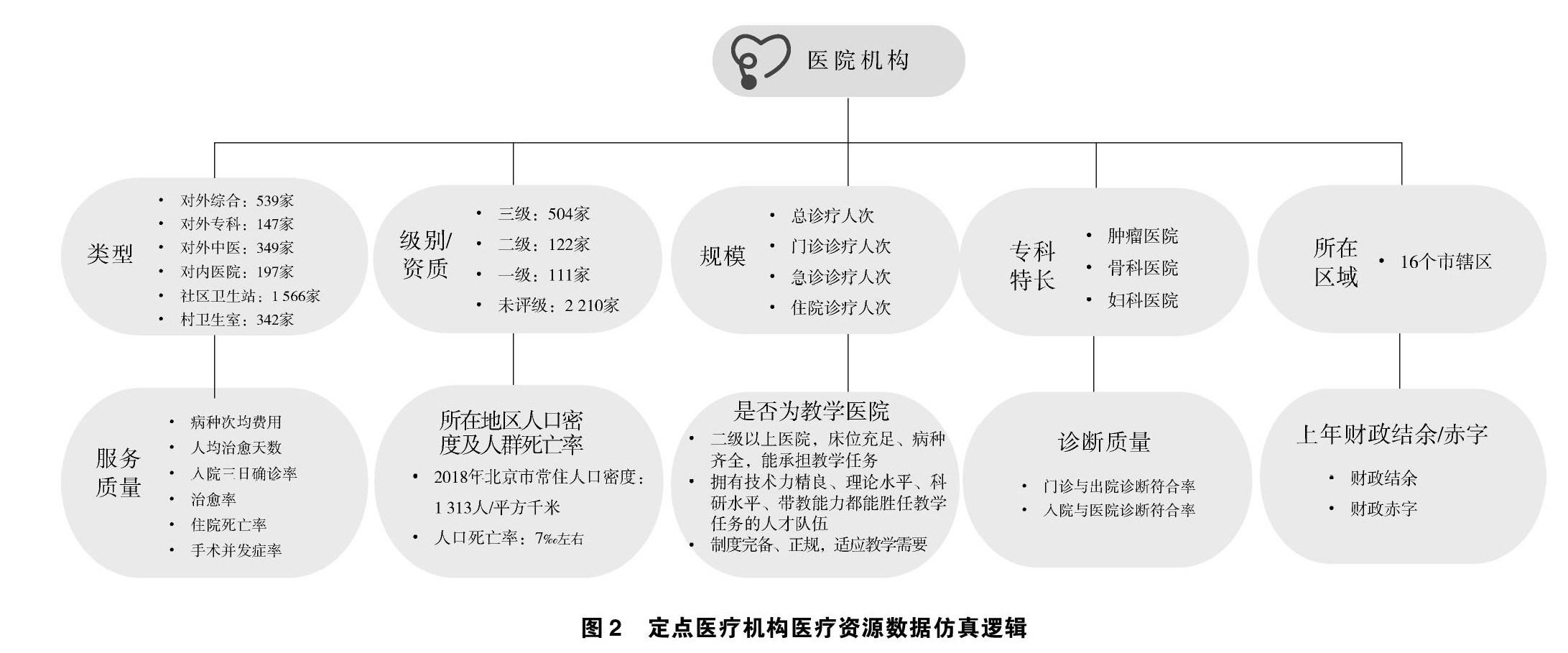
在定点医疗机构医疗资源数据仿真方面,根据各个定点医疗机构的医疗资源及就诊现状等情况,从医院类型、级别/资质、规模、专科特长、所在区域、服务质量、所在地区人口密度及人群死亡率、是否为教学医院、诊断质量、上年财政结余/赤字10个维度构建了医院机构的数据仿真体系,见图2。
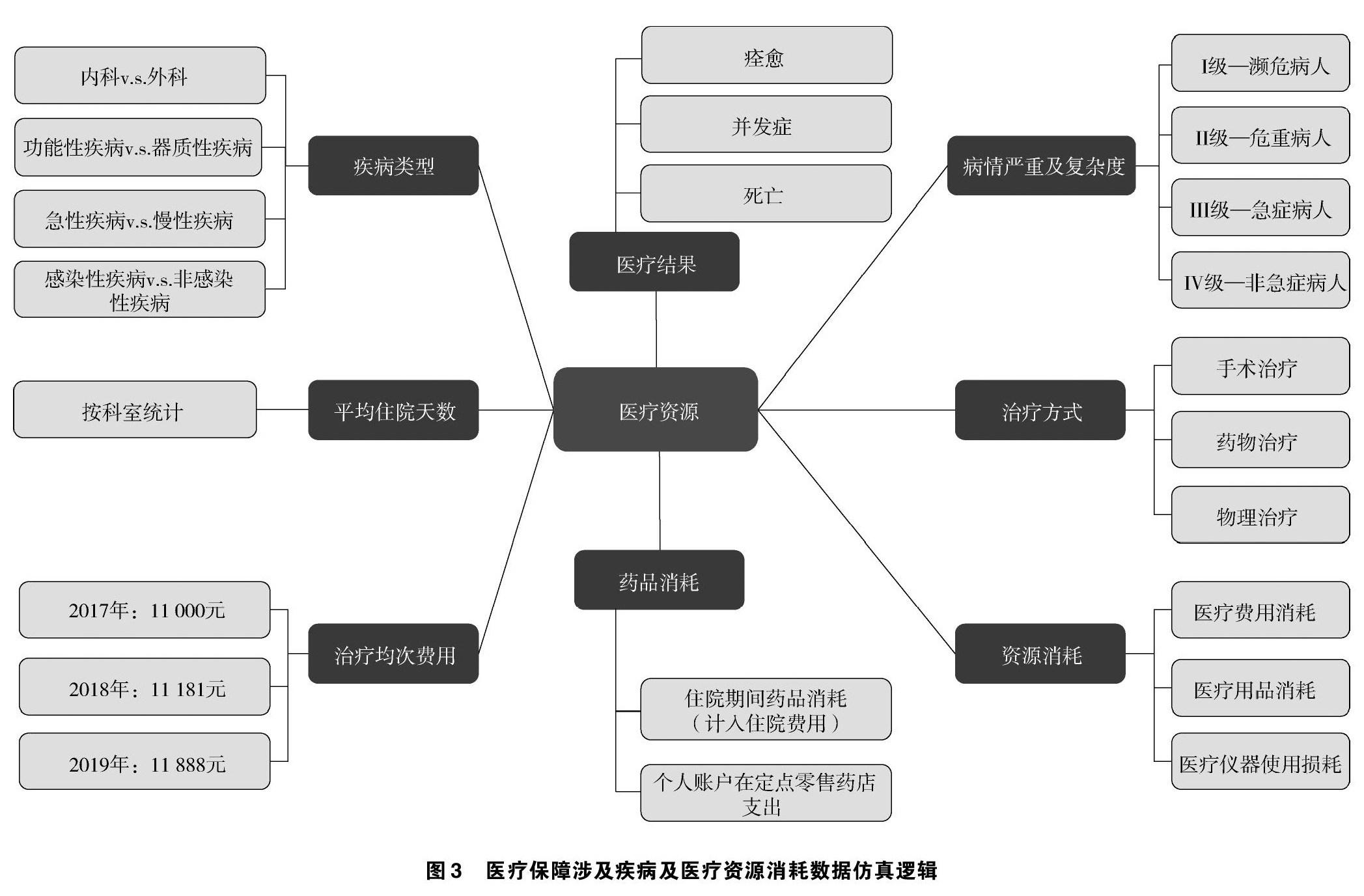
在医疗保障涉及疾病及医疗资源消耗数据仿真方面,综合医疗保障涉及的疾病,从疾病類型、平均住院天数、治疗均次费用、医疗结果、药品消耗、病情严重及复杂程度、治疗方式及资源消耗8个维度构建医疗资源数据仿真体系。其中,疾病类型细分为内外科、急慢性、是否感染及是否功能性疾病;平均住院天数按照科室进行统计;治疗均次费用根据历年真实统计数据进行合理推算;医疗结果分为痊愈、并发症及死亡3种;病情严重程度按照国家现有分类分为濒危、危重、急症和非急症4种;治疗方式分为手术治疗、药物治疗和物理疗法3种;药品消耗分为药店购买和住院消耗;资源消耗从医疗费用、医疗用品和医疗仪器3个维度进行统计。医疗保障涉及疾病及医疗资源消耗数据仿真逻辑见图3。
2.3 医保基金分配强化学习模型
强化学习(Reinforcement Learning)是一种通过与环境的一步步交互,调整相应的策略,从而追求最优回报的自我学习方法。其关注的问题是一个算法智能代理(Agent)在特定环境下如何通过与其交互来学习
在不同状态(State)下的行为(Action),使其获得最多的累计回报(Reward),其原理见图4。
强化学习在全球范围内已取得了令人瞩目的发展。DeepMind团队将深度强化学习应用到围棋游戏上并击
败世界顶级围棋选手;智能体AlphaStar在星际争霸Ⅱ的游戏天梯排名中达到了前1%;卡耐基梅隆大学团队研发德州扑克AI冷扑大师轻松击败顶级玩家;微软研发的Suphx麻将人工智能系统被认为已达到专业十段水平。此外,深度强化学习还在数学猜想的证明、电子相互作用的理解,以及控制核聚变等多个前沿领域屡立奇功,相关成果先后在《自然》和《科学》杂志发表。然而在国内,深度强化学习目前的应用领域还非常有限,腾讯公司的深度强化学习智能体王者荣耀“绝悟”于2019年在职业选手赛水平测试中获胜,此外深度强化学习也被应用于银行风险定价领域并初步展现出良好的应用潜力[4]。基于此背景,本文创新探索利用深度强化学习技术实现医保基金分配决策问题,以期进一步拓展强化学习的应用范围。
本文使用强化学习的优点是可以通过数字孪生技术模拟出不同医保基金分配情况下各家医院的经营环境,根据当前医院的运营状态,通过深度强化学习技术应用,智能地给出在“医院的经营效益”和“病人就诊的满足率”达到最佳时的基金分配策略。
在算法环境的定义上,对于医保基金强化学习问题,首先需要准确地定义环境、状态、动作及其奖励。环境以某区域3家医院为例,分别为专科医院、普通医院和综合医院,根据上文提到的仿真模拟逻辑,可以模拟出医院端的环境;状态为在模拟环境中,各医院医保资金的数量、各医院的就诊人数;动作为各家医院基金分配比例;奖励为根据基金分配情况以及医院的就诊情况,计算得到的“医院的经营效益”和“病人就诊的满足率”函数。此问题属于连续决策空间问题,可适应于深度确定性策略梯度(DDPG)算法,给出“医院的经营效益”和“病人就诊的满足率”达到最佳时的基金分配情况。
在深度强化学习算法的选择上,本文采用深度确定性策略梯度算法。在DDPG的原理中,最核心的部分是如何给出两个网络的损失函数,对于Actor网络而言,希望Critic网络对预测出来的动作评分越高越好,所以Actor网络的损失函数为
loss1=-Q(s,a|θQ)(1)
a=μ(s|θμ)
对于Critic网络的损失函数,给出如下定义
loss2={r+γQ′(s′,a′|θQ′)-Q(s,a|θQ)}2(2)
式(1)(2)中,Q(s,a|θQ)为在状态s下采取动作a所得的回报;r为未来收益。
式(2)可简单理解为在使用某动作下Critic网络的评价会逐渐接近在此动作下的回报和未来收益,其中在计算未来收益时需要用到Actor网络和Critic网络的定期“软更新”。
软更新的目标网络参数更新方式为
θQtarnew=ηθπ+(1-η)θQtarold
θμtarnew=ηθπ+(1-η)θμtarold
式中,η为更新参数比例系数,通常为0.01或0.1。
通过不断和环境进行交互,优化Actor网络和Critic网络的参数,最终能够获得一个可以适应环境变化的强化学习模型。此时根据医保基金分配问题的环境状态,可以给出“医院的经营效益”和“病人就诊的满足率”达到最佳时的基金分配智能化策略。
在算法的表现上,以强化学习结果为例,见图5。通过模拟3家医院(其中医院A为专科医院、医院B为普通医院、医院C为重点医院),不难看出,针对仿真模拟的标的医院在指定时间窗口内的表现,与真实情况相比,DDPG算法可以较为准确地给出最佳的医保分配比例智能化策略。
本文所使用的强化学习算法有以下明显优势:一是节省数据存储和计算资源,不同于以往的大数据智能建设,本文相关技术无须消耗大量存储资源来对海量明细数据进行存储,规避数据安全风险,并使得数据传输等操作处理有效节省计算资源;二是节约时间,按照传统方法至少需要2个月的时间才能得到较优解,而通过强化智能可以快速给出合理的结果;三是智能可迁移,数据和智能可以分离,医疗机构可按照自己对业务的理解来建立数字化仿真医保医疗医药数据体系,而后直接通过强化学习系统来获得基于各种仿真环境的最优智能化决策策略。
3 结语
本文运用构建在数字孪生仿真模拟基础上的深度强化学习技术,探索解决由社会医保存在道德风险和逆向选择所导致的医保基金运行风险问题,探索实现该领域社会资源分配达到社会效用最优的智能化解决方案。本文聚焦于医保宏观决策4S框架中“基本医疗保险基金的定额分配”应用场景,通过构建数字孪生仿真模拟环境,建立医保基金分配强化学习模型,探索合理分配医保基金的智能化道路,以期降低医疗保障宏观决策中的基金运行风险,为医保基金的合理运行进行有益尝试。
参考文献
[1]徐伟伟,胡振产.医保支付制度改革的“浙江范式”[J].卫生经济研究,2021,38(12):3-10.
[2]ARROW K J.Uncertainty and the welfare economics of medical care[M].New York :Academic Press, 1978.
[3]吴永飞,孙静,王彦博,等.基于数字孪生视角的商业银行风险定价决策探析[J]. 财务管理研究,2022(3):28-32.
[4]基于深度强化学习技术的商业银行风险定价决策支持系统研发及示范应用课题组,石言,王彦博,等.基于深度强化学习的银行风险定价策略探析[J].中国金融电脑,2020(10):33-37.
收稿日期:2021-10-14
作者简介:
吴永飞,男,1965年生,博士,高级工程师,主要研究方向:金融科技。
王彦博,男,1981年生,博士,博士后,主要研究方向:大数据、人工智能、区块链、量子金融科技。
解立伟,男,1982年生,本科,主要研究方向:面向产业数字孪生技术应用。
杨璇(通信作者),女,1990年生,硕士,注册金融分析师、金融风险管理师,主要研究方向:金融科技。
刘曦子,男,1986年生,博士,研究方向:区块链、大数据。
徐奇,男,1994年生,硕士,研究方向:数据挖掘与机器学习、量子金融科技。
宫雅菲,女,1995年生,硕士,研究方向:金融科技。
何姗,女,1990年生,本科,主要研究方向:金融信贷风险控制。
巨春武,男,1991年生,硕士,主要研究方向:数据治理、图像处理。
