层次聚类算法的改进研究
2022-04-29何雨轩
何雨轩
关键词:层次聚类;聚类;改进算法;连通度
1引言
聚类是一种常用的无监督机器学习方法,在模式识别、数据挖掘、计算机视觉、自然语言处理等方面都有广泛的应用。聚类算法的种类较多,原理也各不相同。例如,有基于密度、划分、层次、图论、网格、深度学习的聚类。每种聚类算法都有自己的特点和适用场景。层次聚类就是其中一种较为典型的算法,它常用于财务分析[1]、社区健康管理、医学研究、时间序列预测等。
与其他类型的聚类算法相比,层次聚类具有许多优点。首先,它具有检测“嵌套类簇”的能力。其次,它构建了一个树状的聚类层次树,可以显示连续步骤的聚类过程。由于类簇可以在二维图中可视化,因此,用户可以直观且容易地理解数据集的底层结构。再次,利用树状图也可以很容易地检测出异常值。最后,它不需要预先指定类簇的数量,这是一个非常重要的优势,因为确定簇的数量是聚类中最难的问题。
层次聚类的特点是聚类过程体现了聚类数量的渐变,一共有两种渐变方式:一是聚类数量从小到大,从最初所有的样本属于同一个类簇,逐渐分裂成两个、三个类簇,一直分裂到每个样本属于一个单独的类簇;二是聚合的方式,最初每个的样本都各自属于一个不同的类簇,然后将其中最相似的两个类簇合并成为一个类簇,接着逐步聚合,直到所有的类簇合并为一个类簇[2]。
层次聚类主流的聚类方式是聚合,当前代表性的算法包括AgglomerativeClustering,BIRCH,CURE,ROCK,Chameleon。这些经典的层次聚类算法不仅有自己的优点,也有明显的缺陷。例如,非球形的数据集聚类准确性较差,以及时间复杂度比较高。后来,有一些学者对经典层次聚类做了改进,如周维柏等[3]提出了一种改进的模糊层次聚类算法:张春英等[4]提出了一种面向不完备数据的集对粒层次聚类算法:王志飞等[5]提出了凝聚中心犹豫度恒定的模糊层次聚类算法。这些算法虽然部分解决了层次聚类的问题,但是效果并不是非常好。
本文提出了新的改进算法,在各个类簇合并的过程中,通过综合判断各个相邻类簇的相似性,并在不同的阶段使用不同的计算方法,从而提升聚类精度的聚类效率。
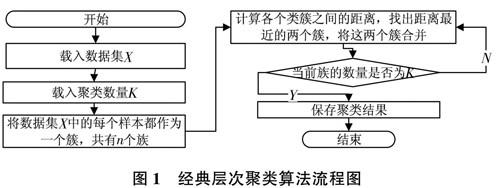
2经典层次聚类算法
目前,常用的层次聚类算法都是用聚合的方式进行聚类[6],如Python下常用的一些层次聚类算法:scipy.cluster.hierarchy.linkage,sklearn.cluster.AgglomerativeClustering。这些算法对包含N个数据的算法的流程如图1所示。
各个类簇之间距离的计算方式较多,其中包括单链接、全链接、平均链接。具体而言,假设有两个类簇Ci,Ci,它们之间的距离用不同方法计算,结果分别不同。
因为单链接方法只考虑两个类簇中最近的样本,不考虑其他样本,所以会导致相似性较差的样本聚合在一起。全链接方法只考虑两个类簇中最远的样本,导致它只适合球形数据的聚类。平均链接方法是这两种方法的折中。
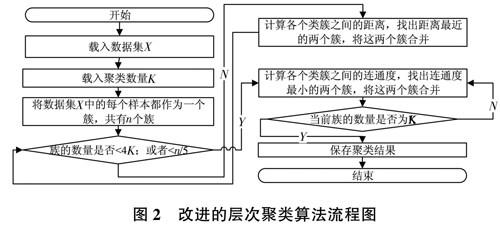
3改进层次聚类算法
为了弥补经典层次聚类的缺陷,本文提出了一种改进的算法。改进算法也是以聚合的方式进行聚类,在聚类的过程中,前期使用单链接的方法判断两个类簇是否可以合并。事实上,在聚类前期,类簇内包含的样本数量较少,使用单链接或者全链接方式基本没有差别。当聚类的数量小于样本的1/5或者达到目标类簇数量K的4倍时,聚类使用新的方法判断两个类簇是否可以合并。这个新的方法就是连通度。
连通度是两个类簇之间的距离和密度的综合衡量,其中距离计算用类簇之间样本的最小距离表示。至于密度计算,首先以计算出类簇之间最小距离的中心点作为圆心,然后用三倍最小距离作为半径来计算该圆形内部的样本数量。
4实验
为了验证改进算法的有效性,本文设计了相关实验进行验证。实验环境的配置如下:计算机的操作系统为Windowsl0:计算机的CPU为Intel Core i3-9IOOF3.6GHz;硬盘为2TB;内存为8GB。
改进的层次聚类算法采用Python3.6编程实现。实验中,用于对比的经典层次聚类算法使用sklearn. cluster. AgglomerativeClustering函数,并分别用单链接、全链接、平均链接的距离计算方法聚类。
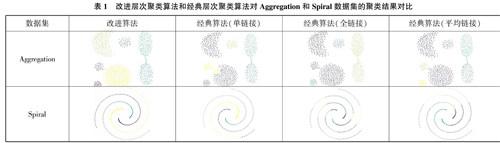
4.1模拟数据集的聚类实验
实验用的模拟数据集选用Aggregation和Spiral。本文提出的改进层次聚类算法和经典层次聚类算法的单链接、全链接、平均链接方法对Aggregation和Spiral的聚类结果如表1所列。由表1可知,本文提出的层次聚类改进算法效果最好。经典层次聚类算法使用的单链接方法和全链接方法对两个数据集的聚类结果都较差,使用平均链接方法对Aggregation聚类效果尚可,对Spiral的聚类效果较差。
本文提出的改进层次聚类算法和经典层次聚类算法对数据集Aggregation和Spiral的聚类结果F值如图3所示。通过对比两个数据集上各种算法的聚类F值可知,改进算法比经典算法的效率至少提高了18.5%。
4.2真实数据集的聚类实验
真实数据集采用了UCI(University ofCalifornialrvine)提供的公开数据。这些数据是通过在真实世界的测量、收集而获得,所以更具有参考意义。在UCI数据集中,本文选择了Abalone和Segmentation。
聚类结果评价指标见表2,其中包括调整兰德系数(ARI,Adjusted Rand index)、標准互信息素(NMI,Normalized Mutual Information)、F值、准确率(Accuracy)。
通过对比表2中的各个聚类指标可知,在单链接、全链接和平均链接方法方面,改进层次聚类算法明显优于经典层次聚类算法。这说明在真实数据集上,改进层次聚类算法的聚类效果更好。
5结束语
层次聚类是一种应用广泛的经典算法,但是其自身也有明显的缺陷,如对非球形数据聚类效果较差。本文提出了一种改进算法,通过在聚类的不同阶段使用不同的类簇合并策略来改进算法,在聚类的开始阶段,使用单链接的方法;在聚类的后期,使用连通度的方法。通过对模拟数据集Aggregation和Spiral的聚类实验,以及对真实数据集Abalone和Segmentation的聚类实验,验证了改进算法的有效性。
