车联网数据仓库技术研究
2022-04-29朱梅清梁国豪蒋祥斌张亮韦通明
朱梅清 梁国豪 蒋祥斌 张亮 韦通明

摘要:车联网数据是分析智能网联汽车用户行为的基础,针对现有车联网数据在海量数据存储查询慢及分析方面的不足,为提高车联网数据的可保存性、易用性,文章提出车联网数据仓库架构体系。通过车联网数据仓库,需求部门可以直接获取大量分析型数据标签,为用户行为分析快速提供数据支撑,不断精准创新智能化用户场景。
关键词:车联网;数据仓库;研究
中图法分类号:TP311文献标识码:A
Research on Internet of vehicles data warehouse technology
ZHU Meiqing,LIANGGuohao,JIANGXiangbin,ZHANGLiang,WEITongming
(SAIC GM WulingAutomoblieCo.,Ltd.,Guangxi Laboratory of New Energy Automobile,Guangxi Key Laboratory of Automobile Four New Features,Liuzhou,Guangxi 545007,China)
Abstract:Internet of vehicles data is the basis for analyzing the behavior of intelligent Internet connected vehicle users. In view of the shortcomings of existing Internet of vehicles data in massive data storage, query and analysis, in order to improve the preservation and ease of use of Internet of vehicles data, this paper puts forward the architecture system of Internet of vehicles data warehouse. Through the Internet of vehicles data warehouse,the demand department can directly obtain a large number of analytical data labels, quickly provide data support for user behavior analysis,and constantly accurately innovate intelligent user scenarios.
Key words: Internet of vehicles,datawarehouse,research
1研究背景
随着汽车网联化及智能程度的提升,车联网技术提升了车辆的智能驾驶水平,为用户提供智能、高效、安全的驾驶体验及交通服务,同时可以提高交通运行效率。车联网数据包含用户信息、应用数据、操控数据、工况数据等,这些数据蕴含巨大的商业价值,是挖掘用户画像、智能推荐、智能出行服务等功能的数据基础。车联网数据由车机或 APP 采集上传,直接存储在数据库(如 MySQL 和 Oracle 等)中,面对快速增长的数据,相关人员在对海量车联网数据进行大量查询和统计分析时显得力不从心。
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策[1]。借助数据仓库技术,将不同来源的车联网数据进行抽取、整合、指标加工,提供分析型数据标签,减少重复计算,为用户行为统计及车联网功能优化提供数据支撑。
2相关技术
2.1 DataX
常用的大数据离线同步工具有 Sqoop 和DataX等,由于 Sqoop 将停止更新、维护,车联网数据仓库采用阿里开源的离线同步工具DataX作为同步工具。DataX(图1)是一個异构数据源离线同步工具,采用插件式框架设计,将数据源读取和写入抽象为 Reader/Writer 插件,其星型数据链路,使得DataX作为数据源之间的中间传输载体,当需要接入新的数据源时,定义好该数据源的 Reader/Writer 插件即可做到跟已有的数据源进行数据同步。目前,DataX支持 MySQL,Oracle,Hive,HDFS 等常见数据库之间的数据同步,插件体系比较全面,使用广泛。
2.2 Hive
Hive 是基于 Hadoop 构建的数据仓库工具,提供抽取、转换、加载、数据集查询和分析等功能。Hive 可以将存储在 Hadoop 中的结构化的数据文件映射为一张数据库表,并提供类似 SQL 的 HiveQL 语言来实现查询功能,其通过 HiveQL 语句实现快速 MapReduce 统计,而不必开发专门的 MapReduce 程序,具有灵活性高、低数据约束格式、良好的容错性和可拓展性、学习成本低等优点,非常适合对数据仓库进行统计分析[2]。
2.3海豚调度
海豚调度是一款分布式易扩展的、支持可视化 DAG 界面的新一代工作流任务调度系统,致力于解决大数据任务之间错综复杂的依赖关系,并监控整个数据处理过程,使调度系统在数据处理流程中开箱即用。海豚调度能够实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及 Kill 任务等操作。海豚调度简单易用,使用场景丰富及高可靠性、高拓展性的特性使其十分流行。
3架构体系
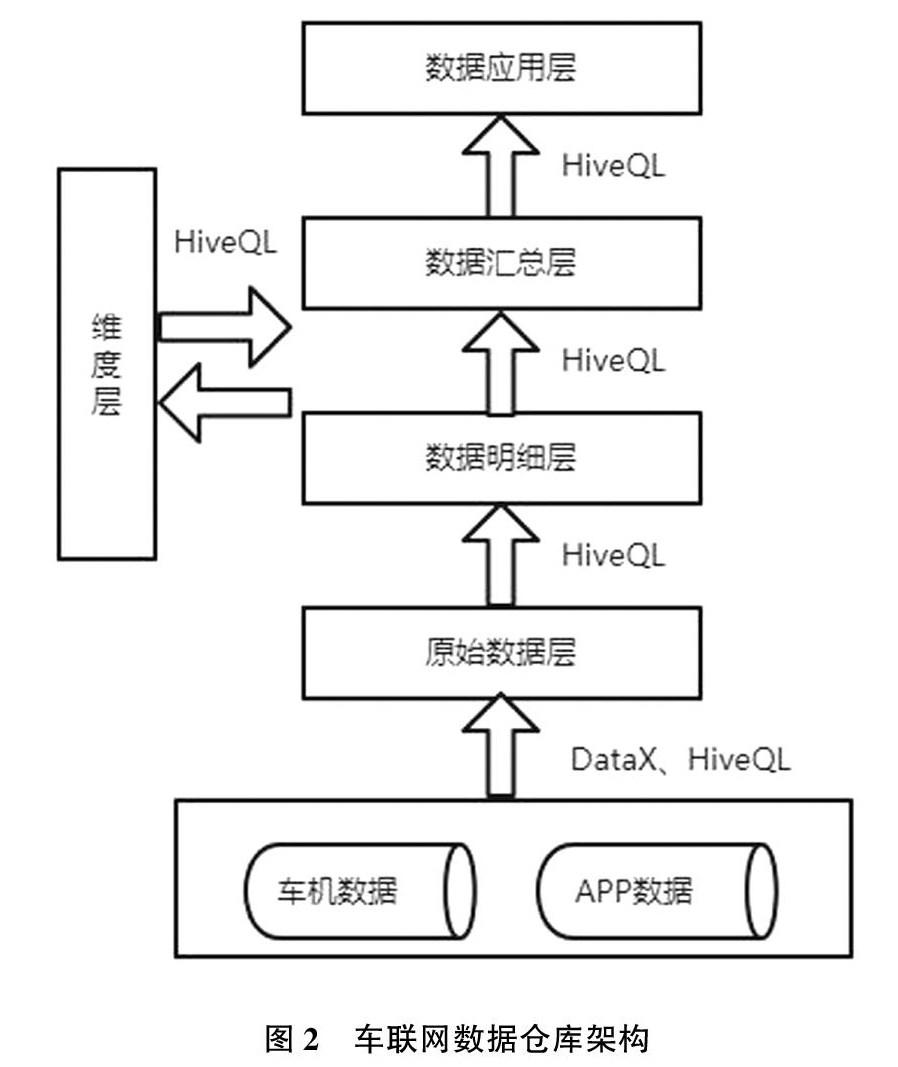
车联网数据仓库采用维度建模技术,由原始数据层、数据明细层、维度层、数据汇总层、数据应用层组成,如图2所示。
3.1原始数据层
原始数据层存放原始数据,是最接近数据源的一层,除了将非结构化数据解析成结构化数据,并不对业务数据进行过多的处理,尽可能保持数据处于原始状态。车联网数据来源于不同的车机、APP,有结构化数据和半结构化数据,存储在数据库 MySQL,HDFS等,需要使用同步工具将存储在不同数据库中的数据同步到原始数据层。通过DataX将数据源中的结构化数据同步到原始数据层;对于非结构化数据,通过 HiveQL 语句将json格式的半结构数据解析成结构化数据,并插入到原始数据层。
3.2原始明细层
数据明细层以业务过程作为建模驱动,构建最细粒度的事实表,对来自原始数据层的所需数据进行抽取、清洗、转换、整合,并通过 join 方式與维度表关联。不同数据源的车联网数据上传标准不一致,存在同意不同名的情况,需要保持统一数据标准,将不同数据源的数据整合到同一数据表中,保持数据的一致性,即同名同意、同意同名,避免因数据口径不一致造成不同业务对数据理解不一致的情况。
3.3维度层
维度层保存维度信息,主要针对业务事实的描述信息,维度属性是查询的约束条件及报表标签的基本来源。车联网数据仓库中的维度信息包括手机品牌、地区、日期、埋点等。
3.4数据汇总层
数据汇总层以数据明细层为基础,按照各个业务过程进行轻度汇总,成为用于分析的服务数据,用来进行快速、方便地查询,一般是宽表。车联网原始数据最细粒度为一次功能触发,而业务方经常使用场景为各车辆每小时使用车辆网功能次数、每天使用车辆网次数等形式的数据,因此每使用一次,就须计算一次。为了减少重复计算,增加一次计算结果的复用性,根据常用业务场景,将数据明细层的数据进行汇总,写入轻度汇总层。
3.5数据应用层
数据应用层面向业务需求定制开发,为各种统计报表提供数据。统计车联网功能标签、不同标签的使用次数、使用车辆数等常用标签数据。
4车联网数据仓库 ELT
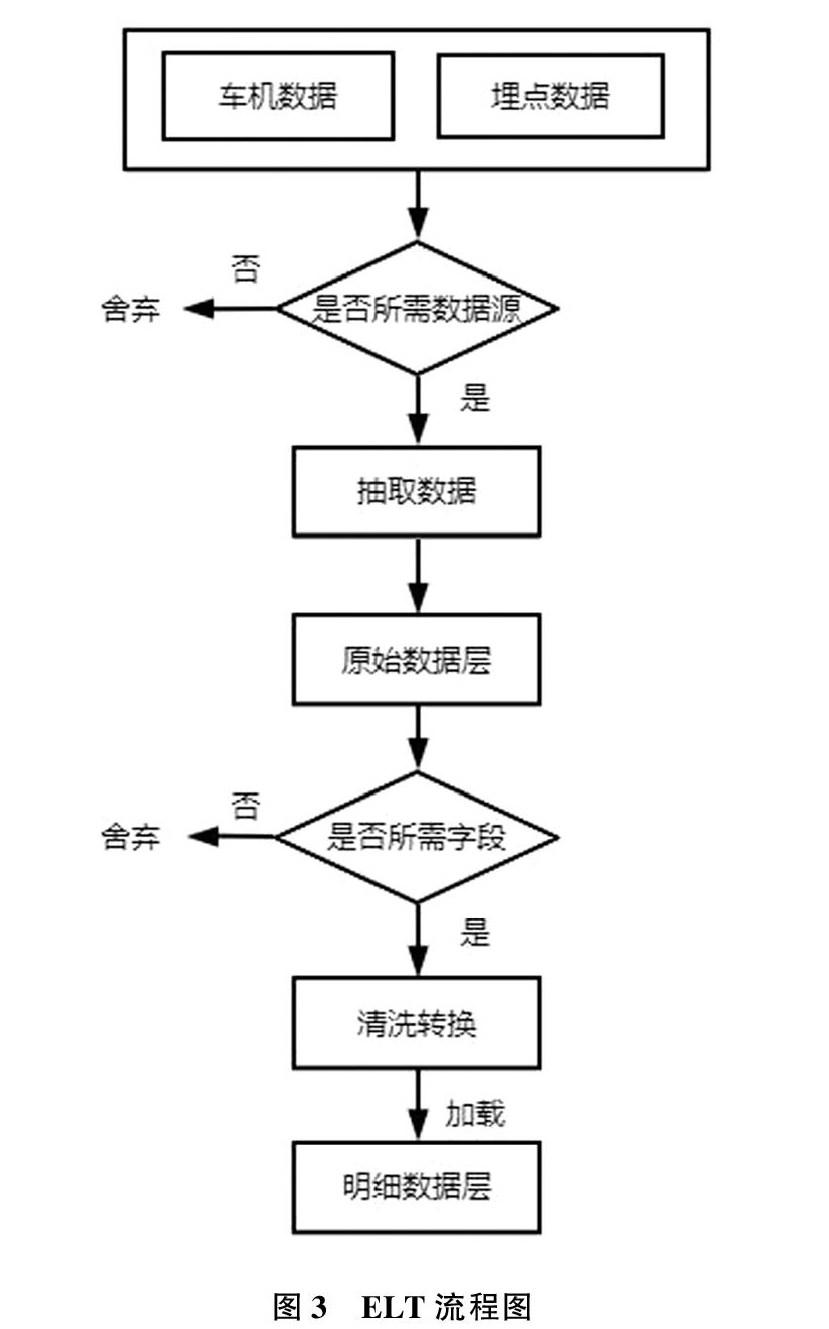
数据抽取、转换、加载是构建数据仓库的重要一环,传统的 ETL 工具是在数据抽取和加载过程中进行清洗转换,加载到数仓中的数据是清洗转换后的数据,当清洗转换的过程中出现问题时,将难以溯源。随着 Hadoop 技术的引入,及存储成本的降低,ELT 日渐普及,车联网数据仓库采用 ELT 方式,将所有原始数据都抽取到数据仓库的原始数据层,仅做多源数据的整合、汇聚,而不做清洗转换,保留原始数据。对 ELT 而言,Hive 是一个功能强大的工具,使用 Hive 作为传统 ELT 工具的替代,充分利用大数据的计算能力,将原始数据层的数据清洗转换后,加载到数据明细层,ELT 流程如图3所示。
4.1数据抽取
对于结构化数据,通过离线同步工具DataX将数据同步到原始数据层;对于存在 HDFS 中的非结构化数据,通过 HiveQL 语句将json格式的半结构数据解析成结构化数据,并插入到原始数据层。数据抽取一般有全量抽取和增量抽取两种方式;对于历史数据,使用全量抽取的方式;对于每日新增的数据,采取每日定时增量抽取的方式。
4.2数据清洗
数据清洗主要是对原始数据层的数据清洗转换,将空值、脏数据、超过极限范围的数据进行过滤、转换。例如,将字符串类型字段的空值,转换为unknown;超过合理范围的经纬度过滤等。
4.3数据加载
数据加载是将清洗转换后的数据加载到数据仓库的数据明细层。车联网数据仓库通过 Insert 的方式,将清洗转换后的数据加载到数据明细数据层。
5结论
通过构建车联网数据仓库,可弥补现有车联网数据在海量数据存储分散、查询慢及分析方面的不足,同时提供分析型数据标签,需求部门可直接、快速地获取数据,减少重复计算,为用户行为统计及车联网功能优化提供数据支撑。
参考文献:
[1]彭先清.数据仓库中联机分析系统的研究与实现[ D].成都:电子科技大学,2019.
[2] Thusoo A,Sarma J S,Jain N,et al.Hive?A petabyte scale data warehouse using Hadoop[ C]∥ IEEE 26th International Conference on Data Engineering,2010:996?1005.
作者简介:
朱梅清(1996—),本科,助理工程师,研究方向:数据开发。
