基于AKPCA 算法的井下WLAN 位置指纹定位
2022-04-29宋明智钱建生胡青松
宋明智,钱建生,胡青松
(1.徐州工程学院 信息工程学院,江苏 徐州 221018;2.中国矿业大学 信息与控制工程学院,江苏 徐州 221116)
0 引 言
近10 年,电子通信技术、计算机网络技术和移动互联技术的快速发展为井下人员定位系统的研究与 应 用 提 供 了 必 要 的 技 术 支 持[1-2]。 RFID[3]、UWB[4]、WSN[5-6]、WLAN[7]等都已在井下人员定位问题中有相应的研究与应用[8]。 其中,WLAN 技术与位置指纹定位算法相结合的应用方案以其成本低、非测距、精度可控等特点已逐渐得到广泛的应用。
由于煤矿井下巷道地理结构的特殊性,在实际的井下WLAN 位置指纹定位应用中,往往需要采用区域划分技术[9]来辅助提升定位的精度和效率。除此之外,在线定位阶段采用位置指纹特征提取技术能够进一步提升人员定位的精度。 比较常用的特征提取技术包括LDA(Linear Discrimination Analy⁃sis)[10-11]、 LLE ( Local Linear Embedding )[12]、LDE ( Local Discriminant Embedding )[13-14]、ISOMAP ( Isometric Feature Mapping )[15-16]和KPCA[17]等。 其中,KPCA 相比其他几种特征提取技术在WLAN 位置指纹定位应用中有更好的噪声抑制性能,因此有着更好的实用性。 KPCA 算法的关键环节是本征维数的计算与确定,本征维数选取的恰当与否直接决定了位置指纹定位系统的定位精度。 目前,对于本征维数的计算主要通过最大似然估计获得。 这一方式虽然计算效率高且无需准备大量经验数据,但由于该方法中的本征维数大小主要依赖于以数据中心点为半径的球形覆盖范围内近邻数据点固定个数L的取值,而L的取值又和井下定位巷道结构有一定的关系。 聚类划分后的位置指纹数据库被分为多个由不同巷道结构的参考点的位置指纹样本组成的子位置指纹图,如果此时设定相同的L,这些子位置指纹图可能会有不同的本征维数。因此,对位置指纹数据库整体求解本征维度的方法将不再适用,而分区域求解本征维数的最大似然估计又会导致运算复杂度的增加。
为解决上述问题,提出了基于最优AP 选择算法的、能够自适应动态调整本征维数的AKPCA 算法。 试验结果显示,AKPCA 算法在本征维数的计算上比KPCA 算法更具有针对性,且相比其他特征提取算法有着更好的定位精度。
1 WLAN 位置指纹定位原理
在特定的WLAN 环境中,空间内的某一个点或某一个小范围区域的物理位置可以与该点或区域处从多个AP(Access Point)信号接收到的一组RSS 序列唯一对应,这就是所谓的位置指纹[18-19]。
WLAN 位置指纹定位分为离线数据采集和在线定位2 个阶段,如图1 所示。

图1 WLAN 位置指纹定位原理Fig.1 Principle of WLAN location fingerprint positioning
离线阶段主要是位置指纹数据的采集工作。 在线定位阶段,用户通过随身携带的移动终端实时采集多个AP 信号的RSS,并将采集的RSS 序列与位置指纹数据库中已存储的所有RSS 序列进行比较,选取最相似的1 组RSS 序列所对应的参考点的物理位置作为用户的估计位置。 在线定位过程中,一般采用K 近邻算法(K-Nearest Neighbors,KNN)[20]或加权K 近邻算法(Weight K-Nearest Neighbors,WKNN)[21]进行位置指纹匹配。 这类算法虽然运算复杂度低,但定位误差较大。 为了保证井下人员定位的精度,考虑到位置指纹样本存储的数据结构特点,采用特征提取技术能够更好地完成在线位置指纹匹配的工作。 位置指纹的特征提取主要是将位置指纹样本序列从原始维度空间通过函数变换映射至新的维度空间中,以更高的计算复杂度为代价换取对噪声样本的进一步滤除。 采用特征提取技术的井下位置指纹定位系统的原理如图2 所示。

图2 采用特征提取技术的井下位置指纹定位系统Fig.2 Underground location fingerprints localization system using feature extraction technology
2 基于KPCA 算法的井下WLAN 位置指纹定位
KPCA 算法是PCA(Principal Component Analy⁃sis)算法与核函数法相结合的应用算法[22]。 PCA算法的主要原理是以从原始数据集中提取出的含有最大信息量的综合变量来表征原始的数据集。 提取出的综合变量就是所谓的原始数据集的主成分,这些综合变量彼此间互不相关,且最大程度的保留了原始数据信息。 但PCA 算法属于线性特征提取技术,对于位置指纹定位这类非线性问题的求解存在失真性。 KPCA 算法使用核方法将位置指纹样本集映射至高维空间,使得原本具有非线性特征的样本集具备了线性可分性,此时便可以使用PCA 算法对转换后的线性样本集进行特征提取,从而实现非线性样本集的降维处理并一定程度上提升位置指纹定位的精确性。 而无效信息或噪声干扰通常都存在于较小特征值对应的特征向量中。 因此,正确选择合理的核函数,使映射至高维空间的位置指纹样本集中有效数据能够更好的被提取保留,这可以进一步的提升位置指纹定位系统的定位精度。 使用KPCA算法的定位运算步骤如下:
步骤1:设定已构建的位置指纹数据库中的RSS 样本序列为原始数据集,用矩阵形式表示为Φ=[f1,…,fi,…,fN]T,其中fi为参考点i处采集到的来自R个AP 信号源的RSS 向量,N为参考点总数,矩阵Φ的维度为N×R。
步骤2:非线性映射定义。ζ:SRPR→H,其中SRPR为参考点所属的欧式空间,H为高维的希尔伯特泛函空间,利用核函数可以计算H中的内积。
步骤3:对原始数据集进行中心化处理,生成新的中心化数据集,其中更新后的fi为



中心数据集的协方差矩阵ΦC为通过上述的操作步骤,中心化处理后的位置指纹原始数据集中的任意数据元f∗在高维特征空间中i方向分量上的投影表示为:


其中,Φ∗为归一化处理后的位置指纹样本矩阵,矩阵维度为N×R。
在线定位阶段,利用式(13)将实时采集的RSS序列均值化处理后与特征变换矩阵相乘,求得D维实时特征向量。 之后,可以使用WKNN 算法将实时特征向量与位置指纹特征矩阵进行比较,最终获得估计位置坐标。
目前,KPCA 算法中本征维数D的确定主要通过最大似然估计法获得,具体的计算公式为:

其中,L为设定的近邻点数量;TK(fi) 为以数据元fi为球心的超球体能够覆盖L个近邻点时超球体的最小半径;DL为特征位置指纹数据库的本征维度。 为进一步提升定位精度,通过对近邻点的差值选择获取最优本征维数:

其中,D为多个结果统一分析后的最优本征维数。 虽然最大似然估计法在一定程度上解决了需要依靠经验数据求解本征维数的问题。 但是最大似然估计法一般是针对整个位置指纹数据库进行的本征维数计算,如果需要结合区域划分定位方法的话,还需要对划分后的位置指纹子数据库分别进行KPCA和最大似然估计过程,这会影响位置指纹定位系统的运行效率。 而井下定位区域结构导致了区域划分技术的采用是必然的,那么为了在保证定位精度的前提下,尽可能简化实时定位过程中的运算环节,第3 节将根据定位区域聚类划分的思想,利用最优AP选择算法,提出具有本征维数自适应性取值的AKPCA 定位算法。
3 基于AKPCA 算法的井下WLAN 位置指纹定位
3.1 最优AP 选择算法
在实际井下定位环境中,定位区域一般较大,将有多个AP 设备被合理部署在区域的各个位置处,那么每个参考点处只能接收到小部分AP 信号的RSS 数据,RSS 序列中的大部分数据将由数据库默认值(-80 dBm)填补从而属于无效数据。 如果RSS序列使用未经处理的全数据向量进行运算,则会导致大量的资源浪费以及定位效率的下降[23-25]。 因此,可以考虑采用最优AP 选择算法解决上述问题。

设定参考点i处位置指纹样本序列fi中第k个AP 信号的权重为FRAPk,表示位置指纹样本采集过程中,第k个AP 信号出现的频率,计算公式为:

其中,TAPki为在参考点i处的Ti次采集总数中第k个AP 信号被采集的总次数。

通过位置指纹样本的离线采集过程,每个参考点都有一个最优AP 选择因子序列FACi,结合井下定位区域聚类划分方法[9]在实时定位过程中使用FACi对实时采集的RSS 序列中的无效数据进行滤除。 假设用户实时采集的RSS 序列为fW={fAP1,…,fAPk,…,fAPR} ,经过定位区域判别后fW所属聚类e内的参考点编号为{1,…,i,…,Ne} ,这些参考点对应的最优AP 选择因子为FACi={FACAP1i,…,FACAPki,…,FACAPRi} 。fW中无效AP 信号数据的滤除条件为:

其中,ηAP为AP 信号有效因子。 式(20)表示如果AP 信号k在聚类e内的每个参考点处的最优AP 选择因子都小于ηAP,则fW中可以滤除fAPk使其不参与位置指纹匹配运算。 最优AP 选择因子FACi就是对KPCA 算法本征维数自适应性取值改进上的重要参数。
3.2 AKPCA 算法
基于最优AP 选择算法的本征维数求解过程相对简单。 根据3.1 节所述内容,经过聚类划分后的区域e对应的子位置指纹库的本征维数De通过下述公式求得:

其中,i={1,…,Ne} ;k={1,…,R} ;FAC∗i为滤除无效AP 信号分量后的最优AP 选择因子序列,需要通过迭代计算获得;count(·) 为向量中含有数据分量个数的统计函数。
式(21)所表达的主要思想是,根据对位置指纹数据库的聚类划分,对每一个聚类中能够接收到的有效AP 信号的最大个数进行统计,统计的结果就是聚类区域子位置指纹库的最优本征维数。 最优AP 选择算法的引入,使KPCA 算法的运用更加灵活,在位置指纹数据库聚类划分的过程中即可完成各划分区域对应本征维数的计算。
AKPCA 算法主要是针对本征维数取值的改进,其他计算过程与第2 节中所阐述的KPCA 算法的运算步骤相同。 理论上,AKPCA 算法不仅在执行效率上要优于KPCA 算法,且本证维数确定的合理性也要优于使用最大似然估计法的计算结果,从而保证了特征提取过程中无效位置指纹样本信息的最优滤除,也保证了位置指纹定位的精度。
4 试验及结果分析
图3 给出了巷道同一位置处连续采样同一AP信号1 000 次的RSS 值分布情况。 从图3 中可以看出,由于受到电磁噪声的影响,同一位置处接收到同一井下AP 信号的RSS 值并不是一成不变的,并且某些情况下会有较大的波动。 如果使用传统的RSS测距进行井下人员定位,其同一位置处的测距结果具有不确定性,大概率会使最终的位置估计产生较大的误差。 这是本文选择位置指纹定位方法的重要原因,而提出的AKPCA 算法也能够进一步减小RSS样本随机动态分布对定位精度的影响。 下面将分别进行最优本征维数验证试验和特征提取算法定位试验。

图3 井下AP 信号连续采样分布Fig.3 Continuous sampling distribution of underground AP signal
4.1 最优本征维数验证试验
从式(19)和式(21)中可以分析得出,ηAP是影响本征维数计算的主要参数,而某一个AP 信号在属于同一区域内所有参考点处的采样样本中的出现频率及其样本标准差是影响该AP 信号选择因子的主要原因。 过小的出现频率或者过高的样本标准差,都说明AP 信号在某一个区域的覆盖性很差,而如果FACAiPk的值为0,则说明AP 信号在某一个区域内没有信号覆盖。 因此,合理设定ηAP的值是保证本征维数能够取得最优值的前提。
为分析ηAP的取值对本征维数取值及定位精度的影响,将在如图4 所示的定位巷道环境中在ηAP取不同值的情况下使用AKPCA 算法分别进行多组定位试验。 由于参考点选取密度与定位精度直接相关,试验中参考点选取间隔为1 m,并在巷道转角处增加辅助参考点。 试验巷道平面图、参考点选取位置及定位区域大小如图5 所示。 位置指纹数据库主要由离线阶段研究人员在每个参考点处采集的1 000 组RSS 序列构成,每组RSS 序列包含了该参考点处接收到的10 个AP 信号的RSS 值。 其中,未接收到的AP 信号,其RSS 值以默认值-80 dBm填充。

图4 井下WLAN 定位试验巷道Fig.4 Experiments tunnel of underground WLAN localization
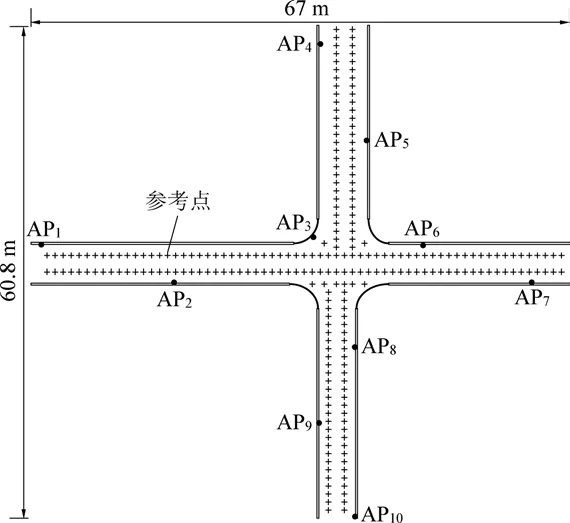
图5 井下WLAN 定位试验巷道平面图Fig.5 Tunnel plane of underground WLAN localization experiment
试验过程中使用了FCM(Fuzzy C-Means)聚类划分算法[9]和子区域定位方法,聚类划分后的定位区域如图6 所示。 针对每个ηAP的取值,研究人员都在定位区域中随机进行了500 次动态定位。试验结果如图7 所示,见表1。ηAP越大,某些区域中会有更多的AP 信号因被标记为无效覆盖信号而被滤除,使得本征维数取值较小,导致了某些有效数据信息可能被滤除,致使定位精度下降。 当ηAP取值为0.06、0.04 和0.02 时,定位精度有所提升且3 组定位结果非常相近,但ηAP=0.06 时5 个子区域的本征维数总数最小,所消耗的系统资源是3 组中最低的。 因此,ηAP的合理取值能够在保证系统定位精度的前提下,尽可能降低系统资源的开销。
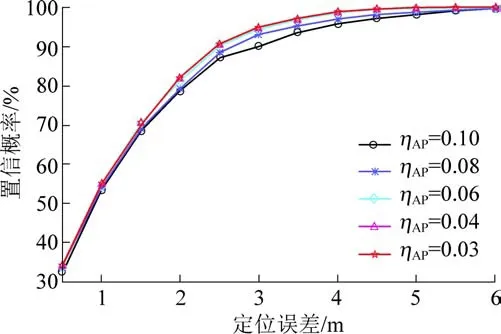
图7 不同ηAP 取值时定位结果比较Fig.7 Comparison of localization results with different ηAP
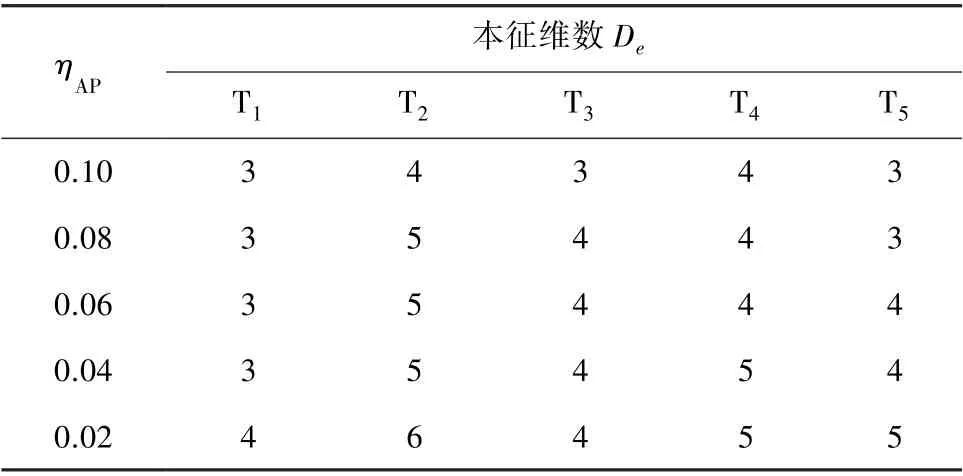
表1 ηAP 的取值对本征维数取值的影响Table 1 Intrinsic influenced by ηAP
为比较KPCA 算法和AKPCA 算法在本征维数取值处理上的不同对定位性能的影响,在如图5 所示的定位巷道环境中分别使用KPCA 算法和AKPCA 算法进行人员定位试验。 其中KPCA 算法使用最大似然估计法求解本征维数,AKPCA 算法使用如图6 所示的聚类划分结果对子区域分别求解本征维数。 2 组试验中,使用KPCA 算法定位时研究人员在定位区域中随机行走并随机进行500 次动态定位,而使用AKPCA 算法定位时研究人员在已聚类划分后的5 个子区域中分别进行500 次随机动态定位。
KPCA 算法和AKPCA 算法计算出的最优本征维数见表2,从对比结果中可以看出AKPCA 算法与区域划分技术相结合后能更好地针对具体的子区域计算出相应的最优本征维数。 2 种算法的定位结果对比如图8 所示,从对比结果中可以看出AKPCA算法的定位精度要略微优于KPCA 算法,定位误差为4 m 时的置信概率近似达到100%。 定位精度的提升主要是因为区域划分后各子区域本证维数的正确选择。 例如T2区域的本征维数为5,而KPCA 算法计算出的本征维数对于所有定位区域都为4,因此当使用KPCA 算法对处于区域T2的用户进行实时定位时有可能会有部分定位信息丢失,从而导致定位精度下降。

表2 KPCA 算法和AKPCA 算法最优本征维数对比Table 2 Comparison of optimal eigendimension between KPCA and AKPCA

图8 KPCA 算法和AKPCA 算法定位结果对比Fig.8 Localization results comparison between KPCA and AKPCA
4.2 特征提取算法定位试验
试验在如图4 和图5 所示的定位巷道环境中进行,分别使用WKNN 算法、LDA 算法、LDE 算法、ISOMAP 算法、PCA 算法、KPCA 算法和AKPCA 算法进行井下真实环境人员动态定位,每一种定位算法都使用了区域划分及子区域粗定位。 研究人员使用每种定位算法在定位区域中各自进行500 次随机动态定位,且研究人员需尽量保证定位区域的所有可能位置处都有进行动态定位,以保证最终的定位结果不失一般性。
对比结果如图9 所示,试验过程由于是随机进行的,所以属于有噪声试验。 从定位结果中可以看出,特征提取算法中ISOMAP 算法、LDA 算法、PCA算法、KPCA 算法和AKPCA 算法有着较为相近的定位精度,但AKPCA 算法不仅有着略微优异的定位精度,更在定位系统资源的消耗方面较其他几种特征提取算法有着更大的优势。 井下人员定位系统使用的服务器的内存大小为4 GB,图10 给出了各定位算法在井下人员定位系统实时定位过程中系统资源消耗上的性能对比,AKPCA 算法的平均内存使用为0.832 GB,要优于KPCA 算法(1.278 GB)和其他位置指纹匹配算法。 在实际的巷道环境中,设备的运转、井下工作人员的流动、巷道温度湿度的变化等因素都会影响会给定位匹配过程带来一定的噪声干扰。 AKPCA 算法在位置指纹数据库聚类划分的过程中对每个子区域进行合理的位置指纹特征提取,滤除无效数据和干扰噪声,在节省系统资源消耗的同时一定程度上提升了井下WLAN 位置指纹定位的精度。

图9 AKPCA 算法与不同特征提取算法的定位性能对比Fig.9 Localization performance comparison between AKPCA and different feature extraction algorithms
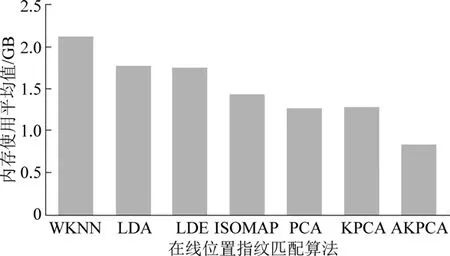
图10 WKNN 算法与不同特征提取算法系统内存使用平均值的对比Fig.10 Comparison of memory usage average between WKNN algorithm and different feature extraction algorithms
5 结 论
1)目前,常用的实时定位方法是利用特征提取技术对位置指纹数据库进行特征提取,构建的位置指纹特征数据库直接用于实时RSS 特征序列的比对。
2)井下定位巷道区域相对较大,基于WLAN 位置指纹的井下人员定位往往需要采用聚类划分技术进行区域划分,而传统的KPCA 算法对于划分后的定位区域的本征维数的求解较为繁琐且单一,并不能较好的适配子区域定位。
3)提出了AKPCA 算法利用最优AP 选择算法计算出与定位子区域相对应的最优AP 选择因子,并以该因子为可变自适应参数,针对性地求解子区域对应位置指纹特征数据库的本征维数。 试验结果显示,AKPCA 算法在本征维数的计算上比KPCA 算法更具有针对性,且相比其他特征提取算法有着更好的定位精度。
