利用改进Elman神经网络的光伏I-V特性建模方法
2022-04-28罗林禄陈志聪吴丽君林培杰程树英
罗林禄,陈志聪,吴丽君,林培杰,程树英
(福州大学物理与信息工程学院,微纳器件与太阳能电池研究所,福建 福州 350108)
0 引言
对于稳定可靠的光伏系统设计来说,高效、快速、准确的I-V特性建模必不可少. 光伏I-V特性建模可用于许多目的,例如I-V曲线物理参数的实时辨识[1-2],最大功率点跟踪(maximum power point tracking,MPPT)的研究[3],光伏阵列的功率预测研究[4],光伏组件的故障诊断、故障定位研究[5]. 因此,建立准确有效的光伏I-V输出特性曲线预测模型对光伏发电系统的设计与研究具有重大的意义.
目前,国内外学者对I-V曲线建模的研究主要可分为两类: 基于等效电路和参数方程的白盒预测模型、基于数据驱动和机器学习的黑盒预测模型. 在白盒模型方面,利用等效双二极管方程作为I-V曲线的拟合方程,使用光伏组件制造商提供的关键点信息和一些电气参数,包括标准测试条件下的短路电流点、开路电压点、最大功率点以及温度系数,然后通过差分进化算法提取标准测试条件下的公共参数,再根据物理参数与环境条件的转换方程,计算出实际条件下的参数,从而代入双二极管方程计算得出电流,实现I-V曲线的预测[6]. 白盒模型的另一种方法是根据等效单二极管方程,使用解析法提取方程中的物理参数,进而预测I-V曲线[7]. 这些白盒建模方法的前提都是基于已知的等效电路和经验公式,并且依赖于导致准确性受到损害的参数假设,预测精度较低. 相比之下,基于机器学习和大量实测数据集的黑盒模型,能够学习到任意实测条件下的I-V曲线信息,并且具有强大的非线性拟合能力,极大地提高了建模的稳定性和准确性.
在黑盒模型方面,一些机器学习算法和深度神经网络被用于I-V曲线建模,例如利用多层感知机算法[8]、广义回归神经网络(general regression neural network,GRNN)和级联正向神经网络算法[9]进行建模,模型的输入为辐照度、温度、电压,输出为电流,通过对大量I-V曲线数据进行训练,从而获得预测模型. 此外,也有使用一维残差网络模型[10],输入设定为辐照度、光伏组件背表面温度、电压,输出为整条I-V曲线,通过训练实测数据集,实现整条曲线的预测. 这些主流黑盒模型的环境因素输入仅仅局限于辐照度和环境温度或是辐照度和背板温度,并未对其他环境因素进行实验分析. 同时,这些黑盒模型的初始值是通过随机初始化得到,这使模型的预测结果不稳定. 对于深度残差网络模型而言,整条I-V曲线的预测是难以实现的,因为不同工况下的开路电压并不能提前获得,这就导致了模型的输入电压不完整,从而使I-V曲线的预测不完整. 为解决现有黑盒模型存在的缺陷,本研究提出一种改进的Elman神经网络模型,使用量子粒子群(quantum particle swarm optimization,QPSO)算法对Elman网络的初始值进行优化,解决模型不稳定和精度较低的问题; 同时对输入特征进行选择分析,使用更多特征进行建模,从而建立一个更加稳定、准确的光伏I-V特性曲线黑盒预测模型.
1 影响光伏I-V特性曲线预测的因素
在理想情况下,影响输出特性的环境因素主要是光伏组件接收的辐照度、光伏组件的温度. 但在实际工作过程中,影响光伏阵列输出特性的因素还包括了环境温度、湿度、风速、风向、降水量、散射辐照度等[11],这些环境因素的影响程度各不相同. 为了进一步提高预测模型的精确度,研究其他环境因素对预测结果的影响就尤为重要. 本研究采用皮尔森系数来分析输出特性与各个环境因素的相关程度,从而最终选取模型的输入特征. 皮尔森公式如下:

(1)


表1 环境因素的相关系数
通过计算环境因素的皮尔森相关系数,并根据系数的绝对值大小进行相关程度分析,最终选择的环境因素为: 光伏阵列平面辐照度、光伏组件背表面温度、环境温度、湿度. 同时,模型的输入还需要电压,这与光伏I-V曲线方程有关,I-V曲线表达式如下:

(2)
其中:I表示电流;V表示电压;Iph表示光电流;Is表示二极管反向饱和电流;q表示电子电荷;k表示玻尔兹曼常数;n表示理想因子;T表示温度;Rs、Rp分别表示串联电阻和并联电阻.因此,本研究最终选择这五个因素作为模型输入进行建模预测.
2 基于QPSO-Elman的光伏I-V特性曲线预测模型
2.1 Elman神经网络

图1 Elman神经网络结构Fig.1 Elman neural network structure
Elman神经网络是一种反馈型神经网络,与前馈式网络相比多了一层承接层. 隐藏层的输出作为承接层的输入,承接层的输出反馈至输入层,使得网络对历史数据具有记忆的功能,提高了网络的稳定性和计算能力[12]. Elman神经网络的结构如图1所示. 以图1为例,Elman网络的数学模型表达式为:

(3)
式中:y(k)是输出向量;x(k)是隐藏层输出向量;xc(k)是承接层输出向量;u(k)是输入向量;ω1是承接层到隐藏层的连接权值;ω2是输入层到隐藏层的连接权值;ω3是隐藏层到输出层的连接权值;g(·)是输出层传递函数;f(·)是隐藏层传递函数[13].
Elman网络采用的权值修正函数为误差平方和函数,表达式为:

(4)

2.2 QPSO算法优化Elman神经网络算法设计
粒子群优化算法(particle swarm optimization,PSO)是一种启发式搜索算法,具有计算简单、易实现的优点,自1995年提出以来,引起了许多国内外学者的关注和研究[14]. 标准PSO算法的寻优过程为: 在n维搜索空间中有m个粒子,每个粒子表示一个潜在的最优解,粒子在搜索空间的飞行过程为该粒子的搜索过程. 粒子具有速度和位置两种属性,速度代表粒子移动的快慢,位置代表移动的方向. 粒子的速度和位置更新公式如下式所示,通过不断迭代,获得满足终止条件的最优个体极值,即搜索空间的一个最优解.

(5)

PSO算法需要设置的参数较多,位置变化缺少随机性,存在收敛速度慢,易陷入局部最优的缺点,为了克服这些缺点,许多改进的PSO相继被提出,量子粒子群(QPSO)算法是其中一种改进算法[14]. QPSO算法引入了粒子历史最好位置平均值mbest的概念,其计算公式为;

(6)
式中:m表示粒子种群大小;pbest_i表示当前迭代的第i个粒子的历史最优位置矢量.
粒子位置更新公式改进为:
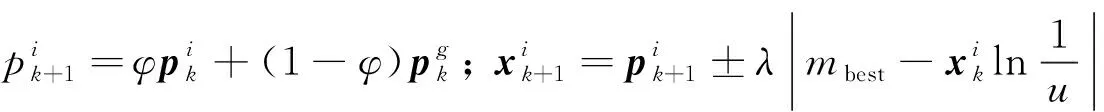
(7)
式中:φ、u为区间(0, 1)上的均匀分布数值;λ为创新参数; 一般λ不大于1. 相比标准的PSO算法,QPSO算法的控制参数更少,只需要控制λ这个参数. 此外,PSO算法是速度-位移模型,QPSO算法简化为仅有位移的模型,加快算法的迭代速度. 并且量子系统的粒子可以分布在任何位置,从而真正实现在约束范围内全局搜索,提高了全局搜索能力,避免陷入局部最优的问题.
由于传统的Elman神经网络采用梯度下降的方法进行权值更新,并且权值和阈值随机初始化,这导致了训练过程容易陷入局部最优,使每次训练结果存在不稳定性的问题,网络的预测结果存在较大误差. 为了解决单一Elman网络预测精度不足、预测结果不稳定以及收敛速度慢的问题,选择用QPSO算法优化Elman网络的初始权值和阈值. QPSO-Elman的设计流程图如图2所示.

图2 QPSO-Elman预测模型流程图Fig.2 Flowchart of QPSO-Elman forecasting model
设计主要分为两个部分: Elman网络模型部分和QPSO算法优化部分. 利用QPSO的全局搜索能力,以Elman网络的误差平方和函数作为QPSO算法的适应度目标函数; QPSO算法在权值和阈值的取值范围内迭代寻找全局最优值,并将迭代计算结果作为Elman网络的初始值,取代单一Elman网络随机选择初始值的方法,从而达到提高网络预测精度、稳定性和训练速度的目的.
QPSO-Elman神经网络算法设计步骤为:
1) 根据拟解决问题的输入和输出,确定Elman神经网络的拓扑结构,确定网络输入层、隐藏层、承接层以及输出层的节点个数,从而确定QPSO算法的维数.
2) 对输入数据进行下采样、网格采样以及归一化处理.
3) 根据网络结构,对QPSO算法的种群粒子进行初始化编码. 网络的每一个权值和阈值表示粒子的每一个维度. 设定种群规模、粒子维数和取值范围,设置QPSO算法的迭代次数和误差容限,初始化各个粒子的数值.
4) 计算个体极值和种群极值,以式(4)作为适应度的判断标准,计算适应度值,根据式(6)、式(7)更新粒子的位置.
5) 判断QPSO算法是否达到最大迭代次数或适应度目标函数是否达到误差容限,是,则QPSO算法优化结束; 否,则返回步骤4)继续执行.
6) 将QPSO算法迭代计算的最优粒子结果映射为Elman网络的初始权值和阈值,设置Elman网络训练的最大次数、训练函数以及误差容限进行训练.
7) 以网络输出的结果建立QPSO-Elman预测模型,算法结束.
3 实验仿真与分析
3.1 I-V曲线数据集预处理

图3 NREL光伏组件及其测量装置Fig.3 NREL photovoltaic module and its measuring device
为了验证所提出的I-V建模方法的可行性和推广性,使用美国国家可再生能源实验室(National Renewable Energy Laboratory, NREL)提供的太阳能电池板测量数据集[15]. 该数据集不仅包含由单晶硅(x-Si)、多晶硅(m-Si)、碲化镉(CdTe)、硒化铜铟(CIGS)、非晶硅(a-Si)、本征薄层异质结(HIT)等六种材料制成的太阳能电池板的I-V输出特性,还包含相应的环境数据,例如阵列平面(POA)辐照度、光伏组件后表面温度、环境温度、相对湿度、散射辐照度等. 数据集的标识分别为xSi11246、mSi0251、CdTe75669、CIGS1-001、HIT05662和aSi03038. 选择安装在科罗拉多州Golden地区的I-V测量数据,其光伏组件及测量装置如图3所示.
3.1.1I-V曲线数据集重采样及网格采样
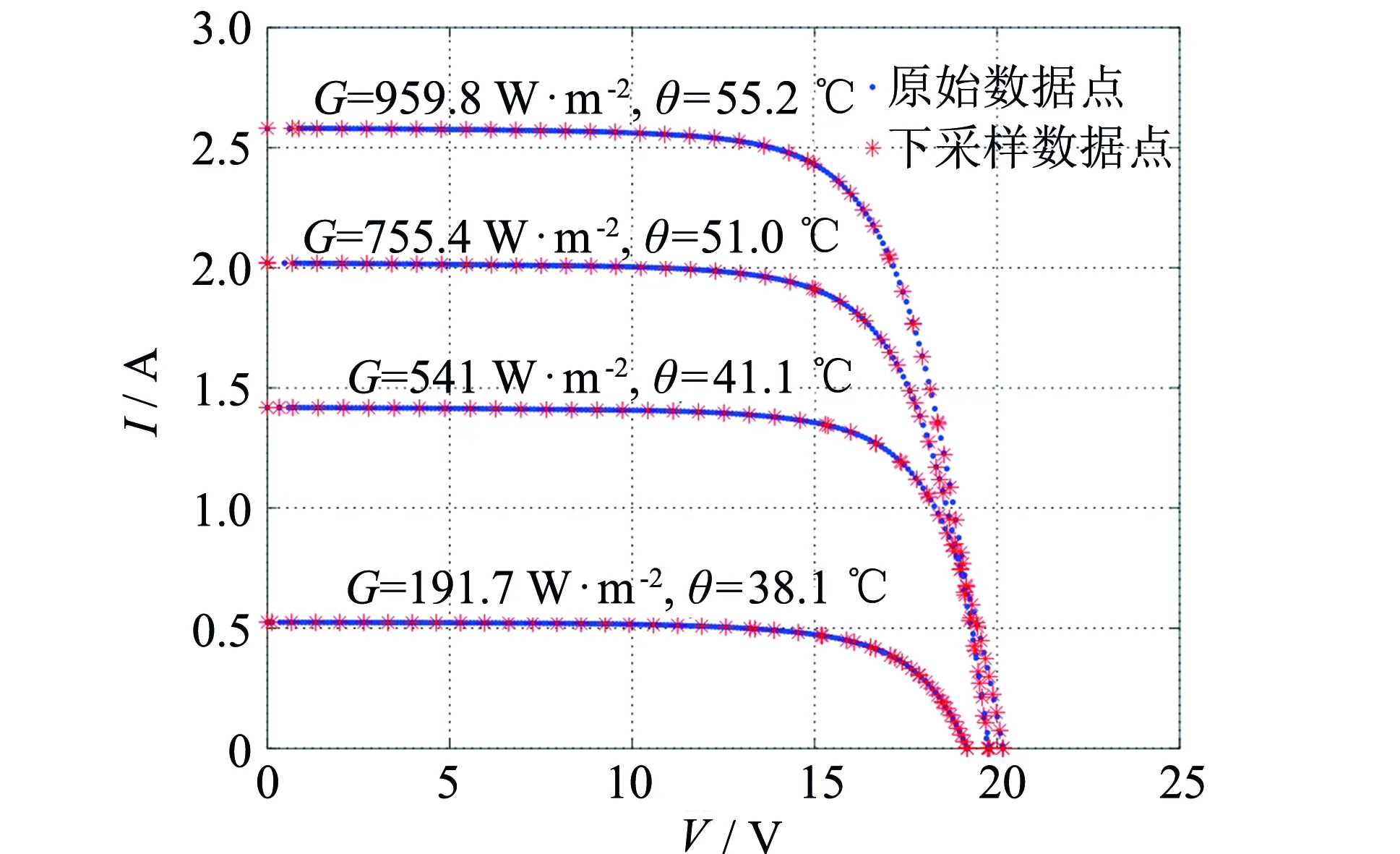
图4 下采样数据点与原始数据点对比结果 Fig.4 Comparison results of down sampling data pointsand original data points
在原始数据集中,每条实测I-V曲线包含接近195个数据点. 为了减少数据冗余并且平衡I-V曲线数据点的分布,提出一种基于电压电流的双线性插值方法来重采样原始I-V曲线. 该方法将曲线上的195个点进行重采样,采样点个数设置为50. 具体过程如下: 首先对I-V曲线0 V至开路电压Voc之间等间隔重采样30个电压点,用电压矢量[V1,V2, …,Vi, …,V30]表示. 然后,在原始I-V曲线中找到最接近Vi的电压点及该点对应的实测电流,分别表示为(V′i-1,I′i-1)和(V′i+1,I′i+1).最后通过线性差值法,即利用算式(8)计算采样电压Vi相对应的电流值Ii. 使用这种插值重采样方法,能够在0 V到开路电压Voc之间均匀采样30组电压电流数据点. 同理,对I-V曲线0 A至短路电流Isc之间等间隔重采样20个电流点,通过式(8)计算重采样电流点Id相对应的电压值Vd,获得20组均匀的电压电流数据点.通过插值,累计获得50个数据点对.最后,通过按电压升序对采样得到的数据点进行排序,形成新的重采样I-V曲线.图4绘制了部分重采样的I-V曲线与原始曲线对比结果,从中可以看出重采样曲线的数据更为合理,既能减少数据冗余又能最大程度地保留关键点信息.

(8)
在实测数据集中,数据样本的分布非常不均匀. 当某些区间的样本分布明显过多或过少时,会导致模型的过拟合或欠拟合. 为了解决本数据集分布不均的问题,本研究中通过网格采样对现有数据进行下采样. 网格采样的具体步骤如下:
1) 确定数据集的辐照度、温度范围,采样间隔根据分辨率要求进行划分. 在本研究中,辐照度网格数目设置为60,温度网格数目设置为30.
2)I-V曲线先根据辐照度进行排序和划分,然后根据温度对每个辐照度网格中的曲线进行排序和划分. 最后,在每个网格中随机选择一定数量的I-V曲线,在本研究中将其设置为2条.
3) 将网格采样后的数据进行随机划分,70%的数据作为模型的训练集,30%作为测试集,最终的采样结果如表2所示.

表2 数据集预处理结果
3.1.2数据归一化处理
模型的输入特征包含辐照度、背板温度、环境温度、相对湿度和电压,这几个特征之间存在较大的数值差异,为了提高模型的精度和收敛速度,需要对输入特征进行归一化处理. 本研究选择Min-Max归一化,把模型输入数据映射到(0, 1)之间. 归一化公式为:

(9)
其中:X、Xmin、Xmax分别表示模型输入数据、模型输入数据的最小值、最大值.
3.2 预测结果评价标准
利用QPSO算法优化Elman神经网络的初始权重和阈值,通过迭代训练后得到I-V曲线预测模型. 选用支持向量机算法模型(support vector machine, SVM)、已发表文献中提出的多层感知机算法模型(multilayer perceptron, MLP)以及未改进的Elman神经网络与本模型进行对比. 采用均方根误差(root mean square error, RMSE)、平均绝对误差(mean absolute error, MAE)、确定系数(R2)作为预测模型的评价标准. 三者的计算表达式分别为:

(10)

3.3 QPSO-Elman模型结构与参数确定
采用Matlab仿真平台进行实验验证,选择NREL数据集中的mSi0251、aSi03038这两种光伏组件进行建模预测.
1) 确定Elman神经网络的网络结构. 网络的输入为阵列平面辐照度、光伏组件背表面温度、环境温度、相对湿度、电压,即输入层节点数为5; 输出为电流,即输出层节点数为1; 隐藏层节点数通过凑试法得出. 当节点数为16时,预测误差最小,所以Elman网络的结构设置为5-16-16-1.
2) 根据网络结构,确定QPSO算法的维数. 维数=输入层节点数 × 隐藏层节点数 + 隐藏层节点数 × 承接层节点数 + 隐藏层节点数 × 输出层节点数 + 隐藏层节点数 + 输出层节点数,计算得出维数D=369.
3) 设置Elman网络的训练函数为“trainscg()函数”,训练最大次数为1 000,误差容限为10-5. 设置QPSO算法的种群规模大小为20,迭代次数为100.
3.4 实验结果与分析
本研究中,mSi0251数据集经过预处理后,训练集包含45 450个点,测试集包含19 500个点; aSi03038数据集的训练集包含47 100个点,测试集包含20 200个点. 为了公平合理地对比,选用的MLP网络结构与Elman网络相同,隐藏层节点数都设置为16个,训练函数也设置为相同的trainscg()函数. 在同等配置条件下,每种模型分别独立编译10次,取10次结果的平均值进行仿真验证,各个模型的预测结果如表3所示, 两种数据集的拟合对比图分别如图5、图6所示. 为了直观地看出拟合效果,将各模型的预测结果与真实值相减并取绝对值,做出绝对误差对比图,如图7、图8所示.

表3 不同模型预测结果对比

图5 mSi0251数据集拟合对比 Fig.5 Fitting comparison of mSi0251 dataset

图6 aSi03038数据集拟合对比 Fig.6 Fitting comparison of aSi03038 dataset
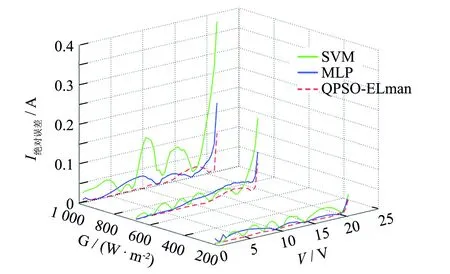
图7 mSi0251数据集绝对误差对比 Fig.7 Absolute error comparison of msi0251 dataset

图8 aSi03038数据集绝对误差对比 Fig.8 Absolute error comparison of aSi03038 dataset
由表3可见,在选取的两种数据集上,本研究提出的QPSO-Elman模型在训练集和测试集上的性能指标几乎接近,表明训练的模型没有过拟合,具有较好的泛化性能. 同时,QPSO-Elman模型的性能均优于其他模型. 从aSi03038数据集中测试集预测情况来看,所提出的QPSO-Elman模型的RMSE为0.008 30,未改进的Elman模型的RMSE为0.009 29, MLP模型的RMSE为0.010 02,QPSO-Elman模型的预测误差相比这两种模型分别减小了约10.66%和17.16%; 从另一组数据集的预测情况来看,所提出的模型在测试集上的RMSE为0.012 09,未改进的模型为0.015 98,相比之下,改进后精度提升了24.34%. 而在MAE指标上,改进后的绝对误差为0.005 08,改进前的误差为0.006 18,MLP的误差为0.006 93,误差分别缩小了17.80%和26.70%. 同时,从确定系数指标来看,QPSO-Elman模型优于其他模型,表明拟合效果更好. 图5显示了其中三种模型的预测拟合情况,可以看出,所提出的模型能更好地拟合真实曲线,两者几乎重合. 从图7、图8中可以看出,所提出的模型在电压较小范围上的预测电流误差远低于其他模型,并且误差波动小,总体平均误差也小于其他模型. 仿真结果表明,在I-V特性曲线建模上,所提出的方法具有更高的精度和泛化性能.
4 结语
针对目前主流的两种光伏I-V特性曲线建模方法存在的问题,为准确地预测光伏I-V曲线,本研究建立了基于改进Elman神经网络的光伏I-V曲线黑盒预测模型. 通过对NREL提供的I-V曲线数据集进行下采样和网格采样预处理,分析环境因素对预测模型的影响,并通过QPSO算法优化Elman神经网络建立QPSO-Elman模型. 实验结果表明,所提出的模型在测试集上的RMSE低至0.83%~1.20%,MAE低至0.50%,R2达到99.9%. 同时,与目前已发表文献中提出的GRNN模型、MLP模型、SVM模型、未改进的Elman模型进行对比,性能指标均优于这些主流模型,平均误差分别降低了67.93%、57.72%、28.65%、17.50%. 此外,所提出模型的I-V曲线拟合效果更好,具有更高的精确度、更好的稳定性、更强的泛化能力. 仿真实验验证了所提出模型的创新性、正确性、可行性以及较好的应用价值和通用性.
