三维帧间配准预测的V-PCC改进算法
2022-04-28王适郑明魁陈建王泽峰邱鑫
王适,郑明魁,陈建,王泽峰,邱鑫
(福州大学物理与信息工程学院,福建 福州 350108)
0 引言
传统图像是像素的集合,每个像素由三个彩色分量或者一个灰度值表示. 与图像类似,3D点云是空间中一系列点的集合,每个点由坐标位置和属性信息(例如颜色、反射率、法向量等)构成. 由于点云可以准确重建一个真实的物体或者场景,目前已经广泛应用于虚拟现实[1]、增强现实[2]以及自动驾驶[3]等领域. 根据不同的应用场合,可以分为单个物体或场景形成的点云,进一步可以分为静态点云和动态点云. 本研究主要针对运动的物体形成的点云(dynamic point cloud,DPC),对于典型的由8i[4]采集的DPC数据,每一帧点云通常包含近百万个点,每个点由30个比特表示几何信息(x,y,z)以及24个比特表示颜色信息(r,g,b),因此一帧点云大小约为6 Mbyte,对于30帧s-1的点云序列,则码率大小为180 Mbytes-1,所以有效的压缩方法对于点云的存储和传输是极其重要的.
为了有效压缩DPC, 目前的方法主要是利用帧与帧之间的相关性去除冗余信息,主要分为两大类方法: 3D的帧间预测方法和3D点云投影成2D视频的帧间预测方法. 对于3D的帧间预测方法, Kammerl等[5]首先提出编码相邻帧八叉树差异,相比直接编码,更有效地压缩了DPC. Thanou等[6]对一帧点云用八叉树分块,对每一块使用频谱图小波变换将3D运动估计转换为特征匹配问题. Mekuria等[7]采用和2D视频编码类似的思想,把一帧点云均匀划分为N·N·N的宏块,根据每一块与对应块的颜色方差和点数的差异大小决定是否使用迭代最近点(ICP)估计其运动信息. Queiroz等[8]把一帧点云均匀分割成N·N·N的用0和1表示的体素,对一块体素计算其与对应体素的相关性大小从而选择帧内编码或者帧间编码. Xu等[9]用k-means把点云聚类成M块,采用ICP估计几何信息的运动矢量,对属性信息则用图的傅里叶变换模型估计其运动矢量. 然而时变的点云帧与帧之间存在点数差异、没有明确对应以及部分点云不存在对应,因此这些方法的帧间预测不够准确,未充分利用时间相关性,点云的压缩效率没有得到显著提高.
由于2D视频编码具有灵活和成熟的算法,一些工作尝试将DPC从3D投影到2D以压缩DPC. 例如,Lasserre等[10]提出使用基于八叉树的方法将DPC投影到2D空间,而Budagavi等[11]则提出一种直接对3D中的点进行排序以组织2D视频的方法,然后使用HEVC压缩2D视频. 但是,这些投影方法会导致投影生成的2D视频发生形状变化,无法充分利用帧间预测技术. 为了解决这个问题,Schwarz和He等[12-13]建议使用圆柱或立方体将DPC投影到2D视频,提高了视频压缩效率,但是由于遮挡而损失了一些点. 为了在投影点数和使用2D视频编码之间取得更好的平衡,Mammou等[14]提出使用基于patch的投影方法,将DPC分解为2D的patch, 形成视频并使用视频编码的方法对其压缩.
基于patch的投影方法(V-PCC)成为MEPG-I制定的对于DPC压缩的标准[15]. V-PCC首先通过计算每个点的法向量把三维点云投影到包围盒的6个平面,形成几何图像和纹理图像,进一步对在同一个平面且在三维几何坐标是相邻的点进行聚类形成几何patch和纹理patch,把patch按照一定顺序插入到网格形成了有空隙的纹理图像和几何图像,为了平滑图像便于后续视频编码压缩,对空隙进行填充,为了区分填充像素和点云投影形成的像素,又引入了0和1的占用图,对纹理图像和几何图像形成的序列采用视频编码压缩,占用图和其它辅助信息则直接熵编码. 但基于patch的投影破坏了3D对象固有的连续性,导致帧间预测编码效率显著下降[16].
对此,Li等[16]通过在编码端重建三维点云,根据三维点云帧与帧之间的对应关系修正2D视频编码的运动矢量,但是对于几何patch,由于点云发生了旋转和平移,因此形成的深度图像具有较大差异,导致无法进行有效的2D帧间运动估计. Kim等[17]提出结合三维和二维的帧间编码,把DPC序列划分为I帧和P帧,I帧采用V-PCC编码,通过I帧进行3D帧间运动估计从而恢复P帧,该方法可能使得P帧的残差过大,不能保证高效的帧间预测. 本研究提出一种优先采用三维配准帧间预测和结合V-PCC帧间预测的改进方法. 三维配准帧间预测: 当前块在已编码的参考帧中寻找最佳匹配的块,进一步优化当前块和最佳匹配块的误差. 因此三维配准帧间预测仅需要编码更小的残差,所以本研究优先采用三维配准帧间预测. 为保证点云配准时点云运动具有一致性和准确的对应性,首先提出一种运动一致性的二叉树粗分割和八叉树细分割的方法; 为度量三维配准帧间预测的可靠性,计算三维配准帧间预测的误差,对于不能有效进行三维配准帧间预测的点云使用高效的V-PCC帧间预测,有效结合三维配准帧间预测和V-PCC的视频编码的帧间预测,形成一种基于分割的混合帧间的预测方法. 所提出的方法主要包括以下贡献:
1) 提出一种用于三维配准帧间预测的分割方法. 保证了分割后块点云相对运动的一致性和对应性.
2) 提出一种三维配准帧间预测结合视频编码帧间的预测方法. 该方法优先采用可靠的三维配准帧间预测,剩下点云融合并使用V-PCC的帧间预测方法.
1 三维帧间配准预测的算法改进
三维配准帧间预测是通过最小化参考帧和当前帧的误差,从而求解对应的旋转矩阵和平移向量生成预测帧. 所以三维配准帧间预测仅需编码更小的残差,提出了优先三维配准帧间预测的V-PCC改进方法. 然而时变的点云同一帧不同位置发生不同运动以及帧与帧之间存在点数差异,而配准的前提是同一帧点云发生相同的旋转和平移,且当前帧和参考帧具有准确的对应. 因此,首先要分割出具有相同运动的点云且保证分割后的对应性. 对此,本研究提出了基于运动一致性的二叉树粗分割和进一步八叉树细分割的方法. 进一步对分割后的每一块点云优先采用三维配准帧间预测,为了保证三维配准帧间预测的可靠性,对分割后的每一块点云进行三维配准帧间预测并计算误差,当误差小于一定的阈值,则该块点云只需编码块索引和运动信息,对剩下点云融合并使用V-PCC的帧间预测.

图1 编码框图Fig.1 Architecture of the encoder
如图1所示,本编码框架由七个模块组成.
1) 模块1. 对输入的当前点云序列采用了一种基于运动一致性的二叉树粗分割方法,分割出具有一致性运动和对应性的点云块.
2) 模块2. 对分割后的点云块进行三维配准帧间预测并根据可靠性分类,计算配准帧间预测后的误差大小把点云分成4个类别,分别为不需要编码的一类点云, 可以通过三维配准帧间预测的二类、三类点云,以及不能被三维配准帧间预测的四类点云. 此时分析四类点云不能配准的原因如下: ① 点云帧与帧之间差异过大,导致对应关系较差; ② 点云分割后的块过大,块内的相对运动仍然并非一致. 所以提出了进一步细分割的方法,基于此时点云有较好的关系,所以采用了相比二叉树更高效的八叉树分割方法,形成了模块3.
3) 模块3. 重复三维配准预测和可靠性的分类,并更新最后的分类结果,当点云分割后的点云数目小于一定的阈值则停止分割,得到最后的四类点云.
4) 模块4(熵编码). 根据模块2的可靠性判断,一类点云只需要编码块索引,二、三类点云需要编码块索引和旋转矩阵以及平移向量.
5) 模块5. 对四类点云融合并使用V-PCC的帧间预测.

图2 解码框图Fig.2 Architecture of the decoder
6) 模块6. 参考帧是已编码的前一帧在编码端的重构,所以分割的点云再次融合形成了模块6. 点云重构并融合.
7) 模块7. 参考帧点云.
解码的框图如图 2所示,其与编码对应. 首先根据分割信息分割已解码的前一帧点云,进一步根据一类点云的索引找到相应的块,从而恢复一类点云; 由二、三类的索引找到相应的块以及运动信息R和T恢复二、三类点云; 对于四类点云则直接通过V-PCC解码; 最后融合一、二、三、四类点云,恢复出最终的解码点云.
1.1 基于运动一致性的二叉树分割方法
目前对于点云三维配准帧间预测的分块方法主要有两种: 1) 基于k-means的方法把点云聚类成M块; 2) 参考视频编码的思路把点云均匀分成N·N·N的立方体. 这两种方法不能保证分割后的点云运动的一致性和块的对应性. 对此,受点云质量评估的启发,通过计算当前帧相对前一帧的最近点误差衡量点云帧间的相对运动,由于具有相同运动的局部点云其几何位置接近,发生相同旋转和平移之后的数值也接近,因此误差的数值接近. 所以具有一致性运动的相邻点云,其误差分布相似. 为度量误差分布的离散程度,引入统计学中的离散系数作为衡量指标. 因此误差的离散系数大小对应了点云是否具有一致性运动.
为使点云分割后参考帧和当前帧的块之间一一对应,引入了二叉树的思想. 例如,当一帧点云沿着维度x均匀分割成两块时,通过比较两块点云中x的相对大小,得到了对应关系.同时考虑点云运动的一致性和对应性,沿着不同的维度分割,对应不同大小的误差的离散系数.离散系数越小,说明此时分割后的点云运动更具有一致性.因此, 构建分割后的两块点云的离散系数之和作为选择不同分割维度的代价函数S(d),其中d=x,y,z,S(d)最小时对应的分割维度即为所求的分割维度.
对于当前帧点云矩阵Pcur,Pcur沿着维度d(d=x,y,z)均匀分割后的代价函数为S(d),定义为

(1)

对分割后的点云进行多次分割,分割M次之后,得到了2M块点云, 如图 3所示,当M=5时,即把点云分割为32块,8i的数据中RedAndBlack数据集随机选取的分割结果展示. 图3(a)为参考帧分割结果,图3(b)为当前帧对应的分割结果,可以看到分割后参考帧与当前帧有较好的对应.

图3 RedAndBlack序列相邻帧的分割结果Fig.3 Segmentation results of adjacent frames or test sequence RedAndBlack
1.2 基于配准的三维帧间运动估计方法
本三维配准算法采用迭代最近点算法(ICP),对每一个点云块用ICP估计其旋转矩阵R和平移向量T, ICP通过最下化当前帧和参考帧的误差E(R,T)求解相应的R和T.
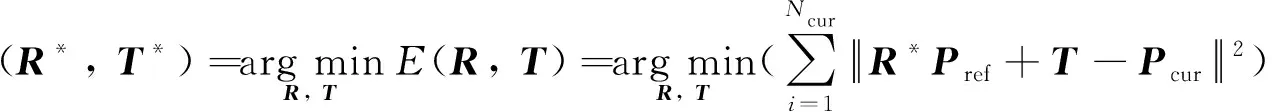
(2)
式中:E(R,T)为均方误差;Pref为参考帧点云矩阵;Pcur为当前帧点云矩阵;Ncur为当前帧点云Pcur的点数;R*和T*即为参考帧和当前帧误差最小时对应的旋转矩阵和平移向量.
为进一步说明优先采用三维配准帧间预测的优势,计算三维配准帧间预测的误差与非配准帧间预测时的误差并比较. 首先,非配准的帧间预测定义为: 当前块在已编码的参考帧中根据误差大小寻找最佳匹配的块.

(3)
此时,式(3)右边是非配准帧间预测的误差对应了旋转矩阵为单位矩阵I、平移向量为0时的误差函数E(R,T)的函数值; 左边表示了三维配准帧间预测时的误差,三维配准帧间预测的误差对应为误差函数E(R,T)的最小值.由于一个函数的最小值是小于等于其它变量对应的函数值,所以三维配准帧间预测改善了参考帧和预测帧的误差.因此,优先对V-PCC采用三维配准帧间预测.
为保证三维配准帧间预测的可靠性. 首先,需要设定三维配准帧间预测误差的阈值mseth,记mseref和msepre分别表示参考点云和预测点云相对于当前点云的均方误差. 进一步判断参考点云配准前后的均方误差和误差阈值的相对大小,对于近似静止的点云块有两种结果: ① 点云是静止的,配准之后没有改进; ② 点云是近似静止的,配准之后改善了参考点云与当前点云的误差. 对于运动的点云也有两种结果: ① 配准之后形成的预测点云与当前点云的均方误差小于等于阈值; ② 配准之后形成的预测点云与当前点云的均方误差大于阈值; 因此,分块之后的点云被分成了如下4个类别.
1) 一类. 当mseref≤mseth, mseref≤msepre,说明该块点云是静止的,参考点云和预测点云之间差异较小,配准之后误差没有改善.
2) 二类. 当mseref≤mseth, mseref≥msepre,说明该块点云近似是静止的,参考点云和预测点云之间差异较小,配准之后的预测点云和当前点云的误差进一步减小.
3) 三类. 当mseref≥mseth, mseth≥msepre,说明该块点云是运动的,参考点云和预测点云之间差异较大,但是通过配准之后形成的预测点云与当前点云的均方误差是小于阈值的.
4) 四类. 当mseref≥mseth, mseth≤msepre,说明该块点云是运动的,参考点云和预测点云之间差异较大,通过配准之后的预测点云与当前点云仍存在较大的差异.
因此,针对一类点云只需要编码块的索引. 对于二类和三类点云需要编码块的索引、旋转矩阵R和平移向量T. 对于四类点云,配准之后均方误差过大的原因是整块点云的运动不一致,即此时的四类点云包含有其他3个类别的点云. 于是对四类点云提出了进一步细分割的方法。基于此时经过粗分割后的点云有较好的对应关系,因此采用了相比二叉树更高效的八叉树分割方法,当有一块点云的数目小于阈值则停止分割. 对进一步分割完成后的点云进行配准,计算误差分类,并更新分类结果. 最后对所有四类点云融合并使用V-PCC进行编码.
2 实验仿真与分析
为评估算法的性能,将本方法与最新的Test Model Category 2 version 12.0 of MPEG PCC[18]、经典算法[7]以及V-PCC改进的帧间编码方法[16-17]比较了BD-rate. 对于RD曲线,由于缺乏其它文献的数据则只和V-PCC对比. 测试数据为V-PCC CTC[19]中定义的5个DPC. 分别从几何失真和属性失真两个方面评估点云质量. 几何失真用点对点的均方距离D1和点对平面的均方距离D2的峰值信噪比(PSNR)作为衡量指标; 属性质量则用颜色信息的(y,u,v)三个分量的PSNR作为衡量指标. 其中BD-rate的计算参考视频编码[20].
根据V-PCC CTC,QP参数分别为VPCC参考软件里面的5个等级,分割时M=5,八叉树分割停止时的点数为2 000,由于量化参数分为5个等级,对应均方误差的阈值也设置为5个等级,从小到大分别是0.50、0.55、0.60、0.65、0.65对应从小到大的5个量化步长. 如图 4分别展示了本方法和V-PCC的Queen数据集属性质量的PSNR、几何质量的PSNR和码率关系的RD曲线图. 从图4(a)~(c)可以看出,不同QP量化下,本方法相比V-PCC在同等属性质量下码率均有降低,随着码率增加,配准性能进一步提高,因此减少了更多点的压缩,所以性能相比具有更多的提升. 相比图4(a)~(c)可以发现, 图4(d)~(e)在同等几何质量下降低了更多的码率. 因为基于配准的帧间估计主要针对几何信息,所以相比属性信息改善更大.

图4 Queen序列率失真曲线图Fig.4 Rate-distortion curves for selected test sequences Queen
表1展示了不同测试序列下BD-rate的改善情况. 对于同等几何质量,基于D1和D2的平均码率分别降低20.70%和40.73%; 对于同等属性质量下,基于y、u、v三个属性,平均码率分别降低了21.61%、29.74%、20.90%. Soldier和Queen数据集同等几何质量下码率分别减少88%和51%,RedAndBlack数据集同等几何质量码率减少为13.53%和77.50%,相比较数值变小了,Loot 和Longdress数据集同等几何质量下码率反而上升了. 观察图5可以发现,Soldier和Queen数据集的对象是人为创作的,属于非自然的,帧与帧之间运动比较有限,可以通过三维配准帧间预测出大部分当前帧的点云,具有较大的性能提升. 而Loot 、Longdress和RedAndBlack数据集对象是真实的人,运动更为复杂,例如,当衣服抖动时,发生旋转、平移、伸缩,通过配准的误差较大,不利于三维配准帧间预测.
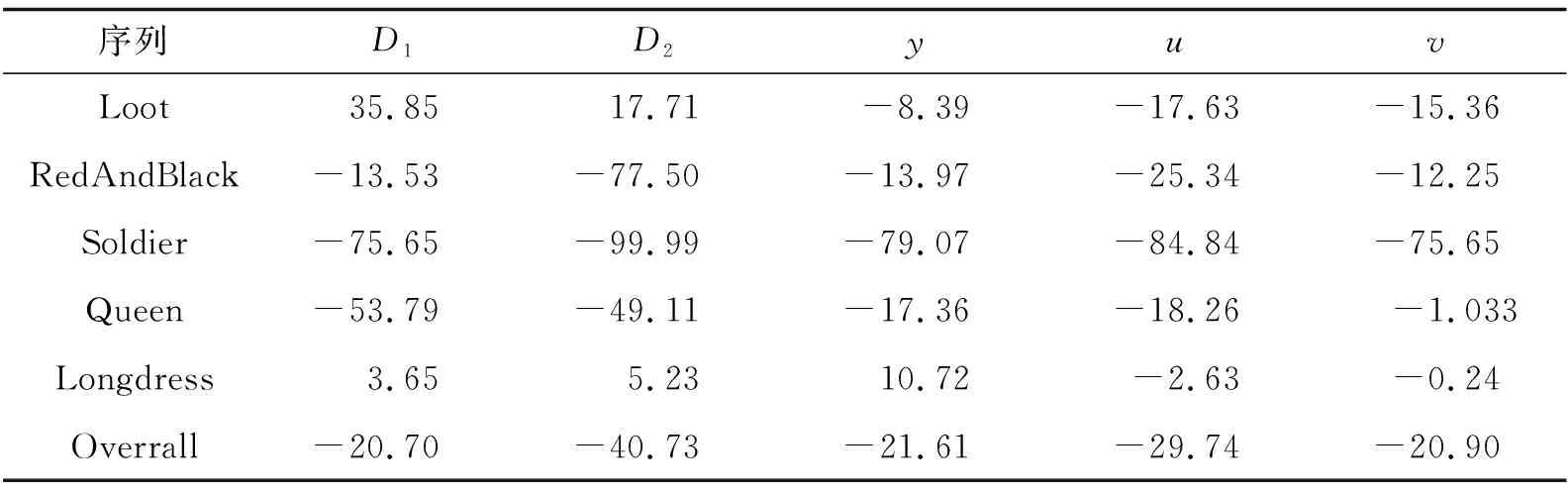
表1 BD-BR结果

图5 展示5个测试序列中的一帧示例视图[4]Fig.5 Example views rendered from one frame of the five test sequences[4]
表2是在同一数据集,不同的方法相对V-PCC在同等质量下的平均码率. 根据表中数据可以看到,本方法性能是远超经典的编码方法Mekuria等[7]采用八叉树和图像帧内编码几何信息和属性信息, 帧间则把点云划分为N·N·N的宏块并使用ICP配准. Kim等[17]对I帧通过V-PCC编码,P帧则通过点云3D搜索I帧中最佳匹配的点从而恢复,但由于点云是运动的,帧间存在较大差异时需要编码较大的残差. Li等[16]通过在编码端重建三维点云弥补了因为投影产生的连续性被破坏的问题,有效提高了属性信息的编码,但是,帧与帧之间的几何信息由于经过旋转和平移,对应点云投影后生成的图像本身存在较大的差异,此时帧间估计后具有较大的残差. 本研究首先提出的分割方法保证了帧与帧之间的对应性和运动的一致性,使得可以有效进行后续的三维配准帧间预测,进一步根据三维配准帧间预测的可靠信分类,筛选出可以有效地通过三维配准帧间预测的点云,减少大量点的编码,进一步提高了V-PCC的性能.

表2 不同的方法相对V-PCC的BD-BR结果
3 结语
本研究提出一种优先采用三维配准帧间预测以及结合V-PCC的帧间预测的改进方法. 首先针对点云帧与帧之间存在点数差异、一帧点云不同位置运动不尽相同,导致不能进行有效的点云配准,提出了一种基于运动一致性的二叉树的粗分割,进一步的八叉树细分割方法,自适应地分割具有相同运动的相邻点云,且保证了分割后参考点云和当前点云的对应性. 为了保证三维配准帧间预测的可靠性,对分割后的点云使用ICP估计运动信息并计算误差,对于运动估计后误差小于一定阈值的点云,则只需编码块索引和运动信息,对于误差较大不能被有效地三维配准帧间预测的点云,则融合并用高效的V-PCC的帧间预测,形成一种基于分割的混合帧间预测的方法.
相比V-PCC的编码,本方法在保证点云质量的同时减少了大量点的编码. 通过实验验证,本算法进一步改进了V-PCC的编码性能. 本研究的下一步目标分为两步: 1) 使用深度学习的点云生成的方法替代ICP的点云配准方法,这样可以避免由于点云存在较大差异时,帧间预测可靠性较差的问题; 2) 把上述分割和配准后的点云重新投影到图像,并添加到视频编码的参考帧,进一步提高编码的可靠性.
