基于卷积神经网络和迁移学习的小麦病虫害识别
2022-04-27姚建斌张英娜刘建华
姚建斌, 张英娜, 刘建华
(华北水利水电大学 信息工程学院, 河南 郑州 450046)
病虫害是影响农业生产的重要自然灾害,据统计,中国每年因病虫害导致粮食损失1 400万t,影响着我国粮食的产量和质量[1]。因此,减少粮食病虫害损失,对我国粮食止损具有重要意义。小麦是我国三大粮食作物之一,其播种面积和产量均位于我国粮食作物的前列。据国家统计局资料,2020年我国小麦播种面积和产量分别占全国农作物种植总面积和农作物总产量的19.4%和19.7%[2]。小麦病虫害具有种类多、易发、蔓延快的特点,早期快速识别病虫害的种类和范围,对精准控制病虫害传播、及时止损具有重要意义。针对小麦病虫害识别,传统的方法是通过日常巡查和经验来判断病虫害发生与否以及病虫害的种类和程度,存在不能及时发现问题延误病虫害最佳防治时机、病虫害范围识别不准导致过度喷洒农药等问题[3]。随着现代农业对生产技术需求的提高,传统的方式已无法大规模且快速准确地判断病虫害的程度及范围,新的智慧化病虫害识别技术应运而生。
近年来,无人机航拍、图像处理、模式识别技术日趋成熟,并不断被应用到农作物病虫害防治领域,使得传统机器视觉检测技术在病虫害识别上取得了长足的发展[4-10]。然而,传统机器视觉检测技术仍存在鲁棒性和硬件消耗性大等缺点,使得“噪声”只能通过人为修正,运算速度慢,从而导致识别准确率和快速检测两个方面受到限制。卷积神经网络(Convolutional Neural Network,CNN)是一种新的深度学习算法,一经问世,在图像处理与信号识别领域发展迅速[11-19]。成熟的CNN技术为农作物病虫害快速准确识别提供了新的手段,但其采用的多为背景简单的实验室场景的样本,在实际应用中存在无法适应大田复杂场景的情况。
本文分别以AlexNet,VGGNet16和Inception-V3网络为基础,使用平均识别准确率、处理速度两个模型评价指标进行综合评价,选取最佳网络模型;在数据扩充集下,使用渐变学习率和训练所有层的迁移学习方法,构建小麦病虫害精准识别网络模型,实现小麦病虫害的精准识别。
1 研究方法
1.1 卷积神经网络
卷积神经网络的本质是一个多层感知机,由输入层、卷积层、池化层、全连接层、输出层共5部分组成。随着网络的不断优化,加入激活函数层来加强非线性关系,加入Dropout层来提高模型的泛化能力。局部连接、参数共享是卷积神经网络的两大特点。AlexNet、VGGNet16和Inception-V3是近几年具有代表意义的3种卷积神经网络模型,其在图像分类领域均有突出的表现。
1.1.1 AlexNet网络模型
AlexNet网络模型由Alex、Hinton在图像识别大赛中提出。它是一个基于LeNet模型改造的且较LeNet模型更深更宽的升级版本,在2012年图像识别大赛中表现优异,获得了冠军,奠定了CNN在图像分类算法中的核心地位[20]。
AlexNet网络模型总共8层,包括5个卷积层和3个全连接层。该网络模型创新性地采用Dropout算法,使一些神经元在训练过程中随机失效,有效防止了过拟合现象的发生,并在很大程度上提高了模型的泛化能力;在激活函数的选取上,采用ReLU激活函数替代了Sigmoid激活函数,有效解决了梯度弥散问题,取得了良好效果。
1.1.2 VGGNet16的网络模型
VGGNet16的网络模型是2014年图像识别竞赛的第二名。该网络模型共有19层,其中卷积层16层。VGGNet16的特点是全部应用了较小的卷积核(3×3)和较小的池化核(2×2)。研究[21]表明,相对于单一大卷积核的卷积操作,较小的卷积核可以在很大程度上减少卷积操作产生的计算量,不仅如此,多个小卷积核的堆叠也提升了网络模型精度,优化了后续网络模型的性能。
1.1.3 Inception-V3网络模型
与之前的卷积神经网络通过堆叠卷积层来提高网络性能相比,Google团队对网络中的传统卷积层进行了修改,提出了Inception结构,用于增加网络深度和宽度,提高深度神经网络性能。该团队在2014年提出了Inception-V1算法,对不同尺度的卷积核和池化层进行了整合,将最终的结果拼接形成了Inception模块,模块利用1×1的卷积核进行降维,降低了参数量[22]。Inception-V3在Inception-V1的基础上,将原始的7×7的卷积核用一维的1×7和7×1的两个卷积核进行替换,这种对卷积核进行的非对称分解不仅减少了参数规模,并且由于1个卷积核拆分成2个卷积核,还进一步解决了过深的网络模型造成的过拟合以及计算量巨大问题,提升了网络性能。典型的Inception-V3网络模型的Inception模块结构图如图1所示。
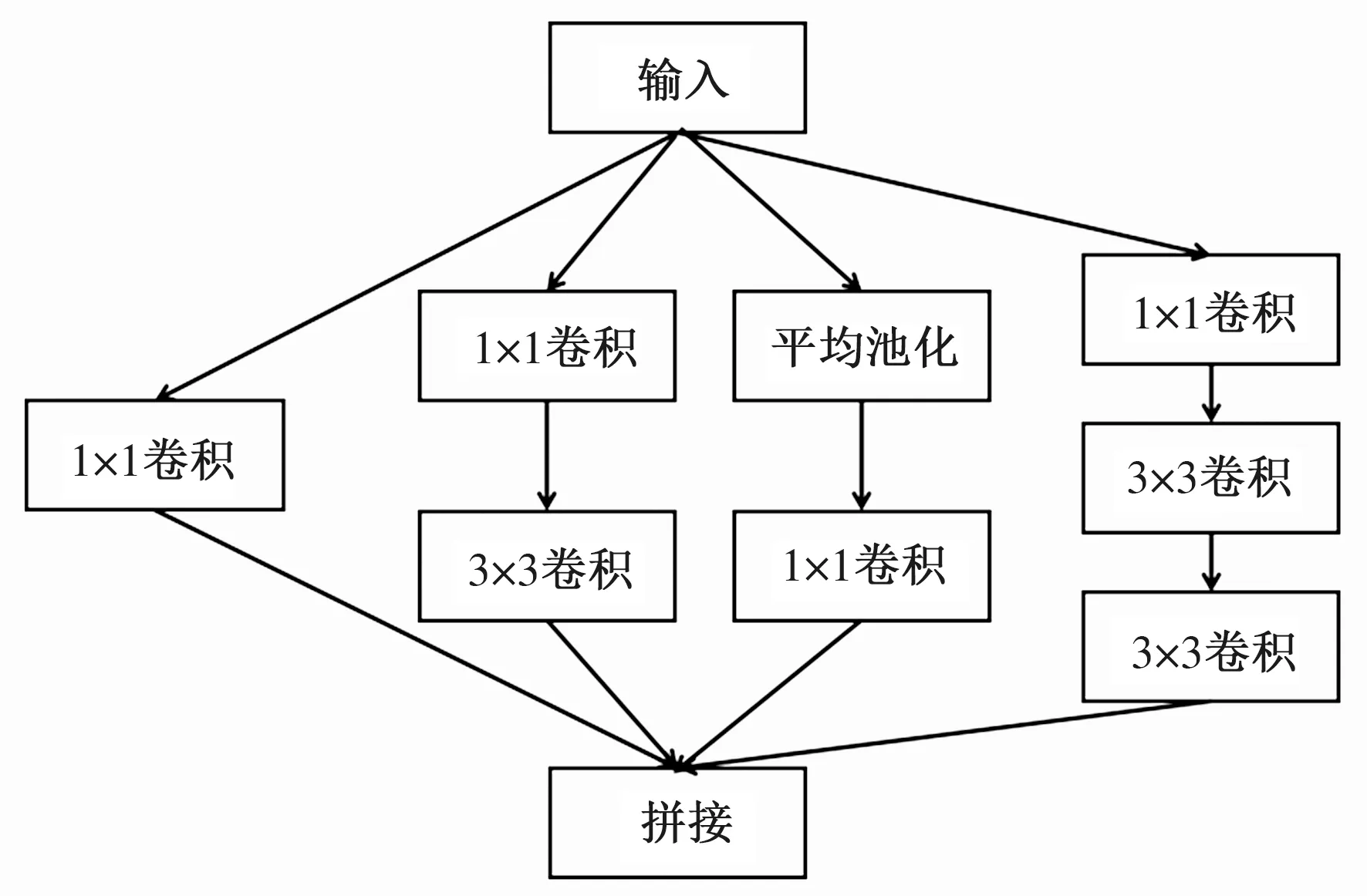
图1 Inception-V3的Inception模块结构图
1.2 数据扩充与迁移学习
1.2.1 数据扩充
本文中的小麦病虫害数据集均在试验田现场采集而来,数据类型包含健康小麦、条锈病、叶锈病、白粉病和蚜虫共5种类型。整体的数据集分为测试集和训练集,部分数据集见表1。
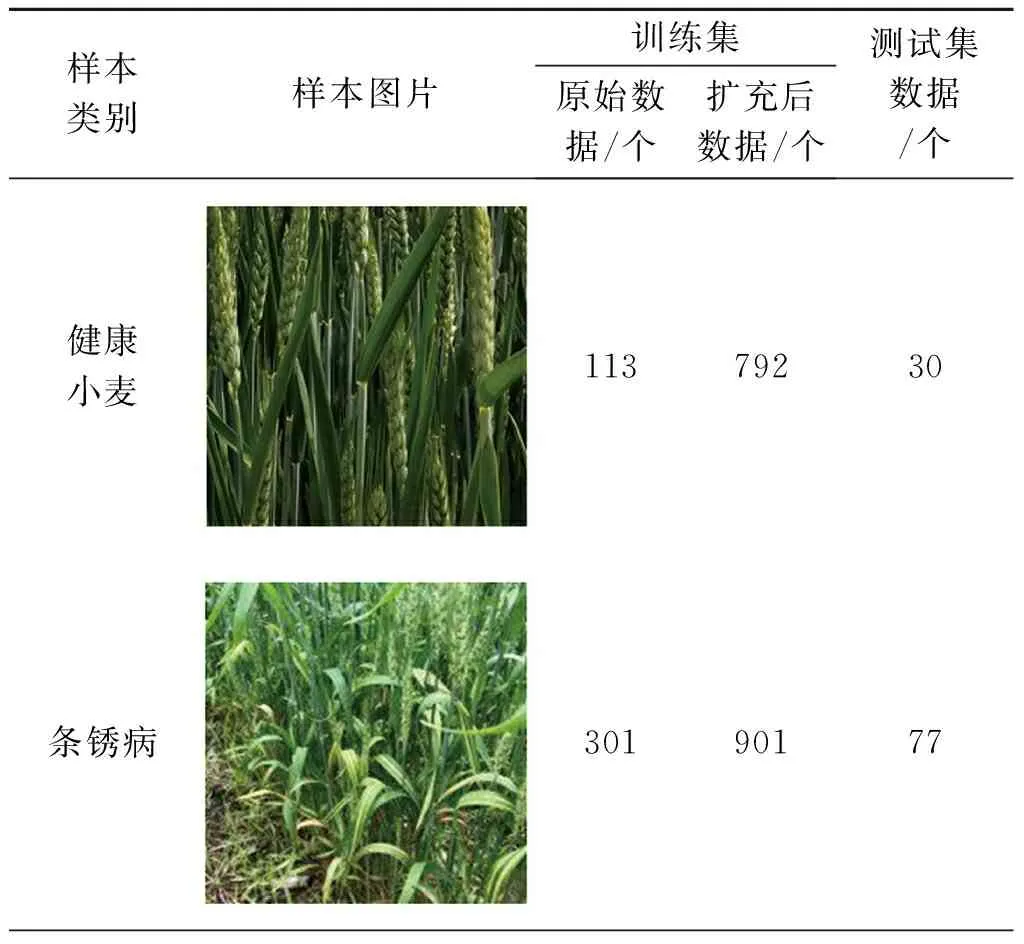
表1 小麦病虫害数据集

续表
针对实际应用中数据集样本类型少、数量分布不均等情况,对训练集进行了随机效果扩充,扩充方法主要有以下几种:
1)添加随机噪声和随机滤波。由于小麦数据集样本图片背景比较复杂,会受到很多噪声和光波的干扰,为避免复杂背景对识别结果产生较大的干扰,采用添加随机噪声和添加随机滤波的方法提高模型对复杂背景的泛化能力。其中,随机滤波包括中值滤波、双边滤波、高斯模糊和均值滤波。
2)随机旋转和偏移。由于本文中的数据集均通过现场采样获取,在采样过程中并非所有目标均规规整整且在图像的中间位置,因此对数据集进行随机旋转和偏移,提高模型对目标位置变化的泛化能力。
3)随机色彩抖动。由于样本的采集未考虑时间和天气因素,因此,在光照充足的中午和光照较弱的下午采集的样本,在色彩方面会有较大的差异。为提高模型对光照因素的泛化能力,加入随机色彩抖动。
1.2.2 迁移学习
由于在利用数据集对上述3种网络模型进行训练的过程中,使用全新学习的方式出现了准确率较低且震荡无法收敛的情况。因此,基于ImageNet数据集对3种网络模型进行预训练,然后再将预训练好的模型迁移到本文数据集上,进行进一步的训练。Inception-V3网络模型直接使用TensorFlow框架封装好的ImageNet数据集上的迁移学习模型,而对于AlexNet和VGGNet16网络模型则手动构建对应的模型,再进行参数加载。这种加载参数的迁移学习方式可以选择性固定后几层的参数,而对于Inception-V3模型,因无法修改瓶颈层之前的参数,因此只能调整最后一个全连接层的参数。本文中的基本迁移学习方式就是固定其他层参数,仅修改最后全连接层的输出个数。3种网络模型迁移学习方式的具体学习流程如图2所示。
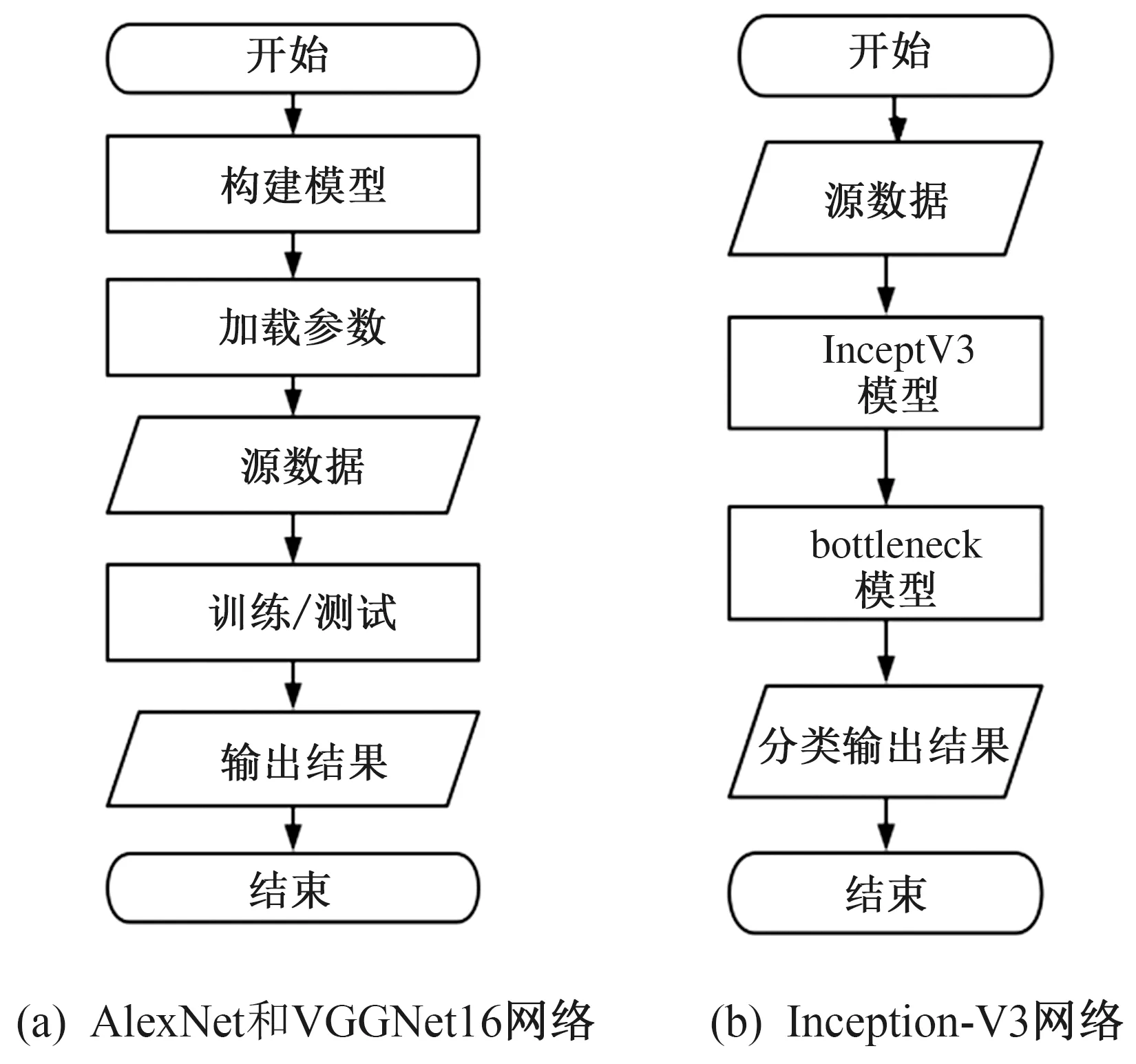
图2 3种网络模型的训练流程
1.3 模型评价指标
模型训练过程中,迭代次数和学习率等超参数是通过不断的试验确定的。本文选取准确率最高的一组超参数对应的模型,作为该网络模型的最终选择模型,然后进行比较。对于最高测试集平均识别准确率不唯一的情况,本文选取迭代次数最小的模型为最终的网络模型,并通过平均识别准确率和运行速度两个指标来对网络模型进行评价。
1)平均识别准确率。其表示测试集中分类正确的样本数与测试集总样本数之比,计算公式为:
(1)
式中:Ns为数据集样本的类别数量,文中Ns=5;Ni为第i类样本的数量;Nii为预测正确的第i类样本数量。
2)运行速度。计算模型处理一个样本的时间,作为网络模型的一个指标。
1.4 试验设计
1.4.1 试验环境
试验在Python3.7.9、TensorFlow-CPU软件下完成,使用的机器为MacbookAir,处理器为Intel Core i5,主频为1.6 GHz。
1.4.2 试验方案
试验分为两个步骤。步骤一是基础模型的选择:使用未扩充数据集和只训练最后一个全连接层的迁移方法,对3种卷积神经网络模型进行训练,并通过对比模型的平均识别准确率和运行速度,选出最佳的基础网络模型,本步骤涉及3组对比试验。步骤二是数据扩充及迁移学习训练:分别在未扩充数据集和扩充数据集上,使用不变学习率和渐变学习率,对模型分别进行仅训练全连接层和训练所有层两种迁移学习方式的训练,共进行30个迭代。本环节涉及8组对比试验,其中不变学习率为0.000 5,渐变学习率的初始值为0.001,在训练过程中,每5个迭代学习率减小为原来的一半,以5个迭代为一组,学习率分别为0.001、0.000 5、0.000 25等。
为更好地利用计算机资源,分批次利用训练数据集和测试数据集进行模型训练。其中每个批次包含32个样本。在测试集每个批次验证结束后,使用TensorBoard记录本批次的平均识别准确率,一个迭代中有206条测试数据,共记录206/32约6个批次的平均识别准确率,30个迭代共记录180个批次的平均识别准确率。
2 结果分析
2.1 CNN网络优选结果
使用只训练最后的全连接层的迁移学习方法,对3种CNN网络模型进行训练,筛选出对本数据集泛化能力最强的模型,作为本文的基础模型。3种网络模型的基础试验结果见表2。
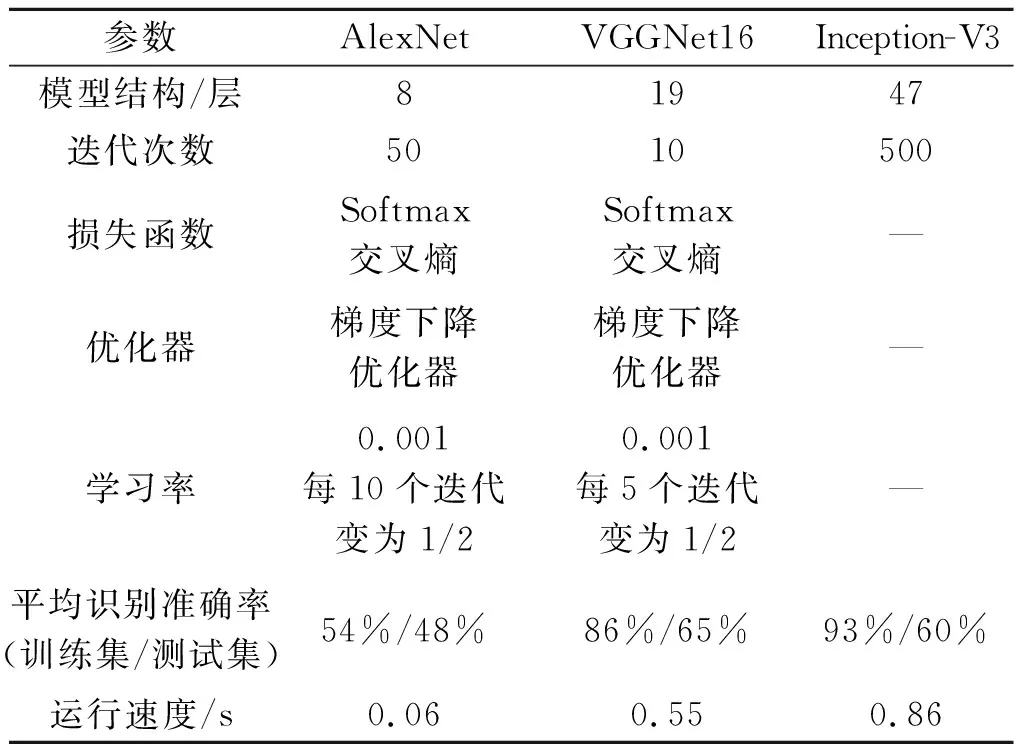
表2 3种网络模型的基础试验结果
由表2可知:①相对于其他两个网络模型的迁移学习方式,Inception-V3网络模型的具有局限性,除迭代次数外其他超参数无法修改,且出现了过拟合现象,训练集表现良好但测试集表现不佳,同时单张图片的处理速度也慢于其他网络模型的,说明其不适合本文数据集。②VGGNet16网络模型的运行速度虽然逊于Alexnet的,但在准确率上优于Alexnet的,且经过10个迭代即可达到较好的效果,相比于Alexnet的50个迭代,VGGNet16网络模型的收敛速度更快。综上,选择VGGNet16网络模型作为本文的基础网络模型进行下一步的优化。
2.2 深度学习试验结果
基于未扩充数据集和扩充后数据集两种数据集、非训练所有层和训练所有层两种迁移学习方式、不变学习率和渐变学习率两种学习方法共进行8种组合试验,对不同组合试验的收敛迭代次数和识别准确率进行统计,结果见表3。

表3 VGGNet16试验结果
2.2.1 数据扩充对模型的影响
在相同学习率和迁移学习方式下,试验1、2、5、6分别与试验3、4、7、8互为对比试验,限于篇幅,仅列出试验5、7与试验6、8的对比结果,如图3所示。
由图3可知:在渐变学习率下,使用扩充数据集训练的模型的平均识别准确率均高于未扩充数据集的。结合表3分析可知,试验1、2、5、6的训练集平均识别准确率均远大于测试集的平均识别准确率,出现了过拟合现象,而试验3、4、7、8的训练集与测试集平均识别准确率相差不大,未出现过拟合现象。综上可知,对数据集进行扩充不仅能有效提高模型的平均识别准确率,还能很好地解决过拟合问题。
2.2.2 迁移学习方法对模型的影响
在相同数据集和学习率的条件下,试验1、3、5、7分别与试验2、4、6、8互为对比试验,限于篇幅,仅列出试验5、6和试验7、8的对比结果,如图4所示。由图4可知:对于训练集,训练所有层的迁移学习方法下的模型平均识别准确率相较于非训练所有层方法的有明显提高,说明本文的样本特征与ImageNet数据集的样本特征差别较大;对于测试集,训练所有层的迁移学习方法下的模型平均识别准确率相较于非训练所有层方法的也有明显提高。说明训练所有层的迁移学习方法能够更好地捕捉样本特征。

图4 渐变学习率下两种迁移学习结果
2.2.3 渐变学习率对模型的影响
在相同的数据集和迁移学习方式下,试验1、2、3、4分别与试验5、6、7、8互为对比试验,限于篇幅,仅列出试验1、5和试验2、6的对比结果,如图5所示。
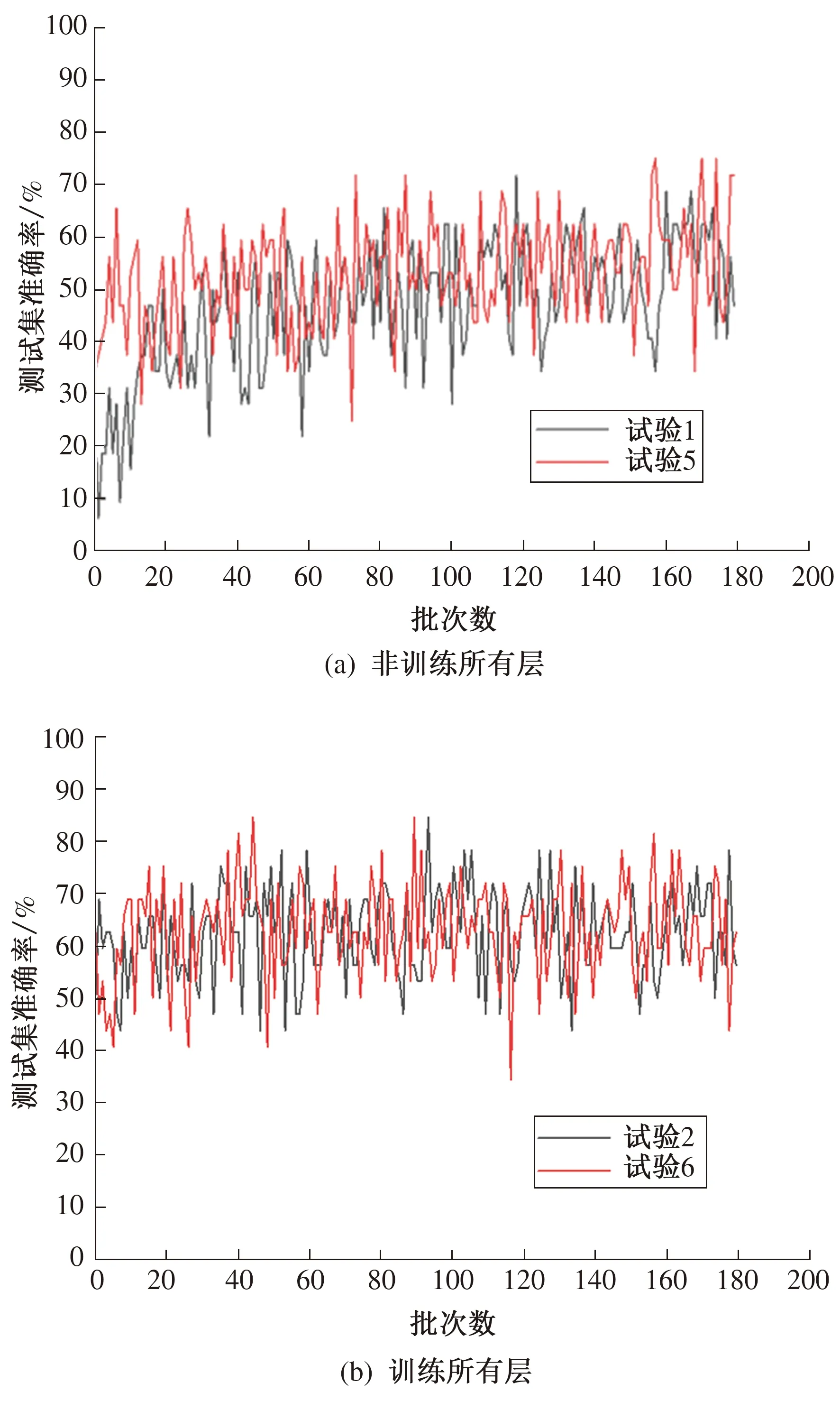
图5 非扩充数据集下两种学习率结果
由图5可知:对于测试集,渐变学习率下的模型平均识别准确率略高于不变学习率的,且平均识别准确率的提高范围为5%~7%;同时,渐变学习率下的模型收敛速度相较于不变学习率的有显著提高,而不变学习率条件下,训练30批次及以上才能收敛,渐变学习率条件下,10个批次即可收敛。说明学习率初始值为0.001,在训练过程中逐渐减小的渐变学习率学习方法更适合本文。
综上,对数据集进行扩充、使用渐变的学习率、基于训练所有层的迁移学习方式对模型进行训练,能很好地解决模型的过拟合问题、加快模型的收敛速度、提高模型的平均识别准确率(试验8的测试集平均识别准确率高达95%),在小麦病虫害精准识别上具有良好的应用前景。
本文基于4种小麦叶部病虫害以及健康小麦的单标签数据集,对构建的网络模型进行训练,获得了较好的效果。然而,实际生产中的小麦病虫害远不止本文涉及的几种,同时还存在多种病虫害并存的现象。受当前数据集的限制,暂未统筹考虑这些情况,后期有待将多标签的样本扩充到数据集中,进一步修改模型训练过程中的损失函数,以及最后全连接层的激活函数,调整模型的输出为样本存在各种病虫害的概率,从而实现多标签的病虫害样本分类识别,进一步提高模型的实用价值。
3 结语
本文基于试验田现场采集的样本,通过对比Alexnet、VGGNet16和Inception-V3网络模型的测试集平均准确率和运行速度,选择VGGNet16网络模型作为本文的基础网络。然后,根据不同的数据集、迁移学习方式和学习率设计了8组对比试验,得出如下结论:
1)在小规模数据集条件下,使用数据扩充技术对数据集进行扩充,能够有效提高模型的平均识别准确率,解决了小规模数据集容易出现的过拟合问题。
2)使用迁移学习方法,能够解决直接训练时对机器硬件要求过高,且难以收敛的问题;同时,使用训练所有层的迁移学习方法的模型平均识别准确率较只训练最后全连接层的迁移学习方法的高。
3)使用渐变学习率先以较大的学习率学习样本的基本特征,然后再使用较小的学习率进一步学习样本更高级的特征,相较于使用不变学习率,模型的收敛速度更快,并且能取得更好的识别效果。
