1种基于视频的油田危险区域入侵检测智能综合识别技术研究*
2022-04-26白欣宇姜文文于巾涛
田 枫,白欣宇,刘 芳,姜文文,于巾涛
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引言
随着深度学习等大量智能算法的出现以及计算机性能的不断提升,使得利用智能算法对监控视频进行快速分析成为可能。基于深度学习算法的智能安防技术在智慧交通、智慧工地、智能矿场等领域开始了初步的应用。在我国各大油田由建设数字化油田转变建设智慧油田的背景下,智能安防技术与智慧油田的结合应用,是油田发展跨领域融合的1种趋势,更是归属于“数字中国”建设必不可少的一环。而油田危险区域入侵检测智能综合识别技术是智能安防技术与智慧油田结合趋势下的核心安防技术,油田危险区域入侵智能综合识别技术可彻底取代基于人力监控油田的高成本低准确率的方式,可为油田安全提供有力保障。
当前,智能安防技术在其他应用领域中技术架构趋向成熟,“智慧油田”理念逐步完善,在二者结合落地的过程中,存在油田危险因素多、油田危险区域多,且危险场景复杂等问题。针对各种油田危险因素,罗音宇等[1]提出了1种含硫气井硫化氢扩散危险程度的分级技术;张若诚等[2]结合APIR500防爆标准,初步进行了油田钻井井场划分;刘康等[3]提出浮式生产系统泄漏天然气扩散规律与危险区域的划分;钻井风险综合评价方法[4-6]对多种油田风险识别因素进行了定量客观的评价。以上研究均从油田施工人员作业安全风险管理方面提出了应对措施,对油田危险区域入侵智能综合识别技术的落地与油田安全作业管理具有重大意义。
针对危险区域入侵问题,王瑞等[7]在解决铁路区域入侵问题方面,提出了1种全天候的铁路区域入侵算法,有效解决全天候的铁路周界的入侵检测。王伟等[8]对建筑施工领域进行区域入侵判断,有效降低入侵危险区域行为的发生。
目前,基于视频的油田危险区域入侵检测算法存在如下难点:1)缺乏大量的训练样本。2)监控视频画质低且目标较小。3)缺乏油田危险场景等级划分的理论与危险区域识别方法。4)缺乏夜间区域入侵方法。
针对上述难点,本文提出1种基于视频的油田危险区域入侵检测智能综合识别算法,该算法从全局视频监控的角度出发,结合相关标准[4-6]对油田危险区域进行划分,并在视频流中完成场景匹配与危险区域识别;针对白天光线条件较好时,通过对深度学习算法进行改进进而提高检出率;针对夜晚场景光线条件差,易受背景干扰等情况,通过运动目标判别方式对作业人员闯入危险作业区进行检测。本算法能够自动判别危险作业区人员闯入,避免设备损坏并降低人员伤亡的风险。
1 油田危险区域入侵检测技术架构
针对油田危险入侵检测存在的难点以及使用场景需求,提出1种综合识别算法。具体包含2个任务:第1个任务为根据危险因素进行油田危险区域分级与映射,实现危险区域的自动判别;第2个任务为人员进入危险区域的判别,为提高检测准确率,将黑夜和白天场景分开处理,结合射线法进行入侵判断。
在白天场景使用目标检测技术,如图1(a)所示。首先,以监控摄像头的rtsp视频流为输入,输入图像进行危险场景的匹配、危险区域的识别与定位;然后,以YOLOv5作为基础网络,加入卷积注意力模块提高目标定位精度,增加检出率;最后,使用射线法完成区域入侵的判别。

图1 油田危险区域入侵Fig.1 Intrusion of oilfield dangerous areas
在夜间场景中使用运动目标检测算法,如图1(b)所示,首先针对连续帧的视频图像进行背景动态建模,使用背景减除法区分前景与背景,然后使用形态学方法过滤无用信息进行精准定位,最后应用三帧差分法确定运动目标,完成区域入侵判别。
2 油田入侵检测算法
2.1 油田危险区域分级与自动识别
油田作业现场中存在多种危险源,例如原油仓库、泥浆池、抽油机等。当这些地方出现故障时,均可能造成严重的财产损失和人员伤亡。因此,本文在基于视频的油田危险区域入侵智能识别的角度下,提出油田危险场景分级与自动识别方法,首先对危险场景进行分级,然后对危险区域进行自动识别。
第1部分为危险场景分级,参考油田3类危险源[5]与钻井风险因素综合评价[4-6]等多种场景下危险因素评价方法,将其中的固有危险源[4]定义为易燃易爆区,触发危险源[4]定义为临时故障区,人为型危险源[4]定义为违章操作区。结合文献[2-6]提出的相关危险场景划分标准,根据是否容易造成人员伤亡,设备损坏,环境污染等因素将危险场景的等级设置为3级:1级区域入侵警报,极易发生人员伤亡与设备损坏;2级入侵警报,易发生人员伤亡;3级区域入侵警戒,易发生人员受伤与设备损坏。根据分级标准,构建油田危险场景库。
第2部分为危险区域的自动识别,如图2所示:首先,提取输入视频流图像中的角点特征,因SIFT[9]特征具有光照不变性,具有旋转不变性,缩放平移性、局部不变性等特性,因此本文使用SIFT在杂波较多、噪声较多的复杂场景中实现对危险场景、危险区域的判别。然后,将提取特征后的图片U与第1部分建立的油田危险场景库V进行危险场景匹配。图像特征匹配采用欧式距离d(U,V)作为相似性距离,如式(1)所示:

图2 危险区域自动识别Fig.2 Automatic identification of hazardous areas
(1)
式中:d(U,Vi)为相似性距离;U(x1,x2,…,x128)为视频流提取的特征描述子向量;Vi(y1,y2,…,y128)为危险场景库V的第i个场景特征描述子向量;xm,ym为特征描述子向量元素;m为第m个描述子向量。最后,将当前场景下的危险区域与视频流进行匹配,确定危险区域位置坐标后映射到视频流中,完成危险区域的自动判别。
2.2 白天场景下的目标检测方法
YOLOv5[10]是目前单阶段检测算法中具有较优检测效果的检测算法,可较好地兼顾检测的准确率以及运行速度,因此本文选择YOLOv5为基准检测算法,并对其特征提取网络部分与推理输出部分进行改进。
YOLOv5的网络结构如图3所示,在特征提取部分中使用Focus结构,减少计算量。使用CSPNet[11]的CSP模块,增加CNN的学习能力,降低计算瓶颈并节约内存成本。

图3 检测网络结构Fig.3 Detection network structure
在特征融合部分,采用FPN(特征金字塔)[12]结构,使用自上而下的路径和横向连接以及自底向上的路径增强,对语义信息与定位信息进行特征融合,大大提高多尺度检测的准确性。
在特征预测部分,在特征图上应用锚定框并生成带有类概率、对象得分和包围框的3种不同大小的特征图向量。
本文将CBAM[13]注意力机制放在骨干网络的池化金字塔前,能使特征学习更加专注于油田危险区域内工人特征,抑制其它干扰信息,增强模型对于油田工人检测精度。输入到CBAM注意力模块中,给定1个油田工人特征图F∈RC*H*W,C为通道数,H为特征图的高度,W为特征图的宽度,使用CBAM推断出1个1维的通道注意力权重Mc∈RC*1*1,之后通道注意力权重Mc与特征图F计算得到通道注意力特征图F′,如式(2)所示:
F′=Mc(F)⊗F
(2)
式中:F′为用于空间注意力模块的特征输入;F为油田工人特征图;Mc为通道注意力权重;⊗表示逐元素相乘。
CBAM推理出1个二维的空间注意力权重Mc∈R1*H*W[13]。然后利用F′与空间注意力权重Ms相乘得到空间注意力特征图F″,最终输出的特征图F″与原始特征进行融合以进行自适应特征细化。其中如式(3)所示:
F″=Ms(F′)⊗F′
(3)
式中:F″为空间注意力特征图;Ms为空间注意力;F′用于空间注意力模块的特征输入;⊗表示逐元素相乘。
在特征预测部分每个卷积模块前加入SE注意力机制,通过增强建模通道之间的相互依赖关系,进而自适应地调整通道的特征响应。主要步骤如下:输入的特征图进行全局平均池化,得到长度等于通道数M的实数列Zgap。压缩率r=16的情况下进行特征图X=[x1,x2,…,xn]通过全局平均池化Fgap,计算过程如式(4)~(5)所示:
(4)
(5)
式中:Zgap为长度等于通道数M的实数列;Fgap为全局平均池化;xc为c通道输入的权重特征;H为特征图的高度;W为特征图的宽度;F1为进行降维的全连接层数;F2为升维的全连接层数;C为特征图的索引;M为通道数;r为压缩率。
进行Sigmoid函数激活,进而生成每个通道对应的权重信息S=[s1,s2,…,sc]。如式(6)所示:
S=Sigmoid(F2(RELU(F1*Zgap)))
(6)
式中:S为每个通道对应的权重信息;F2为升维的全连接层数;F1为进行降维的全连接层数;Zgap为长度等于通道数M的实数列。
根据权值对输入的特征图加权更新,得到更新后的通道特征Y=[y1,y2,…,yc],如式(7)所示:
Yc=sc*xc
(7)
式中:Yc为c通道更新的通道特征;sc为c通道对应的权重信息;xc为c通道输入的权重特征。
使用SENet[14]注意力模块,能够更好地利用全局信息进行特征筛选,对重要特征强调并对非重要特征进行抑制,从而重新校准特征来提高网络的表示能力。
2.3 黑夜场景下的目标检测方法
由于黑夜场景中光线不足,目标与背景难以区分,因此本文首先采用背景减除法[15]对背景建模,对各个像素的观察值进行聚类,经过一段时间的学习之后,样本数最多的子类构成动态背景的模型。然后使用形态学处理方法进行区域连通,以腐蚀与膨胀[16]将2个独立的连通域拼接成为1个连通域,提取出图像的轮廓,作为下步的运动目标检测的输入。最后使用三帧差分法[17]进行运动目标的检测,其计算量小,能够快速检测并标记出场景中的运动目标。
将2帧图像对应像素点的灰度值进行相减,并取其绝对值,得到差分图像Dn。两帧差分计算公式如式(8)所示:
Dn(x,y)=|fn(x,y)-fn-1(x,y)|
(8)
(9)
式中:Dn为差分图像;fn为像素点的灰度值。
按照式(8)分别得到差分图像Dn+1和Dn,对差分图像Dn+1和Dn按照式(9)进行与操作,得到图像Dn′。
然后再进行阈值处理、连通性分析,最终提取出运动目标。
2.4 射线法判别危险区域入侵
人物的落脚点是决定人物位置的关键因素,人物是否走入危险区域内,由人物落脚点的位置进行判断。因此考虑人物的落脚点是否在危险区域内,如图4所示,在完成目标检测后,将人物踏入危险区域的区域入侵问题抽象成为人物的落脚点与危险区域多边形的相交问题,即判断点是否在多边形的内部。本文使用射线法[18]进行区域入侵的判断。

图4 判断点是否在多边形内Fig.4 Judgment of whether points in polygon
计算油田工人落脚点Dx,如式(10)所示:
(10)
式中:Dx为油田工人落脚点;x1,y1为中心点的坐标;h为输出的定位框的高。
根据目标检测结果输出的工人定位框,判断是否发生多边形区域入侵,结果为奇数则认定发生区域入侵,如式(11)所示:
Rinvade=(sum(cross(Dx,Grax)))%2
(11)
式中:cross为Dx点向任意方向做射线;Grax为自定义危险区域。
3 实验及结果分析
3.1 目标检测实验及分析
3.1.1 数据整理
1)油田综合视频数据
对油田综合视频进行采样(约10 000张),经统计,视频中出现较为清晰的工人图像占比约68%,而距离较远难以识别的人员约占32%。
由此可见,综合视频中的油田工人目标存在偏小的情况。油田危险区域入侵者主要为油田工人,本文将油田危险区域综合视频数据进行筛选处理,选取含有油田工人的视频图像,根据人员尺寸进行如下数据划分:①油田工人对应的像素高度小于40的图片设置为模糊数据;②油田工人像素在40到70之间设为小尺寸数据;③当油田工人像素大于70设置为正常尺寸数据。处理后的油田综合视频样本数据,模糊数据约占20%,小尺度数据约占25%,正常尺寸数据约占55%。
2)VOC 2012[19]Person
为提高模型的泛化性,对VOC 2012提取person类,结合油田综合视频工人目标特点,选取具有模糊,目标较小的人物3 100张。为提高算法的检测精度及算法的可移植性,为适应油田不同场景下的危险区域入侵检测,算法训练采用油田工人视频数据和筛选VOC 2012 person中更适应于油田现场工人的数据集组成油田工人检测数据集,使得在各种油田场景下更加鲁棒的提取油田工人特征,提高油田工人检测精度,进而提高危险入侵判定的准确性。
3.1.2 实验结果分析
本文选取油田综合视频中具有危险区域的9个场景,共20个视频,从中选取含有油田工人图片1 500张作为测试集。
1)同一网络不同数据集:由表1可以看出,使用公开数据集与油田视频数据混合的数据集oilperson对比只使用公开数据集的算法效果具有显著性提升,泛化性最好,而仅使用油田视频数据集的方法反而效果变差,原因为油田危险场景数据的多样性欠佳。

表1 同一网络在不同训练集上验证的评价值Table 1 Evaluation values of same network verified on different training sets %
2)不同网络同一数据集:为保持实验对比的完整性,本文使用不同的算法模型,对oilperson进行训练,在上述同一测试集下进行验证。由表2可以看出,我们的算法与YOLOv5算法相比,在oilperson数据集上的表现更为优越,精确率提高了2.62%。

表2 不同网络在oilperson数据集上的评价值Table 2 Evaluation values of different networks on oilperson dataset %
对不同的场景下的油田区域检测效果如图5所示,图5(a),图5(d),图5(g)为易燃易爆区检测效果;图5(b),图5(f),图5(h)为临时故障区检测效果;图5(c),图5(e),图5(i)为违章操作区检测效果,其中图5(c)为夜间检测效果,仍有较好的检出率。通过以上检测结果可以看出本文算法对油田场景下较小尺寸的工人与模糊的工人具有较好的识别精度,无漏检、错误检情况出现。

图5 油田不同场景的检测效果Fig.5 Detection effect of different scenes in oilfield
3.2 油田区域入侵算法应用
运用本文提出的油田入侵检测算法在油田的不同场景下进行入侵检测准确率的测试,入侵检测准确率达到90%,具体效果如表3所示。
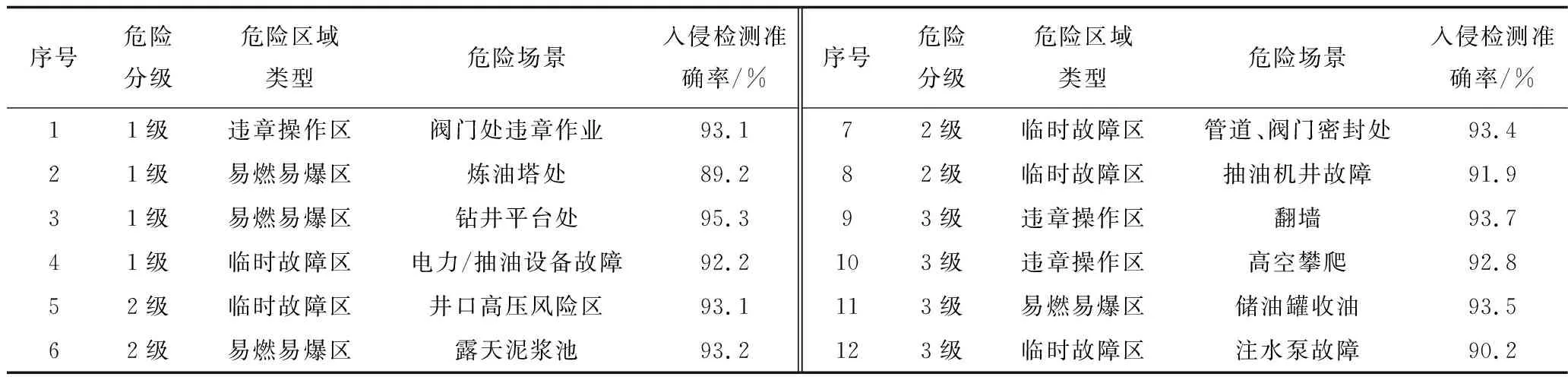
表3 不同场景的入侵检测准确率Table 3 Intrusion accuracy in different scenes
本文主要研究的是识别人员进入危险区域内,但给在高危区域中以其他方式判断进行某种违章操作提出了1种可能性。在部分模拟场景下,入侵效果如图6所示,在各种油田危险区域下进行分级,红色代表危险区域,人员进入危险区域使用红色检测框,并显示“入侵”标签。图6(a)为在违章操作区-阀门,施工人员在危险区域停留达到10 s,视为正在进行阀门正拧危险操作行为;图6(b)为违章操作区-近海区域,油田工人违规翻墙进入近海周界危险区域,视为危险区域入侵。图6(c)为临时故障区-抽油机故障处人员闯入判别为发生危险区域入侵。图6(d)为易燃易爆区-钻井平台处人员闯入判别为发生危险区域入侵。

图6 区域入侵效果Fig.6 Area intrusion effect
4 结论
1)结合油田多种危险因素,提出油田危险场景分级与映射方法。按照危险源进行危险区域等级划分并建立危险场景图像库,在视频流中自动识别危险场景并映射危险区域位置。
2)提出基于综合视频的全天候检测方法,针对白天场景,对YOLOv5模型进行改进,在特征提取网络部分添加CBAM卷积注意力模块,在预测部分添加SE通道注意力模块,使模型更加鲁棒地提取工人特征。同时,制作油田作业现场数据集,使得模型具有更好的泛化性。
3)本文设计1种人员闯入危险区域的自动入侵检测方式,引入射线法进行人员踏入危险区域的自动判别。
4)本文方法提高油田危险区域入侵的准确率,满足油田现场安全需求,有效预防油田危险区域内施工人员伤亡,并在真实油田场景下部署应用。
