大数据聚类算法在成品油输油管道泄漏检测中的应用
2022-04-25李鑫伟刘瑞哲
李鑫伟 刘瑞哲
〔国家石油天然气管网集团有限公司华中分公司 湖北武汉 430000〕
当今成品油管道输送已成为最经济、安全的输送方式[1-2],但自然灾害频发、第三方施工破坏以及不法分子打孔盗油都对管道安全构成重大威胁[3]。一旦管道发生泄漏必然带来严重安全隐患,不仅存在起火爆炸风险,同时还会造成环境污染[4]。因此,准确高效的泄漏检测系统已成为保障管道输送安稳长满优运行的必备设施[5]。
随着企业数据的快速增长以及大数据技术的发展[6],如何利用现有管道大数据进行有效挖掘,构建符合不同管道、不同工况的数学模型,实现管道泄漏发生后的快速、精确预警,已成为各油气管道企业确保安全运行的重要研究课题[7-8]。
1 研究背景
华中区域管网湖南管道全长732 km,年设计输量600万t。管道走向示意图见图1,各站场功能见表1。由图1和表1可知湖南管道工艺复杂,各站功能不同。为了加强管道泄漏风险检测投用了泄漏报警系统。由于各管段间地形、管路特性、各站工艺功能不同,泄漏报警系统并没有针对各管段的数据分析采取区别化的阈值设定,均按统一化的阈值设定。在实际运行中面对同一工况经常持续性的重复报警并存在大量误报,需要消耗大量的精力去处理误报信息,无法做到准确高效判断[9]。

图1 湖南管道走向示意图
2 理论分析
基于上述问题,采用聚类算法进行研究,该方法对大数据集处理有很高的效率并且可伸缩,在时间复杂度上近于线性,更加直观,非常适合挖掘大规模数据集[10]。因此,利用聚类算法对各管段各工况下数据进行收集分析确定合适的阈值非常合适,可有效提高预警的准确性。
2.1 聚类算法
目前存在大量的聚类算法,算法的选择取决于数据的类型、聚类的目的和具体的应用[11]。大体上分为划分聚类法、层次聚类法、基于密度的聚类算法、基于网络的聚类算法和其他聚类算法[12]。由于长输管道中数据量大、维度低、时间线性取值等特点,因此选用划分聚类算法更加合适。
划分聚类算法需要提前指定聚类数目或中心,通过反复的迭代运算来降低目标函数的误差值[13],当目标函数收敛至一定精度要求时得到相应的聚类结果[14]。典型的划分方法包括:K-means(K均值)聚类和K-medoids(K中值)聚类[15]。
离群点挖掘又称作异常检测,目的是发现与其他对象不同的对象[16]。离群点挖掘技术本质上与聚类技术类似,那些没有被聚类的点即离群点[17]。成品油管道泄漏检测最重要的就是通过挖掘输油中的异常数据并经过分析确定该数据是否为管道泄漏数据,从而判断管道是否发生了泄漏并定位泄漏的位置,基于聚类的离群点挖掘技术是一种新型高效技术[18]。
2.2 基于聚类的泄漏检测技术
在输油管道的正常运行中,受到泵流量的不稳定波动、压力表的最小量程等因素影响,各站的压力即使在无工况调整时都会不断波动,只是波幅有大有小[19]。通过聚类进行离群点挖掘可以发现并找出正常波动中微小的异常波动,然后将上下站压力的离群点进行对比,并根据压力传播的速度即负压波原理[20-21]算出最可能发生泄漏的位置。
由于在成品油管道正常输送的过程中,压力一直存在小幅波动的情况。因此,要在小幅波动的压力中找到真正的异常波动点,并且第一时间发出预警信号至关重要[22]。通过聚类技术,可以按照以下顺序筛选出压力异常波动的点。
(1)选取某个时长的压力数据(每秒取样一次作为单点数据a1、a2、a3……)作为一个离群数据集m,在数据处理中以时长60 s为子数据集m进行迭代计算(子数据集选取的具体时长可以根据管道特性进行调整)。
{m1,m2,m3,m4,m5……}∈M
m1={a1,a2,a3,a4,a5……a60}
(2)对数据集m中的所有对象进行聚类。
(1)
(2)
然后删除最后一个数据进行聚类:
(3)
(4)
两次聚类结果差值的绝对值即为该数据集最后一个数据的离群点得分Vm:
(5)
(3)每一个点都与前59个点(共60个点,60s的压力数据)作为一个数据集计算它的离群点得分,经采集数据分析计算得到新的离群点得分。这里采用将离群得分现值与前60s离群点得分最大值进行比较的方法,得到离群系数L,即:
(6)
(4)不同管段不同工况对于离群系数L的下阈值均不同,需要通过大数据挖掘分析得到各自阈值,这样才能避免重复报警、错误报警,真正达到预警效果。
3 实例计算
现以湖南管道I站与J站间管段为例,进行不同工况下数据分析。IJ管段具体情况如下:I站为中间下载站, J站为末站,具体功能见表1。IJ管段长98.0 km,管径为273.1 mm×6.4/7.9 mm,具体的高程示意图见图2。由图2可知,IJ段地形起伏较大,在末站J站前有连续的高点,再根据I站和J站的功能,现对IJ管段进行4种情况分析,分别是:①正常单油品运行;②汽油顶柴油在管段中运行;③柴油顶汽油在管段中运行;④清管器在管段中运行。由于类似启输、停输、停下载等大范围工况调整系统都能做出判断报警,现主要针对平稳运行时小幅度压力波动所产生的持续性报警情况进行分析,故针对IJ管段情况选取以上4种工况。收集各工况运行数据并进行大数据挖掘分析,得到各种工况下阈值,降低报警系统的误报和重复低效报警,提高泄漏检测报警的准确性。

图2 IJ段管道高程示意图
3.1 正常单油品在IJ管段间运行
在正常单油品输送过程中,IJ管段压力波动很小。由于低压下载站切罐操作是模拟管道泄漏最佳工况,因此选择J站做切罐操作,对I站的出站压力进行分析。
利用SCADA系统获取实时压力数据,并对实时数据进行判别处理后按照公式(1)~(6)用MATLAB对相应的压力数据点进行聚类处理,得到压力数据的离群系数。单油品运行时I站出站压力和离群系数的变化见图3。从图3可以看出,当工况发生变化时,该算法成功给出预警(图3中有明显离群点),具有可靠性。

图3 单油品运行时I站出站压力和离群系数变化图
通过大量数据模拟得到离群系数概率图4。从图4可以看出:①若阈值设在1以下有大量的离群点需处理,会产生大量重复报警,需要消耗大量的精力去处理错误信息;②若阈值设在1.5~2.0之间有两个明显的离群点,可以有效起到预警作用,高效省时;③若阈值设在2.0以上则离群点可能会在边界区徘徊,系统不能做出明确判断,会漏掉报警信息,将产生严重的漏报情况。

图4 单油品运行时I站离群系数概率图
由此可看出此次阈值设在1.5~2.0之间最理想。但不同流速不同温度不同油品都会对阈值的设定产生影响,通过大量数据总结分析,最终将IJ段单输油品工况下的阈值设在1.65可以排除99.9 %以上的误报,从而真正实现有效预警。
3.2 汽油顶柴油在IJ管段间运行
IJ段地形起伏较大(见图2),汽油与柴油的理化特性相差很大,因此混油在过连续起伏的地形时会产生大量不间断报警,需要通过大数据分析选择汽油顶柴油在IJ管段间运行的合理阈值,排除重复无效报警干扰。
利用SCADA系统获取实时压力数据,并对实时数据进行判别处理后按照公式(1)(6)用MATLAB对相应的压力数据点进行聚类处理,得到压力数据的离群系数。汽油顶柴油运行时J站进站压力和离群系数的变化见图5。从图5可以看出,当混油过高点时,该算法成功给出预警(图5中有明显离群点),具有可靠性。

图5 汽油顶柴油运行时J站进站压力和离群系数变化图
通过大量数据模拟得到离群系数概率图6。从图6可以看出:①若阈值设在1.2以下有大量的离群点需处理,会产生大量重复报警,需要消耗大量的精力去处理错误信息;②若阈值设在2.5~5.5之间有一个明显的离群点,可以有效起到预警作用,但阈值范围过大还需要结合大数据最终给出合理值;③若阈值设在5.5以上则离群点可能会在边界区徘徊,系统不能做出明确判断,会漏掉报警信息,将产生严重的漏报情况。
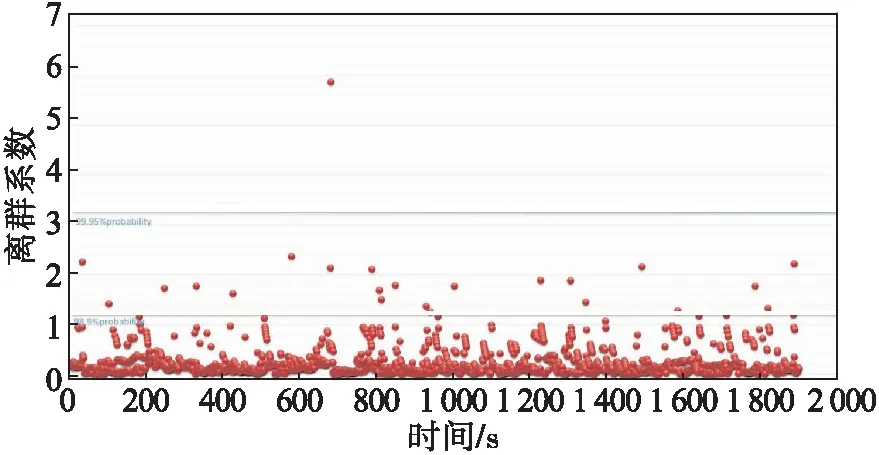
图6 汽油顶柴油运行时J站离群系数概率图
由此可看出此次阈值设在2.5~5.5之间最理想。但不同温度和不同流速都会对阈值的设定产生影响,通过大量数据总结分析,最终将汽油顶柴油在IJ管段运行工况下的阈值设在3.25可以排除99.95 %以上的误报,从而真正实现有效预警。
3.3 柴油顶汽油在IJ管段间运行
同理,混油在过连续起伏的地形时会产生大量不间断报警,需要通过大数据分析选择柴油顶汽油在IJ管段间运行的合理阈值,排除重复无效报警干扰。
利用SCADA系统获取实时压力数据,并对实时数据进行判别处理后按照公式(1)~(6)用MATLAB对相应的压力数据点进行聚类处理,得到压力数据的离群系数。柴油顶汽油运行时J站进站压力和离群系数的变化见图7。从图7可以看出,当混油过高点时,该算法成功给出预警(图7中有明显离群点),具有可靠性。

图7 柴油顶汽油运行时J站进站压力和离群系数变化图
通过大量数据模拟得到离群系数概率图8。从图8可以看出:①若阈值设在1.3以下有大量的离群点需处理,会产生大量重复报警,需要消耗大量的精力去处理错误信息;②若阈值设在2.0~3.5之间有一个明显的离群点,可以有效起到预警作用,但阈值范围较大还需要结合大数据最终给出合理值;③若阈值设在3.5以上则离群点可能会在边界区徘徊,系统不能做出明确判断,会漏掉报警信息,将产生严重的漏报情况。

图8 柴油顶汽油运行时J站离群系数概率图
由此可看出,此次阈值设在2.0~3.5之间最理想。但不同温度和不同流速都会对阈值的设定产生影响,通过大量数据总结分析,最终将柴油顶汽油在IJ管段运行工况下的阈值设在2.25可以排除99.95 %以上的误报,从而真正实现有效预警。
3.4 清管器在IJ管段间运行
每条管段都需要定期进行清管扫线。清管器在通过IJ段起伏地形时会产生大量报警,需要通过大数据分析选择清管器在IJ管段间运行的合理阈值,排除重复无效报警干扰。
利用SCADA系统获取实时压力数据,并对实时数据进行判别处理后按照公式(1)~(6)用MATLAB对相应的压力数据点进行聚类处理,得到压力数据的离群系数。清管器在IJ管段间运行时J站进站压力和离群系数的变化见图9。从图9可以看出,当清管器过高点时,该算法成功给出预警(图9中有明显离群点),具有可靠性。

图9 清管器在IJ管段间运行时J站进站压力和
通过大量数据模拟得到离群系数概率图10。从图10可以看出:①若阈值设在1.2以下有大量的离群点需处理,会产生大量重复报警,需要消耗大量的精力去处理错误信息;②若阈值设在3.0~8.0之间有一个明显的离群点,可以有效起到预警作用,但阈值范围过大还需要结合大数据最终给出合理值;③若阈值设在8.0以上则离群点可能会在边界区徘徊,系统不能做出明确判断,会漏掉报警信息,将产生严重的漏报情况。

图10 清管器在IJ管段间运行时J站离群系数概率图
由此可看出,此次阈值设在3.0~8.0之间最理想。但不同型号的清管器和不同流速都会对阈值的设定产生影响。通过大量数据总结分析,最终将清管器在IJ管段运行工况下的阈值设在4.55可以排除99.95 %以上的误报,从而真正实现有效预警。
4 结论
(1)基于聚类算法的离群点挖掘技术在管道泄漏检测报警系统中应用,检测范围更加精确,对压力的异常波动更加敏感,反应更加迅速,具有较强的使用价值。
(2)由于各管段管路特性不同,需要设立不同工况运行时的阈值,以提高报警的准确性。湖南管道IJ管段在正常单油品运行、汽油顶柴油在管段中运行、柴油顶汽油在管段中运行、清管器在管段中运行的工况下,设定的阀值分别为1.65,3.25,2.25,4.55。在设定的阈值下,系统可以排除99.9 %以上的低效重复报警和误报,真正实现了有效预警。
(3)基于聚类的离群点挖掘算法,可以对其他成品油管道在不同工况下的大数据进行处理。通过调整相应管道的阈值,可实现将该算法模型应用于不同管道。
