基于质心感知的自然场景文字检测技术
2022-04-25张高明
张高明
(上海电力大学电子与信息工程学院,上海 201306)
近年来,图像文字检测在自动驾驶、图像分割[2]、商品识别等领域被广泛应用,伴随着大数据的支持及深度学习的发展,自然场景文字检测引起了计算机视觉界的广泛关注。文字检测的任务是定位图像中的文字区域,印刷文档中的文字往往排列整齐、背景简单,文字与非文字区域存在明显差异。由于现实场景中图像中的文本大多排列样式多样,且具有形状不规则、背景干扰较大等特点,均使得在该场景中进行文字检测面临着巨大的挑战。
随着深度学习技术的兴起和不断发展,神经网络也开始应用于自然场景文字检测之中。若设计多个相关性较强的任务进行多任务学习[3],如TextSnake[4]、PSENet[5]等,在主任务确定的条件下,在网络结构中额外增加与主任务相关性较高的辅助任务,可显著提高模型效果。
为此,本文提出在自然场景文字检测网络中增加质心预测分支,与网络中文本分类分支结合,通过增大靠近文字实例中心处的分类概率值,减小远离中心处的分类概率值,提升模型性能。
1 自然场景文字检测网络
1.1 场景文字质心预测
经实验发现,即使用anchor free 方法可对多个不同尺寸特征图进行预测,但效果仍不如anchor based方法,主要原因是神经网络的分类任务只考虑当前位置属于文字的概率,许多远离目标质心位置处的文字分类概率较高,而受限于感受野的影响,距离文字中心较远位置处得到的回归结果往往准确度较低。因此若简单将分类结果高于阈值区域对应的回归结果保留,将可能导致在后续非极大值抑制过程中保留错误回归结果,丢弃正确回归结果,对模型准确率造成极大影响,如CTPN[6]、RRPN[7]等,因此,借鉴FCOS[8]的想法,本文在分类网络中增设文字质心预测,判断每个像素点属于文字区域质心的概率。像素点越靠近文字区域的质心,则对应位置处的值越接近1,相反则越接近0。
与FCOS 通过边框内每个位置与其对应xmin、xmax、ymin、ymax关系得到质心预测目标值不同,考虑到自然场景文字检测任务的对象往往具有多种形式(水平、倾斜、弯曲),直接使用矩形边框对中心的计算方法不能保证中心点始终在文字实例中心。为此,本文根据自然场景中的文字形式设置了新的质心预测目标值计算方法,如图1 所示。
给定文字区域内某像素坐标(xi,yi),分别计算其与该文字实例x轴最值(xmin,yi)、(xmax,yi)的距 离li、ri,和垂 直 方向 与上 下边 界(xi,) 、(xi,) 距离ti、bi,即可计算该位置质心得分wi,wi的计算方式如下:
wi的取值范围为0~1,与文本分类相似,表示每个像素点位于质心的概率。在测试阶段将分类与质心结果逐像素相乘,得到最终分类结果。
1.2 目标函数
模型输出包含分类与回归2 个部分。其中分类任务部分同时得到文本、非文本分类和质心、非质心分类2 个结果,考虑到样本中正例远小于负例,为应对类别不均衡的分类问题,2 个分类任务均采用Focal Loss[9]作为损失函数,定义如下:
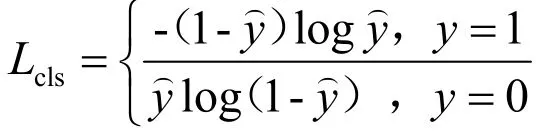
回归任务部分采用ⅠOU 损失作为损失函数,如图2 所示,ⅠOU 损失定义如下:
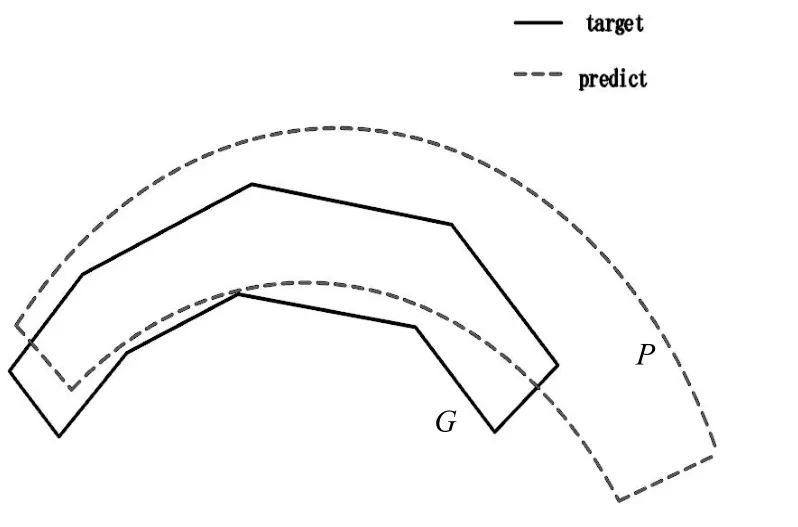
图2 ⅠOU 损失计算示意图
式(1)中:Gi为实际文本位置;Pi为预测的文本位置。
因此,模型总的损失函数为L=Lcls1+Lcls2+Lreg。
1.3 评估指标
本文采用自然场景文字检测问题中常用指标(精确率、召回率、F-score)对方法的有效性进行评估。
精确率表示预测为文字的区域内实际为文字区域的比例,召回率表示实际为文字的区域同时也被预测为文字区域的比例,公式如下:
式(2)(3)中:Gi为实际为文字的区域;Di为预测为文字的区域。
根据精确率与召回率反映检测模型的综合性能,F-score 的定义如下:
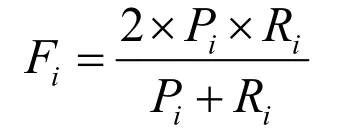
2 实验结果分析
为验证本文提出的质心预测分支网络有效性,分别训练无质心预测分支和包含质心预测分支的网络,进行消融实验。使用SynthText 对网络进行预训练,然后在TotalText 数据集中进行相同轮数的微调和推理,比较不同网络效果。实验使用的编程环境为Python3.6.4 和Pytorch 1.1.0,在Ubuntu16.04 操作系统中利用一张显存为12 GB 的GTX TⅠTAN X 显卡进行模型训练和测试,CUDA 版本为11.0。
通过随机旋转(旋转范围为[-5°,+5°])、抖动(对图像加入轻微噪声)、翻转(50%概率对图像左右翻转)对图像进行数据增强,并将图像分辨率修改为512×512。将常用的ResNet50-FPN 作为基础网络,设置batch 数量为12,每个文字实例的长边使用K=10个插值进行表示,并采用带动量的随机梯度下降为优化器,动量为0.9。首先设置学习率为0.000 1,使用人工合成数据集SynthText 对网络进行80 万次预训练,再将学习率修改为0.001,分别在TotalText 数据集中进行微调和测试[10]。测试结果如表1 所示。

表1 TotalText 数据集结果对比
本文方法在TotalText 数据集上进行测试,在其他条件保持一致的情况下,比较神经网络包含和不包含质心预测分支时的效果情况。由表1 可知,网络模型中增添质心预测分支后,模型效果得到了显著提升,其中精确率的提升尤其明显。
3 结论
本文提出一种质心检测网络分支,用于在自然场景文字检测场景中提升模型效果。在FCOS 的质心计算基础上,修改质心的计算方法,使其更适用于自然场景文字检测问题,提高了模型的准确度。经过数据对比,本文提出的方法在TotalText 等包含任意形状文字实例的数据集中均取得了较好的实验效果,验证了方法的可行性和有效性。
