蚁群算法在网络舆情中的信息传播路径预测研究*
2022-04-24张俊豪铁道警察学院
张俊豪 铁道警察学院
引言
本文以社交网络为例,在蚁群算法的基础上,研究分析用户行为,找出消息从源头流转到特定人群的最优传播路径,以期为公安舆情管控提供技术支持。
社交网络是由用户及用户关系组成的,消息通过用户之间的关系实现流转,实际的交通网络是由实体及实体之间的道路组成的,车辆通过实体之间的道路实现运转。两者的拓扑结构较为相似,比如消息类似于车辆,用户关系类似于道路,因此研究预测舆情消息传播的最优路径可以借鉴实际生活中的道路寻优算法蚁群算法[1]。但是社交网络不同于实际的交通网络,应进行实际的改进,加以应用,找出消息的最佳传播路径。
一、蚁群算法简介
蚁群算法是基于蚁群觅食行为的路径寻优算法,该算法是一种启发式的全局优化算法。在蚁群算法中,蚂蚁之间通过信息素分享经验,而且蚂蚁会根据一定的概率pk(i,j)选择下一条路径,并在此路径上释放信息素[2]。pk(i,j)的确定是整个算法的核心,pk(i,j)的计算如式(1)所示:

式(1)中,τ(i,j)表示路径(i,j)上的信息素浓度,其更新机制主要对应三种模型:蚁密系统、蚁周系统和蚁量系统,η(i,j)表示第k只蚂蚁的启发式函数,其确定一般和路径的长度有关。α为信息素的相对重要程度,β为启发式因子的相对重要程度,allowedk表示蚂蚁下一步可以前往的节点集合。
二、基于用户行为及蚁群算法的最优路径选择
在道路交通网络中,使用蚁群算法需要考虑到影响道路交通的诸多因素,比如道路交通事故、交通信号灯等,以此进行更新信息素分配机制以及启发式函数[3]。在社交网络中,使用蚁群算法应根据用户行为以及用户之间的关系进行更新信息素分配机制以及启发式函数。
(一)改进信息素初始浓度分配机制
在蚁群算法中,每一条路径上的初始信息素浓度是一样的,主要是为了蚁群在初始能够以均等的概率搜索每一条路径,但是在社交网络中,消息的传播具有“被动性”,即消息的传播是由用户选择的,而不是由消息决定的,这一点不同于蚁群觅食的“主动性”,用户选择消息一般情况下会受用户之间的背景影响,比如工作性质相似的人群、具有相同教育背景的人群更容易转发内容相似的消息。所以改变蚁群算法的信息素初始浓度分配机制,既能够提升计算效率,而且避免算法陷入局部最优。
本算法在进行信息素的初始浓度分配时主要考虑网络用户的背景相似度[4]。本文将提取出6个属性衡量用户的个人基本信息:性别、年龄、地理位置、职业(可通过工作信息获取)、标签(包含百度人物介绍、简介等信息),个人主页微博内容,即PI(u)={sex(u),age(u),location(u),work(u),tag(u),blog(u)}。部分信息如图1所示。

对于微博用户u和v,可通过一个向量A(u)和A(v)进行表示个人的基本信息,向量的取值过程为:若为同性,sex(u)=1,sex(v)=1,否则sex(u)=1,sex(v)=0,若无信息,默认值为sex(u)=1,sex(v)=0;若年龄相差不到5岁,则age(u)=1,age(v)=1,否则age(u)=1,age(v)=0,若无信息,默认值为age(u)=1,age(v)=0;若地区相同,则location(u)=1,location(v)=1,否则location(u)=1,location(v)=0,若无信息,默认值为location(u)=1,location(v)=0;若职业相同,则work(u)=1,work(v)=1,否则work(u)=1,work(v)=0,若无信息,默认值为work(u)=1,work(v)=0。由于标签信息以及个人主页微博内容不可能相同,而且涉及大量的文本信息,所以不能通过简单的赋值计算,在这里用余弦相似度获取标签信息的相似度Tag-Similarity(u,v),其中Tag(u)=1,Tag(v)=Tag-Similarity(u,v),若无信息,默认取值为Tag(u)=1,Tag(v)=0;个人主页微博内容的取值可参考标签信息。
对用户基本信息的向量赋值后,采用余弦相似度Similarity(u,v)评估用户之间的相似度,即用户之间的个人基本信息相似性,计算如式(2)所示:

根据用户的相似度,信息素的初始分配机制可如式(3)所示:

式(3)中,τuv(0)表示在初始时刻用户关系(u,v)的信息素浓度。M表示消息在每次传播时的初始信息素浓度,为一常数,k为调和参数。在上式中,用户的背景相似度能够衡量社交网络的初始人物关系,该值越大,则该传播路径上的初始信息素浓度就越大。
(二)改进启发式函数
在蚁群算法中,启发式函数是由蚁群的搜索路径长度决定,但未从道路交通网络全局出发,容易陷入局部最优的情况。在社交网络中,用户之间的关系并不能由长度决定,而是由用户之间的行为关系决定的,用户之间的互动越频繁,消息被传播的概率就越大。因此,可根据用户之间的行为关系量化用户之间的关系距离,再从全局的角度出发,综合考量启发式函数。
用户之间的关系距离需要用户之间的交互信息去量化,因用户之间的交互信息主要包含评论、转发、提及,所以本文采用传统加权融合的方式求得用户之间的交互量IV(Interactive Volume),如式(4)所示:

式(4)中,IV(v,u)表示用户v对用户U的交互量,R(v,u) 表示用户v转发用户U微博的数量,M(v,u)表示用户v评论用户U微博的数量,@(v,u)表示用户v提及用户U微博的数量,α,β,γ表示相应因素的权值,很显然,用户之间的交互量具有有向性。
得到用户的交互量后,以duv=p*IV-1(v,u)表示用户v对u的关系距离,即该值越小,用户之间的关系就越近,反之,就越远,其中p表示调和参数。
设u表示当前消息的位置,v表示消息的下一传播目标,s表示消息的最终受众位置,Dvs表示采用Dijkstra得到的节点u到终点s的最短路径[5]。故启发式函数η(u,v)如式(5)计算所得:
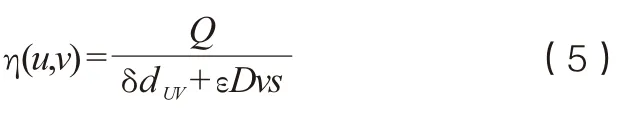
式(5)中,Q表示第K只蚂蚁在本次遍历中所产生的信息素常量,δ和ε为相应的权值。此时,启发式函数既能够根据局部关系duv考 虑局部的用户关系强度,又可以根据Dvs考虑下一选择位置v在全局网络中的位置信息,这样在选择下一传播对象时能够从全局和局部的双重角度衡量路径的优良程度,避免陷入局部最优的状况。
(三)改进信息素更新机制
信息素的更新机制直接决定了蚁群算法的性能,传统的信息素更新机制主要有上一节提到的三种模型,但是这三种模型并不适用于社交网络的路径寻优问题,而且这三种模型都未从全局和局部的双重角度更新信息素,所以本文以动力学为依据,从全局和局部的双重角度改进信息素更新机制。
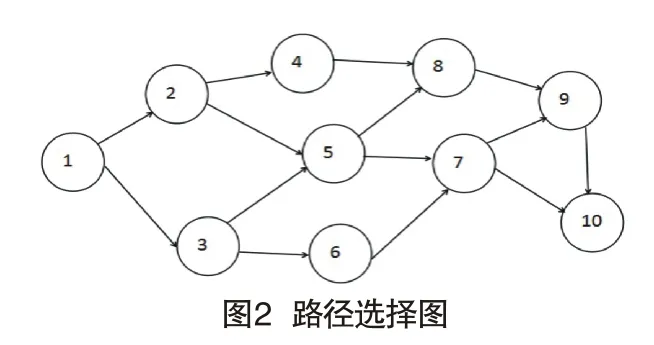
在网络舆情中,决定消息传播范围的主要用户行为就是转发、评论和收藏[6],决定舆情发展的关键人物往往是利益的相关人,即在某一舆论中,消息的局部传播路径一般情况下会相对稳定,如图2(某一微博社交圈)所示。
在图2中,假设用户1为消息源,如果消息从1传到用户10,用户2转发用户1的消息越多,那么在舆情中,消息的传播路径就会稳定在1→2这条路径上,即越关注越转发。本文加入时间因子,信息素局部更新函数如式(6)所示:

如果仅仅通过局部信息素更新机制,算法往往容易陷入局部最优的状态,比如根据上面的信息素更新机制选定了一条路径1→2→5→7→10,在该路径上,由于用户2和用户1的背景较为相似,用户2在单位时间内转发用户1的信息量也较大,那么1→2这个局部路径就会越多的被选择,但是在实际的消息传播过程中,有可能出现其他情况,比如用户5和用户4在单位时间内转发(评论)用户2的信息较少,那么信息从用户1到用户2之后,消息的传播基本上就处于停滞状态了,这时根据局部的信息素更新机制,算法达不到全局最优。因此设Lk表示第k条信息本次遍历完所走的所有路径和。全局信息素更新如式(7)所示:

借鉴最优最差蚁群算法,本算法的信息素更新如式(8)所示:

当路径(i,j)属于最优路径p*时,采用对其进行奖励,反之采用对其进行惩罚。比如在图2中,如果1→2路径被大量选择后,但是在用户2之后,没有消息被传播,相反,用户1→3在初始状态传播信息量有限,但是用户5和用户6却会大量的转发用户3的信息,那么最优路径1→3→6→7→10可能就被发现选择,这样本算法不仅从全局的角度更新了信息素,也从局部的角度更新了信息素,避免算法陷入局部最优,同时也增加算法的执行效率。
(四)路径评价函数
在对道路的寻优路径进行评价时,没有严格意义的标准,但是在对消息的传播路径进行评价时,考虑的因素较少,主要有在单位时间内用户B接受用户A的信息量,以及用户A到用户B的路径实际长度两个因素,前一个因素主要衡量的是信息的传播质量以及传播速度,后一个因素主要考虑的是信息传播的稳定性。故引入式(9)作为路径的评价函数:

在式(9)中,S表示用户B接受用户A的信息量,S/t表示在单位时间内用户B接受用户A的信息量,d表示用户A到用户B的关系距离,f(d,t)则表示任意两个节点之间在单位时间内传播的信息量,即衡量整个路径在传播信息时的效率,该值越大,路径越优。
(五)改进信息素挥发机制
在蚁群算法中,蚂蚁所产生的信息素会挥发,在实际的社交网络中,消息传播所遗留的信息素同样也会“挥发”,本文根据单位时间内消息经过该路径的信息量T衡量信息挥发因子ρ,如式(10)所示。

三、实验及结果分析
本算法根据图2模拟社交网络进行仿真实验,实验以经典的蚁群算法和Dijkstra算法为对比模型,验证本算法的有效性。根据层次分析法以及传统的蚁群算法要求,本算法的主要参数详见表1。

?
根据微博网络中实际发生的网络舆情情况,以图2的微博社交圈进行模拟仿真,在该图中,每个节点代表的可能是一个网民,也有可能代表的是较小的一个社交圈,部分用户具有相似的工作背景,舆情周期设定为半个月,微博数据为8000条。
本实验根据微博数据测试集的不同,设置三组对比实验,以此进行对比分析。三组实验中,测试集分别设置为总微博数据的60%、70%、80%。出发节点为1,接收节点为10。
第一组实验:设置测试微博数据为4800条,验证微博数据为3200条,根据用户行为及蚁群算法得到的最优路径为1→3→5→7→9→10;根据经典蚁群算法得到的最优路径为1→3→6→7→10;根据Dijkstra算法得到的最优路径为1→3→5→7→10。
三种算法得到最优路径长度以及f(d,t)结果详见表2。

?
根据测试集中每条微博的转发路径,三种算法得到准确率详见表3。

?
第二组实验:设置测试微博数据为5600条,验证微博数据为2400条,根据用户行为及蚁群算法得到的最优路径为1→2→5→7→9→10;根据经典蚁群算法得到的最优路径为1→3→6→7→10,没有产生变化;基于Dijkstra算法的最优路径选择结果也不变,最优路径仍为1→3→5→7→10。
三种算法得到最优路径长度以及f(d,t)结果详见表4。

?
根据测试集中每条微博的转发路径,三种算法得到准确率如表5所示。

?
第三组实验:设置测试微博数据为6400条,验证微博数据为1600条,根据用户行为以及蚁群算法得到的最优路径为1→2→5→7→9→10没有产生变化;根据经典蚁群算法得到的最优路径为1→3→6→7→9→10;基于Dijkstra算法的最优路径选择结果不变,最优路径仍为1→3→5→7→10。
三种算法得到最优路径长度以及f(d,t)结果详见表6。

?
根据测试集中每条微博的转发路径,三种算法得到准确

?
对三组实验结果进行横向比较,随着测试集的增加,基于用户行为及蚁群算法的最优路径选择算法趋于稳定,单位时间内传播的信息量都有所增加,算法的准确性也在逐步增加。对于蚁群算法而言,路径随着测试集的增加,路径会产生相应的变化,单位时间内传播的信息量在测试集增加到6400条时反倒有所下降,算法准确率随之也下降。对于Dijkstra 算法而言,随着测试集的增加,虽然路径没有产生变化,但是单位时间内传播的信息量和算法的准确率都在下降。
对三组实验进行纵向比较,在每组实验中,基于用户行为及蚁群算法的最优路径选择算法在单位时间内传播的信息量和算法的准确性都要高于其他两种算法,而且随着测试集的增加,这种对比结果更加明显。
在第一组实验中,基于用户行为及蚁群算法的最优路径选择算法的路径长度是要多于其他两种算法的,这主要是因为本算法会充分地考虑用户之间的行为关系,改进了信息素的更新机制以及概率选择函数的缘故,并不以路径长度作为唯一的追求目标。另外本算法的收敛速度要明显优于经典的蚁群算法,这主要是因为改变了信息素的初始分配机制以及信息素的全局更新机制。
四、结语
基于用户行为及蚁群算法的最优路径选择算法充分衡量了用户行为以及用户关系的特点,能够从全局和局部的双重角度更新信息素以及概率选择函数,明显的提升了蚁群算法的收敛速度,进而得到消息的最优传播路径,借此,可以为公安机关准确预测网络舆情中的信息传播路径以及判断舆情发展态势提供技术支持。
