基于K-modes聚类分组的大数据相似重复记录检测研究
2022-04-19张平,余顺
张 平,余 顺
(安徽职业技术学院 信息工程学院,安徽 合肥 230011)
随着大数据时代的到来,大型企业数据日积月累,数据量庞大,如何从大数据中找出有价值的信息是当前企业关注的热点。大型企业存储了大量的数据,但是数据质量令人堪忧,集中表现在数据相似重复、冗余、错误、歧义等问题,多个数据源的合并加重数据的冗余。在大数据环境下,数据的来源、数据量和维度不断增加,使得数据质量更加糟糕,数据质量不断下降,数据挖掘出有用的价值的信息就越困难。因此,如何解决对同一条数据因描述标准不统一而导致的数据冗余问题,即相似重复记录检测问题,逐渐成为数据预处理的核心问题。
针对相似重复记录检测,国内外学者提出了很多的检测方法:东北石油大学的袁满等人改进了经典的近邻排序(SNM)算法,该算法先找出关键属性进行排序,然后通过滑动窗口对相近邻的记录逐个比较找出相似记录[1];复旦大学的周傲英教授等人提出了以N-Gram值作为排序关键字对记录排序,然后把N-Gram值映射成空间的点来聚类相似重复的记录[2];东南大学的韩京宇等人提出了一种分层次聚类的算法来检测相似重复数据,该方法采用将数据映射成空间的度量点之间的相似度来找出相似数据[3];暨南大学的朱蔚恒教授提出的通过构建R-树,减少R-树中叶子比较次数进行降维来检测相似重复记录[4]。文献中阐述的方法大多用到排序和比较的方法进行相似记录比较,在时效上比较慢,应用于大数据集的时候,排序和比较的时间复杂度将会很高,本文为了在保证检测精度不变的情况下降低时间复杂度提出了基于K-mod es聚类分组检测算法。
1 相似重复记录
当今是一个数据爆炸的时代,数据质量问题已经引起企业的重视。多源数据的合并导致业务系统中有很多冗余和不合要求的数据,这些数据主要包括重复记录、错误的数据、不完整的数据、歧义的数据等。数据清洗就是从海量数据中找出这些冗余和不合要求的数据的过程,其中相似重复记录的检测尤其重要,它是整个数据清洗的关键环节[5]。
数据表中一条数据一般由若干个字段组成,如果数据库中存在两条记录,他们除了主键不同以外其他字段都相同,我们称为完全重复记录。如果两条记录是同一个对象实体,除了主键不同,而其他字段在表述或者格式上不同的两条记录称为相似重复记录,如表1所示:
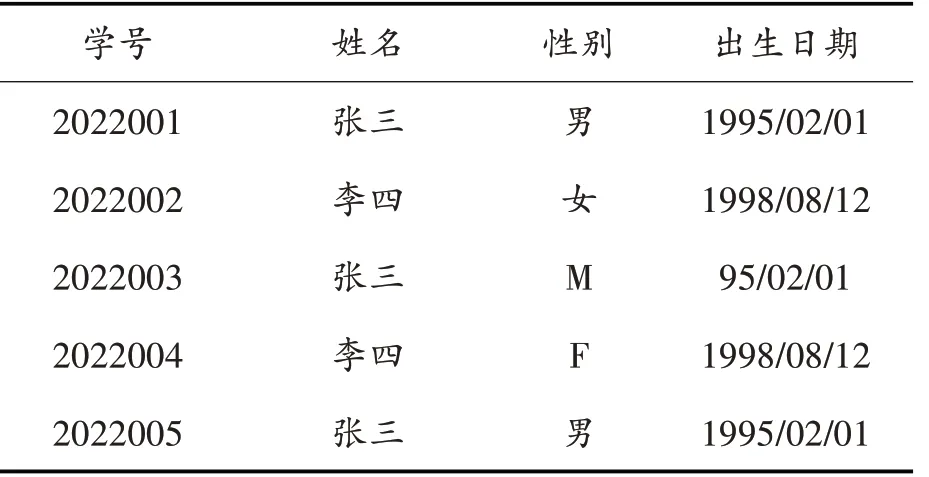
表1 学生信息表中的重复数据
表1为在校学生的四条记录存在两种重复类型,其中,学号2022001和2022005的两条记录除了学号不相同,其他字段值均完全相同,可以判定这两条记录即为完全重复记录。而学号2022001和2022003的两条记录、学号2022002和2022004的两条记录除了主键不同以外,性别字段值、出生日期字段的值以及院系字段的值都是表述不一样的,如性别属性的值“男”和“Male”的缩写“M”本质一个意思,也可以判定这两条记录是同一条记录,这样的两条数据即为相似重复记录。
2 相似重复记录检测
2.1 编辑距离与相似度
字段间的相似度是通过编辑距离转换得到的。编辑距离的计算方法有欧式距离、曼哈顿距离、马式距离等衡量方法,本文采用经典的欧式距离度量字段间的编辑距离。假设m维数据看作m维度向量xi(xi1,xi2,…,xim)和xj(xj1,xj2,…,xjm),则欧几里得几何距离可定义为:
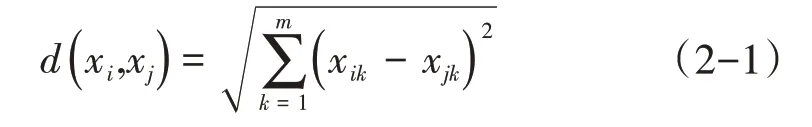
通过公式可以计算出字段间的编辑距离,根据编辑距离的计算结果构造编辑距离和相似度之间转换关系表,例如当编辑距离为1时,可以转换相似度为0.9,当编辑距离为2时,可以转换成相似度为0.8,以此类推,可以计算得到所有字段间的相似度。
记录相似度是通过字段相似度累加求和得到的,两条记录的相似度检测是通过字段相似度累加求和的结果。往往为了提高检测精度,可以给根据每个字段的重要性设置权重w,通过权重来衡量字段的重要性,这样可以提高相似记录检测的精度。
假设有m维的两条记录X和Y,它们对应于属性Ri的字段值分别为x和y,则字段间相似度为SRi(x,y),则记录的相似度为:
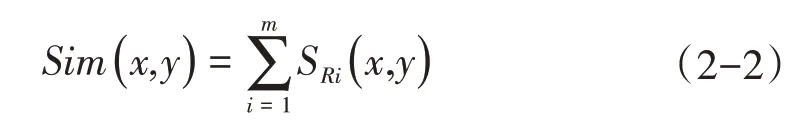
为了更加准确的评价一条记录相似度时经常会对重要的属性增加一个权重系数w,通过赋予不同字段不同数值的权重以突出该字段的重要性,这样就能够比较全面的评价字段间的相似度,从而提高检测精度,其中权重之和为1,则加权的记录相似度为:
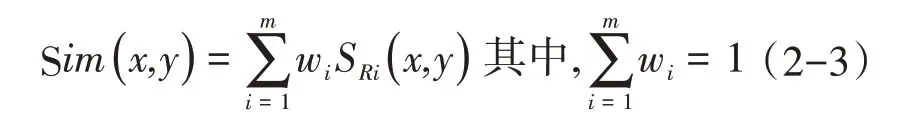
2.2 相似重复记录检测过程
相似重复记录检测的方法主要是先进行全局的数据排序,先选出关键字段以关键字段进行排序,这样同一关键字段的数据就会聚集在一起,然后通过定义字段间相似度进行逐个字段加权累加得到记录的相似度,设定相似度的阈值,对所有记录进行轮询比较,若接近阈值的归为相似记录。重复记录检测的步骤如图1所示:
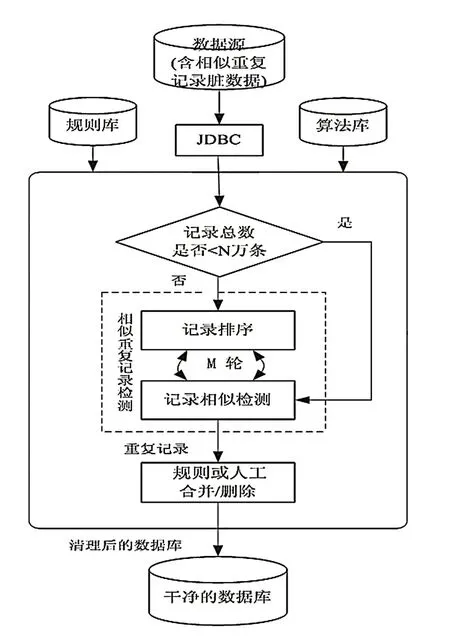
图1 相似重复记录检测过程
3 基于网格密度的K-modes聚类分组检测
本文对传统算法对大数据处理的局限性提出了一种“化大为小分而治之”的K-modes聚类分组检测算法(KCG)。首先通过网格密度来改进K-mod es聚类算法效果,对大数据进行有效的相似聚类分组,然后再各分组中采用高效的Pair-wise比较算法[6]检测出组内所有相似重复记录检测。
3.1 K-mod es聚类
K-mod es算法是对K-means算法的扩展,该算法采用相异度来表示记录之间的相关程度,在每个分类簇中选择属性值出现频率最多的属性值来更新modes[6,7]。
定义1(记录间相异度)假设两个记录xi和xj的距离为:
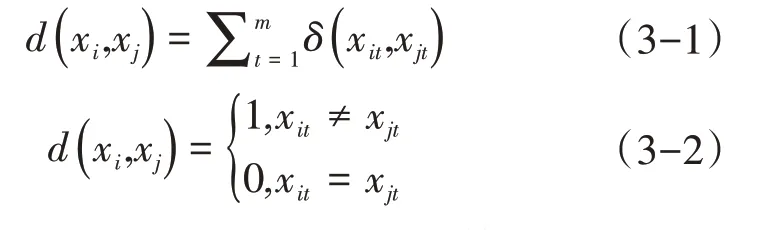
算法1:基于K-mod es聚类分组算法
Input:数据集D(n个数据点,m个维度),k个初始聚类个数
Output:k个相似重复记录的聚类簇
(1)随机的选取k个不同数据对象作为初始聚类中心;
(2)计算数据集中所有对象到k个聚类中心的相异度,将然后将每个对象分配到与其相异度最小的聚类中心所在的簇中;
(3)在得到的k个簇中,根据提出的簇中心点的更新方式选出新的中心点,迭代直到簇中心不发生变化,聚类过程结束,得到k个的相似的聚类簇。
3.2 基于网格密度的K-mod es聚类
经典的K-modes聚类算法在通常采用随机选取初始聚类中心点,这种选取中心点的方法会对聚类结果有较大影响,会导致初始中心敏感的问题[8]。针对这一问题,本文采用基于网格密度的方法来改善初始聚类中心的选择,解决初始中心敏感问题。该方法思路是增大初始簇中心之间的距离,增加了聚类间的差异性,从而得到较为满意的聚类结果。
定义2(网格密度阈值MinS):假设Oi和Oj分别为网格空间的两个数据点,x为最小网格单元里的点个数,则网格密度阈值MinS的计算公式定义如下:
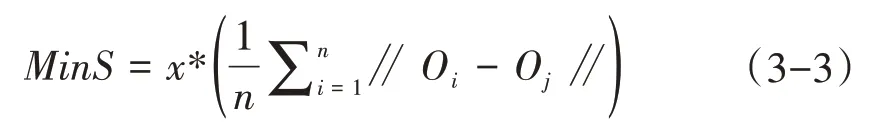
3.3 基于网格密度K-modes聚类分组的相似重复记录检测
相似重复记录检测是通过比较记录各字段值的相似度检测出重复记录的过程,而聚类算法是将数据之间的相似度对数据进行分类的过程,数据被划分为若干个簇,簇内的所有数据具有相同或接近的相似度,而簇与簇之间是相异的,所以可以运用聚类的思想先从大数据集中找出相似重复记录的簇,再在各个簇中进行相似检测,这样就能够很好解决大数据环境下的检测效率和精度。
本文基于这个思想提出了一种改进初始聚类中心K-mod es聚类算法先对大数据进行有效的分组,然后在分组中采用经典的Pair-wise算法检测出所有相似重复记录检测,算法的步骤如下图2所示:
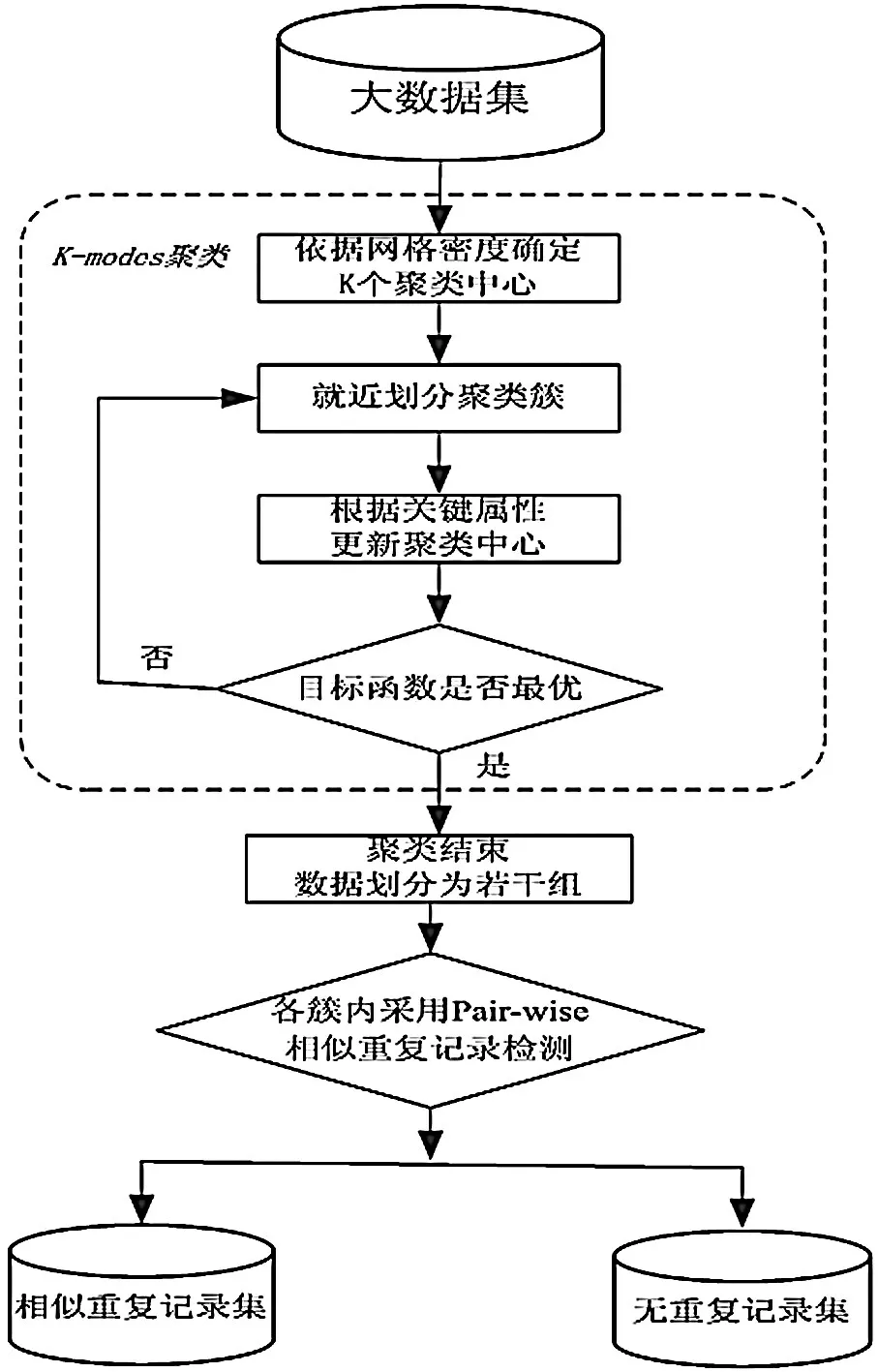
图2 KCG相似重复记录检测步骤
算法2:KCG相似重复记录检测
Input:大数据集D(n个数据点,m个维度),k个聚类数

其中:δ为相似度阈值,是由相关领域专家处取得,用来判定两条记录是否是相似重复记录。记录的相似度为对应字段的相似度之和,如果两条记录的相似度大于2δ,则判定两条记录不是相似重复记录。
4 实验分析
4.1 评价标准
相似重复记录检测的评价标准主要有3个指标:准确率P(Precision)、查全率R(Recall)和时间效率T(Time)[9]。准确率P是正确识别出来的重复记录占识别出作为重复记录的比例;查全率R是正确识别出来的重复记录占数据集中实际的重复记录比率。查全率R,查准率P可以用公式(4-1)和(4-2)表示:
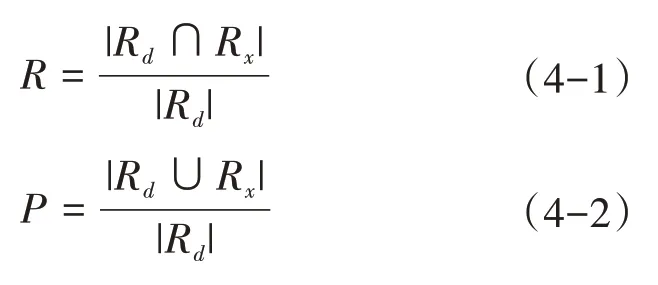
其中,Rd代表原数据集实际的重复记录集合,Rx代表识别出来的重复记录集合。
4.2 实验数据
本文采用开源Febrl数据集的数据,并使用生成器工具模拟产生本实验所需的数据。Febrl数据集中每条记录包含了18个字段信息:人的姓名、年龄、国籍、住址、电话等。本文对该数据集使用前进行了适当的处理,采用生成器工具分别生成了10、20、30、40和50万条数据集用于相似重复检测实验对比。数据集中的数据由两部分组成,50%为原始数据,50%根据原始数据模拟出的相似重复记录。
4.3 实验环境
服务器选用酷睿i9 CPU,物理内存256GB,硬盘空间4T,操作系统Windows 10,数据库为Mysql,程序采用Python语言编写。
4.4 实验结果分析
为了验证方法的有效性和正确性,我们将该文所提出的聚类分组相似记录检测算法与经典的SNM算法从检测精度和运行时间两个方面进行了对比实验。
4.4.1 查准率对比
从图3中可见,当数据量较少时聚类分组方法检测精度低于SNM方法,这是因为数据量较少时,分组时组间区分不明显,产生交叉的重复数据故而导致检测精度低。但随着数据量不断的增大,聚类分组的方法在检测精度上明显优于SNM方法。
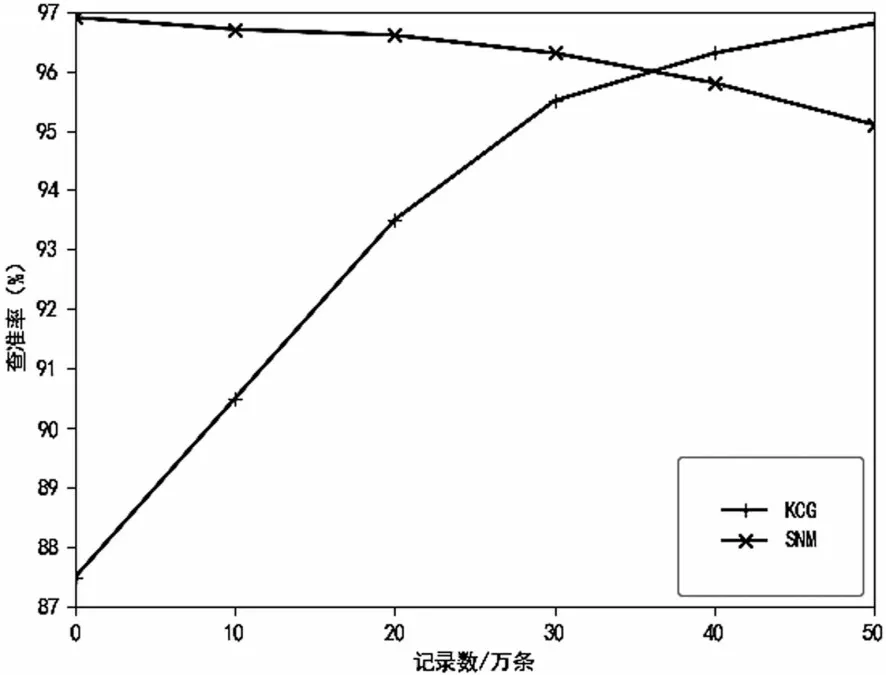
图3 查准率比较
4.4.2 运行时间对比
从图4可见,两种方法在10、20、30、40和50万条数据集下的运行时间,开始时聚类算法因为分组需要花费计算时间,时间较长,随着数据量的增加,聚类分组体现出其处理大数据的优势,运行时间明显比SNM算法更少,而且是数据量越大越明显。
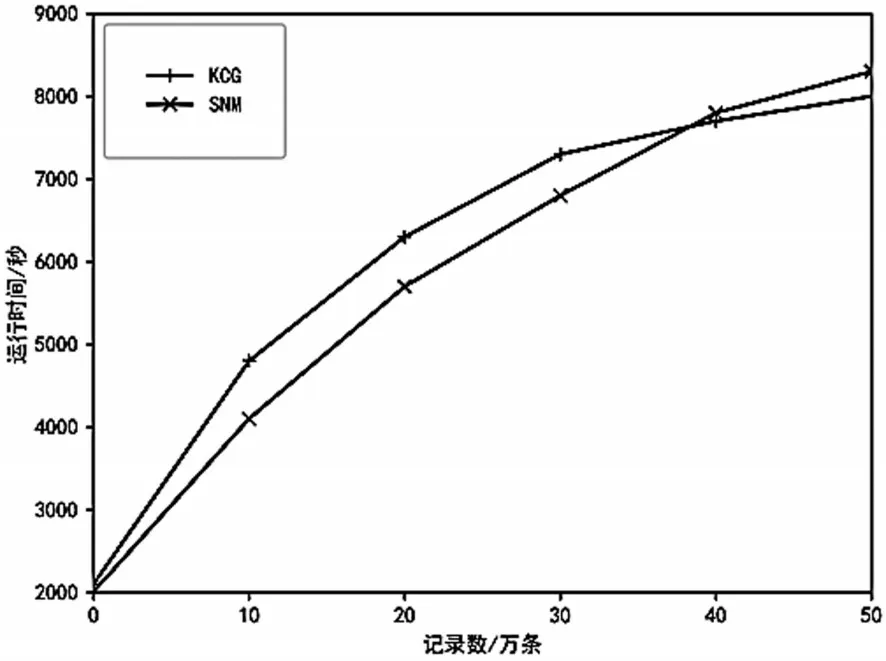
图4 运行时间比较
5 结语
本文针对大数据环境下不能有效的检测相似重复记录的问题,提出了一种聚类分组的KCG算法来检测大数据集中的相似重复记录。该算法通过网格划分方法解决初始中心点的敏感问题,能够有效的进行相似重复记录聚类分组,然后在分组的基础上再分组的小范围使用Pair-wise高效检测算法进行组内相似记录检测,在保证精度不降低的情况下提升了检测的效率。通过实验对比分析显示,该方法的运行效率和检测精度都高于直接检测的算法,有效地解决了大数据量的相似重复记录检测问题。由于采用聚类算法的分组会导致相似重复分组数据交叉使得检测的精度没有较明显的提高,接下来的工作就是要解决如何进一步提高检测精度的问题对算法改进。
