基于三相表特征约束聚类的低压台区用户相序识别方法
2022-04-18蔡永智李其霖刘斯亮张勇军羿应棋黄向敏
唐 捷,蔡永智,李其霖,刘斯亮,张勇军,羿应棋,黄向敏
(1. 广东电网有限责任公司,广东省 广州市 510060;2. 广东电网有限责任公司计量中心,广东省 广州市 510080;3. 智慧能源工程技术研究中心,华南理工大学电力学院,广东省 广州市 510641)
0 引言
低压配电台区作为直面用户供电的最后环节,其运维管理的智能化、精益化水平将直接影响客户用电满意度[1-2]。由于低压台区面广、量大、变动多,供电企业难以准确掌握低压用户的供电相序信息,导致台区线损异常、三相不平衡、低电压等运维管理问题难以有效解决[3-5],成为客户投诉的焦点。因此,开展低压用户相序识别方法研究具有重要的工程意义和社会价值[6-7]。
针对此问题的解决方法主要包括人工排查法、信号辨识法与数据挖掘法。其中,人工排查法是指依靠电力员工现场使用相关识别设备进行勘察,是目前电网公司获取低压用户相序信息的主要方法,但其效率低下,且需要消耗大量的人力物力,经济效益极低。信号辨识法通过注入脉冲电流或载波电压信号,根据信号的收发情况辨识用户供电相序[8-10]。其原理简单、识别准确,但需要额外加装监测终端或模块,投资高、运维压力大,且信号发生电路可靠性差,在雷击、浪涌环境下易损坏。
随着高级量测体系逐渐建成与完善,智能电表多类型、高频次、准同步数据得以自动采集获取[11]。由于电表电气量是台区潮流分布的关键状态量,具备反映台区网络拓扑关系的特征。为此,大量学者开展数据挖掘法研究,主要可分为关联分析法、模型拟合法和特征学习法三大类。
关联分析法利用同相用户电压时序变化具有相关性的机理特征,通过设置相关系数阈值判据,实现台区相序关系自动识别。文献[12-13]通过比较电表与配电变压器电压时序的相关性,确定用户相序关系。一般来说,关联分析法依赖相关系数阈值设置,在不同台区应用时适应性较弱。
模型拟合法通过最小化实际量测值与系统状态误差,拟合用户相序关系。文献[14-15]通过最小化台区各相总功率及其下属电表功率总和的偏差值,拟合各电表的相序归属关系。但是,除了线损外,实际台区中还存在窃漏电等情况,导致台区首末端功率偏差较大,将显著影响识别准确率。
特征学习法从数据本身出发,通过挖掘台区运行数据与其拓扑结构的内在关系,实现用户相序关系自动识别,其主要包括监督学习与无监督学习算法。其中,以聚类为典型代表的无监督学习算法不依赖正确的数据标签,实用性强,近年来被广泛应用到相序识别问题中。文献[16]提出了以皮尔逊相关系数、L1/L2范数为相似性量度指标的K-means 聚类算法对用户电压曲线进行分类,进而实现用户相序识别。文献[17]提出了一种带约束的K-means 聚类算法进行用户相序识别。
在相序识别问题中,尽管三相表在数据采集过程中已标定了相序,但由于接线不规范等问题广泛存在标定相序与真实相序不一致情况。若在相序识别过程中忽略三相表,将影响单相表相序识别的准确率,进而影响线损精益化管理、三相不平衡或低电压等问题的精确治理。此外,当三相表位于配变分支出线首端时,由于其与配变母线电气距离较近,在母线三相电压不平衡度较小的情况下将导致三相表的三相电压变化具有较高相似性,直接采用基于相似性量度的聚类方法会将其识别为同相电表,进而影响识别准确率。
针对当前相序识别研究中较少考虑三相表的问题,本文提出了基于三相表特征约束聚类的低压台区用户相序识别方法。首先,理论推导了用户电压的时序变化特性与关联机理,为后续相序识别分析提供先验知识;然后,对用户电压时序进行特征标准化与降维处理,提出基于背景知识的嵌有快速收敛机制且考虑三相表特征约束的K-Medoids 半监督聚类算法(CFK-Medoids)开展台区相序识别。最后,通过实际数据计算分析,验证了所提方法的有效性与适用性。
1 用户电压时序特性及其与相序关联分析
本章通过推导低压台区节点电压的计算公式,从理论上分析用户电压的时序特性。为了更好地掌握用户电压的时序特性,本文根据实际情况,在理论推导过程中进行了相关简化,包括:1)用户下户线一般较短,忽略其电压损耗;2)台区无功负荷较低,忽略电压降落中的无功分量。图1 给出了低压台区某一相线示意图。

图1 低压台区某一相线示意图Fig.1 Schematic diagram of a certain phase line in lowvoltage distribution-station area


通过分析式(1)和式(2)可知,可总结用户电压时序特性及其与相序关联关系:电表电压受所在相配电变压器低压母线电压、所在相线上游各支路传输功率总和以及上游各支路阻抗共同影响。对于同相电表而言,其电压差异主要受后两者影响。当2 个同相电表处于同一出线,且两者间的距离短、阻抗小、传送功率较低时(即电气距离较近),两者电压变化具有相似性。但随着两者电气距离逐渐增大,其电压变化相似性逐渐减弱。而对于异相电表而言,其电压差异还受台区三相电压不平衡度影响,则异相电表电压变化相似性明显较低。基于上述分析,可总结以下先验知识,为后续相序识别提供支撑。
先验知识1:同相且电气距离相近的电表电压变化相似性高,同相且电气距离较远或异相电表电压变化相似性低。因此,基于电压相似性量度的聚类算法将有助于区分电表相序。
先验知识2:受负荷、线径、线路长度等因素影响,同相电表电压变化亦存在相似性较低情况。因此,聚类时应充分考虑各聚类簇的簇内紧凑度与簇间分离度。
先验知识3:在单相表相序识别时若不考虑三相表,由于三相表数据缺失,将导致同相电表群的电压关联性下降,进而影响单相表识别准确率。因此,相序识别时应考虑三相表的影响。
2 电压时序特征标准化与降维
为了有效挖掘不同用户电压时序变化特征的差异,进而提高聚类效果,本章采用Z-Score 与t分布的随机近邻嵌入(t-SNE)算法对用户电压时序特征进行标准化与降维处理。
2.1 Z-Score 标准化方法

2.2 非线性降维算法t-SNE
特征降维指的是在保留原始数据主特征的前提下,将原始高维数据集压缩至低维数据集的过程,其通过主特征提取,能够减少原始序列噪声对后续聚类准确性的影响。特征降维方法主要可分为线性降维与非线性降维两大类。其中,非线性降维对原始序列分布特性保真能力较好。t-SNE算法是一种基于概率分布嵌入的非线性降维算法,降维效果好,应用较为广泛[18-19]。
t-SNE 算法的基本思想为:基于高斯分布函数将高维数据点之间的欧氏距离转化为联合概率,构建高维空间的概率分布;再基于t分布函数计算低维空间数据点之间的欧氏距离,并将其转化为联合概率,构建低维空间的概率分布;最后计算高、低维概率分布之间的Kullback-Leibler(KL)散度,其值越低,表明高、低维空间的概率分布越相似,将其作为目标函数,使用梯度下降法进行迭代求解,直至寻找到使KL 散度最小的原始数据集的低维表示,即可得到降维后的数据集。
t-SNE 算法的具体步骤如下。
基于高斯分布函数计算高维空间数据之间的相似性概率pi|j与pj|i:

式中:xi和xj分别为高维空间中的任意2 个向量;δi和δj分别为以xi和xj为高斯分布中心的高斯模型方差。

3 基于背景知识的CFK-Medoids 聚类算法
3.1 聚类算法
聚类分析是指基于某种相似性量度,将具有相似特征的样本聚为一簇,使得簇内样本的特征差异较小,而类间样本的特征差异较大。常用的聚类算法包括划分、层次、网格、密度、模型聚类等。
划分聚类计算复杂度低,对高维数据集的运算相对高效,但需预设聚类数;层次聚类采用树状结构进行逐层聚合,无须预设聚类数即可发现类的层次关系,但计算复杂度高,离群值点影响较大;网格聚类利用属性空间的多维网格数据结构,将空间进行块划分,其聚类的质量和准确性较低;密度聚类基于数据的分布密度,通过连接高密度区域实现聚类,其无须预设聚类数,但对参数的设置敏感且数据样本越大收敛时间越长;模型聚类通过模型假定,寻找数据对假定模型的最佳拟合来实现聚类,当数据的概率分布数较多且数据量较少时执行效率不高。
3.2 本文算法
基于先验知识1,采用基于电压相似性量度的聚类算法有助于区分电表相序。结合3.1 节分析,由于本文研究问题的聚类场景数相对固定,可考虑采用对数据具有高效处理能力的划分聚类算法进行分析[20-22]。
基于先验知识2,聚类分析时应充分考虑各聚类簇的簇内紧凑度与簇间分离度,不能简单地将聚类数设定为台区相序数。因此,通过特定指标评估聚类结果的优劣,进而判断聚类数的设定是否合理。聚类有效性评估指标包括2 类:一类是外部评价指标,其将聚类结果与参考模型进行比对,判断聚类效果的优劣;另一类是内部评价指标,针对聚类结果的数据分布情况,从紧致性、分离性和连通性等方面对聚类结果进行评价。内部评价指标不依赖于参考模型,更适合本文研究的问题,因此本文选取内部评价指标作为聚类有效性评价指标。戴维森堡丁指数(Davies-Bouldin index,DBI)是最为常用的聚类有效性内部评价指标[23],其计算公式如下:
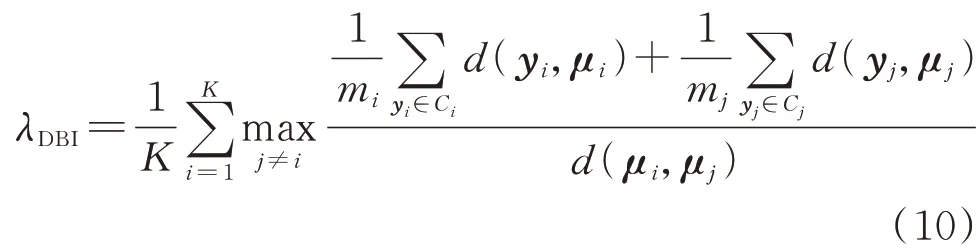
式中:mi和mj分别为聚类簇Ci和Cj的电表个数;μi和μj分别为聚类收敛后聚类簇Ci和Cj的聚类中心电压特征向量;d(·)为距离函数,一般采用欧氏距离作为距离量度。
基于先验知识3,相序识别时应充分考虑三相表影响。目前大多数文献主要针对单相表开展相序识别,尚未考虑三相表对相序识别的影响[14-17]。在实际情况中,台区既包含单相表也包含三相表。尽管目前三相表相序可直接获取,但由于现场施工、管理不规范等问题,导致三相表存在错相接线,即其相序信息并非对应系统真实的供电相序。因此,在对台区用户开展相序识别时,若仅考虑单相表相序识别,一方面无法辨识三相表错相接线问题,进而导致台区三相不平衡,影响线损分析的准确性;另一方面,当台区三相表比例较高时,将影响单相表相序识别的准确性。
当考虑三相表开展相序识别时,还需引入描述三相表特征的背景知识,即同一块三相表所等效的三块单相表应归属于不同相序。因此,本节在聚类算法中引入了Cannot-link 成对约束,其规定了成对实例必须在不同簇中,符合三相表特征。文献[24-25]将Must-link 和Cannot-link 成对约束引入Kmeans 聚类算法中,提出带约束的K-means 聚类算法,在三相电表数量占比较高的台区上展现出了一定效果。然而,K-means 算法对数据噪声和离群点较为敏感,这类异常数据易使聚类中心偏离理想位置,导致算法准确率下降。
综上所述,本文采用K-Medoids 算法替代Kmeans 算法,并引入快速收敛机制,提出了CFKMedoids 聚类算法开展低压台区用户相序识别。其中,快速收敛机制将聚类中心点的替换范围限制在簇内部,即在每个簇中寻找到一个新的中心点,这个中心点与簇中其他对象之间的距离总和最小。该方法只需要计算一次簇内的距离矩阵,避免了传统KMedoids 算法每次迭代中的全局最优搜索过程,显著提升了算法收敛速度,并且其与传统算法计算所得的聚类中心偏差不大,在精度范围内能够有效提升算法计算效率[26]。算法计算流程图如附录A 图A1 所示,具体步骤可描述如下:
步骤1:输入目标台区用户原始电压时序X=[X1,X2,…,Xi,…,Xn],其中Xi=[xi1,xi2,…,xiT]T,对X进行Z-Score 标准化和t-SNE 降维,得到用户电压特征向量Y。
步骤2:依次设定聚类数K=1,2,…,M,采用CFK-Medoids 进行聚类计算。
步骤3:根据式(11)计算各用户电表电压特征向量在特征空间中的相对距离系数vj,升序排列并选择前K个用户电表的电压特征向量作为初始聚类中心η1(1),η2(1),…,ηK(1),也称为代表对象,其余数据称为非代表对象。

步骤4:基于欧氏距离分别计算各电表电压特征向量到K个聚类中心的距离,基于最小距离原则,将各电表分配给距离其最近的聚类中心所属的簇。
步骤5:检验各聚类簇中的电表元素是否违反Cannot-link 约束。若是,则将该电表分配到其次近的簇中,并再次检验直至满足约束。

步骤8:若S′i(N)小于Si(N),则令Si(N)=S′i(N),且令yi为新的聚类中心。
步骤9:重复步骤6、7,直至遍历所有的非代表对象。
步骤10:重复步骤3 至步骤8,直至K个聚类中心不再发生变化。
步骤11:基于当前聚类结果计算DBI,重复步骤2 至步骤11,直至完成各聚类数设定情况下的聚类分析。
步骤12:选取λDBI最小值对应K作为最佳聚类数,分别计算K个聚类簇的聚类中心与配电变压器低压侧母线三相电压时序的欧氏距离,欧氏距离最小的即为当前聚类的相序。
4 算例分析
4.1 算例数据说明
本文选取中国广东省某地市3 个台区实际数据作为分析样本,对所提方法的有效性进行验证。3 个实际台区的基础参数如表1 所示。

表1 实际台区基础参数Table 1 Basic parameter of real distribution-station area
各台区数据集均由配电变压器低压侧母线及所有用户智能电表电压时序数据组成。其中,台区1电压时序数据长度为3 d,频次为15 min/次,共计288 个时刻;台区2 电压时序数据长度为2 d,频次为15 min/次,共计192 个时刻;台区3 电压时序数据长度为12 d,频次为60 min/次,共计288 个时刻。
本文算例中3 个台区的所有电表均已通过人工现场勘察结合相关识别设备检测获取其正确相位标签,本文所提算法的识别准确率均是以人工现场识别结果为基准计算得出的。
为验证所提方法的准确性,本文设置了多种方法对照:1)方法1 为基于主成分分析(principal component analysis,PCA)降维的CFK-Medoids 聚类方法;2)方法2 为基于t-SNE 降维的平衡迭代规约 层 次 聚 类(balanced iterative reducing and clustering using hierarchies,BIRCH)方法[27];3)方法3 为基于t-SNE 降维的快速K 中心点聚类(fast KMedoids,FK-Medoids)方法,其考虑聚类的快速收敛机制,但不考虑三相表特征约束;4)方法4 为本文所提方法;5)方法5 为基于t-SNE 降维的约束K 中心点聚类(constrained K-Medoids,CK-Medoids)方法,其考虑三相表特征约束,但不考虑聚类的快速收敛机制。
4.2 降维方法有效性分析
为体现t-SNE 降维的有效性,本节分别采用方法1与方法4在台区1至3中进行了仿真计算。附录A图A2 至图A4 给出了方法1 在台区1 至3 中的可视化识别结果,图2 至图4 给出了方法4 在台区1 至3中的可视化识别结果。表2 给出了方法1、方法4 在台区1 至3 中的相序识别准确率。

表2 方法1 和方法4 的相序识别准确率对比Table 2 Comparison of phase sequence identification accuracy between method 1 and method 4
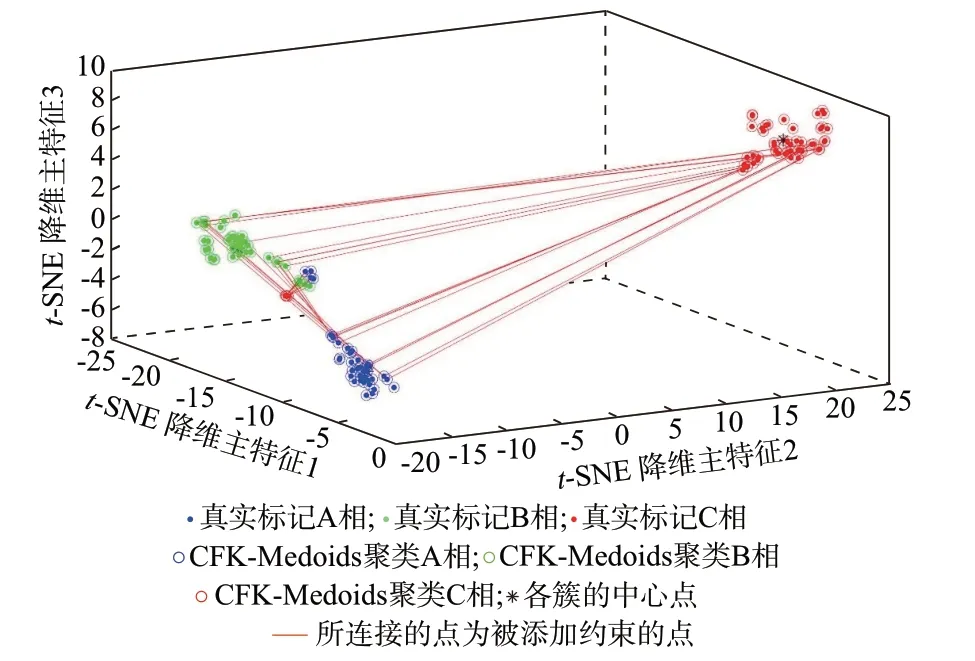
图2 方法4 在台区1 中的可视化识别结果Fig.2 Visual identification result of method 4 in distribution-station area 1
对比图2 至图4 与附录A 图A2 至图A4 可知,方法4 下各聚类簇在低维特征空间中的分布差异度更为显著,即相较于PCA 降维方法,t-SNE 算法能够更为有效地保留原始序列的主要特征,更好地将高维空间中的数据分布特性在低维空间中表示,进而有助于提高相序识别的准确率。
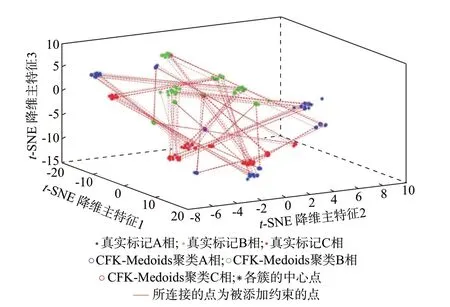
图4 方法4 在台区3 中的可视化识别结果Fig.4 Visual identification result of method 4 in distribution-station area 3
4.3 考虑三相表及其特征约束的必要性分析
为体现考虑三相表特征约束的必要性,本节分别采用方法2、3 与4 在台区1、2 中进行仿真计算。其中,方法2、3 均未考虑三相表特征约束。附录A图A5 和图A6 给出了方法2 在台区1、2 中的可视化识别结果,附录A 图A7 和图A8 给出了方法3 在台区1、2 中的可视化识别结果。表3 给出了方法2 至4在台区1、2 中的识别准确率。

表3 方法2 至4 的相序识别准确率对比Table 3 Comparison of phase sequence identification accuracy of methods 2-4
分析表3 可知,在台区1 中,相较于方法4,方法2、3 的识别准确率较低。其中相序识别错误的电表均为三相表,具体表现为A、C 相电表被错误识别为B 相,违反了来自同一三相表中的3 个单相表不能连接到同一相序的背景知识。这是由于台区1 中三相表分布在靠近配电变压器低压侧分支出线首端,其电气距离相近,导致其等效三块单相表的电压时序变化较为相似,进而聚类时会将其聚为一类。而方法4 通过引入三相表特征约束,识别准确率均可达100%。此外,在台区2 中,由图3 和表3 结果可知,方法4 通过添加Cannot-link 约束,识别准确率较方法2、3 分别提升了11.49%、9.77%,说明三相表特征约束的考虑能够有效提升识别准确率。
从水的实际用途进行归类,水的使用大致可以分为自然使用和人为使用,自然使用主要包括生活饮用水、家禽用水和家庭用水,相关用水权利是一种绝对权利。人为使用主要体现为水用来进行发电、生产和休闲,相关用水权利通常不是绝对权利。如果自然使用和人为使用存在冲突,如何合理分配水权呢?通常,人们认为自然使用优于人为使用。问题是,当水资源能够满足自然使用需求,但是无法满足各种人为使用需求时,如何在用水需求相互竞争的用水人之间分配有限的水资源?
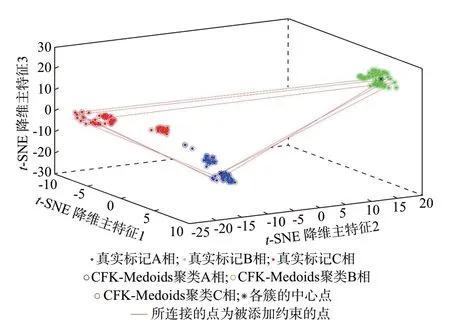
图3 方法4 在台区2 中的可视化识别结果Fig.3 Visual identification result of method 4 in distribution-station area 2
为进一步说明考虑三相表的必要性,采用方法2、4 在台区3 进行仿真计算。其中,方法2 假定三相表相序标定,仅考虑单相表相序识别。附录A 图A9给出了三相表未参与情况下方法2 在台区3 上的可视化识别结果。通过统计可知,未考虑三相表时,方法2 在台区3 上的单相表相序识别准确率仅有57.14%,相较于方法4,相序识别准确率下降了42.86%。结合附录A 图A9 可知,由于台区3 属于城乡结合部类型台区,其三相表报装占比高,若因三相表相序标定而不考虑参与相序识别,则会显著降低同相电表群的电压关联特性,导致特征空间中聚类可行性差,易导致聚类错误,进而劣化识别准确率。
此外,通过考虑三相表及其特征约束,本文所提方法能够有效辨识三相表不规范接线问题,如附录A 表A1 至表A3 所示。三相表不规范接线的有效辨识能够为台区线损精益化管理、三相不平衡与低电压问题精准治理提供支撑。
4.4 快速收敛机制的有效性分析
为验证本文所提CFK-Medoids 聚类算法中初始聚类中心选取方法以及快速收敛机制的有效性,采用方法4、5 在台区1 至3 中进行了仿真计算。其中方法5 采用随机初始化聚类中心点、全局寻优更新中心点的方式。表4 给出了方法4、5 的计算时间。

表4 方法4、5 的计算时间对比Table 4 Comparison of calculation time between methods 4,5
分析表4 可知,相较于方法5,方法4 在台区1 至3 的计算时间分别减少了约53.3%、53%与90.2%,说明了聚类快速收敛机制的引入能够显著提升计算时效,且随着台区用户规模增加,提升效果更为显著。附录A 图A10 给出了方法4 在各台区应用的迭代收敛过程,其中纵坐标表示前后两轮迭代各聚类中心点的欧氏距离,当该值为0 时,说明各中心点不再变化,算法收敛,从图中可以看到在各台区中算法的收敛次数均不高于5 次,收敛速度快。需要说明的是,方法4、5 在台区1 至3 中的相序识别准确率均为100%。因此,聚类快速收敛机制能够有效兼顾相序识别的准确性与时效性。
5 结语
针对当前低压台区用户供电相序识别因缺乏考虑三相表导致识别不准确问题,本文提出了基于三相表特征约束聚类的低压台区用户相序识别方法,得到以下结论。
1)所提方法能够保留原始数据在低维空间中的差异特征,有效提高了相序识别准确率。
2)当台区三相表占比较高时,若不考虑三相表及其特征约束,将显著降低相序识别准确率。通过引入三相表特征约束,能够显著提升相序识别准确率,且能够有效辨识三相表不规范接线问题,进而为台区线损精益化管理、三相不平衡与低电压等问题的精准治理提供支撑。
3)当台区三相表占比较高、用户规模较大时,采用聚类快速收敛机制能够在保证识别准确率的前提下,显著提升相序识别的时效性。
本文所提相序识别方法依赖实际台区数据质量,下一阶段将针对计及数据质量问题的鲁棒相序识别方法展开研究。
本文受到广东电网有限责任公司科技项目(GDKJXM20190385)支持,特此感谢!
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
