基于混合分析的Java反序列化利用链挖掘方法
2022-04-18武永兴陈力波姜开达
武永兴,陈力波,姜开达
(上海交通大学网络空间安全学院,上海 200240)
0 引言
2015年,Lawrence和Frohoff首先提出了Java反序列化漏洞。随后,Breenmachine利用Java反序列化漏洞成功攻击WebLogic、WebSphere、JBoss、Jenkins、OpenNMS等Java应用,并实现了远程代码执行。Fastjson、Jackson、Hessian、XStream 等第三方反序列化库被爆出存在反序列化漏洞,在反序列化攻击者可控的数据时可能会执行攻击者构造的恶意代码。攻击者通常需要通过组合应用中存在的代码片段,即gadgets,形成反序列化利用链,才能挟持反序列化器的执行控制流,达到执行对应危险操作的目的。因此,反序列化利用链是Java反序列化漏洞利用的关键,研究如何自动化挖掘Java反序列化利用链至关重要。
序列化是指将Java对象转换成字节序列、JSON字符串、XML字符串等,用于存储、网络传输等。反序列化是序列化的逆过程,将字节序列、JSON字符串、XML字符串等,转换成Java对象。Java反序列化漏洞常见于RPC调用过程中,客户端将参数对象序列化成字节码,通过网络传输给服务端,服务端将收到的数据反序列化成参数对象,然后调用相应的处理函数。另一种常见的场景是对HTTP请求的参数进行反序列化,将用户传递的JSON/XML格式的数据转换成Java对象。按照反序列化的机制,Java反序列化器可以分为两类,一类是基于bean,通过调用setter方法对field进行赋值;另一类是基于field,通过反射直接对field进行赋值。常见的基于bean的反序列化器有:Fastjson和Jackson。常见的基于field的反序列化器包括:JND(java naive deserialization)、XStream、Hessian。攻击者根据反序列化器的特点,在类路径中搜索合适的gadget,将这些gadget组装成反序列化利用链。通过反序列化利用链可以挟持程序的控制流,执行危险的代码片段,达到执行任意代码的目的。由于反序列化是一项正常的功能,修复时不能简单地关闭反序列化功能。因此,针对反序列化漏洞,常见的修复手段是将已知的利用链加到黑名单中。换言之,如果攻击者能够找到新的利用链,那么就可以继续利用反序列化漏洞进行攻击。
然而在反序列化漏洞利用链的搜索中面临以下3个方面的困难。
首先,在反序列化的过程中用户可以控制生成对象的类型和属性,field实际对应的类型可能是声明类型的任意子类,从而造成所调用的函数不确定,需要排查所有子类情况。在确定被调函数的时候,可能要排查N倍的具体函数(N为实现方法的数量)。随着调用链长度的增长,要排查的函数数量将呈指数性增长,导致搜索空间爆炸。
其次,Java多态特性导致调用方法不确定,需要通过指针分析计算其实际运行中对应的类型。但是,指针分析需要消耗大量计算资源。
最后,当前整个JDK的代码量已然十分庞大,以Java(1.8.0_171)为例,共有38 466个类和32 4595个方法。庞大的代码数量,给自动化分析带来巨大挑战。
与Java反序列化漏洞相关的工具大多是payload生成工具,如Marshalsec和Ysoserial,这些工具将已知的利用链封装成payload,但不具备挖掘未知利用链的能力;同时,有一部分工业界的工具,如GadgetInspector,提供了自动化搜索gadget的能力,但其没有进行指针分析,导致误报率和漏报率都很高。当前学术界大多数的工作是关于如何检测注入类漏洞,对于自动化挖掘Java反序列化利用链没有探索过。
综上所述,针对序列化利用链搜索的空间十分大,人工审计难以覆盖的现状,提出一种能够协助安全研究人员自动化挖掘利用链的方法是相当有必要的。针对该问题,本文主要贡献如下。
1) 提出了基于混合分析的Java反序列化利用链挖掘方法,设计并实现了在字节码级别进行自动化分析挖掘Java反序列化利用链工具——GadgetSearch。
2) 实验表明GadgetSearch的误报率和漏报率远小于现有的工具GadgetInspector,并且利用GadgetSearch挖掘出1条Jackson未公开利用链、4条XStream未公开的JDK利用链和1条Hessian未公开的JDK利用链,申请分配了5个CVE(CVE-2021-39141、CVE-2021-39144、 CVE-2021- 39146、CVE-2021-39153、CVE-2021-43297)和1个CNVD编号(CNVD-2021-44381)。
1 相关工作
指针分析(pointer analysis)[1-4]是计算程序变量在运行期间可能指向的对象集合。Java多态的性质,需要根据变量运行时指向对象的类型解析被调用函数,所以指针分析是其他分析的基础。Bravenboer[5]等提出了一种声明式指针分析框架Doop,他们通过在Datalog中描述完整的端到端分析,并使用专门针对递归的Datalog程序进行优化,推动了声明式指针分析的发展。Antoniadis[6]等将Doop中的Datalog推理引擎从LogicBlox换成了Souffle ,Souffle支持通过共享内存并行分析,切换推理引擎之后,Doop整体提速 4倍。
污点分析(taint flow analysis)[7-11]是信息流分析(information flow analysis)的一种。Livshits[12]等探索使用Datalog进行污点分析,但没有将该污点分析与指针分析统一起来。Tripp[13]等认为污点分析是一个需求驱动问题,不需要进行完整的全程序分析,他们提出了一套名为Andromeda的工具,利用数据流方程和污点集进行数据流分析。FlowDroid[14]是一种Android应用污点分析框架,可以进行流敏感(flow-sensitive)的污点分析。FlowDroid对常见的Android特性(如回调等)进行了建模,并且手工筛选出了700多条Source、Sink以及转移函数。这些转移函数包含了常见数据结构的操作。但是FlowDroid没有将信息流分析和调用图构造统一起来。Pidgin[15]通过程序依赖图(program dependence graph)的方式实现了信息流分析。程序依赖图可以被用来模拟任何形式的数据以及指令之间的控制依赖。DroidInfer[16]使用约束流图的可达性算法进行污点分析,它依靠WALA8在进行主要分析之前产生一个控制流图。
Grech等提出了P/Taint[17],将指针分析和污点分析结合起来,他们通过很小的改动把信息流分析整合到了Doop指针分析框架。通过扩充堆对象的定义域来实现这一目标,并增加污点分析的内容。程序分析通常将污点分析和指针分析视为不同的过程,但该项工作表明,同样的算法可以同时计算污点信息和指针信息这两种相互关联但独立的信息。同时,由于反序列化漏洞的污点源不是来自Source函数,而是来自隐式创建的对象,无法直接利用Doop的信息流分析功能来跟踪反序列化的污点数据流。
Dahse[18]等介绍了PHP反序列化漏洞,他们提出了一个过程间字段敏感和对象敏感的数据流分析方法,利用该方法自动化挖掘PHP反序列化利用链。Shcherbakov[19]等研究了.NET中的反序列化漏洞。他们先将.NET字节码转换成.NET通用的中间语言;然后实现了一个高效、可扩展的过程间污点分析;最后基于该方法实现了自动化挖掘.NET利用链工具SerialDetector。由于他们的方法只针对PHP和.NET这两种特定语言,无法直接应用到Java反序列化利用链的挖掘。
JackOfMostTrades在BlackHat上介绍了一款挖掘利用链的工具 GadgetInspector[20]。GadgetInspector利用ASM库解析字节码,通过模拟操作栈实现污点分析,支持JND、XStream,Jackson这3种反序列化利用链的挖掘。杜笑宇等[21]将GadgetInspector中的广度优先搜索算法改造成了深度优先算法,找到了一些新的利用链。Threedr3am对GadgetInspector进行了改造,增加了对 Fastjson和 Hessian的支持。但是GadgetInspector构造调用图时没有进行指针分析,导致调用图不准确,包含大量不存在的调用关系,误报率和漏报率非常高。
2 研究动机
通过分析Java反序列化器的实现可知,Java反序列化漏洞能被利用的原因包含以下3点。反序列化的数据用户可控,用户能够控制对象的类型以及其属性值;反序列化器在反序列化的时候会自动调用入口函数;类路径(包括JDK和第三方库)中存在合适的gadget,通过构造将gadget串成一条链,从自动调用的入口函数开始链式调用到危险函数。
从上述原因中,可以提取出反序列化漏洞利用环节的三要素。污染源:攻击者可控的变量;入口函数:反序列化时自动调用的接口函数;危险函数:能够执行命令的函数。
因此,挖掘反序列化利用链首先需要根据反序列化器的实现,分析出入口函数和污点源;然后从入口函数开始,根据声明类型初始化污点源,跟踪污点传播。同时在追踪的过程中,会遇到新的函数调用,这时通过指针分析,解析其真实的调用,进行过程间污点传播分析,判断污点数据能否传播到危险函数。
下面将根据图1所示的反序列化利用的示例,解释寻找Java反序列化利用链的详细过程。

图1 反序列化利用链示例 Figure1 Example of a gadget chain
其中,hashCode是常见的入口函数,本文从类A的hashCode函数开始分析调用路径。A#hashCode先调用A#getInterfaceC,然后调用InterfaceC#getHashCode。变量interfaceC声明类型是InterfaceC接口类,但是由于Java多态的性质,根据声明类型InterfaceC,无法判断出interfaceC.getHashCode在运行时调用的是CImpl#getHashCode还是CImplOther# getHash-Code。因此,为了得到准确的调用图,需要进行指针分析,计算变量interfaceC在实际运行过程中可能指向的对象类型,再根据指针信息解析实际调用。在图1所示的例子中,通过指针分析,可以计算出变量interfaceC在运行过程中指向CImpl对象,因此interfaceC.getHashCode对应的实际调用方法是 CImpl#getHashCode。在CImpl#getHashCode中调用了interB.get,由于变量interB也是接口类型,所以需要指针分析计算其运行时可能指向的对象类型。变量interB来自变量iobj,iobj为A的field。同时由于通过反序列化创建的A类型对象的iobj field不像变量interfaceC有显式的创建对象代码,所以无法通过常规的指针分析计算interB的指针信息。在反序列化的过程中能够控制类型和属性值,所以可以控制iobj为InterfaceB的所有实现类,即图1示例中的BImpl或者BImplOther。因此,interB.get可能会调用BImpl#get或者BImplOther#get,需要遍历追踪这两个接口,发现BImplOther#get不会调用危险函数,但这个分支属于不得不排查的无效分支;接下来,在BImpl#get分支中调用了method#invoke,其中clazz和methodName都是field,在反序列化时对应的值是攻击者可控的,因此变量method也是攻击者可控的,所以该分支最终可以调用method.invoke危险函数,而且变量method和obj都是攻击者可控的。至此,本文找到了一条以A#hashCode为起点,Method#invoke为终点的反序列化利用链。完整的调用链如图1中的红色箭头所示:A#hashFigure→ CImpl# getHashFigure→ BImpl#get → Method# invoke。
过程间的污点传播链为图1中蓝色箭头所示:A#hashCode@iobj → CImpl#getHashCode@ interB → BImpl#get@this。
从上面示例中可以看出,寻找利用链过程的本质是污点分析:分析污点源能否从入口函数传播到危险函数。同时,过程间的污点传播需要准确的函数调用图,但Java多态导致不能只根据声明类型确定调用关系。所以需要根据指针分析的结果解析准确的函数调用。反序列化的过程中会隐式创建对象,而且创建的对象可能不唯一,可以是声明类型的所有实现子类,导致传统的指针分析无法直接应用在这项任务中,需要进一步遍历可能的所有接口。但是反序列化入口函数多,类路径代码量大,反序列化时创建的field可能是声明类型所有子类对象,这些因素导致直接从所有入口函数进行指针分析,计算量非常大,在有限的时间和受限的内存情况下无法得出指针分析的结果。
另外,如果只通过声明类型构造简单调用图,然后在调用图中寻找从入口函数到危险函数的调用链作为反序列化利用链。这种做法将存在大量的误报:一是因为根据声明类型构造的调用图不准确,调用关系在实际运行的过程中可能不存在;二是即使调用链存在,如果污点源无法传播到危险函数,调用链也将无法利用。
综上所述,虽然通过调用图分析挖掘反序列化利用链的速度快,但调用图不准确导致存在大量的误报;同时为了构造更准确的调用图用于过程间信息流分析,需要进行指针分析。引入指针分析后,准确的调用图让污点传播更准确,但指针分析计算复杂导致效率较低。
因此,为了准确且高效地挖掘反序列化利用链,本文提出了一种基于混合分析的Java反序列化利用链挖掘方法。首先,通过调用图分析找出可能到达危险函数的入口函数;然后,利用筛选出的入口函数作为混合信息流分析的入口,构建包含指针信息和污点信息流向的混合信息流图;最后,基于混合信息流图判断从入口函数开始的污点是否能传播到危险函数,从而高效查找实际可行的反序列化利用链。
3 方法设计
3.1 面向危险函数的调用图分析
判断一条利用链是否有效的充分必要条件是:攻击者控制的污点输入能否从利用链的入口函数传播到利用链的敏感危险函数。如果利用链有效,一定存在从入口函数到危险函数的调用路径。因此,有效的反序列化利用链一定在通过调用图分析找到的调用路径集合中,可以通过调用图分析进行筛选,得到可能到达危险函数的入口点集合。
进行调用图分析首先需要构造调用图,调用图中的节点是方法,边为调用关系。Java中的函数调用分为3类:静态方法调用、特殊方法调用、虚拟方法调用,其中特殊方法调用包括私有方法调用、超级方法调用和构造方法调用。静态方法调用和特殊方法调用,不需要根据指针信息进行解析,能够根据声明类型确定被调用函数。由于Java多态的特性,虚拟方法不能根据声明类型确定被调函数。如何解析虚拟方法调用的被调函数是调用图分析面临的主要难题。为了防止调用图不全导致的漏报,本文假设变量在实际运行时,指向声明类型所有的子类。按照这种策略,在图1所示的代码中变量interfaceC可能指向CImpl或者CImplOther,调用interfaceC.getHashCode被解析成CImpl#getHashCode或者CImplOther# getHashCode;同理,调用interB.get被解析成BImpl#get或者BImplOther#get。最终调用图如图2所示,构造好调用图之后,根据调用图从危险函数开始回溯,寻找能够到达危险函数的入口函数。图2中能够到达危险函数的入口函数为A#hashCode,另外一个入口函数AOther# hash-Code无法到达危险函数。在后续污点分析时,将污点的入口函数设置为A#hashCode即可。入口函数到危险函数的调用路径有两条分别是:A#hashCode→ CImpl#getHashCode→ BImpl#get →Method#invoke 和 A#hashcode→ CImplOther#getHashCode→Method#invoke。第一条是有效的利用链,第二条是调用图不准确导致的误报,即图2中红色边表示的调用图中覆盖但程序运行时不存在的调用。
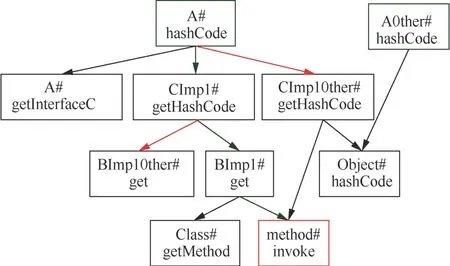
图2 调用图 Figure 2 Call graph
需要指出的是,在实际的Java应用分析中,由于代码量过大,为了能在有限的时间内得到简单调用图的分析结果,在构造调用图时增加了如下两类约束:一是通过设置参数MAXSTEPS,限制从入口函数出发最大的调用长度,当达到最大的调用长度之后,就不再继续解析新的调用;二是由于JDK中的java.util.*内部调用相对复杂,而且对寻找利用链帮助不大,所以限制以java.util开头的类的方法,不允许再调用其内部函数。
3.2 面向指针的信息流分析
通过调用图分析,能够找到入口函数到达危险函数的路径集合。但是调用关系在程序实际运行中是否真实存在,还需要指针分析进一步验证。
下面根据图1的信息流分析示例介绍面向指针分析的信息流图构造。
(1)指针信息初始化
传统指针分析中的指针信息初始化操作是new语句,如图3中代码第9行b3=new B(),通过new创建的对象为OB9,赋值操作将对象OB9的信息传播到变量b3,信息流图中OB9指向b3。

图3 信息流分析示例 Figure 3 Example code for information flow analysis
而在反序列化的过程中,程序会隐式创建对象,需要在信息流图中加上隐式对象流向边。隐式创建的对象是声明类型的所有实现子类。图3中,反序列化时创建的隐式对象设为OA0,OA0被赋值给A#entry@this,在信息流图中OA0指向A#entry@this。实际上反序列化时也会隐式对field创建对象,但静态分析时没有必要对所有field创建对象,可以在加载field时再实例化field对象,这样就可以做到只对用到的field才实例化,而且利用该规则可以对field对象的field进行实例化。在第7和12行中,加载了OA0.fldb1,OA0.fldstr,此时才创建隐式对象OB0、OString0,并在信息流图中将其指向OA0.fldb1、OA0.fldstr。
(2)过程内信息流图构造
在Java中过程内变量之间的信息传播有Assign、Load、Store这3种语句。
Assign表示赋值,如图3中的第8行,变量b1包含的信息将传播给变量b2,信息流图中b1指向b2。
Load表示获取一个对象的filed值,如第7行,对象OA0流向变量A#entry@this,所以OA0.fldb1包含的信息传播给 b1,OA0.fldb1指向b1。
Store表示对一个对象的field进行赋值,第10行,对象OA0流向变量A#entry@this,所以是b3包含的信息传播给OA0.fldb2,b3指向OA0.fldb2。
(3)过程间信息流构造
Call表示函数调用,涉及过程间变量信息传播。例如图3中第11行,遇到函数调用时,需要根据变量指针信息解析真实的调用。因为信息流图中对象OA0流向变量A#entry@this,因此变量A#entry@this运行中指向OA0对象,OA0类型为A,因此,this.func2实际调用的是A#func2。函数调用涉及3种变量传播:实际参数向形式参数传播,比如b1向paramb传播;函数内返回值向函数调用返回值传播,如ret向b4传播;对象向调用方法的this传播,如A#entry@this向A#func2@this传播。因此,在控制流图中b1指向paramb,ret指向b4,A#entry@this指向A#func2@this。
3.3 面向污点的信息流分析
虽然通过指针分析能够得到准确的调用图,但准确的调用关系还不足以判断一条调用链是否真实有效,还需要通过污点分析判断外部污点数据能否传播到危险函数。
表面上,污点分析和指针分析传播不同的信息:指针分析是在变量之间传递指针指向的对象集合;污点分析在变量传递内容时根据污点传播策略传递变量对应的污点属性。但是,污点分析和指针分析本质上均为信息流分析,变量之间传播的实际均为对象信息。可以根据指针变量指向的对象是不是污点,判断当前指针是否需要标记污点属性,从而将两者合并成同一个过程。例如,在图4中,对象OB0在信息流图上能够传播到变量b1,所以b1指向对象OB0。如果OB0含有污点标记,那么就可以认为指针变量b1是污点。
基于污点分析等价于传播带污点标记的对象,本文提出了混合分析——即同时进行指针分析和污点分析。具体地说,在对象初始化时打上是否为污点的标记,即可在指针分析的同时进行污点分析。相较于传统的指针分析,本文根据反序列应用的场景,需要针对性地增加规则来完成混合分析,其主要包含污点源初始化、污点转移规则。
(1)污点源初始化
污点信息的初始化是将反序列化时隐式创建的对象作为污点源,打上污点标记。OA0是污点源,将其标记为图4中的红框。
(2)污点转移规则
污点转移规则包含3种。第一种是当加载污点对象的field时,如z=x.f,如果x是污点,那么z也是污点。因为OA0是污点源,OB0和OString0是加载OA0field时隐式创建的对象,所以OB0和OString0也是污点源。第二种是当调用函数的对象是污点时,如z = x.func(),如果x是污点那么认为 z也是污点。在图 3中有语句str2=str1.substring(1), 所以str1有条指向str2的污点转移流向的边。第三种是当调用函数的参数是污点时,如z=x.func(y),如果y是污点,那么z也是污点。在实际测试中发现第二种规则会带来误报,如this.getClass().getClassLoader()这种情况,由于this是污点数据,getClass()返回的也是污点数据,所以getClassLoader()返回的也是污点数据,但实际情况下getClassLoader()返回值的攻击者并不可控。类似还有this.set.Iterator(),this.map.keys()等的返回值攻击者都不可控。本文通过限制返回值的类型,阻止这种传播,减少误报。
因此,综合利用污点分析和指针分析两方面的信息流传播规则,得到图3对应的混合信息流图,如图4所示。混合信息流图节点中包括变量节点(蓝框表示),隐式对象节点(红框表示),显式对象节点(黑框表示),对象field 节点(绿框表示)。信息流图边包括隐式对象流向、显式对象流向、信息流向、污点转移流向。
车地无线通信采用成熟的LTE技术。该技术具备高可靠的抗干扰能力,可满足互联互通CBTC系统车地之间数据在高速移动环境下的稳定传输[7]。同时,针对空口消息的伪装风险,可采用安全加密技术防护,将其直接部署在TAU(车载终端)和BBU(轨旁基带单元)上来实现鉴权和加密机制,保障车地无线通信的信息安全。安全加密技术采用满足LTE国际加密标准的国密算法——祖冲之(ZUC)算法。
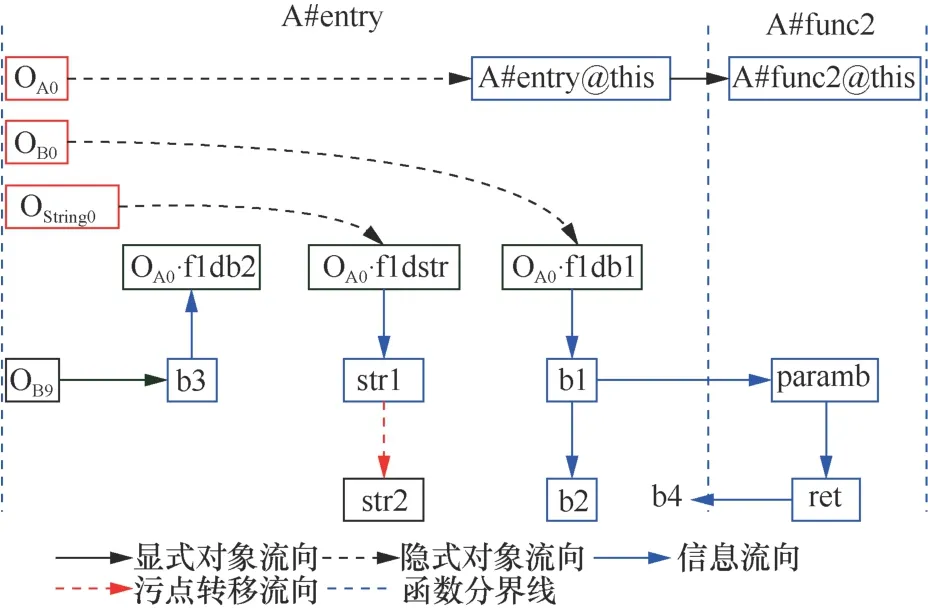
图4 混合信息流图 Figure 4 Hybrid information flow graph
根据指针分析,变量b1、b2、paramb、ret、b4指向对象OB0,变量str1、str2指向对象OString0。由于对象OB0和OString0都带污点标记所以变量b1、b2、paramb、ret、b4、str1、str2都是污点。
综上所述,本文提出的混合分析方法先通过调用图分析筛选出可能达到危险函数的入口函数;然后,再以这些入口函数作为入口进行同时面向指针和污点变量的混合信息流分析,最后基于信息流分析找出从入口函数开始污点源流向危险函数的路径。
混合分析示意如图5所示。其中A函数是调用图分析提取的潜在利用链入口函数。将A函数作为混合信息流分析的起点,通过传播污点标记的对象,进行指针分析和污点分析。
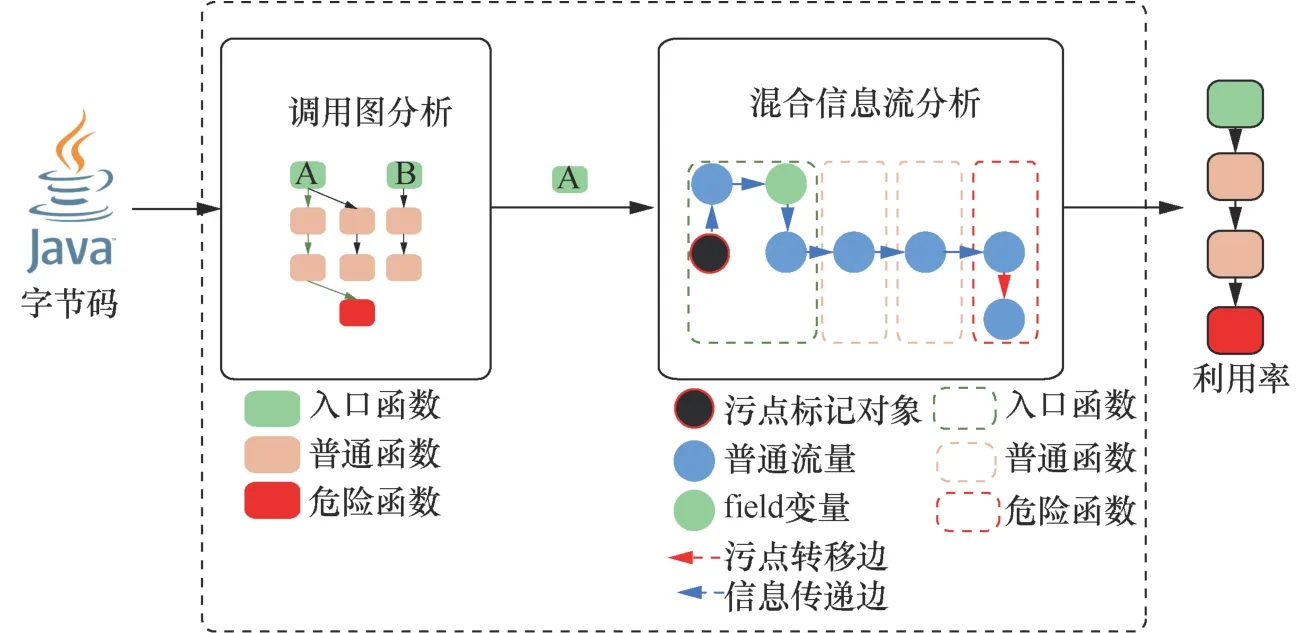
图5 混合分析示意 Figure 5 Hybrid analysis method diagram
4 方法实现
基于上述方法,本文实现了一套自动化挖掘Java反序列化利用链的原型系统——Gadget Search,GadgetSearch支持挖掘Jackson、Fastjson、XStream、JND、Hessian 5种常见反序列化器的利用链。
GadgetSearch首先利用Soot解析Java字节码,将字节码转化中间语言Jimple。然后,从Jimple中解析出类的基本信息,如类修饰符、父类、field、方法等以及方法中的操作指令new、Assign、Load、Store、Call,将这些信息保存成facts。接着用Datalog语法表达第4节描述的规则,用Souffle执行Datalog文件进行混合分析。分析完成后产生两个主要文件:Nodes.csv和Calls.csv。Nodes.csv记录各个Method,有3类标签,分别是EntryPoint、Method和SinkMethod;Calls.csv记录方法之间的调用关系。最后,通过Neo4j-admin 将Nodes.csv和Calls.csv文件导入Neo4j 数据库,并通过Cypher语句查询从EntryPoint到SinkMethod的路径,对方法调用路径可视化,方便安全排查调用链是否可利用。
5 实验分析
为了评估本文提出混合分析方法的有效性,需要设计实验回答下面3个问题。
RQ1:GadgetSearch能否挖掘到未公开的利用链?
RQ3:如何评估本文提出的混合分析方法的必要性?
测试的实验环境为 Ubuntu16.04,Java 1.8.0_171, 内存36 GB,24核Intel(R) Xeon(R) CPU E5-2630处理器。
5.1 针对RQ1的实验
为了验证GadgetSearch能够挖掘未知利用链,本文对JDK和一些流行的Jar包进行了测试。最终发现5条未公开利用链,具体数据如表1所示。其中CVE-2021-43297是第一条仅依赖JDK就能够命令执行的Hessian利用链。换句话说,只要存在Hessian反序列化漏洞,攻击者无须关心类路径包含哪些第三方库,直接利用这条链即可攻击,危害十分严重。本文成功利用该链攻击了Dubbo。
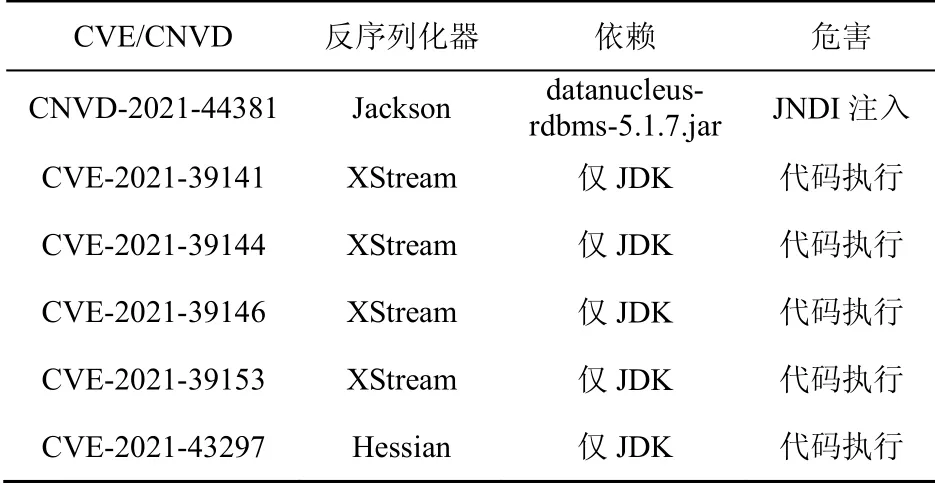
表1 未公开利用链列表Table 1 List of CVE/CNVD
5.2 针对RQ2的实验
挖掘Java反序列化的工具有Jack Of-MostTrades版本的 GadgetInspector(记为JGadgetInspector),以及Threedr3am 改进后的GadgetInspector(记为 TGadgetInspector) 。JGadgetInspector支持检测Jackson、XStream、JND这3种反序列化利用链。GadgetSearch和TGadgetInspector都支持检测Jackson、Fastjson、XStream、JND、Hessian这5种反序列化利用链。
为了只找出能够命令执行的利用链,本文去掉了JGadgetInpsector和TGadgetInspector中不能够造成命令执行的危险函数(如ssrf,文件读写等)。TGadgetInspector检测Fastjson利用链时,其为了检测出新的利用链,将已知的利用链加入了黑名单,对黑名单中的链不再检测。为了实验的公平性,本文将TGadgetInspector中Fastjson的黑名单置为空。
为了对比GadgetSearch和JGadget Inspector,TGadgetInspector检测反序列化利用链的误报率、漏报率以及运行效率,本文在Marshalsec,Ysoserial、Jackson CVE、XStream CVE数据集上进行测试。Marshalsec和Ysoserial是两个业界较出名的Java反序列化利用链Payload生成工具,包含一些已知的反序列化利用链。Marshalsec包含Jackson、XStream、Hessian 3种反序列化利用链,Ysoserial只包含JND反序列化利用链,数据集详情如表2所示。Jackson和XStream官方会为反序列化利用链申请CVE,所以本文从Jackson历史CVE中筛选出15个能够命令执行的CVE,从XStream历史CVE中筛选出14个能够命令执行的CVE作为另外两组数据集。
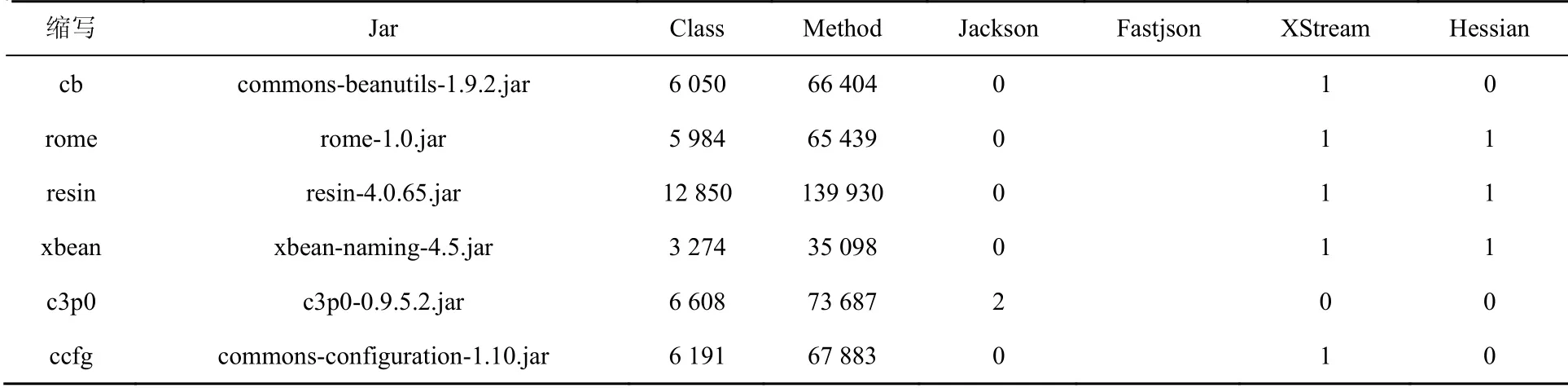
表2 Marshalsec 数据集Table 2 Marshalsec dataset
Jackson检测结果如表3所示。Marshalsec数据集中总计有 2条 Jackson利用链。JGadgetInspector挖掘出8条链,其中0条有效链,9条误报链,漏报率为100%,误报率为100%; TGadgetInspector挖掘出9条链,其中0条有效链,9条误报链,漏报率为100%,误报率为100%;GadgetSearch一共挖掘出18条利用链,且均为18条有效链,漏报率为0%,误报率0%。
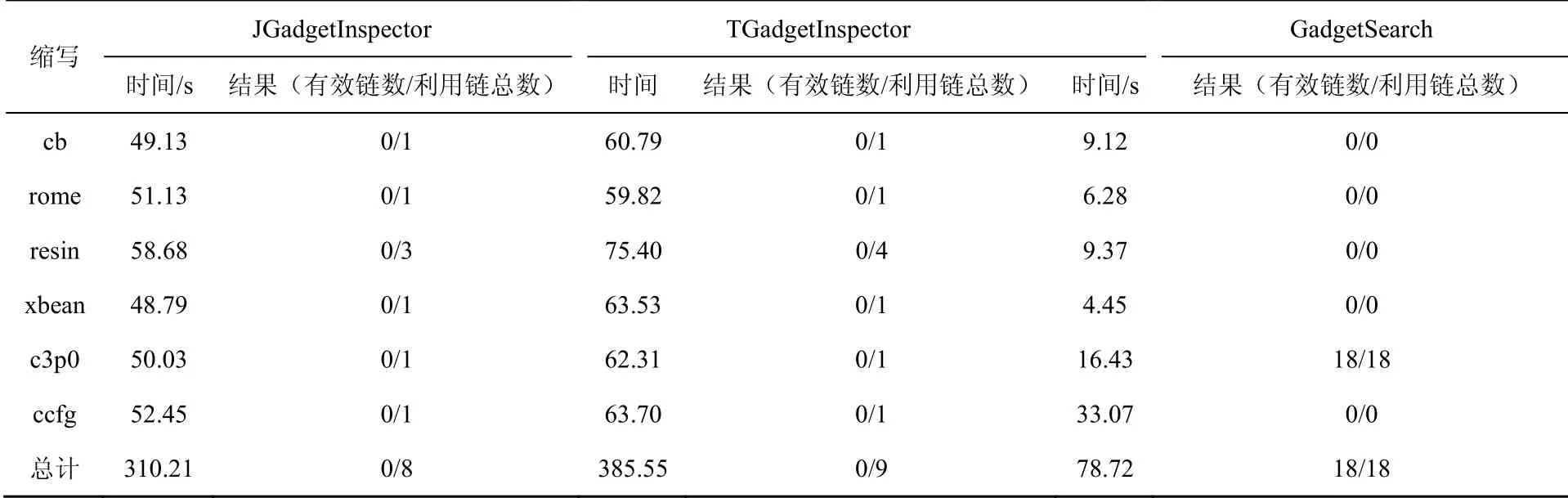
表3 Jackson 检测结果Table 3 Results of Jackson
Fastjson检测结果如表4所示。Marshalsec数据集中没有相应的Fastjson利用链, JGadgetInspector不支持 Fastjson利用链的检测。TGadgetInspector一共检测出633条利用链,其中0条有效链,漏报率100%,误报率100%;GadgetSearch一共检测出85条利用链,均为有效链,误报率为0%,漏报率为0%。
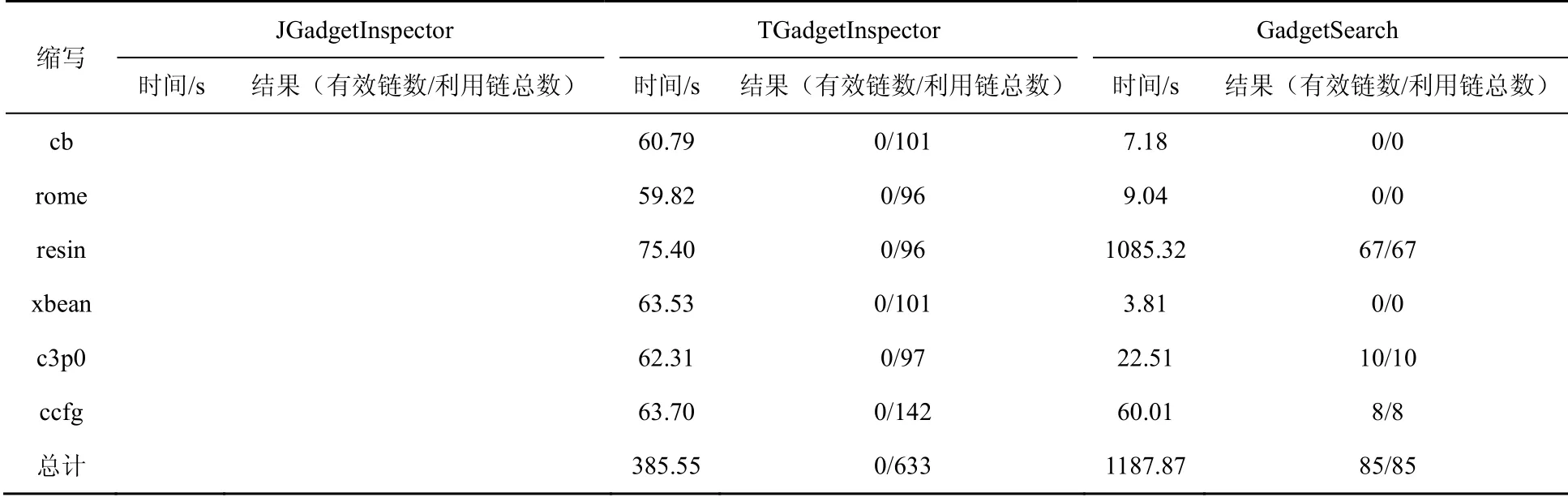
表4 Fastjson 检测结果Table 4 Results of Fastjson
XStream检测结果如表5所示。Marshalsec数据集中包含 5条 XStream 利用链,JGadgetInspector检测出101条利用链,其中有14条有效利用链,漏报了5条,误报率为86%,漏报率为100%;TGadgetInspector一共检测出269条利用链,其中12条有效利用链,漏报了5条,误报率为95%,漏报率为100%;GadgetSearch一共检测出126条利用链,且均为有效链,误报率为0%,漏报率为0%。
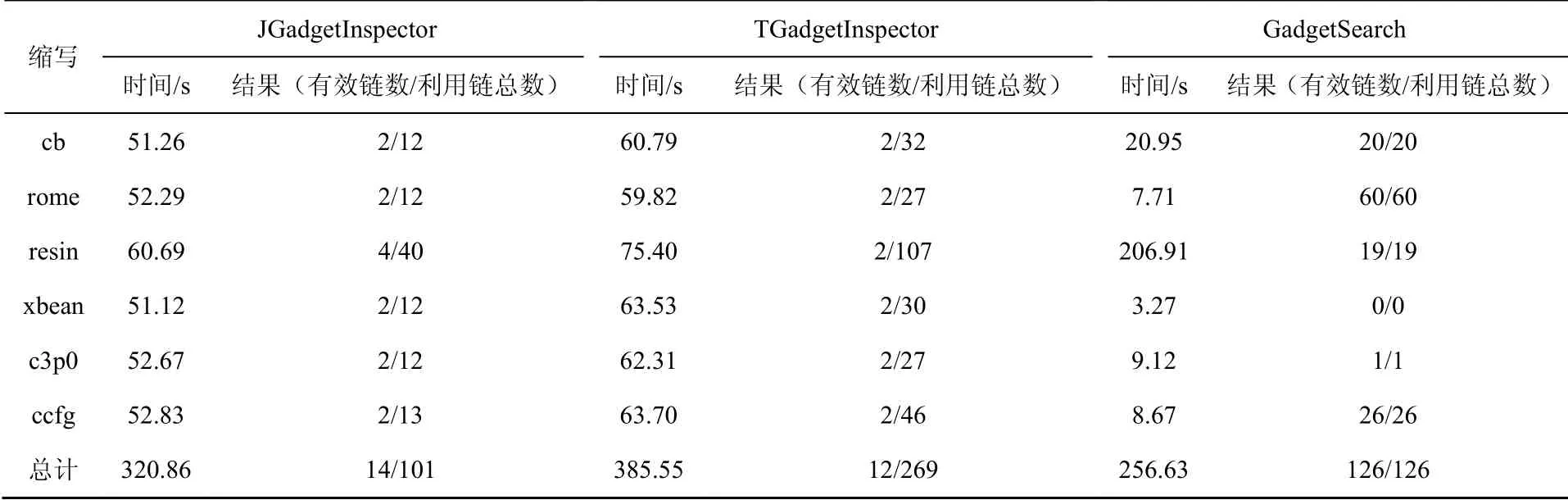
表5 XStream 检测结果Table 5 Results of XStream
Hessian检测结果如表6所示。Marshalsec数据中包含3条Hessian利用链,JGadgetInspector不支持Hessian反序列化利用链的挖掘。TGadgetInspector一共检测出1021条利用链,其中6条有效利用链,误报率为99.4%,没有检测出Marshalsec数据集中包含的利用链,漏报率为100%;GadgetSearch一共检测出36条利用链,且均为有效链,误报率为0%,漏报率为0%。
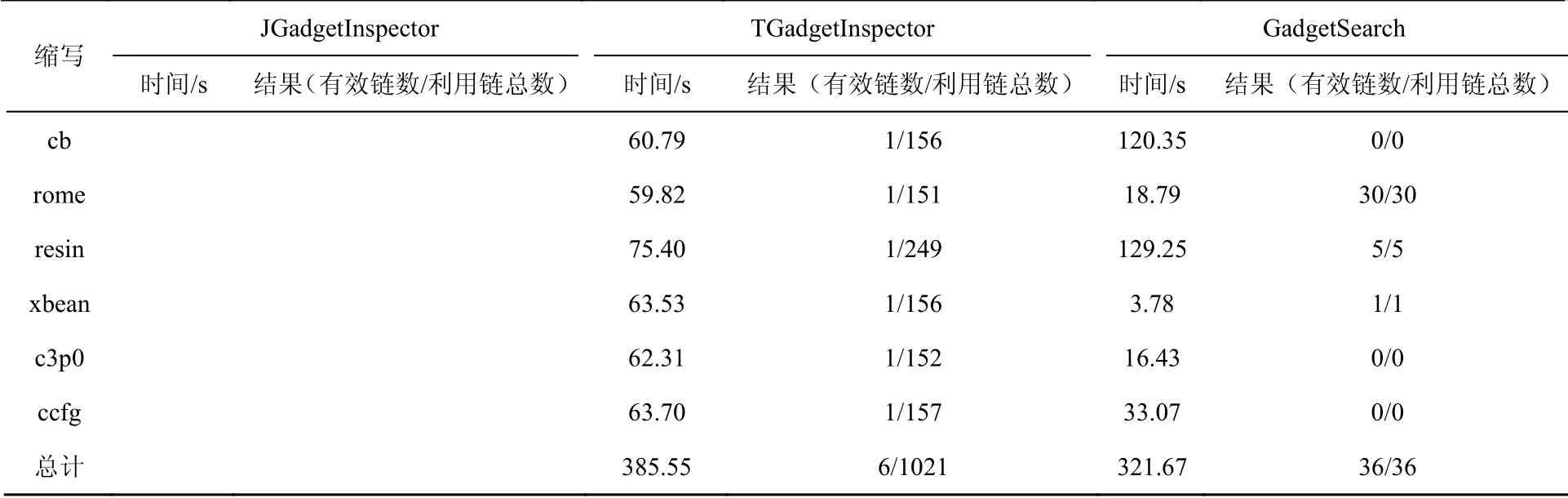
表6 Hessian 检测结果Table 6 Results of Hessian
JND检测结果如表7所示。Ysoserial数据集中包含13条JND反序列化利用链。JGadgetInspector一共检测出24条利用链,分析发现24条全是误报,漏报率为100%,误报率100%。针对JGadgetInspector报告的common- collections反序列化利用链,如图6所示,经过分析可认为此条链并不能直接利用。因为最终Method#invoke 调用时,第一个参数input是Class类,无法造成危害,不能达到命令执行的效果,如图7所示。TGadgetInspector一共发现了26条利用链,26条利用链均为误报,漏报率100%,误报率100%。GadgetSearch一共检测出118条利用链,均为有效链,针对bsh-2.0b5.jar利用链过长超过了GadgetSearch设置的最大长度,未被检测出有效利用链, 漏报率为7%,误报率为0%。

图6 JGadgetInspector 检测common-collections结果 Figure 6 The results of common-collections detected by JGadgetInspector
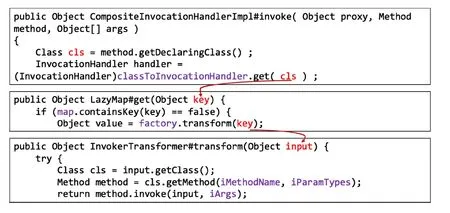
图7 common-collections 无效利用链 Figure 7 common-collections Invalid gadget chain

表7 JND检测结果Table 7 Results of JND
在Jackson CVE数据集上JGadgetInspector 和TGadgetInspector均未检测出相应包含关键类的利用链,漏报率100%,GadgetSearch则全部检测出,漏报率0%,检测结果如表8所示。

表8 Jackson CVE检测结果Table 8 Results of Jackson CVE
在XStream CVE数据集上的检测结果如表9所示,JGadgetInspector 和TGadgetInspector能检测出3个CVE,GadgetSearch能够检测出12个CVE。其中CVE-2021-39141、CVE-2021-39144、CVE-2021-39146、CVE-2021-39153为上报给XStream官方的,此外CVE-2021-39149基本等同 于本文发现的CVE-2021-39144,CVE-2021-39154基本等同于本文发现的CVE-2021-39146。CVE-2020-21344和CVE-2020-21345利用链过长,导致GadgetSearch无法检测出相应的利用链。
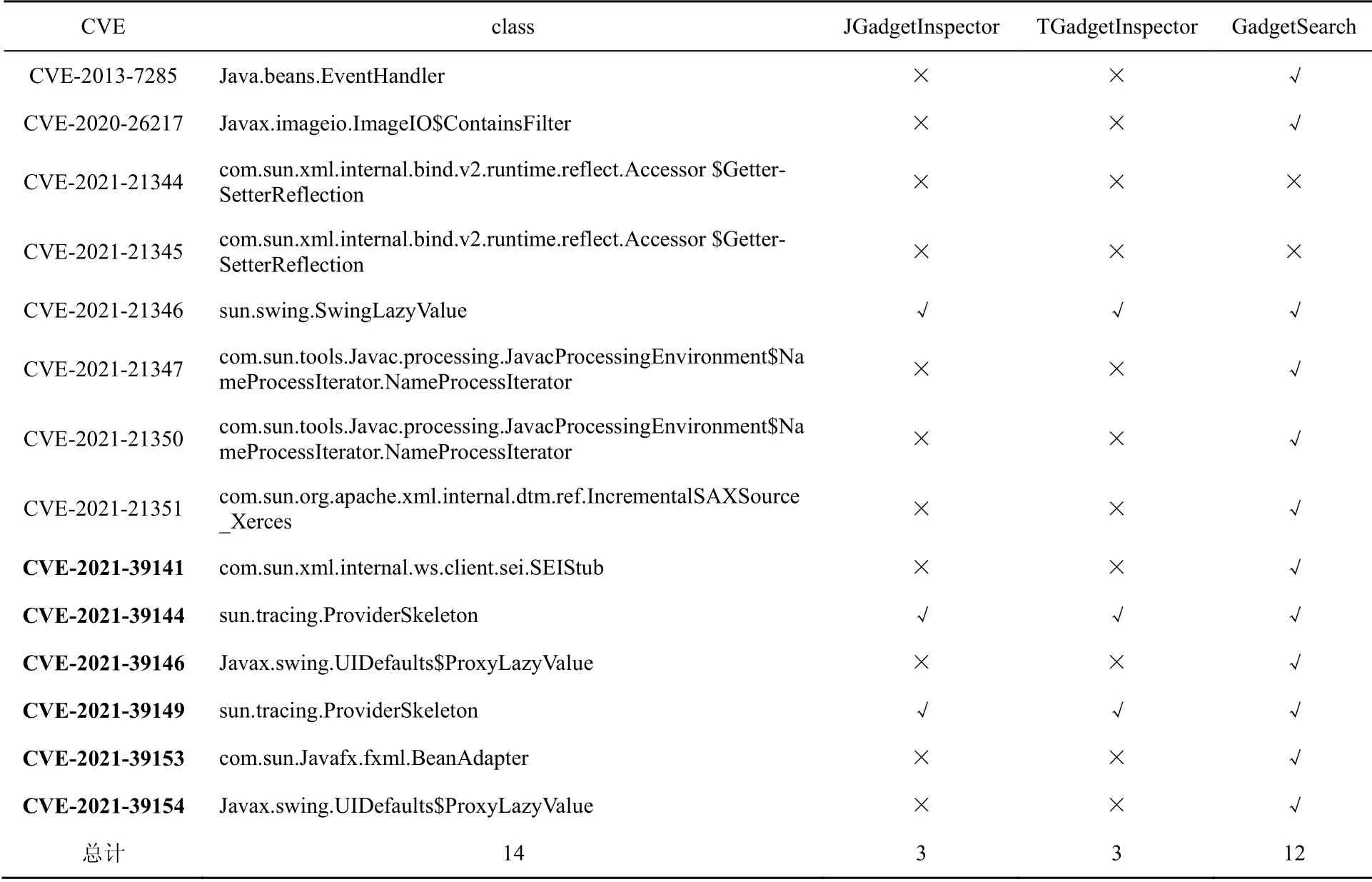
表9 XStream CVE检测结果Table 9 Results of XStream CVE
从实验结果可以看出,GadgetSearch的漏报率和误报率都远低于 JGadgetInspector和TGadgetInspector,主要原因是JGadgetInspector和TGadgetInspector入口函数和危险函数设置不全,以及没有进行指针分析且调用图不准确。
GadgetSearch 检测 Jackson、XStream、Hessian、JND的运行效率优于JGadgetInspector和TGadgetInspector;检测Fastjson的效率低于JGadgetInspector和 TGadgetInspector。Gadget Search设置的危险函数比TGadget Inspector全,在测试resin时GadgetSearch找到的从入口函数到危险函数的路径比TGadgetInspector多,导致GadgetSearch后续指针分析和污点分析消耗了较多的时间。
5.3 针对RQ3的实验
为了验证本文提出的混合分析方法的有效性,本文做了3组对比实验,分别利用调用图分析、混合信息流分析以及混合分析,实验结果如表10所示。在入口函数设置为toString和危险函数设置为Method#invoke的情况下,对JDK中的XStream利用链进行检测。实验结果表明,调用图分析效率最高,但误报数也最高。混合信息流分析在有限的时间(24 h)未能完成分析,混合分析误报数最低,同时运行时间在可接受的范围。混合分析的误报主要来自转移函数的黑名单不健全,污染了一些不该污染的返回值。
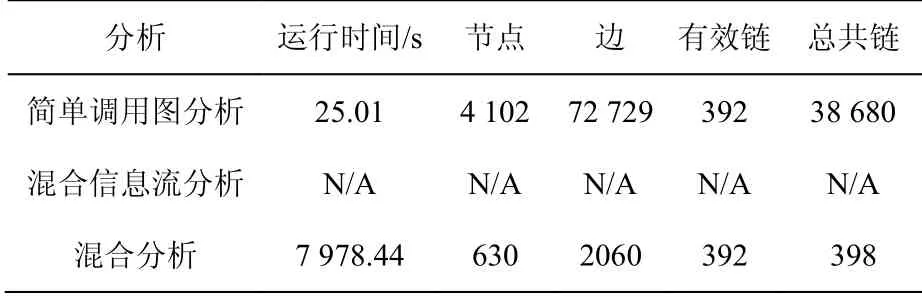
表10 3种分析对比实验结果Table 10 Comparison of experimental results
5.4 Dubbo Hessian反序列化RCE分析
下面将介绍GadgetSearch挖掘到了Hessian仅依赖JDK的反序列化利用链,并基于此利用链攻击Dubbo的全过程。Dubbo 是一个高性能、轻量级的开源服务框架。其默认支持Hessian作为其数据传输时序列化和反序列化的方式。Hessian在反序列化Map类型时执行map#put时会触发Object#hashCode,但是Object#hashCode调用范围比较小,未能找到可以利用的调用链。为了扩大利用链的搜索范围,寻找除了Object#hashCode以外新的入口函数。分析GadgetSearch的调用图,发现在执行HessianInput#readMap时会将反序列化之后的obj和字符串拼接,触发obj.toString() 函数,所以本文找到了一个新的入口函数Object#toString,如图8所示。

图8 Hessian 新入口函数 Figure 8 New entry point of Hessian
将Object#toString添加到入口函数重新运行GadgetSearch,输出了利用链如图9所示。MimeTypeParameterList#toString中调用了parameters. get(keys),parameters是类型为Hashtable的field,在反序列化时可控,可以设置parameters值为UIDefaults的实例,当执行parameters.get(keys)时,实际是执行UIDefaults# get,这样就从MimeTypeParameter List#toString这个gadget跳到了UIDefaults#get这个gadget。UIDefaults#get中调用了UIDefaults# getFromHashtable,在UIDefaults# getFromHashtable中,通过super.get(key) 获取了value值,由于UIDefaults继承了Hashtable类,并且UIDefaults值是攻击者可控的,所以取出的value也是攻击者可控的。如果value是LazyValue类型,则调用value.create Value(this)。因为value攻击者可控,所以可以设置value值为UIDefaults $ProxyLazyValue的实例,调用value.createValue(this)时,实际上是调用UIDefaults$ProxyLazyValue. create-Value(this),调到了UIDefaults$ProxyLazy Value# createValue gadget上。在UIDefaults$Proxy Lazy-Value# createValue中变量 className、args、methodName 均为field,所以可以从类名为className中获取方法名为methodName的方法,然后通过MethodUtil.invoke调用获取的方法,MethodUtil.invoke就是本文定义的危险函数。通过4个gadget,完成了从入口函数Object#toString到危险函数MethodUtil.invoke的调用。但是利用到此还未结束,还需要确定要调用哪个类的哪个方法,MethodUtil.invoke(method,obj,args)第一个参数是要调用的方法,第二个参数是调用的对象,第三个参数是要传的参数。在UIDefaults$Proxy LazyValue#createValue中能控制第一个参数和第三个参数,第二个参数无法设置为对应的对象。所以这里要调用class的方法,但调用class的方法没有什么危害。此外还可以调用静态函数,因为静态函数的调用,对对象没有要求,即使设置为null也可以。所以需要找一个有危害的静态函数调用。从所有JDK的静态函数中,找到了两个合适的静态函数,com.sun.org.apache.xml. internal.security.utils. JavaUtils#writeBytesToFilename和Java.lang.System# load,JavaUtils# writeBytesToFilename函数可以对任意文件写任意内容,System#load 可以加载so文件,在加载so文件时触发代码执行。所以可以将两者组合,利用JavaUtils#writeBytesToFilename在临时目录写入一个恶意的so文件,然后再用System#load加载该恶意的so即可触发命令执行。

图9 Hessian 反序列化利用链 Figure 9 Hessian gadget chain
6 结束语
本文提出了一种基于混合分析的反序列化利用链挖掘方法,并基于该方法实现了一款自动化挖掘Java反序列化利用链工具GadgetSearch,利用该工具发现了一条第三方库中的Jackson未公开利用链,4条JDK中的XStream未公开利用链,1条JDK中的Hessian未公开利用链。同时,在对比实验中GadgetSearch的误报率和漏报率远低于现有工具GadgetInspector。
