基于FT-MIR的三七粉末掺伪成分的定量检测模型研究
2022-04-15何凤芸杨晓东周胜灵谢林李光林
何凤芸,杨晓东,周胜灵,谢林,李光林
西南大学 工程技术学院,重庆 400715
三七又称田七、人参三七、金不换等,为五加科植物,主要产于云南、广西、四川,是一种应用于临床治疗的中药材[1].通过研究发现,三七不仅可以治疗咯血、衄血、外伤性出血、肿痛等症状[2],对冠心病、心绞痛、糖尿病、血栓等疾病也具有良好疗效[3].大量的科学研究表明,三七有效成分中不仅含有Rb1,Rd,Re,Rg1,Rg2,Rh1,R1,R2,R3,R4,R6,R7等人参皂苷,还包括77种挥发油、17种氨基酸、丹参碱、三七黄酮类和多糖等[4].三七的药用加工方式分为精加工(提炼萃取物)和粗加工(研磨成粉末)两类.为了尽可能降低成本和牟取最大化的利益,不法商人选择将三七粉与几种中药材粉末混合,在医药市场上以相同甚至更低的价格出售,不仅扰乱了市场秩序,还损害了消费者的利益和健康.为解决掺假问题,找出能够快速精确地鉴别三七粉末纯度的方法是非常必要的[5].
中国传统药材的光谱鉴定主要使用特定波长的光照射或扫描样品,获取特定的图谱数据.中药材光谱鉴别主要包括紫外光谱、红外光谱、荧光光谱、核磁共振和质谱等方法[6-7].傅利叶中红外光谱技术(Fourier transform mid-infrared,FT-MIR)能检测多组分因素,还具有扫描速度快、灵敏度高等优点,不需要与KBr等混合制样,无需压片,比近红外扫描获得的数据具有更高的完整度.由于FT-MIR具有检测精度高、分辨率高、应用范围广以及不需要对样品做预处理等优点,已广泛应用于预防医学、农业、生殖生物学等领域对样品进行定量分析.
图1为实验流程,实验使用标准正态变换(Standard normal variate,SNV)、基线校准(Baseline)等方法单独或组合进行原始光谱数据降噪及平滑; 协同区间(Synergy interval,Si)、竞争自适应加权算法(Competitive adaptive reweighted sampling,CARS)、连续投影算法(Successive projection algorithm,SPA)等方法用于挑选建模使用的特征变量; 最后分别建立偏最小二乘回归(Partial least squares regression,PLSR)模型及支持向量回归(Support vector regression,SVR)模型,再比较建模效果.甘草、合欢树皮以及向日葵花盘等药材粉末具有与三七粉末相似的外观和物理性质,仅凭肉眼几乎无法分辨他们的差别,这些药材的价格也远比三七低廉,因此常用于配制三七伪品.实验将20头纯三七粉末与甘草、合欢树皮和向日葵花盘等药材粉末分别按实验设计的10个掺比混合,并采集所有样品的FT-MIR光谱数据[8-9].

图1 三七粉末及其混合物伪品成分定量检测模型建立流程图
1 材料和方法
1.1 实验材料
实验所用样品包括采集于文山产区的20头三七1 000 g,购买于中药材市场的纯甘草超细粉末、纯向日葵花盘超细粉末、纯合欢树皮超细粉末各1 000 g.所有样本收集完成后均放置于50 ℃恒温环境中至质量保持恒定.使用研磨机将烘干后的三七样品粉碎后过200目筛,纯甘草超细粉末、纯向日葵花盘超细粉末、纯合欢树皮超细粉末烘干后也分别过200目筛,用精天FA1004A万分之一精度电子天平按表1的比例分别称取甘草、合欢树皮和向日葵花盘粉末与三七粉末放入玛瑙研钵中,用钵杵研磨使粉末混合均匀,每种比例制备35份样品,每个样品总质量为1 g,用于光谱数据采集.建立基于FT-MIR的三七粉末掺伪成分的定量检测模型,以实验样品掺伪成分的不同质量作为浓度变量,保持每一份实验样品总质量不变,以100%伪品药物粉末含量为基准,每次以0.1 g为增量梯度掺入三七粉末,同时减少0.1 g的伪品.
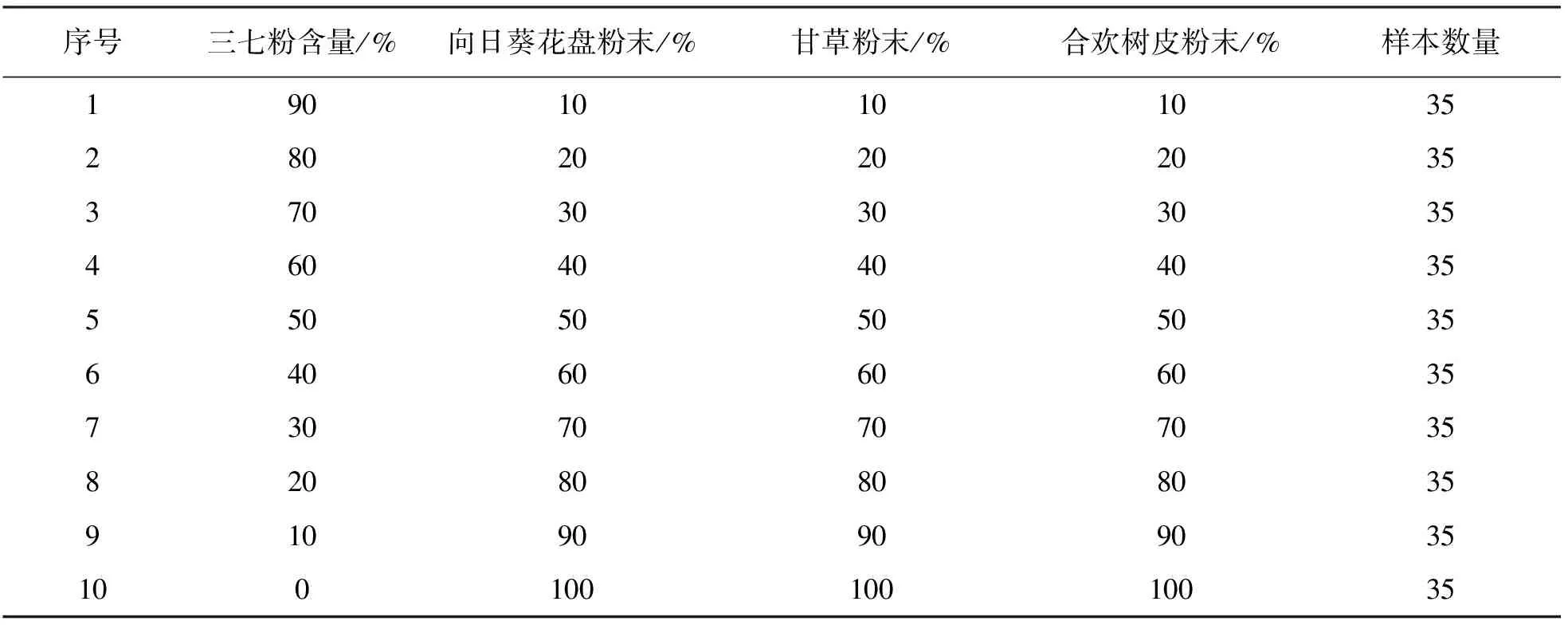
表1 三七粉末分别与向日葵花盘粉末、甘草粉末、合欢树皮粉末混合的比例
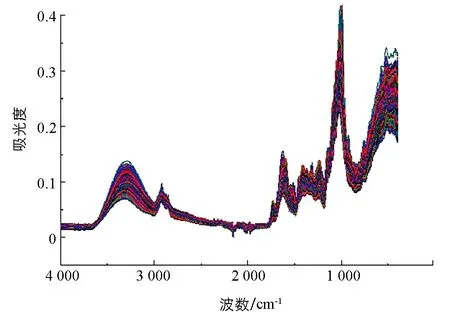
图2 三七及其伪品混合物的FT-MIR光谱
1.2 FT-MIR光谱数据采集
光谱数据采集使用的设备为傅里叶变换红外光谱仪(Thermo Fisher Scientific 5225 Verona Rd.Madison,WI 53711),光谱采集设备配套软件为OMNIC,初始化设置如下:分辨率设置4 cm-1; 设置自动大气背景扣除; 每间隔30 min重新采集一次背景信息; 扫描次数为32次,最终扫描结果取平均光谱.如图2所示,单个样品通过实验最终得到一条FT-MIR光谱.模型建立使用Random Sampling算法划分数据集,训练集与预测集划分比例为3∶1,训练集共787条光谱数据,预测集共262条光谱数据.光谱数据分析处理使用的软件包括MATLAB2018a,The Unscrambler X10.4,OriginPro 8等.
1.3 数据预处理和异常值剔除
原始光谱数据中常存在一些与待测样品性质无关的噪声信息,这些干扰信息会直接造成光谱数据的基线漂移.因此,有必要采用预处理方法消除噪声,将仪器或环境的干扰而随机引起的噪声信息最小化,提高样品光谱的信噪比.SNV和Baseline等方法[10-11]可有效地校正红外光谱数据,消除颗粒大小和分布不均匀对数据的影响,实验分别应用这两种光谱预处理方法及其组合方法对原始数据进行预处理后建立回归模型.
异常值是指样本中的个别值[12],其数值明显偏离所属样本的其余观测值,不属于同一总体,因此需要通过数据预处理及特征变量挑选减少它对实验结果的干扰.实验通过计算F值(F-residuals)和T值(Hotelling’s T2)并将此结果作为评判变量是否为异常值的标准.F值的大小即为样本和模型之间的差值,而T值则是表征模型对样本描述效果的评估.当F值和T值的计算结果超出置信区间[13]的5%,那么这个样本就可被视为异常值.实验中剔除了一条异常光谱,总计使用1 049条样品光谱,每条光谱含7 468个变量.
1.4 偏最小二乘回归原理及支持向量回归建模
PLSR是一种基于因子分析的多元校正方法,广泛应用于定量分析,集成了主成分分析、典型相关分析、线性回归分析的优点[14]; SVR[15]是在研究二分类问题的基础上提出的,旨在使所有样本点离超平面的总偏差最小.实验中全光谱数据、特征波段和特征变量被分别用于建立各自的PLSR和SVR模型,评价变量选择方法主要通过比较基于不同方法建立的模型效果,依据均方根误差(RMSE)和决定系数(R2)进行评估.

图3 三七、甘草、向日葵花盘、合欢树皮粉末光谱
2 结果与分析
2.1 FT-MIR特征
实验中使用FT-MIR数据,因此采集了波长范围400~4 000 nm的反射谱,用于后续数据分析和建模.全光谱可分为4个宽区域:X—H延伸区(2 500~4 000 nm)、三键区(2 000~2 500 nm)、双键区(1 500~2 000 nm)和指纹区(400~1 500 nm).图3为纯三七粉、纯向日葵盘粉、纯甘草粉、纯合欢皮粉的FT-MIR光谱,所有药材粉末的光谱特征都呈现出相似的趋势,有明显吸收峰的波长约1 008.84 nm和3 285.43 nm,这可能与C—H—O键和O—H键的对称振动有关.当样品受到红外辐射时,会产生反射、吸收等作用,所以物质浓度差的变化可以直接反映在能量变化上.
2.2 建模的特征变量选取方法
2.2.1 协同区间算法(Si)
Si可以结合多个高精度的局部区间来最小化模型中的变量数量[17].对于每个区间组合,以RMSE作为模型精确度的评价标准,选取RMSE最小的独立子区间建立PLSR模型进行预测.校正集RMSE为0.014 4,预测集RMSE为0.015 1,全光谱划分为20个子区间,此时经Si选择出的特征波段为第14,15,16,17,18个子区间,波长范围为759.815 9~1 658 nm,其中共含有1 864个变量.Si-PLSR方法选择的特征变量数与原光谱数据的全部变量数相比已大幅减少,但样本总量与压缩后的变量综合后,对于建模而言仍然是非常庞大的运算量,因此有必要对样品光谱的特征变量数进一步压缩.
2.2.2 竞争自适应加权算法(CARS)
与Si相比,CARS[18]是一种变量选择方法,因此覆盖面更广.CARS算法对于同样的数据集单次运行的结果会有些差异,即挑选出的变量及其数量略有不同,在此基础上建立的定量模型也会得出略微不同的评价结果.为得到尽可能精确的实验结果,数据经过120次CARS算法计算,综合计算结果选取RMSE值最小的变量选择结果为后续建模使用的理想数据.图4即为运行120次CARS算法后采用的最优结果,表示随采样次数增加,算法选择的特征变量在数量上会逐渐缩减; 图4(b)中曲线表示的是RMSE随采样次数的增加而改变的趋势,可以看出采样次数小于20次时,预测集RMSE稳定小于0.05,对应图4(a)特征变量数较多,而当采样次数大于20后,预测集RMSE明显增大,对应图4(a)显示变量总数趋于极小值,说明迭代过多后选择的特征变量过少,导致PLSR模型欠拟合; 图4(c)回归系数,展示了每次迭代各变量的回归系数值会随采样次数增加而波动的情况,每条曲线都代表着一个变量的回归系数,迭代结束后回归系数不为0的变量被CARS选中.
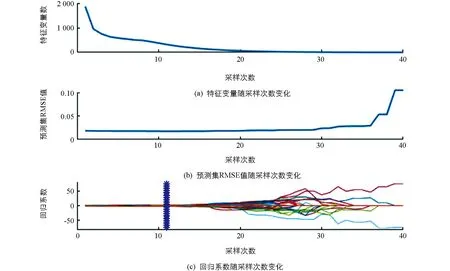
图4 CARS算法特征变量选择结果
从图4可以看到,随着CARS算法迭代次数在1~15区间时,特征变量数会急剧减少,预测集RMSE值则处于较低水平,回归系数此时同样没有明显变化; 当迭代次数处于15~30区间内,特征变量数量已降至最低,预测集RMSE在此阶段无明显变化,回归系数开始剧烈波动; 当迭代次数处于30~40区间内,预测集RMSE值急剧上升,这表明随着特征变量的减少,模型会欠拟合,大量回归系数经历振荡后波动幅值减小,逐渐收敛于零,也存在少量回归系数波动幅值持续增大.总体来看,当CARS迭代11次时,预测集RMSE的值最小,回归系数也处于稳定水平,对应图4(a)中选出的特征变量总数为321.

图5 SPA算法特征变量筛选结果
2.2.3 连续投影算法(SPA)
SPA是前向特征变量选择方法[19],变量选择的最终结果是最小共线性的变量组合,利用向量的投影分析,将波长投影到其他波长上,投影向量的大小决定其是否能够作为待选波长.实验在经过Si和CARS选择后每条样品光谱留存了321个变量,使用SPA算法可以在保持建模性能良好的前提下最大限度地减少变量数.算法迭代最佳结果校正集RMSE值为0.0210,预测集评价指标RMSE值为0.0286,这表明变量选择结果是合理的.图5为SPA算法特征变量筛选结果,此时样品光谱的变量总数压缩到了17个,分别为1 560.13,1 347.999,1 150.813,1 132.492,1 106.458,1 040.89,1 009.552,985.446 5,945.430 9,889.505 4,862.506 8,845.150 6,839.365 2,804.652 8,799.831 5,786.332 3,759.815 9.
2.3 PLSR与SVR模型比较
表2总结了不同变量选择方法的建模结果.通过采用Si和CARS及SPA得到的光谱变量建立PLSR和SVR模型,并利用模型结果评价变量选择的效果.所有模型的决定系数均在0.97以上,表明所建立的模型具有较好的预测效果,也表明中红外光谱技术适用于三七粉末成分定量检测.由表2的实验结果对比可知,SVR模型在各个变量选择方法基础上的性能表现均优于PLSR模型.三七粉末PLSR模型预测性能最优的是Si-CARS-PLSR模型,校正集RMSE值为0.024 4,R2值为0.992 8; 预测集RMSE为0.024 7,R2值为0.992 7.PLSR模型的校正集与预测集的RMSE均小于0.046,决定系数最小值为0.975 1.三七粉末SVR模型预测性能最优的是CARS-SVR模型,校正集RMSE值为0.019 9,R2值为0.9955; 预测集RMSE为0.020 5,R2值为0.994 1.SVR模型的校正集与预测集的RMSE均小于0.024 0,R2最小值为0.983 3.在PLSR模型中,与其他变量选择方法相比,CARS可以选择回归系数绝对值较大的波长点去除权重较小的波长点,通过交互验证选择RMSE值最小的子集,可以有效地求出变量的最优组合.在SVR模型中,CARS变量选择方法对于三七粉末成分表现了最好的预测结果,显著减少了模型的光谱变量数,同时提高了模型的效率和准确性.
3 讨论
光谱技术已经较为广泛应用于三七质量检测方面,Nie P C等[20]将三七粉末掺入苦参粉和玉米粉,使用可见光光谱和近红外光谱分别建立了PLS模型和最小二乘—支持向量机(LS-SVM)模型.实验结果表明,近红外光谱技术适用于三七粉末的定量检测,然而针对不同批次的检测样品,使用近红外数据建立的判别模型泛化能力有待提升.Chen H等[21]使用了苦参粉、玉米粉分别依照不同比例掺入纯三七粉末中,采集近红外光谱数据,在此基础上建立CARS-PLSR模型进行定量分析,实验结果表明,基于特征变量建立的PLSR模型效果优于基于全光谱变量建立的PLSR模型.三七粉几乎不溶于水,而玉米粉加入水中溶液会变浑浊,因此可通过观察粉末加水后的溶液清澈程度进行判断.目前,适用于光谱数据的定量分析模型多种多样,如人工神经网络(Artificial neural network,ANN)、多元线性回归(Multivariable linear regression,MLR)、极限学习机(Extreme learning machine,ELM)、BP神经网络[22]、PLSR和SVR等,使用的PLSR和SVR模型具有稳定性好、适用范围广等优点.三七及其伪品的光谱数据特征选择过程是:首先将原始光谱划分为20个子区间,使用Si选出特征波段,使用CARS从特征波段中选择初始特征变量,使用SPA选出最终特征变量,使定量模型尽可能精简.
每条原始光谱往往包含几千个变量,其中大多数都是不表示研究对象特征的冗余信息,使用原始光谱建模会降低模型预测效果,选用的特征变量选择可以较好地保留原始数据中潜在的语义信息,减少建模运算量.三七及其伪品的光谱数据特征变量选择过程即首先将原始光谱划分为20个子区间,使用Si选出特征波段,再结合CARS从中选择特征变量,最后利用SPA将特征变量数压缩至尽可能小.实验完成了快速识别以及三七粉末及其伪品混合物的定量检测,包括数据预处理、特征波段提取、特征变量选择以及定量模型评估等,SNV和Baseline等方法单独或组合用于原始光谱数据降噪及平滑; Si,CARS,SPA等用于挑选建模使用的特征变量; 最后分别建立PLSR及SVR模型.
4 结论
实验结果表明,FT-MIR是定量检测三七粉末掺入伪品的有效方法.实验采用Si,CARS和SPA 3种变量选择方法来提高模型的稳定性和预测精度,其中基于CARS方法挑选的特征变量训练的SVR和PLSR模型对三七粉成分检测都有较好的预测效果.对比两种建模结果可知,SVR在使用相同变量时建模精度优于PLSR,实验中建立的所有三七粉末及其混合物伪品成分定量检测模型准确率最高的是CARS-SVR模型,评估参数校正集R2值为0.995 5,校正集RMSE值为0.019 9; 预测集R2值为0.995 2,预测集RMSE值为0.020 5,该模型的建立基于254个特征变量,数据量仍有进一步压缩的空间.CARS-SPA-PLSR/SVR模型使用了数量最少的特征变量,与原始光谱的建模结果比对,即使是变量数从7 468减至12个,其建模效果仍优于全光谱.原始光谱数据在经过特征变量选择后,不仅可提升建模精度,还能优化建模速度,为实际生产应用提供了可行稳固的方案.SNV-Baseline作为数据预处理方法有效消除了原始光谱数据中的噪声信息,使用变量选择方法CARS方法可以极大地压缩特征变量数目,优化建模效果.实验表明,CARS-SPA-SVR模型具有实际应用潜力,对今后的三七粉末质量分级、检测和筛选具有重要意义.
