基于Mask R-CNN的密集木材检测分割方法
2022-04-15杨攀郑积仕冯芝清丁志刚李少艺黄其悦孔令华
杨攀,郑积仕,冯芝清,丁志刚,李少艺,黄其悦,孔令华
(1. 福建工程学院计算机科学与数学学院,福州 350118; 2. 福建工程学院交通运输学院,福州 350118;3. 福建金森林业股份有限公司,三明 353300; 4. 福建工程学院机械与汽车工程学院,福州 350118)
木材是可再生能源之一,高效开发森林中的木材资源,有着重要的经济和环境效益。目前,国家林业和草原局积极推动林业生产各环节往信息化和智能化方向发展[1]。木材检尺是指检测原木或原条的尺寸和缺陷以确定其材积和等级的计量作业,它作为木材经济发展的基础,是木材经济信息化和智能化的关键。传统人工检尺方法的成本高、效率低、主观性强,且检尺结果无法可视化,无法适应现代化木材加工和销售的发展趋势。
随着计算机视觉技术的发展,基于传统图像检测分割方法检测图像中的木材数目基本实现。如钟新秀等[2]结合K-means聚类和Hough圆变换[3]完成原木计数。传统木材图像检测方法要求图像质量稳定且去除背景干扰,通常木材漏检测问题严重,深度学习图像检测技术的进步使得木材检测正确率得到保证。Samdangdech等[4]提出了一种将单发多盒探测器[5](SSD)目标检测模型和全卷积网络[6](FCN)语义分割模型相结合来实现车载桉树图片分割的方法,木材计数正确率达到94.45%,但对遮挡和分裂木材的分割效果不理想;Tang等[7]利用SSD在自然场景下检测原木,计数准确率为94.87%,为特定场景下木材计数奠定基础;林耀海等[8]开发了一种结合YOLOv3-tiny[9]目标检测模型与Hough圆变换的等长原木材积检测系统,少样本测试中,系统木材真检率为98.79%,误检率为0.602%,该系统更适用于大径级圆形原木检测。
现有木材检测研究聚焦于中等和大木材的检测,对混合尺寸及小木材检测研究比较缺乏,小目标检测同属深度学习难题。为了提高木材综合检测效率,提高小木材的检测分割性能成为必要,笔者采用深度学习的方法探究实例分割模型对各尺寸木材端面分割的可行性。掩模区域卷积神经网络(Mask R-CNN)[10]是一种通过训练标注图像,能对多类或同类目标多个实体进行像素级分割的实例分割模型。本研究采用Mask R-CNN对包含泥土、树枝、树叶等复杂背景下的木材端面进行分割,针对小木材检测难题,改进优化多种模型参数,并在多个维度对木材分割准确性进行定量分析。这一研究将为复杂背景下混合尺寸木材分割算法提供参考,同时为木材材积自动测量提供算法支持。
1 材料与方法
1.1 图像采集与图像预处理
实验数据采集于福建金森林业股份有限公司某木材货场,考虑样本多样性,通过工业相机和手机相机等设备采集了500张木材图片,包括不同光照条件、不同木材端面背景和不同拍摄角度下的图片。Mask R-CNN属于有监督学习模型,需要对图片中木材轮廓进行标注。剔除模糊图片,共保留150张清晰图片,通过Labelme软件对图片中所有木材使用多边形标注工具进行轮廓标注,标注效果如图1所示。其中木材标注信息可提供模型学习木材轮廓特征,可根据木材轮廓掩码图实现木材计数。

图1 木材轮廓标注效果Fig. 1 Outline marking effect of stacked logs
将全部标注图片按照4∶1∶1的比例划分为训练集、验证集和测试集,按照COCO数据集的目标尺寸划分方法(小目标:像素面积<32×32;中等目标:32×32<像素面积<96×96;大目标:像素面积>96×96)对标注数据集进行统计,如表1所示。
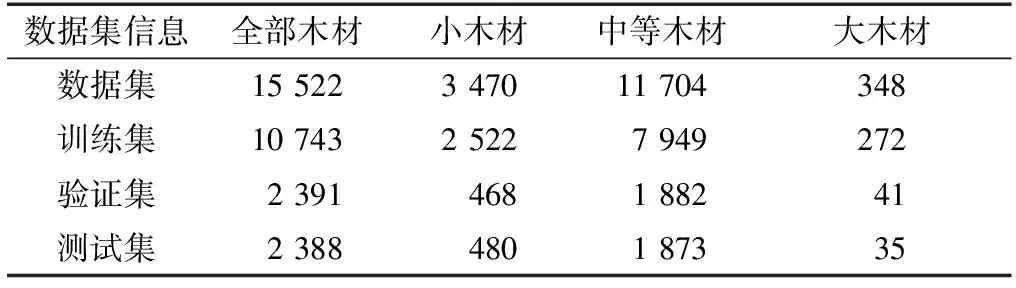
表1 标注数据集木材统计信息Table 1 Log statistical information of annotated data set
为了提高模型泛化性能及满足深度学习模型对数据样本量的要求,本研究通过裁剪、模糊处理、图片色彩通道处理、增强对比度、锐化、增加干扰噪声等技术进行数据增广,丰富数据样本。数据增广后,训练集图片数据量最多可达1 600张。
1.2 实验方法
1.2.1 Mask R-CNN基本原理
Mask R-CNN是由He等[10]通过升级更快速区域卷积神经网络[11](Faster R-CNN)目标检测模型得来,在其基础上增加了Mask分支,并用ROI Align改进原有ROI Pooling模块,解决了Faster R-CNN区域匹配存在误差的问题。故Mask R-CNN同时具备目标分类、目标检测和像素级分割的功能,能实现对同类别不同实例的分割,满足木材检测分割的功能需求。
Mask R-CNN的基本原理框架如图2所示。其主要分为主干网络(Backbone)、区域候选网络[11](RPN)、ROI Align和R-CNN 4个模块。Backbone通常由残差网络[12](ResNet)和特征金字塔网络[13](FPN)构成,FPN对ResNet输出的5层特征图进行融合,获得更丰富的木材特征图并输出到RPN和ROI Align模块。RPN的作用是生成目标候选区域,完成特征图中前后景目标分类和边界框回归,获取前景目标粗略位置。ROI Align模块利用最大池化操作对Backbone输出的特征图和RPN输出的目标候选区域进行匹配,完成特征图特征聚集并池化为固定大小,再经过全连接层输出到R-CNN模块。R-CNN模块共3个分支:第1分支通过softmax分类器实现木材分类;第2分支经过边界框回归器实现更精确的木材位置定位;第3分支通过FCN完成木材轮廓分割,生成木材分割掩码。最后,将各分支输出信息进行综合,得到一张包含木材类别、木材定位边界框和木材分割掩码的图像。

图2 原木实例分割模型结构图Fig. 2 The structure diagram of the log instance segmentation model
1.2.2 优化Mask R-CNN
本研究检测分割目标为密集木材,类别单一,其中数据集中小木材占22.36%,平均每张图片包含103根木材,故本检测任务属于密集目标和小目标检测。原始Mask R-CNN对本任务中的小木材检测分割效果欠佳。为了改善模型对密集小木材的检测性能,本研究对原始模型进行了改进优化。
1)优化RPN和R-CNN模块中样本采样数。原始Mask R-CNN中RPN和R-CNN模块中样本采样数分别为256和512,其中在RPN和R-CNN模块中正样本采样率(即特征图中所有目标的前景目标采样率)分别为0.5和0.25,均采集128个正样本。但平均每张图片包含103个目标,故模型在现有采样数下,难以充分学习103个目标的全部特征,此为模型精度提高的瓶颈之一。提高RPN和R-CNN模块中的采样数,更多的正样本数,携带更丰富的木材特征,充分学习后,有助于提高模型精度。
2)优化图片输入尺寸及多尺度训练。本任务中木材数据集的分辨率为1 600×1 200,原始Mask R-CNN的图片输入尺寸为1 333×800,以尺寸短边为依据进行说明。这意味着原始图片中的木材尺寸在输入模型后会降低55.6%。同样,若将图片输入尺寸提升50%,即2 000×1 200,这意味着原始模型中的目标尺寸将提升125%。此外,可以采用多尺度训练技巧,将图片输入尺寸变为多个尺度,每个图片批次随机选取一个尺度送入模型进行训练。这两种方法十分有利于各尺寸目标的特征学习,尤其是小目标的特征提取,一定程度上能提高模型的检测能力。
3)优化数据增强。本木材图片数据均于卡车装载木材的场景下采集,图片中木材基本呈对称装载。故在图片数据送入模型训练前,进行一定概率的水平翻转,符合图片实际采集场景。结合1.1节介绍的数据增广,有效选择数种图像增广方法,既弥补了数据量不足的缺陷,又对图片采集场景进行模拟扩充,能有效提高模型泛化性和鲁棒性。
1.2.3 模型训练参数配置
在Windows10操作系统下,使用RTX3090显卡,采用MMDetection[14]完成Mask R-CNN模型的训练。模型训练时首先采用在COCO数据集上训练好的预训练权重进行迁移学习完成网络参数初始化,再将自标注的木材数据集转化为COCO数据集格式后送入网络进行训练。
为了探究不同模型优化方法对模型训练精度的影响,将各种优化方法单独或叠加配置,形成不同组合如表2所示。表2中训练优化方法包括Baseline、Aug4、Aug16、512+1 024、1 024+2 048、2 000×1 200、MS6和MSR。其中:Baseline表示RPN和R-CNN模块中的采样数为256和512,并且模型输入图片尺寸为1 333×800;Aug4和Aug16分别表示数据增广4倍和16倍;512+1 024和1 024+2 048 分别表示在RPN和R-CNN模块中的采样数;2 000×1 200表示模型输入图片的尺寸;MS6和MSR参数均表示进行多尺度训练,括号中的1 333×800和2 000×1 200表示最大尺度,在每个图片批次中MS6和MSR分别在最大尺度下的6种尺度和多种尺度中随机选择一种尺度进行输入训练。

表2 模型优化方法组合Table 2 Model optimization method groups
根据本试验的检测需求,其他通用训练配置参数为:目标类别数为1,检测类别为“wood”;为提高网络的运行效率,选用ResNet50作为Backbone;采用线性修正单元(ReLU)[15]作为模型的激活函数;训练参数配置中BatchSize数设置为1,数据加载线程数为2;训练Epoch数为36,初始学习率为0.01,且前500次迭代中设置线性变化的Warm up,以稳定训练初期的参数梯度,并基于随机梯度下降法[16](SGD)进行梯度优化传递。此外,在Epoch数分别等于12,20和28时,进行学习率乘以0.1倍的下降策略。

图3 部分模型方法的实验测试结果Fig. 3 Experimental test results of some model methods
1.3 评价指标
为了更全面、客观地评价分析优化后的Mask R-CNN对木材检测分割的可行性,本试验采用平均精度均值(mAP)、掩码交并比(IoUMask)和木材识别率这3种指标评价木材检测分割结果。这3种指标数值越大,模型木材检测分割效果越好。
1.3.1 mAP指标
本研究采用COCO数据集定义的目标检测和实例分割模型通用评价指标——mAp对不同IoU阈值下的模型训练精度进行统计。这里的mAP_s、mAP_m和mAP_l分别表示目标尺寸在小、中、大3个级别时的平均精度均值,而单独的mAP表示IoU阈值自0.5到0.95,间隔0.05进行统计的均值结果。
1.3.2 IoUMask指标
虽然mAP对深度学习模型有很好的表征性能,但mAP更适合于评价分类置信度,对Mask的实际分割质量尚无法进行评估。针对这一问题,本试验借鉴文献[17]中的做法,选用IoU值对Mask的质量进行评估。IoUMask的计算方式为:
(1)
通过计算模型推理的木材Mask区域(P)与人工标注的木材轮廓区域(G)之间的交并比,用IoUMask值来定量评估Mask的质量,从而进一步衡量模型对木材轮廓分割的精确度。
1.3.3 木材识别率指标
本研究其中一个目标在于木材识别计数,模型对木材的识别率越高,则模型检测性能越好。木材识别率包括木材检测率和木材真检率。本研究根据模型输出的木材分割掩码分别统计测试集木材图片中所检测出的小中大各尺寸木材的数量、误检木材数量、漏检木材数量和真检木材数量,同时结合测试集木材的实际数量统计信息,计算模型木材检测率和真检率。
2 结果与分析
2.1 木材分割对比实验结果分析
为了验证优化后Mask R-CNN对木材检测分割的可行性,本研究按照1.2.3节所述的多种模型优化方法及文献[4,8]方法进行训练,共分成32组,形成对照,部分模型方法的实际木材检测分割结果如图3所示。为了验证模型在整个测试集上的泛化性能,本研究统计了这32组方法在木材测试集上的掩码分割精度及掩码的IoU分数,如表3所示。从图3可以发现,该测试图中小木材的检测分割数量在方法1的基础上得到了不同程度的提升,这说明1.2.3节所述的不同参数优化方法对较小木材的检测性能有一定的改善。
在表3中,对比优化方法(1~3),可以发现在Baseline的基础上对模型进行多尺度训练,mAP最大提升0.3%,mAP_s提升1.4%;对比组合(1,4,5),RPN和R-CNN中样本采样数为512和1 024时,mAP、mAP_s和mAP_m分别提升0.4%,5%和0.6%;对比组合(1和10),提升图片输入尺寸为 2 000×1 200,mAP、mAP_s和mAP_m分别得到2.5%,11.7% 和2.9%的巨大提升;对比组合(15~18),在无数据增广的条件下,提升图片输入尺寸、MS6的多尺度训练,提升RPN和R-CNN中采样数为512和1 024 时,组合15的mAP达到68.4%,同时mAP_s、mAP_m和IoUMask相较Baseline分别提升12.7%,3.3% 和0.9%,但是mAP_l却比较低,对大木材的检测效果欠佳。考虑到大木材数量仅占训练集木材总数的2.24%,可能模型对大木材的检测存在欠拟合,故本试验对训练集图片分别进行了4倍和16倍的图像增广。基于组合(1~18)中对小目标和中等目标的检测性能有所改善的方法项,本试验设计不同数据增广倍数的方法组合,详见组合(19~30)。结合参数组合(1,19,25),可以发现随着数据增广倍数的增加,mAP_l同步提升。比较方法组合(19,23,24,25,29和30),数据增广后,提高图片输入尺寸、提高模块采样数、多尺度训练,都对mAP有着不同程度的提升,同时数据增广倍数越大,模型的IoUMask分数越高,分割掩码质量越高。在方法30中,IoUMask较Baseline有着2.2%的改善。
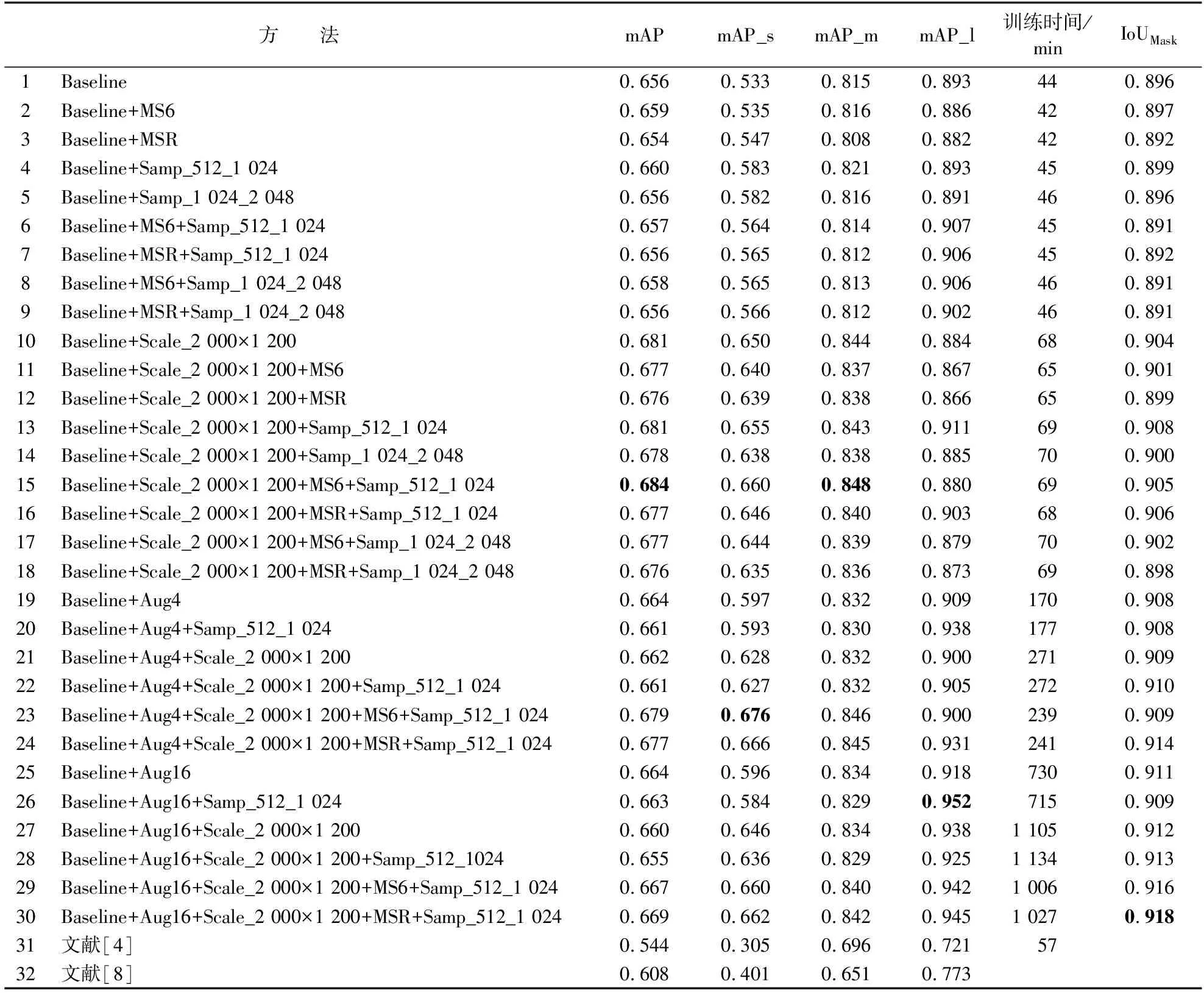
表3 不同模型方法在测试集上的掩码分割精度Table 3 Mask segmentation accuracy of different model methods on the test set
在模型训练耗时方面,从表3可见MS6和MSR的多尺度训练方式并不会增加模型训练时间成本,而增加样本采样数会略微增加训练耗时,增加图片输入尺寸则会成比例的增加训练耗时,但是这些方法均可在70 min内完成模型训练。对训练图片进行不同倍数的数据增广,则训练时间成本将以相同倍数增加,但模型泛化性能也进一步增强。
2.2 木材检测性能对比实验结果分析
mAP和IoUMask是对模型检测分割性能比较系统的评价指标,然而最直观、有效的验证方法是对测试集中木材数量的检测。本研究使用OpenCV库完成对Mask R-CNN木材分割掩码的轮廓查找、圆形轮廓拟合及轮廓计数,部分模型方法计数结果如图4所示。其中,计数图左上角打印了图片中木材的统计结果(等号左侧数字表示木材总数,等号右侧3个数字分别表示小、中、大3种尺寸木材的统计数量),并用蓝绿红3种颜色的圆或矩形框对小、中、大各尺寸木材进行定位标注,标注圆或矩形框中的数字表示识别的木材序号。此外,本试验对具有最高mAP和最大IoUMask分数的两组方法模型的木材检测性能进行统计,获得模型的木材检测率和木材真检率分别如表4和表5所示。

图4 人工标注及部分模型方法的木材检测计数结果Fig. 1 Log detection counting results of manual labeling and some model methods

表4 不同模型对各尺寸木材检测性能统计Table 4 Statistical analyses table of the detection performance of different models for various sizes of logs

表5 不同模型对木材真检性能统计表Table 5 Statistics table of the real inspection performance of different models on wood
对比表4中测试集实际木材数量和模型检测数量可以发现,优化后的模型相比Baseline模型,对各尺寸木材的检测性能均有较大提升,尤其小木材的检测性能提升明显。图4中漏检小木材也逐渐减少,模型木材检测率从94.681%提升到98.827%。但是模型存在一定的误检测,即可能将与木材相似的目标误识别成木材。从表5可以发现,Baseline模型的木材真检率仅为94.430%,而mAP最高的方法15的真检率最高,为98.073%,但是误检率也较高,为0.76%。相比之下,IoUMask分数最高的方法30,经过16倍数据增广,木材轮廓特征得到更充分的学习,其误检率仅为0.30%,且真检率为97.989%。从图4中也易于发现,方法30的模型木材检测结果最接近人工标注结果,检测率更高,漏检更少。综合实际应用考虑,方法30模型更优。此外,从图3~4、表3~5均可看出,相较文献[4]和文献[8]方法,本研究方法对各尺寸木材的检测性能更佳。
综合上述32组实验结果和对部分优秀模型3个维度指标的分析结果可以看出,进行多尺度训练、扩大模型样本采样数、提高图片输入尺寸和有效的数据增广对模型各尺寸木材的检测性能都有一定的提升,叠加使用,提升更加明显,具有较好的木材检测能力,且能适应多尺寸密集木材检测场景。
3 结 论
为解决人工检尺方法中的效率低下且检尺主观性较强的问题,提出一种基于Mask R-CNN实例分割模型的木材分割方法,并针对存在的小木材检测难题,提出4种模型优化方法,探究实例分割对木材密集堆放场景下各尺寸木材的分割的可行性,以期实现智能检尺,提高检尺效率。在木材数据集上进行了32组对照试验,并对实验结果进行分析,得出以下结论:
1)使用多尺度训练、提高模型RPN和R-CNN模块样本采样数可以有效改善小木材检测性能。
2)提高图片输入尺寸,对小木材和中等木材的检测性能有较大提升。
3)有效的数据增广,对模型各尺寸木材的检测能力均有一定提高。
4)4种优化方法的叠加使用,对各尺寸木材的检测分割性能提升最大。与原始Mask R-CNN Baseline模型相比:mAP提高1.3%;mAP_s提高12.9%;mAP_m提升2.7%;mAP_l提升5.2%;IoUMask分数提高2.2%,达到91.8%;木材真检率提高3.559%,达到97.989%;误检率仅为0.30%。优化后的模型对密集场景下各尺寸木材有着良好的检测分割性能。
在现有工作下,模型对密集木材检测分割性能尚有一定的提升空间,如改善Backbone特征提取能力、提高标注数据集的数量量级和改善数据集的标注质量等。
