WSN中基于BP神经网络的数据融合算法优化
2022-04-12张志驰
王 军, 张志驰
(沈阳化工大学 计算机科学与技术学院, 辽宁 沈阳 110142)
无线传感器网络(wireless sensor networks,WSN)以传感器为传输节点,将其大量分布在所要监控的区域内,对信息进行采集、传输和处理,形成一个智能型综合网络信息系统[1].近年来,随着硬件设备性能的提升,已有部分装置应用在WSN上,用于工业和农业生产,并且在环境监测、医疗护理、目标跟踪等领域迅猛发展[2].而WSN节点能量有限,不能随时更换电池,如何高效地减少能耗、延长网络生命周期成为其最主要的研究目标之一[3].
数据融合技术通过特殊的信息获取手段,对收集到的数据进行传输、分类、汇总、再生成,最终达到对各领域应用实现审核、查询以及辅助决断[4].利用数据融合技术可以对冗余数据进行筛除,降低无效信息量,节约网络传输能耗,提高数据的精准度和可信度[5],以此延长网络生命周期.
有学者将BP神经网络模型引入WSN来处理数据融合问题[6].但是BP神经网络收敛速度慢,训练能力差,样本依赖性高,在实际应用中受到诸多因素影响.王华东等[7]采用蝙蝠算法对BP神经网络的模型结构、参数和收敛速度进行优化,提出了一种基于蝙蝠算法的在神经网络模型中的数据融合策略 (BPNN data fusion,BPDF),有效提高了节点存活率.黄廷辉等[8]设计了一种萤火虫算法(firefly algorithm-BPNN,FA-BPNN),优化了BP神经网络的求权值矩阵,在一定程度上提高了数据融合的效率.余修武等[9]提出了一种改进蚁群的BP神经网络数据融合算法(information fusion algorithm based on improved ant colony optimization BP neural network in WSN,IFA-IACOBP),通过对蚁群算法启发因子的改进,优化了蚂蚁下一跳节点选择概率,对网络生命周期有一定的延长.
在经典的BP神经网络模型中,由于误差函数本身的复杂性,导致网络节点训练时间过长和震荡现象的出现.为了加快训练速度,降低感知节点传输的数据量,提高能量利用率,本文提出一种基于BP神经网络的WSN数据融合算法——ALR-BPDFA算法(adaptive learning rate back-propagation data fusion algorithm,ALR-BPDFA),对节点收集的冗余数据进行数据融合,减少传输能耗,从而延长网络生命周期.
1 BP神经网络
1.1 BP神经网络模型
BP神经网络是一种多层前馈式网络,它的结构主要包括输入层、隐含层和输出层.多层BP神经网络含有正向传播和反向传播两个过程.通过正向传播时,输入信息从输入层到隐含层逐层处理,并传向输出层,每一层神经元的状态只影响下一层神经元的状态[10];如果在输出层不能得到期望输出的结果,则进行反向传播,将误差信号沿着原来的连接通道返回,通过修改各层神经元的权值,最终减小误差.BP神经网络结构如图1所示.

图1 BP神经网络结构
相关研究已经证明,只要隐含层节点数充足,具有3层的BP神经网络就拥有模拟复杂非线性映射的能力[11].在神经网络模型中,其中研究的重点在于如何提高其非线性逼近能力和学习能力;而神经网络的学习流程则是通过样本点集得到一个学习误差函数,然后优化这个函数.
误差函数如公式(1)所示.
(1)
将隐含层和输入层的神经元函数逐步加入误差公式(1),可得误差函数如公式(2)、(3)所示.
(2)
(3)
从上述函数公式可知,误差函数是由预测输出与实际输出之间的误差值组成,各个隐含层的误差函数都与前一层的误差传播信号相关,全部是由输出层的误差逐层反向传播而来.
1.2 BP神经网络算法
BP神经网络算法为一种监督式的学习模式,主要思路是通过梯度搜索技术对已经存在的网络入侵样本进行学习,最终使网络的实际输出值与期望输出值的均方值误差达到最小[12].梯度下降法是常规的学习标准,通过运用反向传播的方式不断调整网络的初始权值和阀值,最终使网络的误差平方和达到最小.其基本的学习思路如下:
(1) 初始化网络的连接权值.将其设置为wij和wjk,阈值为θj和θk.
(2) 随机选择第k个输入样本和与其对应的期望输出.
(3) 计算隐含层单元输出yj、输出层输出yk:
(4)
(5)
式中:wjk为隐含层第j个神经元到输出层第k个神经元之间的连接权值;xk则为输入值.
(4) 计算输出层与隐含层之间的训练误差δk和δj,式中dk为真实值.
(6)
(5) 修正权值
wjk(t+1)=wjk(t)+ηδkxj,
wij(t+1)=wij(t)+ηδkxi.
(7)
式中:η表示为学习率的大小;wjk为隐含层与输出层的权值量;wij为输入层与隐含层的权值量.
(6) 判断平均方误差e是否满足所规定的通过误差:当e符合条件时,则跳到步骤(7);若不符合,则转向步骤(4).
(7) 算法结束.
BP神经网络算法分为训练过程和学习过程[13],其流程如图2所示.在运行训练过程时需要初始化处理BP神经网络:各层权值随机赋值,范围为(-1,1);学习速率η=(0,1),训练次数r=1,对误差精度Emin赋值.初始化结束后,将训练样本的输入向量与实际输出填入设计完成的BP神经网络模型,运行BP神经网络中的反向传播阶段,调整各层权值.

图2 BP 神经网络算法流程
所有样本进行一次训练后,训练次数加1,在训练次数达到预设值并且误差值达到设计精度时,样本训练结束,随后进入样本学习阶段.如果输出总误差没有达到所设精度,则对样本重新训练,直至训练结果与预测值相符合.
2 基于神经网络的数据融合算法
在无线传感器网络中加入BP 神经网络模型的数据融合技术,称为BPDF(BPNN datafusion) 算法,BPDF 算法模型结构如图3所示,主要应用于LEACH分簇路由协议[14].网络训练及数据融合步骤如下:
步骤1 对整个无线传感器网络进行分簇,簇头节点向Sink节点传输簇内节点成员信息表,各层节点将监测到的数据发送给与之对应的簇头节点;
步骤2 Sink节点根据簇头和簇内节点的基本信息,创建BP神经网络的模型架构;
步骤3 对簇头节点和相应的簇内成员节点间应用BP算法对数据进行融合操作,在融合开始时先对每个感知节点将监测到的数据通过输入层的神经网络函数算法进行初始处理;
步骤4 将处理后得到的结果传输给其他的簇头节点,簇头节点再根据隐藏层的神经元函数和输出层的神经元函数进行后续的数据处理;
步骤5 通过簇头节点将处理后得到的数据发送给基站,同时更新样本数据库.

图3 BPDF 算法模型结构
对基于神经网络的数据融合算法的影响因素有很多,也衍生出了诸多的优化策略.例如:通过增加隐含层的节点数来优化BP神经网络模型;为了避免训练时间过长和震荡现象的出现,对学习速率进行动态化设置;为了减小误差,对经典的激励函数Sigmoid函数进行改进[15];为了使训练后收敛达到最优状态、输出误差达到最优解,对各层神经元之间的初始权值进行优化.
本文结合文献[16]提出的数据融合思想,充分利用BP神经网络的优点,根据有差异的融合思路对收集的信息执行过滤和优化处理,最终在网络中实现数据融合.BP神经网络的数据融合流程如图 4 所示.

图4 神经网络数据融合流程
网络训练前期准备工作:对数据进行归一化处理,目的是为了确保网络层中的输出值在一个正常的范围内.在设定好了训练样本集的初始值后,采用梯度下降法调整中心向量、宽度、网络系数以及最后一层的初始权值.在训练过程中,优先选择较快的学习率,如果误差函数变大则需要及时调整学习速率,保证数据的准确性.
3 ALR-BPDFA算法
3.1 ALR-BPDFA算法工作流程
在ALR-BPDFA (adaptive learning rate back-propagation data fusion algorithm)算法中,首先,要在网络中设置某些预参数的值,其中包括连接的初始权值和阈值等数据.当网络的分簇结构稳定后,开始对神经网络进行训练,进而获得对应的部分训练参数.其次,Sink节点将网络中各层的训练参数发送给对应的成员节点,各个簇首利用训练好的BP神经网络模型进行数据融合处理,最终再把处理好的数据以最短路径传送给Sink节点.ALR-BPDFA算法流程如图5所示.

图5 ALR-BPDFA算法流程
3.2 簇首选取及分簇
在选举簇首的过程中,考虑节点当前剩余能量这一因素.根据计算的T(n)值,使当前能量较高的节点优先当选为簇首,同时记录当前剩余能量第二高的节点,并将其设置为辅助簇首节点.分簇及簇首选取流程见图6.

图6 分簇及簇首选取流程
T(n)的计算方法如下:
(8)
式中:p是节点成为簇头的概率;r是目前已经完成的轮数;G是在最近1/p轮时还没有被选为簇头的节点集合;u是反映当前节点能量对T(n)影响程度的参考量,当节点能量较小时,能量因素的影响就比较小,反之也是如此.
通过设定系统参数Nmax的方式限制每个簇的最大节点数,从而限制成簇的规模.在此基础上,笔者提出一种结合计算最优簇首数的方式进行动态分簇的理念,具体形成过程如下:当簇首节点和辅助簇首节点依序产生后,簇首节点向自己一跳范围内的所有节点广播自己成为簇首的消息,同时所有节点根据节点ID号以及信号的强度计算与簇首的距离,记为RSSI,成员节点通过RSSI值采取就近原则,接收离自己最近的簇首节点所发出的广播信息,并向该簇首发送加入消息.
最优簇首数计算公式为
(9)
因为簇首节点能量不一,所以根据各个簇首节点的当前能量值T(n)来限制每个簇的节点个数,能量大的簇首分配的节点多,小的则少,进行以能量为参照标准的非均匀分簇模式.
3.3 改进的自适应学习率
通常对学习率的设置都以稳定较缓的固定模式为主,保证最后解的结果不出现较大的误差.这样就可能导致在不同的环境下出现学习效率低、速率慢的弊端,从而加大了能量的损耗;而在实际的应用中,确定一个最万能的学习率是不现实的.所以,为了加速收敛过程,一个比较好的思路是使其自适应地改变学习速率.自适应学习率算法简化流程如图7所示.

图7 自适应学习率算法简化流程
改变学习率的方法有很多,其最终目的都是使学习速率在训练过程中得到合理的调节.当误差曲面较为平缓时,加大学习率使其尽快收敛;当误差曲面较为波动时,减小学习率,避免出现解的发散.通常的自适应规则如下:

(10)
附加动量的自适应学习率算法如下:
(11)
其中:△E是误差函数E的改变量;a和b是适当的正常数.
为了解决算法在后期学习状态不稳定的问题,对η值进行动态修正,使其在网络学习过程中尽量保持一个相对理想的状态,达到既能在学习初期有较快的收敛性,又能在后期避免出现震荡现象.
加入的算法公式为
η(t)=η[ΣE(t)/ΣE(t-0.5)].
(12)
进入学习后期,η值自动减半,初始值取为1~2之间.
在学习因子η的数值优化方法中,除了修正误差函数E的变量,还可以通过类似数列运算的方式更精确地稳定网络学习后期的波动状态.随着数据量越来越大,网络的能耗和不稳定性也随之升高,故选择附加动量因子δ来更好地控制网络学习速率.

(13)
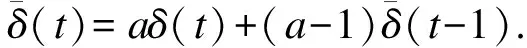
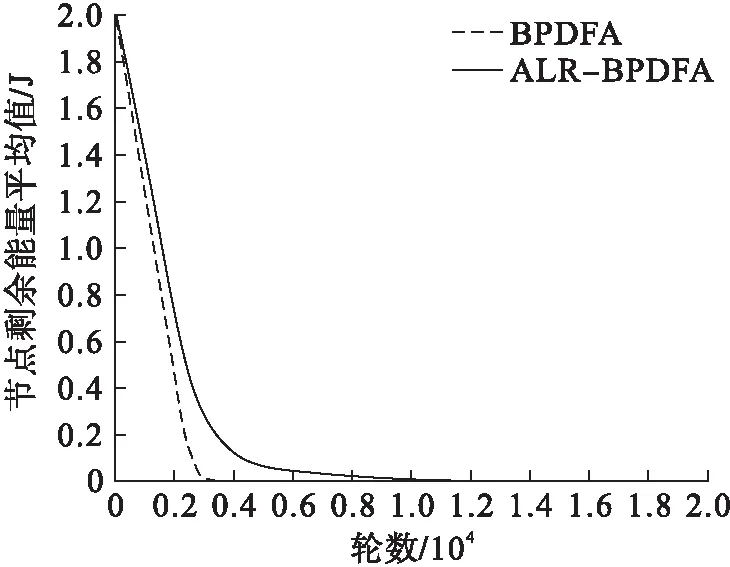
其中0 在基于 BP 神经网络模型的基础上,加入了自适应学习因子η,使其能够自行根据现有状况做出调整,有效地控制学习速率的大小,提高网络学习效率和稳定性. 仿真实验通过Matlab仿真软件对新算法进行仿真测试.为了更好地展现新算法的有效性,将ALR-BPDFA算法与文献[14]中提出的BPDFA算法、文献[17]中提出的BPNDA算法的仿真实验进行对比,主要在总能耗量、节点存活个数和数据传输量等方面测试各算法的优劣性. 仿真实验采用通常定义的物理模型,其定义如下: (1) 所有节点属性完全相同,能量有限且都能与基站直接通信; (2) 基站位置固定不变,节点不知道自身的位置信息; (3) 无线通信采用相对称的通信通道,能耗与传输的方向无关,节点可根据与目标的距离来调节信号的射频发射功率; (4) 簇首节点可执行数据融合. 仿真参数见表1. 表1 仿真参数 仿真环境:在100 m×100 m的范围内随机分布100个一样的节点,并把Sink节点设置在离感知区域较远的地方.节点的初始能量为2 J,数据包的长度为 5000 B,无线信道的带宽为1 Mbit/s,无线信号载频为2.4 GHz,收发数据所耗的能量为50 nJ/bit,神经网络的权值初始值设置为1,阈值设为0.2,训练次数设为4000.传感器节点的分布如图8所示. 图8 节点分布 基于上述建立的模型, 将与其他算法的性能进行对比. 4.2.1 ALR-BPDFA算法与BPDFA算法的比较 如图9所示,两种算法随着实验轮数的增加,节点存活个数都在不断地减少.BPDFA算法在2000轮至4000轮内节点存活个数呈瀑布式下落,4000轮后已无存活节点;而新算法在4000轮后仍有少量节点存活.故新算法有效地延长了网络的生命周期. 图9 节点存活个数对比 如图10所示:两种算法在0~800轮都能较好地控制节点所消耗的能量;BPDFA算法在实验一开始各节点剩余能量呈匀速式下降,进而逐渐能耗殆尽;新算法在3000轮后仍有0.2 J左右的剩余能量.可见新算法在控制节点剩余能量方面优于BPDFA算法. 图10 节点剩余能量对比 如图11所示,两种算法在网络中的总能耗量呈现不同的增长趋势.随着时间的不断增加,BPDFA算法的增长速度明显较快,尤其在前期,增长速度过高容易导致网络发生波动;而新算法的增长速度则较为平稳,有利于网络后期的发展. 图11 网络总能耗量对比 如图12所示,对两种算法在网络中的数据传输量作出比较.可以明显看出,在同等时间内,相比于BPDFA算法,新算法可以传输更多的数据量,同时保证高效的能量利用率,有效地提高了网络的工作效率,加快了整个网络的学习进程. 图12 数据传输量对比 4.2.2 ALR-BPDFA算法与BPNDA算法的比较 为了进一步验证ALR-BPDFA算法在控制节点存活数量上的优越性,与文献[17]中提出的BPNDA算法的仿真实验进行对比.由图13可以明显地看出:随着时间的变化,BPNDA算法在实验进行400 s后节点几乎全部死亡;而ALR-BPDFA算法还有将近40个节点存活,直到800 s左右才全部死亡. 将ALR-BPDFA算法与BPNDA算法在随轮数变化的死亡节点个数方面作对比.由图14可以看出:随着实验轮数的进行,BPNDA算法在大约4000轮后节点全部死亡;而此时ALR-BPDFA算法在实验中还有接近半数节点存活.可见ALR-BPDFA算法在控制节点存活数量上有着出色的稳定性. 图13 与BPNDA算法的节点存活个数对比 图14 与BPNDA算法的死亡节点个数对比 基于无线传感器网络的研究背景,提出了 ALR-BPDFA 算法.该算法引入了 BP 神经网络模型,将分簇路由技术和数据融合技术相结合,重新设计了节点分簇机制,减少了每轮循环都要重新构造簇结构的麻烦和不必要的能耗.在神经网络学习阶段,引入自适应调整学习率的模式,使整个网络能根据实时情况自行调节学习速率,加快网络整体的学习进度,提高数据融合的稳定性,保障数据融合的高效性. 通过以上研究,将新算法应用到无线传感器网络领域下的日常工作中,旨在减少网络中的冗余能耗.经仿真实验证明,优化后的新算法在提高收敛速度、降低误差方面具有更好的成效.4 仿真实验
4.1 仿真模型与参数设置

4.2 仿真结果及分析






5 结 语
