基于分布式预报平台的水文模型预报研究
2022-04-12廖厚初王加虎
廖厚初,王加虎
(1.黑龙江省水文水资源中心,黑龙江 哈尔滨 150001;2.河海大学,江苏 南京 210098)
水文系统是一个高度非线性的复杂系统,而流域水文模型则是封闭流域内的水文循环过程为研究对象的模型[1]。目前的水文模型主要有集总式模型和分布式模型两大类。集总式模型是以整个流域为一个基本单元进行水文计算,以概念性模型为主,而分布式水文模型则将流域进行空间上的划分;分布式水文模型是在DEM所划分的流域网络单元上建立水文模型,本文主要是基于分布式预报平台的水文模型预报研究,考虑土壤水的再分布对水文模型预报的影响。
1 流域概况
汤旺河发源于小兴安岭南坡,由北向南贯穿小兴安岭腹地;全长约465 km,平均坡度0.71‰,流域面积20 557 km2。汤旺河流域降水时空分布极不均匀。年内降水主要集中在6—9月,占全年降水量的76%,其中7—8月占全年的50%。汤旺河上游五营站年径流深约在100~600 mm 之间,多年平均径流深约为255.5 mm,历年平均径流量约为10.59×108m3,径流的年内分配和年际变化都存在较大差异,见图1所示。

图1 五营站年平均流量过程
2 模型采用资料
2.1 资料审查
由于预报平台收集的资料只有18年,不能满足计算的要求,需要对资料进行代表性、可靠性、一致性等三个方面审查,并确定出本次研究的代表站。
(1)代表性。统计参数稳定性分析: 年降水量均值和变差系数在系列长度增加到20年左右时,这两个数逐渐趋于一个固定值,说明如果水文资料系列在20年以上,则此站的水文资料具有一定的代表性[2],资料系列长度越长,那么代表性就越好。
(2)可靠性。流域内代表站的水文资料均为水文资料整编后成果。流域干支流各代表站径流模数在7.8~9.7之间,相差比较小,断面变化也较小,水位流量关系稳定,因此说明汤旺河流域各代表站的水文资料可靠性较高[2]。
(3)一致性。五营站以上没有水利工程,人类活动少,下垫面条件好,径流关系比较稳定。因此该站的水文资料系列一致性较好。
2.2 代表站选择
在洪水预报平台中收集到汤旺河流域,统计流域内水文站的降雨径流和水位资料系列的长度,见表1。

表1 水文资料系列长度统计情况
五营站位于汤旺河流域上游,水文资料系列长度基本满足,可靠性、一致性和代表性良好,而且该流域远离大城市,水利工程等人为影响较小;洪水过程线多为由单次降雨形成的过程线,比较具有代表性。综合分析,确定以五营站代表站,对汤旺河流域进行水文模型的了解和水文预报的研究。
3 模型对比分析
3.1 次洪选择
一般上我们选择次洪[3],要考虑很多方面,比如形成次洪的降水在空间和时间上要具有相似性;尽量选择由单一一场降雨形成的次洪,减小其他因素的影响。
3.2 率定结果的评价方法
对次洪进行参数率定后,可以计算得到拟合曲线,曲线的拟合程度由四个参数进行反映,分别为:纳计系数NSCE、总量误差Bias、峰量误差ErrP、时间误差ErrT。
NSCE为纳什系数,一般用于评定水文模型拟合结果的好坏,取值为负无穷到1,取值越接近1,表示可信度高;取值接近0,表示总体结果可信,误差大;取值小于0,则不可信。
Bias为总量误差,取值既可以为正,也可以为负,取值越接近0越好。
ErrP为峰量误差,取值既可以为正,也可以为负。取值越接近0越好。
ErrT步长数为峰现时间误差,取值既可以为正,也可以为负,其数值的绝对值表示两条曲线洪峰现时之间间隔的小时数,取值越接近0越好。
3.3 水文模型对比
水文模型的产流部分主要描述降雨入渗过程,在不同下垫面中各种因素综合作用下的再分配,它是发生在非饱和土壤中的水分运动,贯穿于产流前期及产、汇流过程中[1]。
选择五营站现有资料中的五场次洪作为代表,使用所选的四种水文模型对其进行参数率定、曲线拟合,筛选出率定、拟合结果较好的水文模型,确定该站点流域的参数和适用模型,见表 2。

表2 次洪信息统计情况
选择其中2010年一场洪水,分别采用四种水文模型对其进行参数率定、曲线拟合,拟合结果的参数取值如表3~表6所示。可以看出:

表3 霍顿两水源模型拟合参数
(1)霍顿两水源模型在拟合时,峰量差别较大时,不能确定出一套公用的参数,所以认为霍顿两水源模型在此地区的实用性有限,需要进行洪水分级再使用。
(2)在剩下三个模型方案中,蓄满两层两水源模型纳什系数均值为0.5845,径流系数两水源的纳什系数均值为0.7249,微调版新安江模型的纳什系数均值为0.8509,径流系数两水源与微调版新安江模型的纳什系数均值都达到了0.7以上,拟合效果较好,相比之下排除掉纳什系数较小的蓄满两层两水源模型。

表4 蓄满两层两水源模型拟合参数
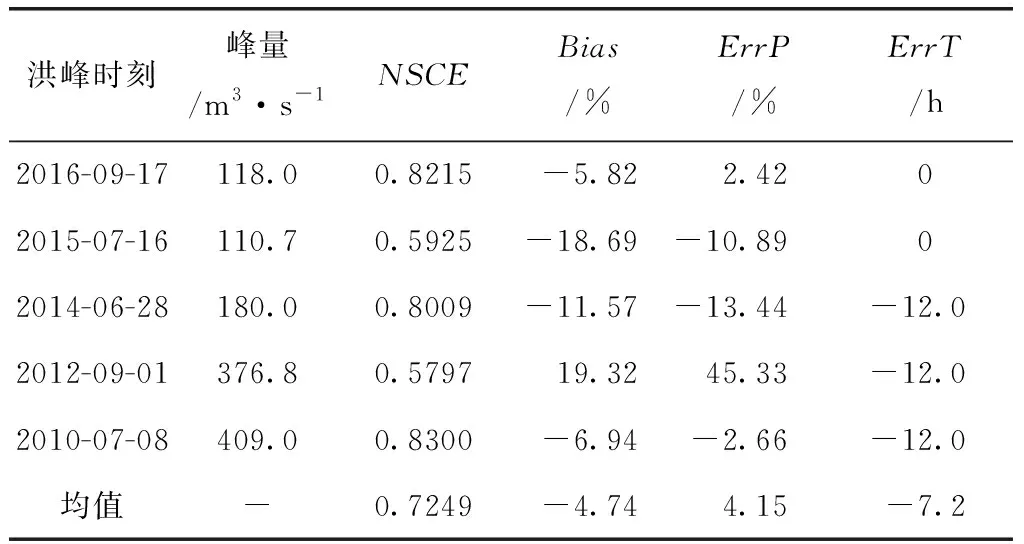
表5 径流系数两水源模型拟合参数

表6 微调版新安江模型拟合参数
(3)剩下的两个模型,微调版新安江模型的纳什系数更大,说明其拟合效果更好,再观察其总量误差与峰量误差的绝对值,误差都在2%以内,比径流系数两水源模型的5%以拟合效果更加好,误差更小。故认为微调版新安江模型最适合用在五营站流域。后续的方案制定均采用微调版新安江模型。
4 参数敏感性分析
本次分析参数的敏感性主要是对土壤水的再分配进行研究。为了方便参数敏感性的分析(以微调版新安江模型中的实际参数为对象),这一步在分析参数的敏感性时,我们对土壤蒸散发折算系数K、自由水蓄水容量SM、蓄水容量曲线指数B、土壤含水量初值、不透水系数M、地下水日出流系数KG、壤中流日出流系数KI、快速滞时进行敏感性分析。详见表7、表8。

表7 蒸散发折算系数、SM、指数B、土壤含水量初始值NSCE等参数对比

表8 不透水系数IM、KG、KI、快速滞时NSCE等参数对比
通过敏感性分析,可以确定各个参数的敏感性,找出误差最小的各参数确定值,重新创建一个方案,只把2010年代表次洪放进去,然后把处理后的参数取值输入模型,拟合得到的结果见表9。

表9 拟合效果评定参数
从拟合的图形和结果可以看出,调整后的参数模拟效果较好。
5 模型验证及精度评定
5.1 模型验证
在比较水文模型的适用性的过程中,我们不仅从四个模型中选择出了五营站的适用模型,也得到了对应该模型的模型参数的取值。这一步我们在已有的十几年水文数据中选出两场代表性较好的次洪,进行模型参数的验证。
依然按照之前的次洪选择方法,优先选择由单次降雨形成的形状较好的过程线。选择出来的两场次洪信息见表10所示将用微调版新安江模型率定出来的参数当作该站点的基本参数,运用在另一个新建方案中,然后将两场验证次洪添加入新建的方案中,点击计算进行过程线的模拟。拟合后NSCE参数对比表见表11所示。
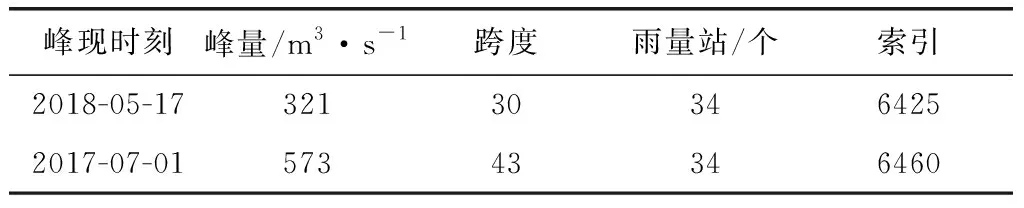
表10 验证次洪信息

表11 验证NSCE等参数
5.2 精度评定
精度评定参照《水文情报预报规范》(GB/T22482—2008)进行评定,预报的精度按合格率或确定性系数的大小分为3个等级[4],见表12。
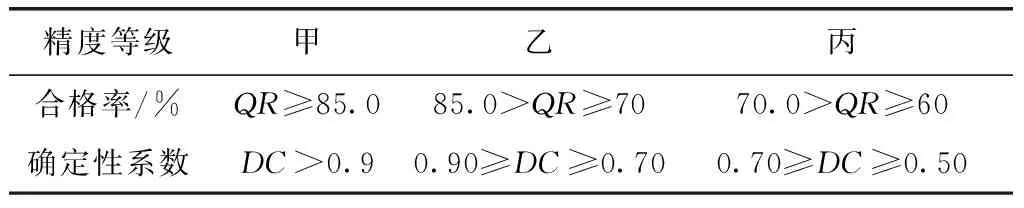
表12 预报项目精度等级
采用7场洪峰进行预报精度评定,分别以方案合格率和确定性系数来确定,详见表13~表14。

表13 洪峰预报合格率计算

表14 洪峰预报确定性系数计算
综合确定合格率为85.7%,确定性系数如式(1):
(1)
通过计算,QR=85.7%>70%;DC=0.81≥0.7,因此可以确定五营站洪峰预报精度评级为乙级。
6 结 论
本文是在分布式水文预报平台下开展的模型预报研究,对所选代表站的资料进行了三性审查,通过对土壤水的各种参数进行再分配和敏感性分析,采用四种不同的模型进行模拟和研究,分别得出了各种模型所对应的参数,掌握了这四种模型的基本理论和预报方法,经过比对分析,确定微调版新安江模型比较适合汤旺河流域上游五营站,确定了该模型的参数,并进行了模型验证和精度评定,最终确定五营站微调版新安江模型的洪峰预报精度评级为乙级,满足标准GB/T 22482—2008的要求,可以运用到实际的洪水预报中。
