结合LDA和孪生BiLSTM的话题演化跟踪方法
2022-04-12龚晓康应文豪龚声蓉1
龚晓康,应文豪,王 骏,龚声蓉1,
(1. 苏州大学 计算机科学与技术学院,江苏 苏州 215006;2. 常熟理工学院 计算机科学与工程学院,江苏 常熟 215500;3. 上海大学 通信与信息工程学院,上海 200444)
0 引言
社交媒体信息作为一种数据类型具有动态变化性,而这种变化的载体就是话题,话题随着时间的发展而演化,从而反映了事态阶段性变化的过程。从认知学的角度,这样的演化过程符合人们认知事物的一般顺序,当用户关注某个话题时,一般从话题事件产生的原因开始,逐步深入到事情的发展、高潮,最终到话题事件的结束,这个逻辑顺序就是话题的动态演化,是话题随着事件变化的过程。然而随着计算机应用技术的快速发展,每时每刻产生的信息繁多复杂,面对海量的社交媒体信息,需要对离散化的数据进行挖掘与分析,需要准确、完整地获取话题在每个阶段的特征,并且以话题为中心将各个阶段的内容整合,完成对话题的动态演化挖掘,使人们能够迅速且清晰地了解和把握事情发展的过程与脉络。
通常,构造事件脉络的核心在于两个方面: 一个是抽取相关事件和子事件的信息集合,另一个是确定关键信息并且清晰定义事件和子事件之间的关系[1]。在话题检测与追踪任务中,TDT(Topic Detection and Tracking)可以帮助人们从海量的网络信息中筛选出感兴趣的话题信息。如今话题检测技术主要分为三类: 第一类是基于主题模型的话题检测,主要是基于LDA(Latent Dirichlet Allocation)技术的主题模型,或者是基于LDA改进的主题模型[2-3],如Xu等人[4]基于LDA提出一种新闻主题随时间演变的方法,实现对新闻文本主题的跟踪和演化。第二类是基于改进聚类算法的话题检测,如Geng等人[5]基于K-means提出一种三层混合聚类的方法对话题进行检测。第三类是基于多特征融合的话题检测[6],如赵旭剑等人[7]提出一种基于特征演变的新闻话题演化挖掘方法,显著提高了话题模型的准确率,Abulaish等人[8]提出一种通过结合LDA主题模型和Word2Vec[9]的方法对话题进行检测,Du等人[10]为了跟踪主题的演化趋势,结合社交媒体的特性提出MF-LDA主题模型。以上方法对话题进行追踪演化主要基于主题模型或者传统聚类方法,然而LDA等主题模型属于概率生成模型,侧重于文本结构,在文本语义提取方面则表征能力相对较弱。
针对以上问题,本文在基于多特征融合的话题检测基础上做出进一步的研究,提出一个基于词嵌入的方法来分析社交媒体在一段时间内的话题演化。本文的贡献主要在于:
(1) 已有的方法大多使用五个时态对话题进行描述,本文认为在演化过程中还存在话题暂时“消失”的情况,因此提出了第六个时态“潜伏”,从而更加完整地描述话题演化过程。
(2) 提出一种融合显性相似度以及隐性相似度的文本邻近度模型PDRBL(Proximity Captured Dominant and Recessive Features of Text based on BiLSTM and LDA)来确定话题演化过程中的时态判定,PDRBL通过引入孪生BiLSTM,捕获上下文的语义特征,可以更好地表达文本的近似程度。
(3) 基于PDRBL和六个演化时态,提出了TETP(Topic Evolution and Tracking based on PDRBL)方法进行话题演化路径跟踪。
1 相关工作
1.1 LDA模型
LDA是一种三层贝叶斯模型,以无监督的方式从文本中发现概括文本的主题[11]。如图1所示,文本中假设文档集S有K个主题,第τ主题被表示成为一个“主题-单词”的多项分布φτ,文档m有Nm个单词, 这K个主题有一个文档-主题多项式θm,整个文档的生成过程如下:
(1) 从以参数为α的狄氏分布中为每个文档采样使用“文档-主题”的分布θm,即θm~Dir(α),m∈[1,M],其中M为总文档数。
(2) 从以参数为β的狄氏分布中为每个主题采样使用“主题-单词”的分布φτ,即φτ~Dir(β),m∈[1,M],其中K为总单词数。
(3) 文档m中的每个词wm,n,采用一个主题标签zm,n~Multi(θm),生成词wm,n~Multi(φzm,n)。

图1 LDA模型结构
该方法将文本表示成一系列话题的集合,生成过程相当于实现了文本的话题聚类和文本的压缩,每个文本根据不同权重被分配到不同话题中。由于本文提出的方法主要用于模拟社交媒体信息数据中的话题演变,而且社交媒体信息通常是短文本,因此我们以不同的时间间隔为基础,使用LDA在相同时间间隔内的文本进行主题提取。
1.2 LSTM模型
LSTM(Long Short-Term Memory)是1997年Hochreiter等提出的模型,是针对RNN出现的梯度消失和梯度爆炸问题而提出的改进模型[12]。它在RNN模型的基础上加入了三个“门”来控制信息的传递,从而在一定程度上避免梯度消失与爆炸问题,获取文本语义的长距离依赖信息。模型内部的三个“门”分别为输入门it、遗忘门ft、输出门ot,和记忆单元ct等部分,具体结构如图2所示。
图2中LSTM通过“遗忘门”将上一个Cell单元中的部分信息遗忘,它由sigmoid完成,通过接收上一个单元的输出与本单元的输入的加权和计算出一个0到1的向量,该向量里面的0到1间的值表示上一个Cell中保留或丢弃多少,0表示完全抛弃,1表示全部保留。计算如式(1)所示。
输入门利用ht-1和xt通过一个tanh层控制Cell单元需要加入哪些信息,计算过程如式(2)、式(3)所示。
it=σ(Wi·[ht-1,xt]+bi)
(2)
ct=ft×ct-1+it×tanh(Wf·[ht-1,xt]+bc)
(3)
输出门控制信息用于当前单元的任务输出,其计算过程如式(4)、式(5)所示。
上述公式中的Wi,Wf,Wo分别为输入门、遗忘门、输出门的权重矩阵;bi,bf,bo为输入门、遗忘门、输出门的偏置矩阵;σ、tanh为激活函数。
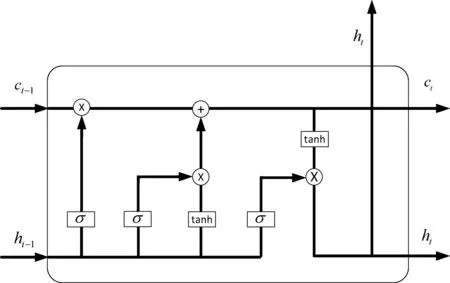
图2 LSTM-Cell内部结构图
1.3 注意力机制
注意力机制[13]最早由计算机视觉领域提出,用于模仿人类给图像分配不同的权重。近几年基于注意力机制的神经网络模型在各项自然语言处理任务中取得了较大的发展。由于Attention层能够捕捉全局信息,可以捕获句子的全面特征,因此本文引入了注意力机制结合双向LSTM获取更多的语义信息。具体模型如图3所示。注意力机制的计算如式(6)所示。
其中,Q∈Rn×dk,K∈Rm×dk,V∈Rm×dv。激活函数softmax中为三个矩阵相乘,得到一个n×dv的矩阵,可以简单地理解为Attention层把n×dk的序列Q编码为n×dv的新序列。
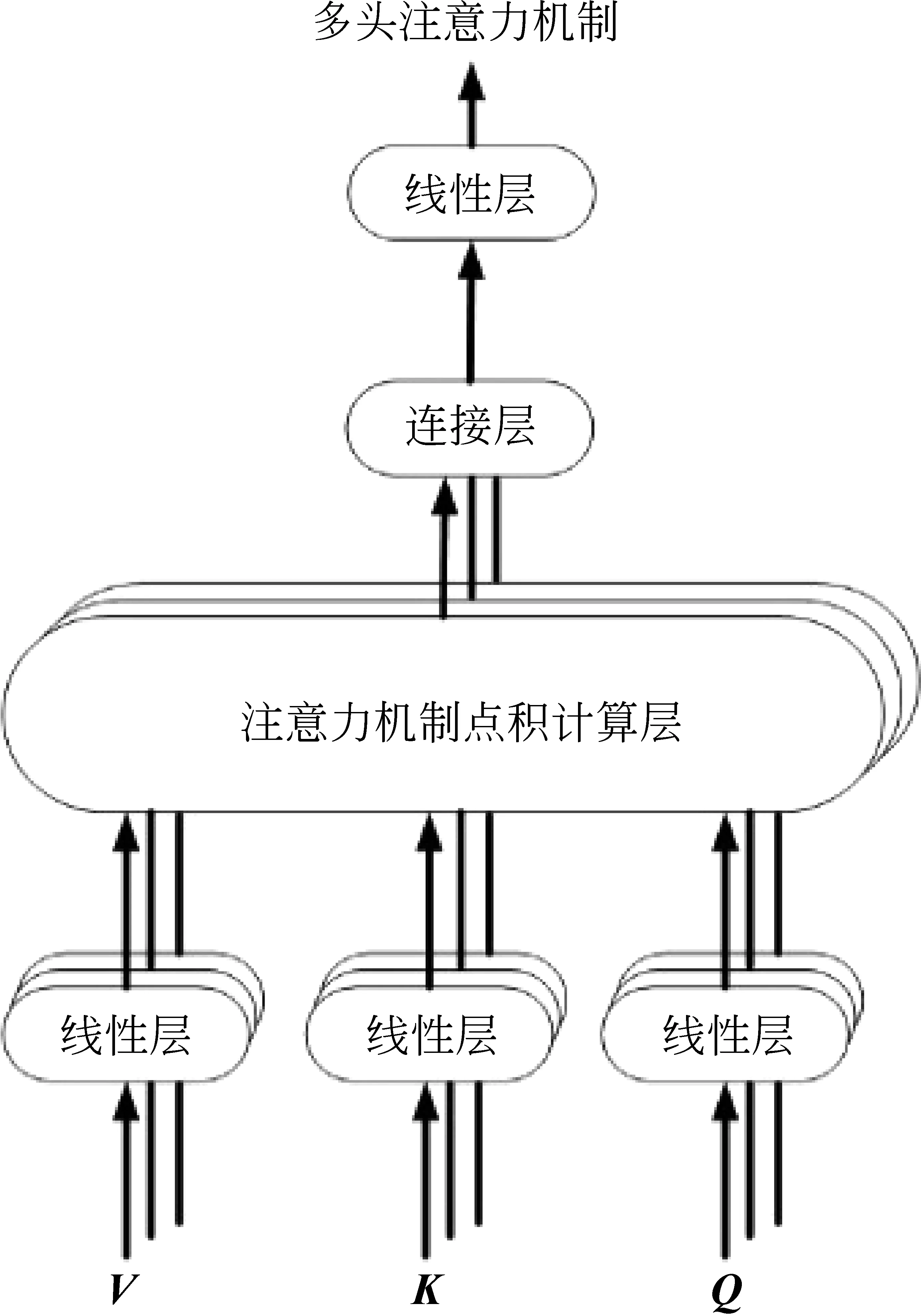
图3 注意力机制的一般框架
2 话题演化跟踪方法TETP
图4描述了本文方法的基本流程: 根据时间片段将社交媒体文本划分为若干个文档集,对其进行主题提取;针对不同时间段的主题,计算其显性相似度以及隐性相似度,求得融合邻近度PDRBL,用于表征话题文本间的相关程度;最后,将融合邻近度与演化时态阈值进行比较,确定话题演化时态,判别话题的演化关系和演化规律。话题演化状态是对于话题演化过程中各个阶段话题的时态定义,主要分为出现、持续、分离、收敛、消亡、潜伏六个时态。下文将对所提出的概念及模型做详细阐述,并给出TETP方法的伪代码。
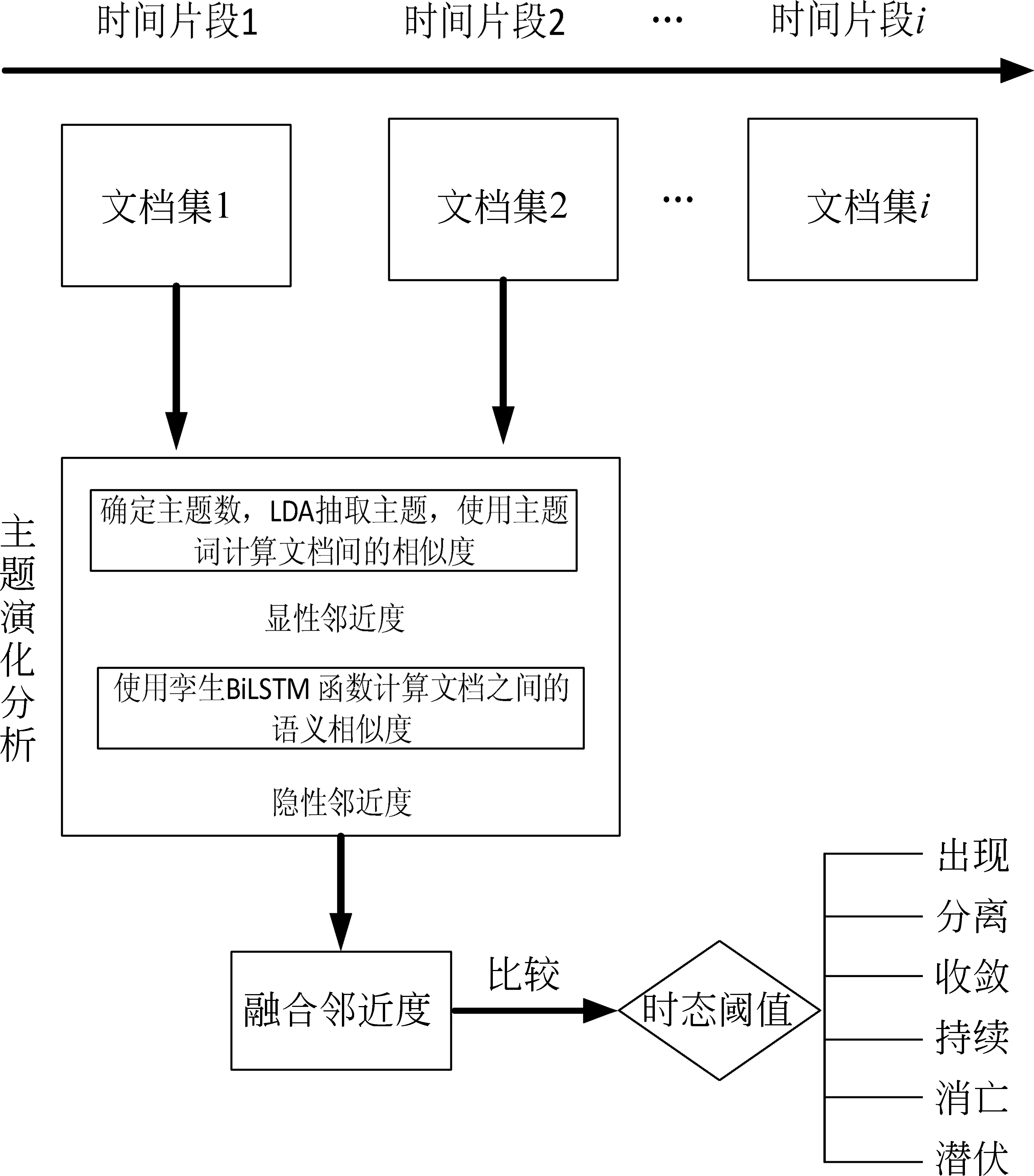
图4 主题演化分析框架
2.1 演化时态阈值的定义
以T1和T2时刻内的时间段为例,划分若干个时间片段,T1和T1+1表示为相邻时间间隔,T1+β为不相邻的时间片段,由此划分5个分区来表示一个时间段内的话题演化,图5中的节点表示话题。在本文中,不同的事件演化定义由θee、θcd,θp三个阈值所判定[8]。θee判定出现和消亡两类事件,θcd判定分离和收敛两类事件,θp判定持续存在类事件。本文以话题间相关性程度的高低为依据,设定阈值时依照θee<θcd<θp的规则。
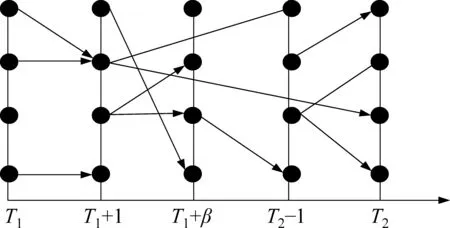
图5 主题时间演化图
2.2 话题间的融合邻近度(PDRBL)
融合邻近度衡量话题之间的相似度,在数学上的定义如式(7)所示。
PX(Tkn,T(k+1)m)=aPα(Tkn,T(k+1)m)+
bPβ(Tkn,T(k+1)m)
(7)
其中,Tkn表示在时间线Tk中第n个主题,T(k+1)m表示时间线Tk+1中第m个主题,Pα(Tkn,T(k+1)m)表示显性相似度,Pβ(Tkn,T(k+1)m)表示隐性相似度,a和b分别表示显性和隐性相似度权重。融合邻近度结合显性相似度以及隐性相似度[14],在显性相似度中采用LDA模型提取文本主题,计算主题词间相似度。在隐性相似度中采用注意力增强的孪生BiLSTM方法,计算文本中语义相似度。其优势在于既考虑主题词在文本中所占比重,又考虑文本语义在相似度衡量中的重要性。比起基于主题模型的传统方法或基于深度学习的语义提取方法, 邻近度可以综合两者的优势,从而更好地度量文本之间的关系。
2.2.1 显性相似度
显性相似度由话题中主题词分布的匹配程度来确定,两个话题若具有相似的主题词分布,则往往二者描述的话题也相似。本文采用LDA方法确定话题间的主题词,提取相邻时间段内的主题,使用Pα表示显性相似度,如主题Tkn与T(k+1)m,使用余弦相似度计算,具体如式(8)所示。
2.2.2 隐性相似度
本文采用注意力增强的孪生BiLSTM方法计算话题之间的隐性相似度,在现有文献中多数使用词向量计算上下文相似度,例如,Word2Vec[9]和GloVe[15],从不同的大型语料库中学习词向量,将每个词表示为上下文向量,但上述方法无法捕获文本中的语义信息,因此本文的隐性相似度使用基于孪生BiLSTM网络和Attention机制,并且使用曼哈顿距离的方法来实现句对之间的相似度度量。输入文本经过图6中模型得到向量,该向量表征其输入文本语义,通过曼哈顿函数进行计算得到相似度,具体如式(9)所示,模型结构如图6所示。
Pα(Tkn,T(k+1)m)=exp(-‖hTkn-hT(k+1)m‖1)
(9)
2.3 话题演化时态
本节详细介绍话题演变中的各个时态,以不同时间段内社交媒体信息的话题演变为例,如Tkn∈Tk表示第k个时间间隔中第n个主题,Tk是第k个事件线中总的主题集合,时间线Tk中每个事件与时间线Tk+1中事件进行融合邻近度计算,不同事件之间的关系使用融合相似度衡量。按照时间顺序构建话题分布图,若融合邻近度大于相应阈值并满足基本转换条件,则将相应话题相连接表示相关,根据从属于Tk与Tk+i的话题数和关系,本文在五个已存在的话题演化时态的基础上[8,10]引入“潜伏”时态,补足不同时间间隔段内的话题关系。
2.3.1 出现(Emergence)
若时间线Tk+1中话题T(k+1)i与时间线Tk中所有话题都无法匹配,即第(k+1)个时间线中第i个主题T(k+1)i与第k个时间线中所有话题的融合邻近度小于阈值θee,简言之,话题T(k+1)i在时间线Tk中未被讨论,在时间线Tk+1中首次出现,表示一个从无到有的过程,具体的数学表达如表1表示。

图6 隐性相似度计算结构图
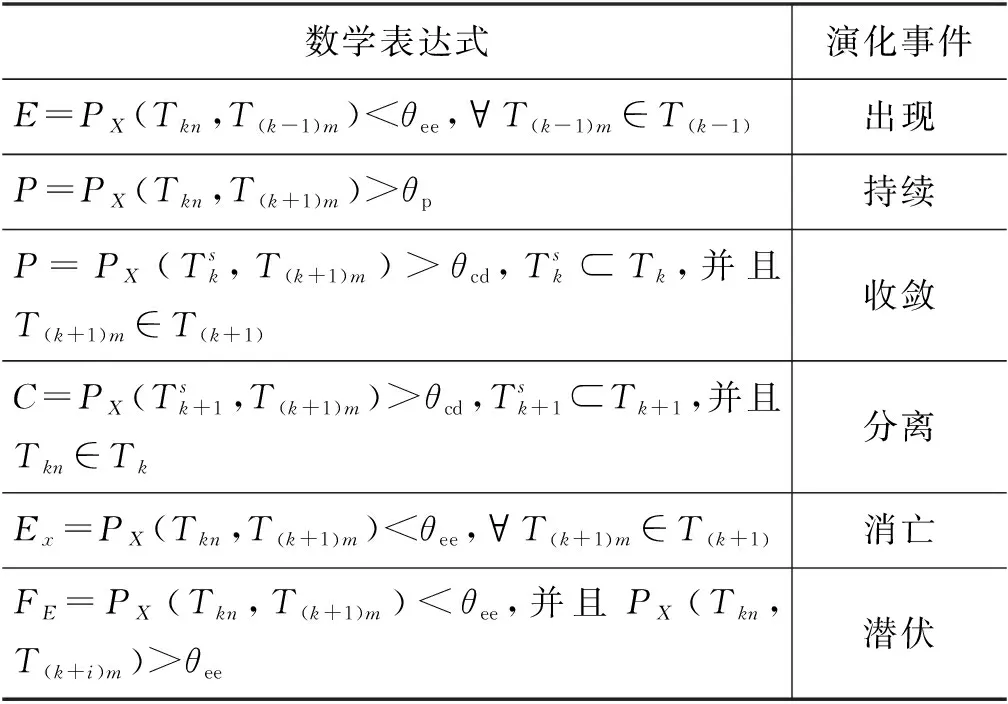
表1 不同话题转换事件的数学关系
2.3.2 持续(Continuance)
有且仅有一个时间线k中话题Tki与时间线k+1中话题T(k+1)j的融合邻近度大于阈值θp,则表示话题Tki在时间线k和k+1中持续存在。话题的持续在数量上表示一对一的关系,在社交媒体方面代表着话题被长期讨论,用户对加入该话题的兴趣和意向强烈,具体的数学表达如表1表示。
2.3.3 收敛(Convergence)
社交媒体中多个话题经过时间变化后会聚焦于同一话题,即话题收敛。如图7所示,若用户在时间线T1内子话题T12以及T23与时间线T2内的话题T23融合邻近度大于阈值θcd,则表示T12与T13收敛于T23,具体的数学表达如表1所示。

图7 话题收敛状态
2.3.4 分离(Separation)
话题演化中存在一个话题经过时间演变后分散为多个子话题的现象,即话题分离。如图8所示,若用户在时间线T1内子话题T12与时间线T2内子话题T22以及T23融合邻近度大于阈值θcd,则表示话题T12发散到T22与T23,具体的数学表达在表1中表示。由于话题的收敛与分离涉及不同时间线中多个话题,其融合邻近度通常低于话题的持续,因此阈值θcd<θp。
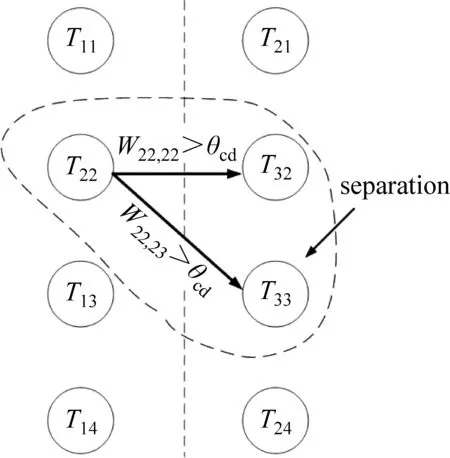
图8 话题分离状态
2.3.5 消亡(Extinction)
如果时间线Tk中子话题Tki与时间线Tk+1中的所有子话题都无法匹配,即话题Tki与相邻时间线k+1中所有话题的融合邻近度小于阈值θee,简言之,话题Tki在时间线Tk+1中未被讨论,表示一个从有到无的过程,具体的数学表达如表1所示。
2.3.6 潜伏(Lurk)
由于社交媒体中用户行为具有随机性的特点,基于消亡状态本文提出了一个新状态——潜伏。如图9所示,若用户在时间线T1内子话题T12与相邻时间线T2中所有子话题的融合邻近度均低于阈值,而在时间线Ti中继续被讨论,则表示话题T12处于潜伏状态,其具体的数学表达如表1 所示。
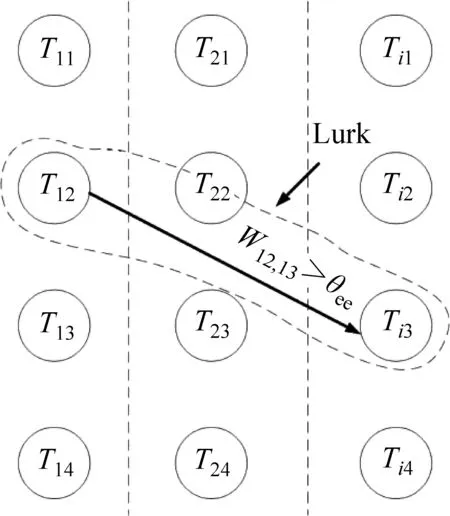
图9 话题潜伏状态
基于融合邻近度PDRBL以及话题演化中的六个时态定义,我们给出话题演化跟踪方法TETP的算法伪代码如下:

Algorithm 1: Topic Evolution and Tracking base on PDRBL1Input: D, θ //D表示疫情数据集,θ 表示为θee,θcd,θp集合2Output: event //event表示话题演化时态3Begin4 P← Partitioning(D)#将疫情数据集按时间顺序排列存储至P中5 topic_list← []6 M← []//初始化矩阵M存储不同时间段内的邻近度值7 For p in P do8 topic_extra← topicExtraction()//使用LDA提取文本主题9 topic_list← topic_extra10 End11 for topic in topic_list do12 Topicset_i←topic_list[i]13 Topicset_(i+n)←topic_list[i+n]//n的默认值为1,表示取相邻时间段的文本比较14 For topic_j in topicset_i do15 For topic_k in topicset_(i+n) do16 Pα= explicitProximity(topic_j,topic_k)//计算显性相似度值17 Pβ=implicitProximity(p_i,p_k)//计算隐性相似度18 PX=Pα+Pβ19 M[i][j][k] =PX20 End21 End22 End23 For M[i][.][k] in M do24 If none of M[i][.][k] values is greater than θee25 Event ← emergence//表示时间线(i+1)内出现并且不再时间线i出现的话题26 If M[i][.][k] has more than one values greater than θcd27 Event ←convergence//表示时间线i中话题在时间线(i+1)内聚焦于一个话题28 End29 For M[i][j][k] in M do30 If M[i][j][k] is greater than θp31 Event ← continuance//表示第j个话题与相邻时间线中第k个话题为同一话题32 End33 For M[i][j][.] in M do34 If M[i][j][.] has more than one values greater than θcd35 event← separation//表示第j个话题在相邻时间线发散为多个子话题36 If none of M[i][j][.] values is greater than θee37 n← m (m>1) //若相邻时间线未发现相似话题,则跨时间线寻找38 If M[i][j][.] has values greater than θee39 event←lurk//在跨时间线中存在与时间线i第j个子话题相近的话题40 event←extinction//时间线i中第j个话题不存在与其相近的话题41 End42 End43End
3 实验
PDRBL模型用以确定话题文本间的相似程度,是话题演化追踪方法TETP中的核心环节。本文采用多组模型对比的方法确定其优越性,并使用疫情期间及后期复工复产数据作为演示案例验证TETP方法的有效性。实验环境如表2所示。

表2 实验环境
3.1 实验数据
训练样本数据集来自Kaggle上的Quora句对数据的中文翻译数据集约40万组,正负样本比例为1∶1.7。话题演化示范数据集采用疫情数据集和疫情后复工复产数据集,前者主要以从2019年12月31日起至2020年5月2日的疫情相关社交媒体新闻报道为主要内容。后者主要为从2020年2月1日至4月30日疫情后复工复产的微博社交媒体数据(1)疫情数据集以及复工复产数据集来源: https://github.com/NickGong/-/tree/main/data.。
3.2 评价标准
本文采用国际通用评价标准精确率P(Precision)、召回率R(Recall)、F值(F-Measure)对实验结果进行评价。相关的计算如式(10)~式(12)所示。

(12)
其中,TP、TN、FP、FN含义如表3所示。
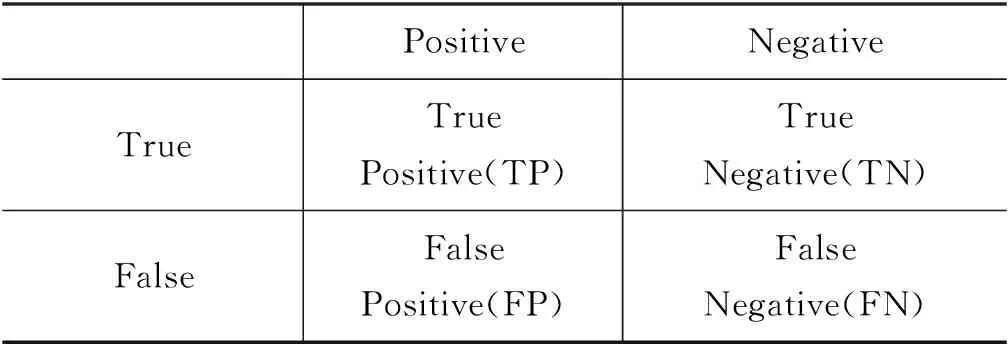
表3 混淆矩阵表
3.3 实验参数设置
深度学习模型参数设置主要包括学习率、词向量维度、隐藏单元数等超参数,以及显性相似度权重a、隐性相似度权重b,具体数值如表4所示[16]。参数a、b的选择采用网格搜索来确定。如图10所示,显性相似度权重a与隐性相似度权重b,按照a+b=1的原则,依次选取a=0.05,0.10,…,0.6,计算对应权重b的取值,得到不同特征权重组合下模型的精确率。
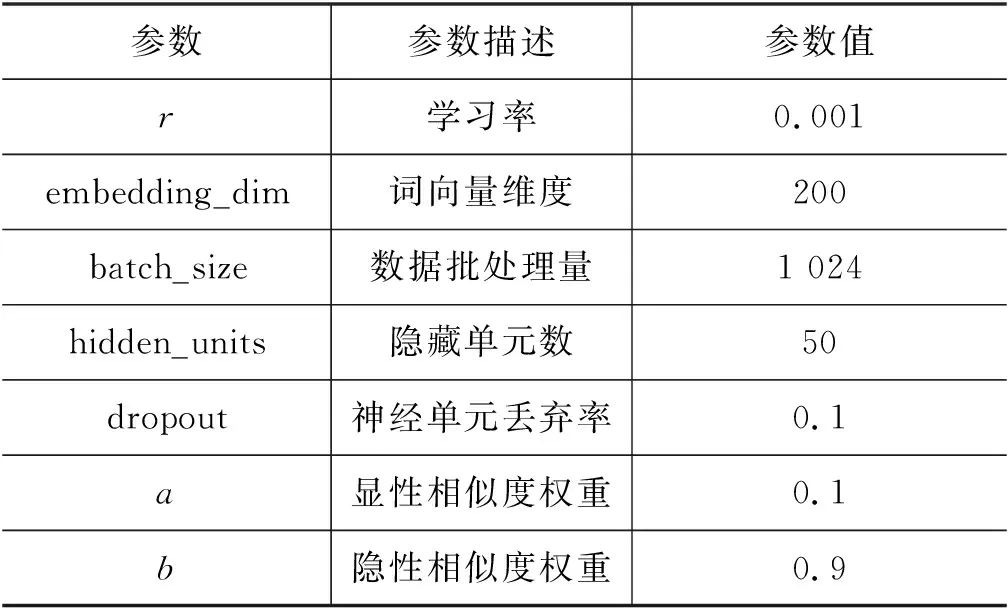
表4 实验参数表
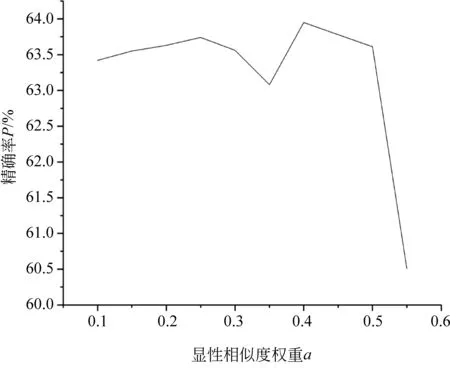
图10 显性相似度权重a与精确率P关系图
从图10中可知,当a=0.4,b=0.6时获取的精确率最高,由此可见,融合了语义的文本相似性度量具有更好的效果。
3.4 对比实验设置
为证明本文模型在相似度度量方面的有效性,我们将提出的相似度判定方法PDRBL与现有相似度判定模型在相同环境下进行对比实验。模型中词向量或字向量使用Word2Vec在文本数据集中进行预训练。为确保实验的准确性,实验采用同一个预训练词向量或字向量。对比模型如下:
(1)CNN基于Kim[17]提出的CNN分类模型,将两文本使用大小为5的卷积核分别提取文本特征,经过全局平均池化后使用曼哈顿距离进行相似度判定。
(2)Word2Vec-CNN基于Word2Vec对于文本向量化的表示结合CNN模型[18],对文本进行相似度计算。
(3)LSTMLSTM解决RNN的一些不足,在此基础上加入门限控制。本文使用LSTM进行语义学习,利用孪生BiLSTM网络结构将输入对应的输出取平均作文本表示。
(4)BiLSTMZaremba等人[19]构建的BiLSTM网络模型,该模型解决了LSTM单向传播的缺陷,加入了后向传播单元,可以同时捕捉上下文的语义。
(5)ATT-BiLSTM在Mueller等人[20]提出的LSTM利用孪生网络结构文本计算相似度的基础上,构建BiLSTM模型结构,并且引入Attention机制。其中,BiLSTM提取文本序列化的信息,Attention机制依据特征对词的重要程度区别表示。
(6)Word2Vec-ATT-BiLSTM在江伟等[21]提出的基于Word2Vec文本向量化表示方法的基础上,结合BiLSTM和Attention机制,进行相似度计算。
(7)PDRBL本文提出的方法使用LDA对文本进行相似度计算获得显性相似度,和基于Word2Vec文本向量化表示结合BiLSTM和Attention的隐性相似度,并且结合各自的权重获得最终的相似度进行话题关系判定。
3.5 实验结果分析
本文从精确率P、召回率R、F1值三个方面进行评价,结果如表5所示。
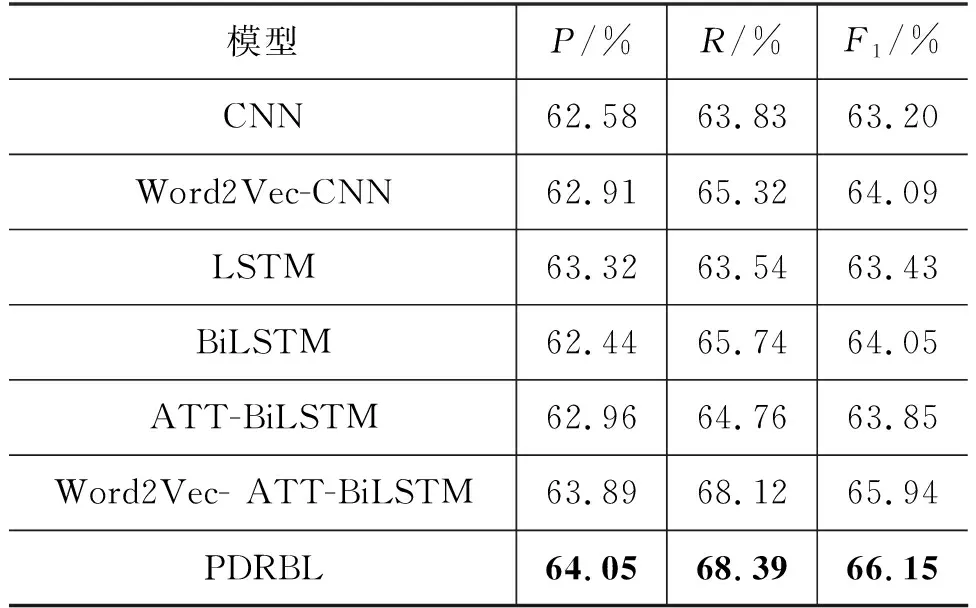
表5 实验结果
从表5可以看出,本文提出的模型PDRBL在精确率、召回率、F1值三个方面上均取得一定提升。相比于传统的CNN和基于Word2Vec的CNN而言,在RNN模型基础上的改进模型LSTM以及基于LSTM的衍生模型取得的效果较优。从CNN和RNN的模型结构来看,CNN侧重于识别跨空间的模式,主要表现为在检测局部的任务中取得较优的结果,例如,在识别表达特定的情感的关键短语上可以获得较好的结果;而RNN侧重于跨时间的模式,主要表现为在长程语义文本中可以得到优异的效果。在本文的文本数据中,由于自然语言本身存在的时序性特点,且LSTM模型结构中记忆单元能有效地记录文本时序特征,本文采用的BiLSTM结构更是在LSTM模型的基础上增加了逆向文本的语义信息,在学习文本语义信息的同时,加强了对语义学习的能力。实验结果表明,使用BiLSTM的结果优于传统的CNN模型,这也反映出相较于CNN模型BiLSTM可以获得更多的文本语义信息。本文提出的PDRBL模型在考虑文本语义的同时,也侧重对于文本中主题词语的偏重。实验表明,在加入主题变量的因素后,能获得较优结果。此外根据实验结果还能得出以下结论:
(1) 通过对比CNN和LSTM在该语料上的实验结果表明,LSTM模型比CNN更能获得文本的语义信息。
(2) 通过对比LSTM和BiLSTM模型在该语料上的实验结果可知,BiLSTM在LSTM基础上加入了后向传播单元,可以获得更多的文本语义,实验结果往往比LSTM更优。
(3) BiLSTM模型和ATT-BiLSTM模型的实验结果并没有达到预期的效果,而在BiLSTM上加入基于词向量的注意力机制的Word2Vec-ATT-BiLSTM模型效果得到了提高,这也说明正确加入注意力机制有助于模型的效果提升。
(4) 通过对比PDRBL模型和ATT-BiLSTM模型在该语料上的实验结果可知,使用Word2Vec词向量能够保留词语间的语义信息,减少其中的信息丢失,对于实验结果有一定的提升。
PDRBL模型作为TETP方法中判定时态的关键部分,通过输出结果判定不同时间段中话题的演化时态,为TETP方法有效追踪话题演化过程奠定了基础。为验证TETP方法的有效性,本文基于疫情数据集和复工复产数据集给出两个演化案例。
如图11所示的“疫情”话题的演化,TETP方法通过PDRBL模型提取文本主题,判定不同时间段内的主题演化时态。按照时间顺序描述疫情从武汉发现病历开始,逐渐从地点、感染、治愈、死亡等方面发生一系列变化。

图11 “疫情”话题演化图
如表6所示,本文采用TOP-N关键词的形式展现结果,表述了疫情后复产复工状态的变化。将数据集按照时间跨度划分10等份,表中的数据显示复产复工从疫情爆发期间到后期 逐 渐恢复的过程,如事件开始时由于疫情原因存在“病例”“涨价”等关键词;然后,出现“返程”“物资”等关键词,表明逐步开始复工复产;最后,“建设”“经济”等关键词出现,表明全面的复工复产,这些变化与TETP得出的结论一致。
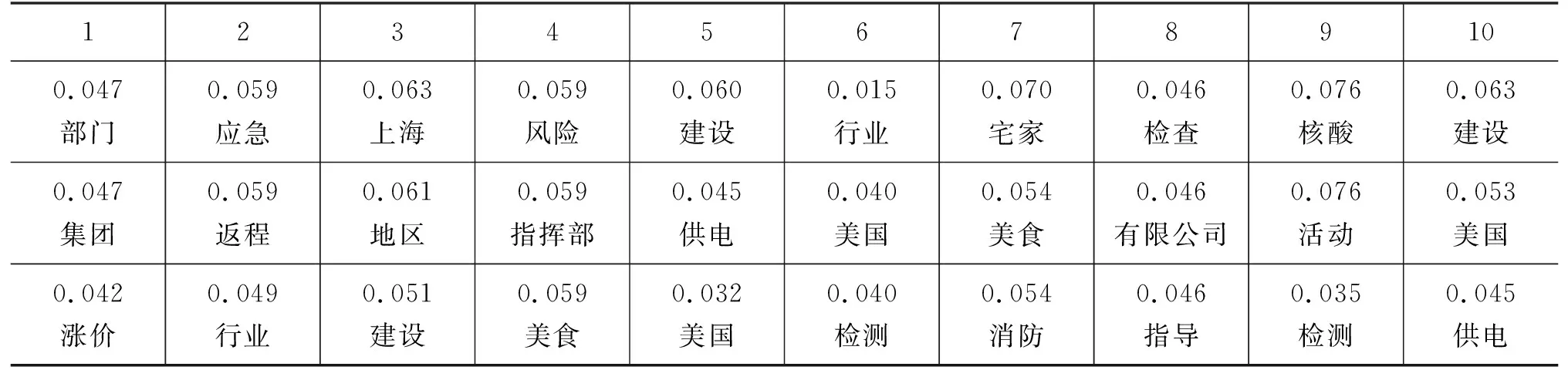
表6 疫情后复工复产状态表
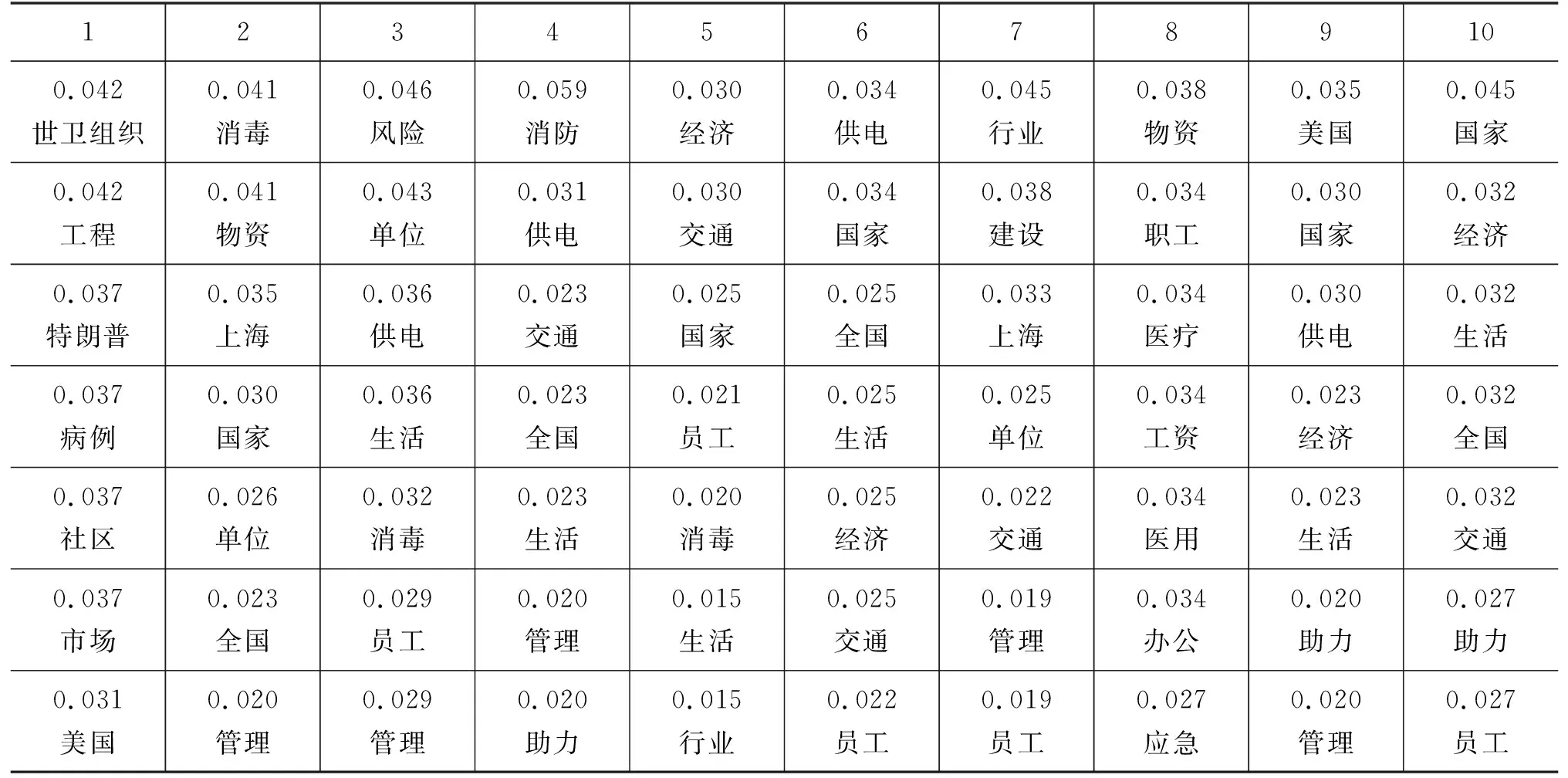
续表
4 结论
本文提出了一种文本邻近度判定模型PDRBL,基于此提出TETP话题追踪方法,用于分析社交媒体信息,观察话题演变过程。与传统主题模型和深度学习模型不同,PDRBL模型结合LDA与注意力增强的孪生BiLSTM网络,使用LDA提取文本关键词,将BiLSTM学习文本语义信息的能力使用在词向量上,并建立注意力机制加强对文本全局信息的把握。实验表明,本文提出的PDRBL模型表现出优越的性能,并在多个指标上超过了现有模型。
TETP话题追踪方法完善了对于话题演化的描述,模拟了不同时间间隔的话题转换。通过实验证明了该方法的有效性,但是由于LSTM等序列模型属于递归模型,所以它的并行能力较弱,耗时较长,后期会在此方面做进一步的改进。
