基于逐步回归的工程造价预测模型构建
2022-04-12邹梅松石华川
邹梅松,古 欣,石华川
(1.重庆中烟工业有限责任公司,重庆 400039;2.中国轻工业成都设计工程有限公司,四川 成都 610000)
1 引言
逐步回归过程是将变量引入一个模型,构建一个检验过程解释模型中的变量,当模型中的变量不再显著时,控制该变量删除,控制回归方程只含有显著性变量[1]。工程造价是卷烟厂建设工程中重要的工作,从卷烟厂建设工程前期准备阶段起,综合建设工程的设计、管理阶段,预测得到工程的花费[2]。预测黔江卷烟厂建设工程的造价,能够为工程建设初期的决策人员提供决策意见,在工程建设过程中,能够有效地控制工程各项开销,形成一个科学化的预测过程[3]。因此,在逐步回归的支持下,构建建设工程造价预测模型。
国外构建工程造价预测模型起步较早,以机器学习算法作为支持,汇总了多种影响因素,构成工程造价预测模型[4]。国内研究预测模型起步较晚,最初以指数平滑作为算法的处理依据,利用主成分分析汇总为模型的指数[5],构建形成工程造价预测模型。从文献[6]中的预测模型来看,利用逐步回归方法有效提取建设工程造价数据,采用多重共线处理过程控制预测模型的泛化过程,形成了工程预测过程。从文献[7]中的预测模型来看,以工程造价的影响因素作为预测模型变化指标,结合灰色模型构建造价控制约束函数,并以该约束函数作为造价预测模型的数值约束关系。经过阶段性的工程预测后,现有的工程造价模型求解得到的预测变量数值偏差过大,导致预测模型内函数拟合优度数值较小,模型内选定的指标关联性较差,针对该问题,构建基于逐步回归的黔江卷烟厂建设工程造价预测模型。
2 基于逐步回归的预测模型构建
2.1 利用逐步回归算法更新预测变量
在采用逐步回归算法整理预测变量时,将历史预测变量数据标准化处理后[8-9],计算数据的均值,可表示为:

其中,x表示数据均值,xi表示建设工程变量,n表示变量的数量。根据计算得到的均值确定数据中的标准值,为控制参与模型构建指标的数量,更新处理数据变量的偏定系数,数值关系可表示为:

其中,Uk表示偏定函数,ri表示更新函数,k表示重复更新次数。对应上述更新处理过程,选定偏决定参数较大的数值作为自变量,不断检验自变量的显著性,检验过程可表示为:

其中,Up表示数值逆变函数,M表示显著参数,其余参数含义不变。当检验得到的自变量显著性较强时,将rk-1转换为决策过程,不断剔除造价变量中不显著变量,整理更新处理得到的变量数据后,设定黔江卷烟厂预测数据变化区间,形成一个有效的预测过程。
2.2 设定数据区间
在设定黔江卷烟厂建设工程预测数据区间时,采用MATLAB软件模拟仿真数据,采用最小二乘法处理造价数据中的惩罚系数以及宽度系数,设定造价数据的上下限数值区间,区间数值可表示为:

其中,uk表示造价函数,ui表示数据隶属度函数,α表示置信参数。在上述数值的控制下,以工程数据的历史残差作为对比标准,数据区间表达如图1所示。
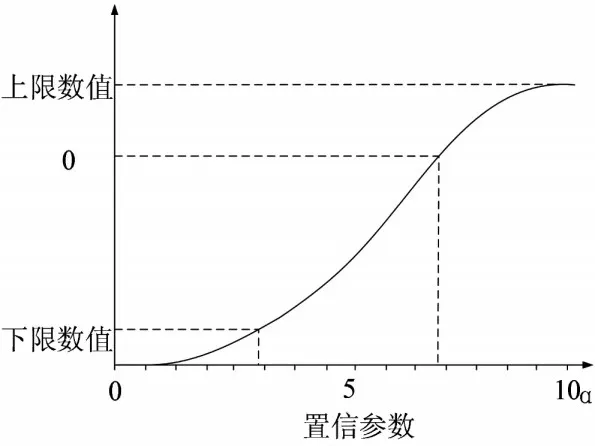
图1 数据区间表达
在图1所示的数据区间表达变化下,采用类样本加权训练造价数据区间,整理造价数据的区间估计数值,数值可表示为:

其中,PL表示下限数值,Pu表示上限数值,PI表示置信参数。在整理造价数据的区间估计数值后,引入支持向量机聚类为不同类别的数据组,综合卷烟厂建设工程的工程技术参数,选定最优数据组,构建造价预测模型。
2.3 完成预测模型的构建
以上述处理过程作为预测模型组合数据,在构建预测模型时,组合预测函数的权重,数值关系可表示为:

其中,Q表示组合函数的误差,wa表示数值拟合参数。在预测数值关系控制下,拟合工程建设过程中产生的质量指标,形成的拟合目标函数,数值关系可表示为:

其中,C(Q)表示构建的拟合目标,et表示拟合处理过程中产生的拟合误差函数。在控制预测模型的精度时将拟合处理的样本数据分割处理为多个数据范数值,控制拟合误差参数数值最小,以设定的约束数值关系作为标准,在平面空间范围内绘制变化线段,整理散落在标准线段周围的造价数据点,标准数值的线性变化及整理过程如图2所示。
在图2所示的预测整理过程下,选定接近标准线段的数据点,并整理为预测数值矩阵,整理得到的数值关系可表示为:
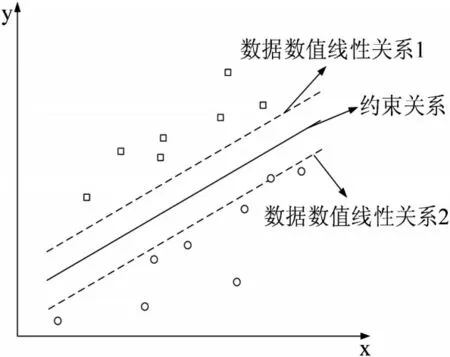
图2 数值预测整理过程

其中,R1表示数值产生的伴随变化函数,Et表示单向预测函数。以上述构建得到的数值关系作为最终的预测数值模型。综合上述数值处理过程,最终完成预测模型的构建。
3 仿真实验
3.1 实验准备
准备二十组黔江卷烟厂建设工程所产生的数据,工程数据如表1所示。

表1 样本数据
在表1所示的样本数据下,准备CPU 型号为Inteli7、内存容量为16GB 的计算机,作为模型验证的上位机。对应上述统计采集的数值指标,在上位机内部建立指标逻辑关系,逻辑关系如图3所示。

图3 构建的指标逻辑关系
在图3构建的指标逻辑关系下,准备文献[6]和文献[7]两种传统预测模型与所设计的预测模型进行测试,对比三种预测模型的性能。
3.2 结果及分析
在上述实验环境下,调用工程层高、混凝土价格、钢筋价格以及工期作为预测指标,根据工程实践过程可知,单一指标的变化可能会引起多个预测指标产生变化,假定三种预测模型均调整高指标,指标的初始因素参数为0.1,定义其他指标随从变化的敏感性,数值关系可表示为:

其中,λ表示设定的单位指标参数,n表示随从参数,f 表示数值变化幅值。在上述数值关系控制下,得到预测模型对相同预测指标的敏感性,敏感性结果如图4所示。
控制三种预测模型处理相同的预测指标,在定义的敏感度数值关系下,固定指标的幅值变化参数,以指标交汇点对应的敏感度数值作为最终的实验结果。当预测模型的敏感度参数越大,则表示该种预测模型的预测结果越精确。根据图4中所示的实验结果可知,文献[6]预测模型的敏感度数值为0.4,该种预测模型的精度较差。文献[7]预测模型的敏感度数值为0.5,预测模型的预测精度较佳。而所设计的预测模型敏感度数值为0.65,与两种传统预测模型相比,所设计的预测模型敏感度数值最大,该
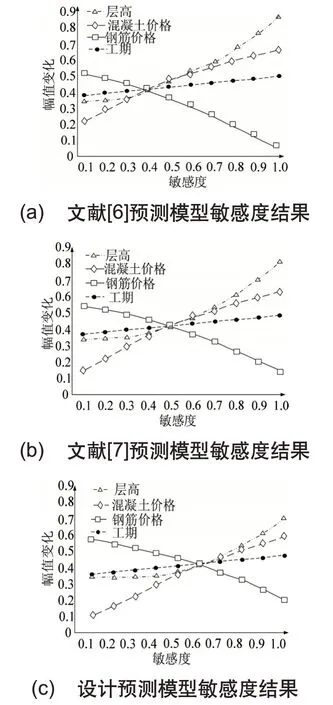
图4 三种预测模型敏感度结果
种预测模型精度最佳。
保持上述实验环境不变,使用三种预测模型处理准备的卷烟厂建设工程预测参数,调用三种预测模型中的回归预测方程,计算回归方程的拟合优度,数值关系可表示为:

其中,R2表示计算得到的拟合优度,SSE表示残差平方和,SST表示总平方和。在上述数值关系的控制下,计算并统计三种预测模型的拟合优度结果,数值结果如表2所示。
对应构建的拟合优度判断数值关系,在计算不同工程预测编号时,根据表2所示的实验结果可知,文献[6]预测模型得到的拟合优度数值在0.75 左右,预测模型选定的指标间的相关性较差。文献[7]预测模型得到的拟合优度数值在0.86左右,拟合优度数值较大,对应预测模型内设定的预测指标相关性较强。而所设计的预测模型得到的拟合优度数值在0.94左右,与两种传统预测模型相比,所设计的预测模型得到的拟合优度数值最大,模型内选定指标间的相关性最强,更加适合在卷烟厂建设工程预测过程中应用。
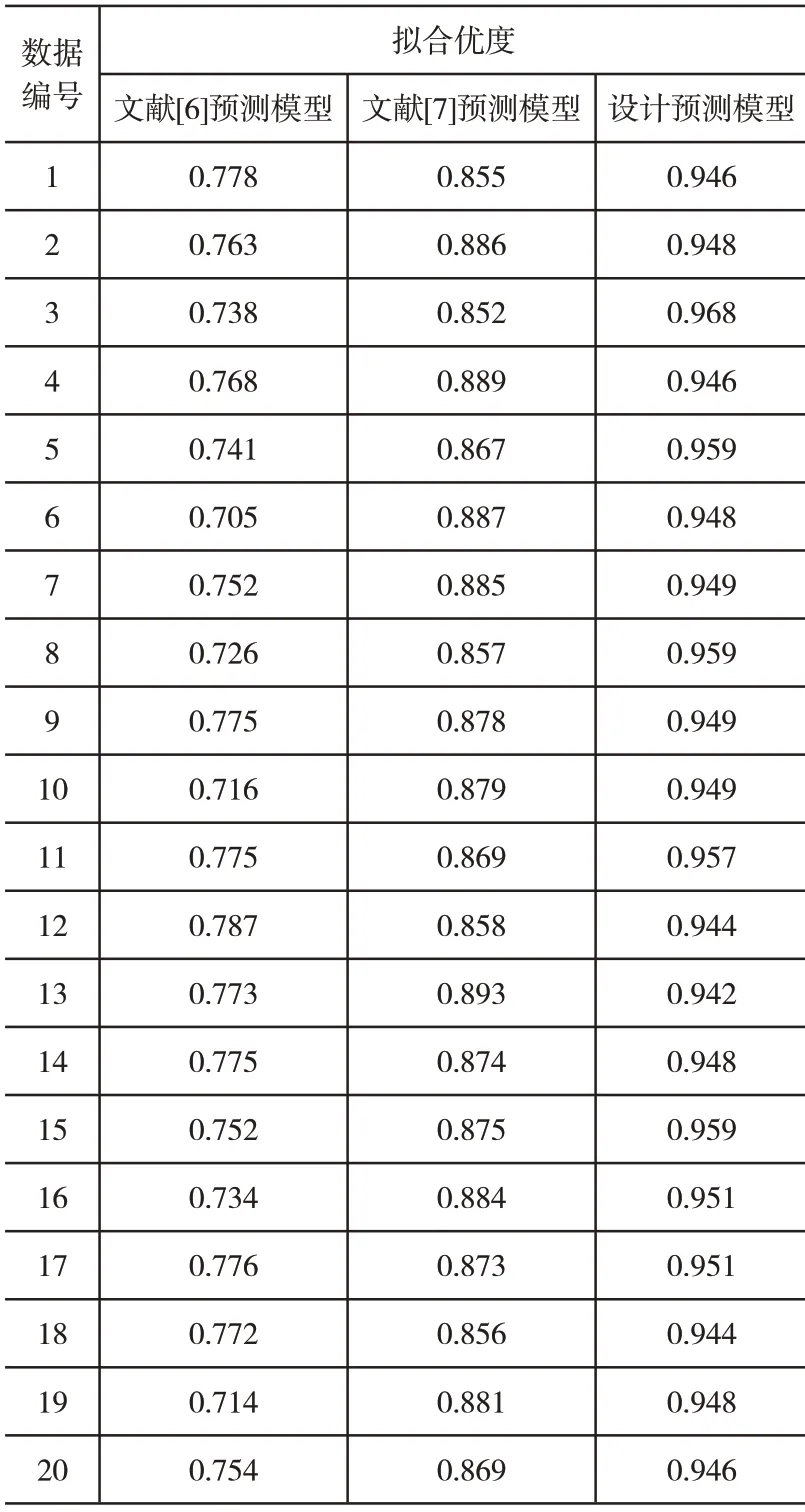
表2 三种预测模型的拟合优度结果
4 结束语
在现代工程建设发展下,如何构建科学化精度化的预测模型成为了当下的研究热点。在逐步回归技术的支持下,构建预测模型,能够改善传统预测模型中函数关系拟合优度数值较小,模型内预测指标关联性较差的不足。为今后构建预测模型提供理论及数据支持。
