基于Bi-LSTM的人机语音交互*
2022-04-12陶浩兵慕京生刘东阳辜丽川
张 锋, 陶浩兵, 慕京生, 刘东阳, 辜丽川, 焦 俊
(1.安徽农业大学 信息与计算机学院,安徽 合肥 230036; 2.京徽蒙农业科技发展有限公司,安徽 亳州 236800)
0 引 言
随着人工智能技术的快速发展,语音识别作为一种人机交互的工具而备受人们的喜爱,国际上很多大型科技公司,如谷歌、微软、百度等相继在语音识别上投入大量资源进行研究,并取得了不错的研究成果,Siri、Google Now、Echo等相继诞生。国内学者也对语音识别与机器人控制展开研究,并取得了一些成果,谭丽芬等人实现了语音交互技术在机械臂遥操作中的应用[1],李艳生等人实现了基于语音的移动式机器人控制系统设计[2]。
20世纪80年代,隐马尔可夫声学模型(hidden Markov model,HMM)被应用于大词汇连续语音识别研究[3],但语音识别技术并未取得突破发展。到21世纪,神经网络的研究取得突破进展,深度神经网络(deep neural network,DNN)、卷积神经网络(convolution neural network,CNN)、循环神经网络(recurrent neural network,RNN)等相继被提出,一些研究者将其引入语音识别声学建模中,语音识别技术获得飞跃式发展。研究表明,RNN能够挖掘序列中上文的相关信息,在时序相关的问题上表现得比DNN和CNN好[4]。RNN在情感分析、语音识别、股票分析等序列化的特征任务上表现良好,但在实际训练过程中会面临梯度消失与梯度爆炸问题[5]。针对RNN在训练过程中存在的问题,研究并提出了关于RNN的变体,其中最流行的方案是使用门控循环单元(gated recurrent unit,GRU)或长短期记忆(long short-term memory,LSTM)网络架构[6,7]。本文利用双向LSTM(bidirectional LSTM,Bi-LSTM)网络搭建语音识别模型,并将其在自己制作的语音库中进行训练与优化,结合训练好的语音识别模型制作机器人远程语音控制终端,实现了通过语音远程控制机器人的运动状态以及云台的转动。
1 LSTM与Bi-LSTM
1.1 LSTM
LSTM是RNN的一种变体,能够学习到长期依赖关系。LSTM引入了一个叫做细胞状态的连接,这个细胞状态用来存放想要记忆的内容,LSTM通过三个门来对细胞状态进行更新,分别为忘记门、输入门、输出门[8~11]。图1为LSTM单元结构图,其中,x为输入的数据,h为LSTM单元的输出,C为细胞状态。LSTM单元的输入与输出关系可以通过式(1)~式(6)表示
ft=σ(Wf×[ht-1,xt)]+bf)
(1)
it=σ(Wi×[ht-1,xt)]+bi)
(2)
(3)
Ct=ft×Ct-1+it×t
(4)
ot=σ(Wσ×[ht-1,xt)]+bo)
(5)
ht=ot×tanh(Ct)
(6)
式中σ为Sigmoid激活函数;i,f,o,C分别对应输入门、遗忘门、输出门及细胞状态。三个门的存在,使得LSTM能够控制梯度的收敛性,从而梯度消失、梯度爆炸的问题得到缓解,同时也能够保持长期的记忆性。
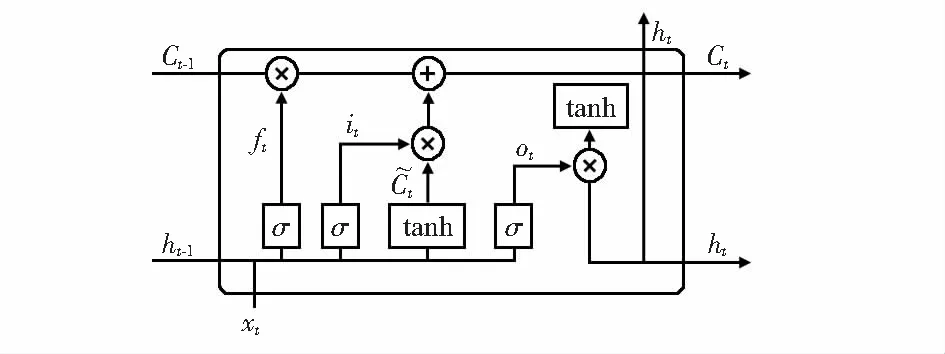
图1 LSTM单元结构
1.2 Bi-LSTM
LSTM网络可以利用某一时刻之前的输入信息来预测结果,但有时预测可能需要由过去若干输入和未来若干输入共同来决定,这样得出的结果更加准确,由此,Schuster M等人在循环神经网络的基础上提出了双向循环神经网络[12]。图2为一个Bi-LSTM网络结构图,包含一个前向LSTM层和一个后向LSTM层,图中有6个独特的权重在每一个时步都会被重复利用,分别为输入层到向前向后隐含层权重(W1,W3),隐含层到隐含层权重(W2,W5),隐含层向前和向后的权重(W4,W6),训练过程中向前和向后的隐含层之间没有信息交流,互不干扰。前向LSTM层从1时刻到t时刻正向计算,并保存每个时刻前向LSTM层输出;后向LSTM层从t时刻到1时刻反向计算,并保存每个时刻后向LSTM层输出。最后在每个时刻结合前向和后向LSTM层输出得到最终输出,其计算式如式(7)~式(9)。其中,ht,h′t分别为t时刻正反向LSTM层的输出,ot为t时刻模型最终的输出
ht=f(W1xt+W2ht-1)
(7)
h′t=f(W3xt+W5h′t+1)
(8)
ot=g(W4ht+W6h′t)
(9)
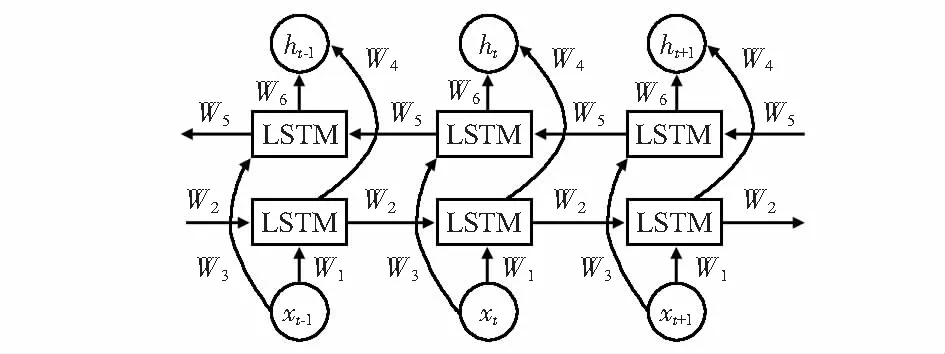
图2 Bi-LSTM网络结构
2 基于Bi-LSTM的语音识别模型
2.1 语音库与语音标注
为实现基于Bi-LSTM的机器人人语音交互,首先以采样率8 000,单通道,8位采样点的采样参数录制关于机器人控制命令的音频,包括“前进”“后退”“左转”“右转”“停止”“加速”“减速”“云台左转”“云台右转”“云台上转”“云台下转”,以及“零”到“十”,总共22种语音,每种语音录制50个样本,样本总数为1 100。
2.2 音频数据预处理
数据在输入模型前,需要根据模型算法的需求对数据进行变换,以改善模型的训练效果。本实验提取音频的梅尔频率倒谱系数(MFCC),将音频数据转换为MFCC特征向量。提取MFCC包括对语音的预加重、分帧、加窗、快速傅里叶变换(fast Fourier transform,FFT)、滤波等操作[13,14]。
2.3 构建Bi-LSTM模型
本文采用Bi-LSTM构建网络,模型共分6层,由全连接层与LSTM层组成,其中第4层采用LSTM架构设计的单层Bi-LSTM网络,最后一个全连接层用于SoftMax分类。激活函数采用带截断的ReLU[15],截断值设为10,其计算式如式(10)。由于网络中节点较多,学习功能强大,为了防止过拟合,在每层均添加Dropout层。语音识别属于典型的时间序列分类问题,此类问题使用ctc_loss的方法计算损失值,优化器选用AdamOptimizer
f(x)=min(max(x,0),10)
(10)
2.4 模型训练与结果分析
实验采用TensorFlow框架来构建网络模型,主要探究不同隐含层节点数与不同Dropout值对网络的影响,争取用较少的隐含层节点训练出符合要求的网络模型。
首先,研究不同隐含层节点个数对Loss值变化的影响。当学习率为0.001,迭代次数为40,Dropout值为0.8时,探究隐含层节点数分别为128,256,512时Loss值的变化,其结果如图3所示。从图3中可知,在三条曲线中,隐含层节点数为128时,网络学习信息的速度最慢,迭代到40次时Loss曲线才衰减到0.5左右;隐含层节点数为512时,Loss曲线衰减速度最快,迭代到20次左右时,Loss曲线已经接近零值,曲线开始趋于平稳。
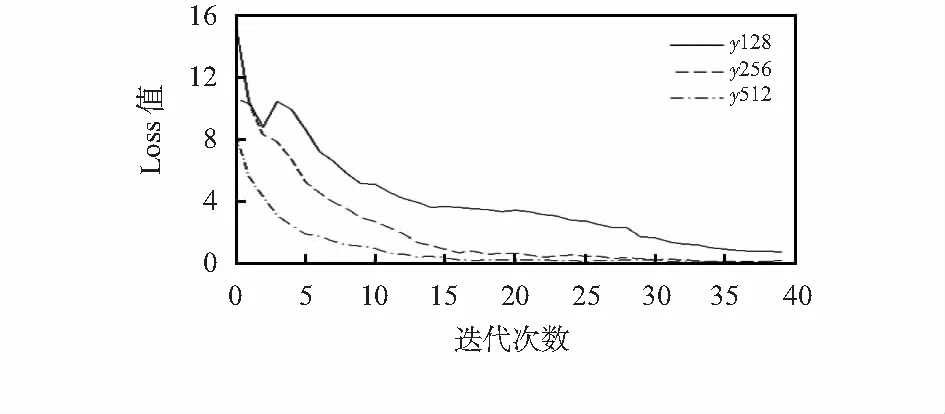
图3 不同隐含层节点数的Loss曲线
接着,研究不同Dropout值对Loss值变化的影响。当学习率为0.001,迭代次数为40,隐含层节点个数为512时,探究Dropout值分别为0.7,0.8,0.9时Loss值的变化,其结果如图4所示,为了使曲线比较较为明显,从第5次迭代开始显示。从图4中可知,Dropout值为0.9时,Loss曲线衰减速度最快,曲线更平滑,曲线后面未出现明显抖动。
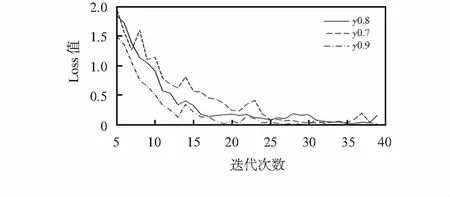
图4 不同Dropout值的Loss曲线
综上所述,本实验最后设置网络参数为:学习率0.001,迭代次数40,隐含层节点数为512,Dropout值为0.9。本文作者通过句错误识别率(sentence error rate,SER)和句正确识别率(sentence correct,S.Corr)来评价模型的识别效果,其计算式如式(11)。接着选3名同学,分别对“前进”“加速”“云台左转”“云台下转”四种命令各录制5段音频,测试结果如表1所示,第一列中1,2,3分别代表3名学生,中间4列的数字代表某一同学对某一命令录制的5段音频正确识别的个数,由表中可知,对各种命令的整体识别率达到80 %以上,达到了预期效果,其中第一名同学的语音识别效果最好,第三名同学的语音识别效果较差,可见发音标准对语音识别率有一定的影响
(11)

表1 测试结果
3 机器人测控节点设计与实现
3.1 机器人测控节点设计
节点主要由嵌入式开发板、四合一传感器、氨气传感器、数字摄像头、双自由度云台等组成。采集节点以NanoPC—T4嵌入式开发板为核心,分别通过串口连接数字摄像头采集图像信息,通过RS—485转串口连接四核一传感器与氨气传感器,采集周围环境的温度、湿度、光照、CO2以及氨气数据,通过GPIO口连接云台,通过控制20 ms内GPIO口输出高低电平的变化来控制云台的转动角度,将摄像头安装在云台上,控制云台双自由度的转动来实现对周围环境图像的多方位采集。
3.2 基于用户数据报协议的数据传输
节点采集图像数据,实现两种传输方式:连续与定时。定时模式可以通过设置定时器时间来改变图像传输时间间隔,连续即实现图像实时传输,其对于实时性、连续性有很高的要求,要求传输的时延尽量小,能够容忍一定范围内的数据丢失,以达到传输图像的连续显示,因此,本节点系统选用用户数据协议(user datagram protocol,UDP)进行数据传输。
使用UDP进行通信时,为了保证通信双方能够正确解析接收到的数据,需要对数据帧的格式进行约定。帧分为帧头与数据两部分,帧头放一些控制信息(帧头设计如表2所示),其中,前导码设置为0xEAFB,接收端通过前导码判断是否为需要接收的数据,通过功能码来区分图片数据与环境数据,当功能码为0xFA时;帧的数据部分放的是图片数据,当功能码为0xBE时,帧的数据部分放的是环境数据。

表2 帧头格式表
由于图片文件较大,所以需要对图片进行切片传输,图片切片及封装成帧的过程如图5所示。

图5 图片切片及封装过程
主要分为如下几步:1)计算需要传输的图片数据大小;2)将图片大小A与帧的数据部分大小B进行比较,如果A小于等于B,则不需要进行切片,可以通过一帧直接将一张图片发送完成,否则需进行切片,进入步骤(3);3)以B的大小对图片进行切片,并记录下切片大小与数据偏移量等信息;4)将切片封装成帧,帧号、数据偏移量等控制信息放在帧头,切片放入帧的数据部分,封装后以UDP发送到接收端,循环发送,直到一张图片的数据全部发送完成。
3.3 控制架构与电路
本文的机器人为履带式机器人,将多媒体信息采集节点安置在履带机器人上,实现了多功能、移动式信息采集平台的设计,如图6所示。机器人采用STM32开发板作为机器人控制板,控制板通过驱动器来实现对机器人的控制,后台与控制板之间通过LoRa模块进行通信,STM32控制板接到数据后,会与预设控制命令进行匹配,若匹配成功,则启动相应中断程序,通过定时器来改变对应引脚输出脉冲的周期与频率,驱动器会根据脉冲信号对电路中的电流进行放大,来驱动左右直流电机实现不同的转动状态,达到控制小车的目的。

图6 机器人平台实物
4 基于Bi-LSTM的远端控制与显示
4.1 基于Bi-LSTM的远程控制
基于前文利用Bi-LSTM网络所训练的模型,本实验设计了一个基于语音识别的远程控制界面,如图7所示,在界面的左端为音频输入设备与音频参数的设置区,本实验音频参数设置为固定的采样率8 000、单通道等,以提高模型的识别率,右端为实时输入音频波形图,通过观察波形图的变化可以判断有没有声音进入。当点击界面上的开始录音后,程序开始录音,点击停止结束录音,程序会将音频数据保存为.wav文件,并调用训练好的模型进行识别,接着将模型反馈的识别结果与命令库中预设命令进行比较,若反馈信息与控制命令匹配成功,右下角会显示发送命令,向节点发送相应控制命令,如控制机器人前进、后退、云台转动等,若不匹配则显示未匹配,不进行任何操作。

图7 语音识别界面
4.2 回传信息处理
服务端程序基于UDPSocket套接字函数与节点进行通信,主要实现数据接收显示、节点交互控制、数据存储三个功能。程序界面如图所8所示,左侧为图像显示区,右侧为传感器参数显示区与节点控制区,节点控制区提供了多种远程控制指令,如图片的连续/定时传输控制、环境参数采集定时器时间控制、云台转动方向控制等。同时,服务端会对数据进行存储,程序先将接收到的数据在本地进行存储,然后根据设定的实际定时从本地读取图片上传FTP服务器,同时将图片数据的地址信息及采集的环境参数存入云服务器的MySQL数据库中。
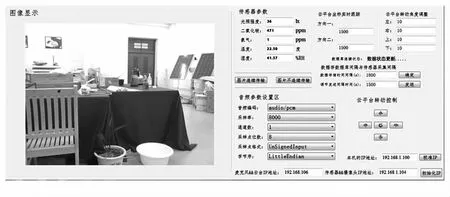
图8 程序界面
5 结束语
本文利用TensorFlow框架搭建了Bi-LSTM网络,将其在自己制作的数据集上进行训练,分析了不同参数对网络的影响,选取恰当的参数训练出模型,对其进行测试,识别率达到80 %以上。同时本文设计了基于嵌入式的多媒体信息采集平台,实现对周围图像、环境信息的采集,并结合语音识别模型设计了机器人远程语音控制终端,通过语音控制机器人的运动状态与云台转动。
未来可以在多种不同噪声环境下录制音频,训练更具有泛化能力的模型。同时,本文设计的语音识别控制终端还存在一些不足以及局限,后续将完善语音控制反馈,语音控制命令等内容。
