面向视觉问答的跨模态交叉融合注意网络
2022-04-12彭亚雄陆安江
王 茂,彭亚雄,陆安江
(贵州大学大数据与信息工程学院,贵阳 550025)
0 引言
视觉问答(Visual Question Answering,VQA)用于自动回答与图像内容相关的自然语言问题,是结合自然语言处理、计算机视觉和人工智能领域的多模态学习任务,用来处理图像、自然语言和综合推理等多个领域的问题,因此VQA 任务使人工智能的研究超越了单一任务,需要视觉和语言的综合推理,VQA 模型如图1 所示。VQA 技术可以应用于交互式机器人系统、追踪自动量化评估任务进度、儿童早教和医疗援助等,研究VQA 可以进一步推动人工智能的发展,对实现人工智能化社会具有重要意义。
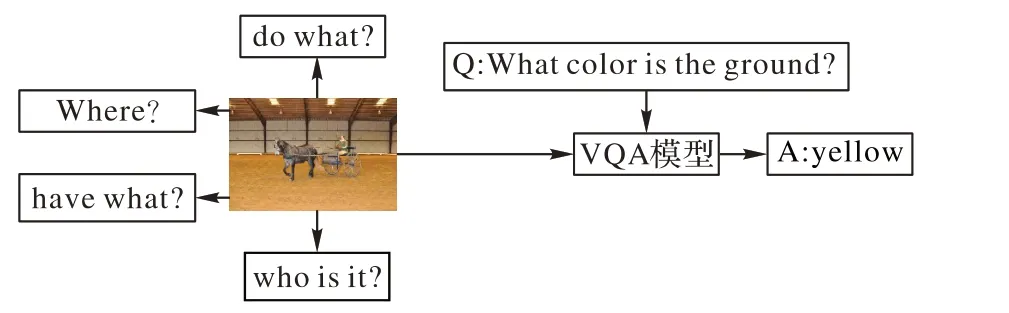
图1 VQA模型Fig.1 VQA model
随着深度学习(Deep Learning,DL)领域注意机制的发展,已经成功应用于VQA 任务。基于视觉注意的方法已经成为精确理解VQA 模型的一个重要组成部分,除了视觉注意方法之外,共同注意方法也取得了巨大成功[1-3],共同注意方法关注图像的重要区域和问题的关键词,以学习视觉注意和文本注意。目前图像的特征提取逐渐由VGG 网络转为使用He 等[4]提出的ResNet,问题的特征提取则利用长短期记忆(Long Short-Term Memory,LSTM)网络,多模态特征表示在提高VQA 性能方面起着重要作用。Yu 等[5]提出了多模态双线性矩阵分解池化(Multi-modal Factorized Bilinear pooling,MFB)模型,先将不同模态特征扩展到高维空间用点乘方法进行融合,之后进入池化层和归一层,以将高维特征挤压成紧凑输出特征;Fukui 等[6]提出了一种联合嵌入视觉和文本特征的方法,通过将图像和文本特征随机投影到更高维空间,然后将这两个向量在傅里叶空间中进行卷积执行多模态紧凑双线性池(Multi-modal Compact Bilinear pooling,MCB)操作,以提高效率;赵宏等[7]提出了一种图像特征注意力与自适应注意力融合的图像内容中文描述模型;陈龙杰等[8]针对图像描述生成中对图像细节表述质量不高、对图像特征利用不充分、循环神经网络层次单一等问题,提出基于多注意力、多尺度特征融合的图像描述生成算法。目前的视觉问答通过自适应学习问题局部细粒度图像特征,在视觉问答任务中引入了注意力机制。Chen 等[9]提出了一种新的多模态编解码注意网络,通过将关键字查询与重要的对象区域最小化相关联来捕获丰富且合理的问题特征和图像特征;Yang等[10]提出了一种堆叠注意力网络来迭代学习注意力,然而问题信息仅通过系数p进行表达,限制了学习联合表示的能力;Nguyen 等[11]提出了密集联合注意模型来模拟每个问题和每个图像区域之间的完整交互;Gao 等[12]和Yu 等[13]提出了几种基于深度联合注意的新模型,在VQA 任务上取得了较好的性能。
上述算法在VQA 方面取得一定的效果,但在特征提取融合、注意力机制等方面仍存在局限性,提取特征不完全以及图像注意力信息的缺失,都会制约模型的学习能力,影响视觉问答效果。此外,上述联合注意模型因为忽略了两者之间的密集交互不能推断任何疑问词和任何图像区域之间的相关性。为了解决上述问题,本文提出了面向视觉问答的跨模态交叉融合注意网络(Cross-modal Chiastopic-fusion Attention Network,CCAN),利用改进的残差网络对图像进行注意,提高图像注意的准确性,并提出新的联合注意力机制,对问题和图像特征进行联合表示,提高两者的交互性,同时采用交叉融合的方法,提高了模型的分类精度,实验结果说明了CCAN 的有效性。
1 面向视觉问答的跨模态交叉融合注意模型
本章主要介绍了面向视觉问答的跨模态交叉融合注意模型,该模型主要包括三个模块:问题嵌入提取、图像特征提取、特征融合与分类。CCAN 模型的整体架构如图2 所示。

图2 CCAN模型框架Fig.2 Framework of CCAN model
1.1 问题词注意特征提取
句子嵌入有两个作用:1)引导图像自上而下的注意力学习;2)作为多模态学习的输入之一,在输入分类器之前与图像特征融合。将问题Q 中的每个单词映射为一个向量,依照从前往后的次序进行处理,即从第一个单词到第i个单词的次序进行运算,问题编码部分主要是对问题进行编码获得特征向量,[q1,q2,…,qN]是问题的单词序列,其中qi∈Rdw×1是第i个单词的one-hot 表示,dw是单词词汇表的大小,N是问题中的单词数,由嵌入矩阵We∈Rdx×dw,即可以得到中间表示xi=Wewi之后将xi送入LSTM 模型以生成新的表示qi∈Rdq×1,公式如下:

其中:dq是LSTM 单元的输出尺寸,dx是中间表示xi的尺寸。
为了获得更具有语义关系的问题表示,对问题进行自注意,关注重要词与词之间隐含语义关系。在进行注意时,问题的每个词根据其在问题中的重要性计算出一个权重值,问题表示向量vw∈Rdq×1是通过计算从LSTM 生成的所有单词表示加权和获得,即:


1.2 基于改进的残差通道自注意提取图像特征
图像特征的提取主要分为两个部分:1)利用目标检测模型ResNet-152 学习图像的硬注意;2)利用改进的残差通道注意增强特征。首先,在残差网络的基础上利用了特征通道之间的相互依赖性,让网络注意到更多信息,其中每个通道积的特征生成不一样的权重;其次,引入最小阈值化处理,旨在根据图片对每个区域进行评分,减少不重要图像区域的影响。
ResNet-152 提取图像特征 如式(4)所示,本文使用ResNet-152 进行特征提取,为了获得图像I不同区域的特征向量,将图像输入到ResNet-152 模型进行特征提取,经过ResNet-152 的最后一个池化层res5c 后输出图像的特征表示V∈Rk×2048,其中k∈[10,100]为物体区域数,Rk×2048是对应于第N个区域的2 048 维特征向量。

改进的残差通道注意模型提取特征 受残差学习的启发,本文引入残差通道自注意模块,使网络集中于更有信息量的特征。本文利用特征通道之间的相互依赖性,产生通道注意机制,并且引入最小阈值化以消除不重要的特征,有效地学习了视觉和语言信息的联合表示,进一步增强图像特征。原始残差网络,其内部残差块使用跳过连接,网络结构如图3 所示,通过跳跃连接将输入x和x的非线性变换F(x)相加,从而可以减轻深度神经网络中由于增加深度而导致梯度消失的问题,公式如下:

图3 原始的残差网络结构Fig.3 Original residual network structure

其中F(x)是基于残差模块的框架上,引入通道注意和最小阈值化,其网络结构图如图4 所示。
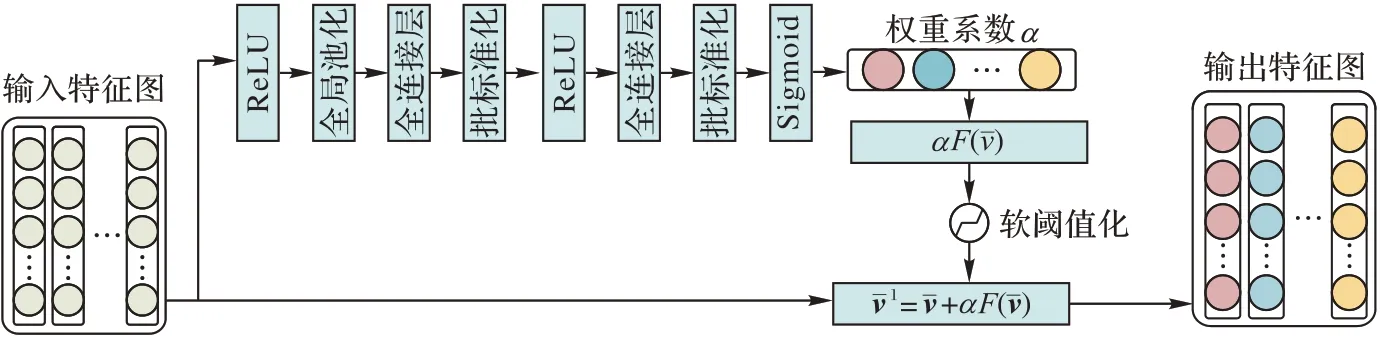
图4 残差通道自注意网络结构Fig.4 Structure of residual channel self-attention network
本文将图像的注意权重转化为期望,图像I的期望可以表示为:

其中v是ResNet-152 最后一个rec 层输出的图片特征,ci是对图片进行通道注意的特征表示,通道注意对v进行Squeeze、Excitation 和特征重标定,∘表示点乘,conv(•)是由线性整流单元(Rectified Linear Unit,ReLU)和卷积层组成的卷积学习运算,图片引导的区域注意可以表示为:

提取到通道注意特征vˉ后,将它的注意力权值加入到图像特征中,即利用残差自注意进一步增强图像特征。对残差网络进行改进,首先对输入特征求绝对值和全均值池化,之后输入到一个小型全连接网络,全连接层由卷积层、批标准化、激活函数、全局均值池化以及全连接输出层构成,并以sigmoid 为最后一层得到一个权重系数α,最后利用残差自注意增强图像,公式如下:

1.3 跨模态交叉融合注意模型
跨模态交叉融合注意模型利用残差通道自注意增强图像特征,为了充分利用自然语言问题消除图像特征冗余,采用问题引导双头注意进一步提取与问题相关的图像特征。根据自然语言问题,利用自上而下的注意力计算问题与36个目标图像特征中每个目标之间的概率,从而获得注意力权重,注意力权重乘以图像特征产生最终的图像表示。
与单向、堆叠或多头注意力不同,本文使用不共享参数的双头软注意力结构,公式如下:

其中:f表示全连接神经网络,vˉi表示通过残差通道自注意增强的图像特征,q表示问题特征,q_Attw表示通过词注意自我关注的问题特征。将两个注意力权重通过softmax 函数归一化,并进行相加得到最终的注意力权重β,公式如下:

注意力权重用于对所有图像特征进行加权求和,得到最后的图像特征,融合问题嵌入进行最终分类,公式如下:

本文使用的跨模态交叉融合注意是双头软注意,由于原来的单注意模型不适合VQA 任务的特点,原有的单一注意力模型使用softmax 函数对注意力权重进行归一化,使得注意力模型只根据输入选择最感兴趣的键值对,不符合VQA任务中问题可能有多个正确答案的情况。
最后,将问题嵌入和图像特征分别通过相应的非线性层,利用两个交叉融合注意对两个特征进行表示,使用逐元素相乘的方法融合两个特征,问题和图像的联合表示如下:

其中:h是图像和问题的联合嵌入,⊙代表逐元素相乘。fq(q)和()代表非线性层。
1.4 答案预测和损失函数
本节设计了一个由两个全连接层组成的多层感知器(Multi-Layer Perceptron,MLP)层来转换问题特征和图片特征,然后通过softmax 函数计算问题词特征的注意权重,最终关注的问题特征可以通过汇总关注权重和相关问题词特征的乘积表示,关注特征式子如下:

其中,MLP 表示线性变换操作,本文选择概率最大的候选答案作为最终答案。为了训练本文模型,使用KL 散度(Kullback-Leibler Divergence,KLD)损失函数来预测∝E:

其中yi∈[0,1]是时第i个真实答案的出现概率。
2 实验
本章对所提模型在VQA 任务中的性能进行评估,并使用VQA v1.0 数据集进行验证。首先对CCAN 模型与之前研究的模型进行对比实验,以验证本文模型的有效性;然后为本文模块提出最优参数,与现有研究方法进行比较分析。
2.1 视觉问答数据集
实验使用的VQA v1.0 数据集[3]由常见物体图像识别(MicroSoft Common Objects in COntext,MSCOCO)数据集提供的204 721 幅图像组成,有248 349 道训练题、121 512 道验证题、60 864 道测试题和244 302 道标准试题。VQA1.0 中的问题可以分为3 个子类别:是/否、数字和其他,每个图像有3 个问题,每个问题有10 个来自10 个不同注释者的基本答案。此外,v1.0 包括两个任务:开放式任务和多项选择任务(每个问题18 个答案选项)。
2.2 参数设置
本文利用ResNet-152 提取图像区域特征,每个区域由2 048 个维度特征表示,使用LSTM 对问题进行编码,每个问题中单词特征向量的维数为2 048,在每个LSTM 层(正则率p=0.3)和模块(p=0.1)之后使用dropout。
模型训练时,使用β1=0.9 和β2=0.99 的Adam 解算器,基本学习率设置为0.000 1,并以0.5 的指数速率每40 000 次迭代衰减一次,本文在50 000 次迭代时终止训练。在训练中,整个网络使用ReLU 激活函数,mini_batch=100。本文实验基于PyTorch 0.3.0 深度学习框架进行编码,并在带有GTX 2060GPU 处理器的工作站上进行。对于所有实验,本文在训练集上训练,在验证集上进行验证。
3 结果
3.1 与已有研究比较分析
将CCAN 模型与已有模型在VQA v1.0 数据集上进行比较,即在VQA v1.0 数据集上的训练集和验证集上训练CCAN模型,在Test-dev和Test-std两个测试集上评估CCAN模型。
表1 为CCAN 模型在VQA v1.0 数据集上与其他模型比较的结果,可以分为三类:1)不使用注意机制的方法;2)仅基于视觉注意的方法;3)整合视觉注意和文本注意的方法。

表1 VQA v1.0数据集上CCAN与已有模型性能比较 单位:%Tab.1 Performance comparison between CCAN and existing models on VQA v1.0 dataset unit:%
从表1 可以观察到整合视觉注意和文本注意模型的结果优于其他两类模型,CCAN 模型在Test-dev(67.57%)和Test-std(67.54%)上获得最佳的总体准确性。本文模型是基于视觉和文本注意力的方法,与MLAN(Multi-level Attention Network)[21]、CAQT(Co-Attention network with Question Type)[22]和 v-VRANET(Visual Reasoning and Attention NETwork)相比,在Test-dev 上分别提高2.97、1.20 和0.37 个百分点,在Test-std 上分别提高2.74、1.01 和0.20 个百分点。MLAN 模型除了视觉注意之外,还使用语义注意来挖掘图像的重要内容,CAQT 模型通过自我注意模型实现的文本注意以减少无关的信息,进而用于引导视觉注意;v-VRANE 模型使用视觉推理和注意网络;相比之下,本文提出跨模态交叉融合注意模型(CCAN),明显更深层次地加强文本和视觉的交互,以捕获丰富的视觉语义并帮助增强视觉表示。与第一类方法(没有使用注意机制的方法)相比,本文模型优于FDA(Focused Dynamic Attention)模型,在Test-dev 总体准确性方面提高了8.33 个百分点。此外,与涉及视觉注意的第二类方法相比,本文模型的准确率最高。
3.2 消融实验
为了分析CCAN 模型中每个模块,并证明面向视觉问答的跨模态交叉融合注意模型的性能效果,本文利用消融实验证明模型的有效性。为了公平比较,所有评估模型提供完全相同的特征,在训练集上训练并在验证集上测试。
模型一 以LSTM 提取问题特征与ResNet-152 提取的图片特征作为输入;
模型二 以提取的问题特征进行词注意和图片特征作为输入利用逐元素相乘的方法进行融合;
模型三 对利用ResNet-152 提取的图片进行残差通道自注意,然后用逐元素相乘的方法对注意后的图片特征和文本特征进行融合;
模型四 整体结构框架与本文模块一致,但在此模块中是利用加法进行联合表征;
模型五 图片特征的处理在模块二的基础上,引入跨模态交叉融合注意的方法。
表2 中的模型一和模型二为简单基准模型和使用视觉注意机制的模型,当对文本进行词注意之后与图像进行融合时能够获得性能提升,表明词注意可以提取出更有用的问题特征,并可以从中发现更重要的语义信息,去除与问题无关的噪声信息,使得问题与图片之间的交互性进一步提升。模型三利用残差通道自注意加强图像特征,可以发现对于图像特征,可以从相关图像区域获得信息,推断问题的正确答案,结果比模型二有0.84 个百分点的提升。模型四中,利用元素加法对多模态进行联合表征,比使用元素乘法的准确率低,表明在视觉问答任务中,元素乘法是一种比加法更好的多模态融合方法。模型五使用跨模态融合注意网络将动态信息整合在一起,与任何单一层次的注意力模型相比,取得了显著的改进,相较于其他四种模型分别提升了2.12、1.37、0.53 和0.15 个百分点的准确率。

表2 消融实验结果 单位:%Tab.2 Results of ablation experiments unit:%
为了选择最佳的损失函数来训练神经网络,表3中比较了三种常用的损失函数,即KLD损失函数、二分类交叉熵(Binary Cross Entropy loss,BCE)损失函数和交叉熵损失函数。如表3所示KLD函数获得了最好的性能,并且收敛速度最快。

表3 三种常用的损失函数比较 单位:%Tab.3 Comparison of three commonly used loss functions unit:%
3.3 可视化结果分析
在图5 中展示了视觉注意和文本注意的可视化结果。在自注意力中,把重点放在重要的单词以及单词之间潜在的语义关系上,以便全面理解问题。模型中的文本注意准确检测出“donuts”和“boy”之间的关系,并有效协调了关系特征和视觉特征。此外,提出的残差通道自注意能准确检测出图像各个区域之间的关系,结合两者注意力机制来回答“Is the boy eating donuts?”,本文模型发现问题所提到的3 个对象区域之间的密切联系,并成功推理出正确答案。

图5 视觉注意和文本注意的可视化结果Fig.5 Visualization results of visual attention and textual attention
4 结语
本文针对VQA 任务提出了面向视觉问答的跨模态交叉融合注意网络(CCAN),该网络包括文本注意、视觉注意,其中利用词注意和改进的残差通道自注意对图片进行注意,得到一个增强的图片特征,以此获得更重要的图像信息。此外,引入了跨模态交叉融合注意模型对多模态进行联合表征,每一个交叉融合都会产生一个有效的信息流,从而提升模型性能。本文模型在VQA1.0 数据集上达到了67.57%的总体准确率,与当前的一些主流模型相比,本文提出的模型性能有所改进,实验结果表明了本文提出的CCAN 模型在VQA 任务中的有效性。未来的工作将研究如何通过集成模型来提高开放问题回答的准确率。
