基于注意力机制和金字塔融合的RGB-D室内场景语义分割
2022-04-12刘彦魏雄炬万源
余 娜,刘彦,魏雄炬,万源
(武汉理工大学理学院,武汉 430070)
0 引言
图像语义分割是计算机视觉研究中的一个重要课题,其目标是为图像中的每个像素分配一个类别标签,并预测每个像素的位置与形状,以此提供对场景的完整理解[1]。图像语义分割在自动驾驶、机器人传感、目标检测、图像检索等领域有着广泛应用[2]。对于室内场景语义分割问题,由于室内场景存在光照不均匀、遮挡关系复杂等因素,如何降低这些因素的影响、提高室内场景语义分割精度是一个巨大的挑战。
目前,图像语义分割算法分为传统语义分割算法和基于深度学习的语义分割算法两类算法。传统语义分割算法利用图像的手工特征,使用基于边缘[3]、区域[4]、图论[5]、聚类[6]等分割方法获取图像的关键信息,提高语义分割的效率,但在处理较复杂的分割任务时无法带来良好的分割效果。深度学习技术的出现弥补了传统语义分割方法的不足。2015年Long 等[7]提出全卷积网络(Fully Convolutional Network,FCN)架构,该网络将传统的卷积神经网络,如AlexNet(Alex Network)[8]、VGGNet(Visual Geometry Group Network)[9]、GoogLeNet(Google Inception Network)[10]等最后的全连接层替换为反卷积层,实现“端到端”的RGB 彩色图像语义分割输出,并加入上池化层和跳跃连接,解决了位置特征丢失问题。Badrinarayanan 等[11]基 于FCN 提出了SegNet(Segmentation Network),该网络采用“编码器-解码器”结构,解码器层使用最大池化对特征图进行上采样,增强图像边界定位的准度,有效解决了FCN 中存在的输出图像分辨率降低等问题。Zhao 等[12]基 于ResNet(Residual Network)[13]提 出PSPNet(Pyramid Scene Parsing Network),该网络引入金字塔融合模块,依赖场景中上下文的先验知识,融合不同尺度的特征信息,成功解决了FCN 中存在的空间信息丢失等问题。
由于室内场景复杂度、光照不均和色彩纹理重复性高,上述基于RGB 彩色图像的语义分割方法存在物体边缘误分割、类别误分类等问题,无法实现智能体对环境语义信息的精确理解。近几年研究发现,与基于普通RGB 彩色图像的方法相比,基于RGB-D 方法可以利用场景中额外的Depth 深度信息,该信息受光照影响小;同时可以反映出物体之间的位置关系,且和RGB 彩色信息互补。Couprie 等[14]发现辅助Depth 深度信息可以降低具有相似深度、外观、位置信息的物体分割错误率。
随着Kinect[15]等深度摄像机的出现与发展,人们很容易获取到图像的Depth 深度信息。然而找到RGB 彩色信息与Depth 深度信息的融合方式,挖掘两者之间的互补性一直是一个具有挑战性的问题。一些简单方法[16-18]将其堆栈到RGB 彩色通道,并在假设有4 个通道输入的RGB-D 数据上训练网络。但是直接将Depth 深度信息作为第4 通道融合并不能完全利用其所编码的场景结构信息。Gupta 等[19]提出HHA(Horizontal disparity,Height above ground,Angle of the surface normal)深度信息表示方法,将深度图像转换为三种不同的通道(水平差异、对地高度、表面法向量的角度),但HHA 只强调每个通道数据之间的互补信息而忽略了各个通道的独立性,且计算量大。Hazirbas 等[20]提出一种新的融合深度信息架构FuseNet(Fusion Network)融合网络,将互补Depth 深度信息融合到语义分割框架,提高了分割精度,但没有实现多尺度的融合。Hu 等[21]提 出ACNet(Attention Complementary Features Network),设计注意力辅助模块平衡特征的分布,使网络更关注于图像的有效区域,在保持原有RGB-D 特征分支的同时,充分利用RGB 信息与Depth 信息融合后的特征。
上述方法仍然存在着两个问题:1)一些分割方法直接将Depth 深度信息作为第4 通道融合,没有充分利用RGB 彩色信息与Depth 深度信息的互补性;2)现有方法无法有效地推断上下文关系,存在不同尺度信息特征丢失等问题,然而对于室内场景语义分割任务而言,多尺度信息特征的提取能提高场景中小尺度物体的分割精度。
针对上述语义分割中存在的问题,本文提出一种新的基于注意力机制和金字塔多模态融合的RGB-D 室内场景图像语义分割网络结构,以提高室内场景语义分割的精度。该网络为“编码器-解码器”结构,并为其设计了注意力机制融合模块(Attention Mechanism Fusion Module,AMFM)与金字塔融合模块(Pyramid Fusion Module,PFM)两个新的模块。注意力机制融合模块充分挖掘RGB 特征和Depth 特征的互补性,有利于提取到更多的RGB-D 室内图像语义信息。金字塔融合模块利用四种不同的池化核,融合多尺度特征,提取图像语境信息,其编码器网络以ResNet-50[13]卷积层的拓扑结构为基准,包含3 个分支,并去掉ResNet-50 的平均池化层和全连接层。网络中有两个分支分别提取图像中的RGB 彩色特征和Depth 深度特征;同时逐层传入到注意力机制融合模块中进行特征融合;第三个分支用于处理上述融合后的特征。接着,采用金字塔融合模块融合局部与全局信息,使用解码器网络连续对上述特征进行五次上采样,并进行跳跃连接,逐步恢复高分辨率的图像,输出语义分割结果。
本文的主要工作如下:
1)提出了一种新的基于注意力机制和金字塔融合的网络结构,该网络在编码器部分采用预训练的三分支ResNet-50 卷积结构,相较于现有的双分支网络而言,结合注意力机制融合模块的三分支网络充分利用RGB 特征与Depth 特征的协同互补性,根据前向误差学习特征权重,得到信息含量更高的多模态融合特征。
2)在编码器部分采用金字塔融合模块,利用不同大小的池化核,提取不同尺度下的特征信息,并进行融合,增强网络场景分析的性能。
实验结果表明,本文提出的网络结构能够利用到场景中更丰富的信息,在两个公开的RGB-D 数据集SUN RGB-D[22]和NYU Depth v2[23]对APFNet(Attention Mechanism and Pyramid Fusion Network)网络进行训练,结果表明本文所提出的RGB-D 室内场景图像语义分割算法在像素精度(Pixel Accuracy,PA)、平均像素精度(Mean Pixel Accuracy,MPA)、平均交并比(Mean Intersection over Union,MIoU)上均比现有先进算法有所提升,充分体现了该模型在室内语义分割任务中的有效性。
1 相关工作
1.1 全卷积神经网络
2015 年Long 等[7]提出全卷积网络FCN,可以输入任意尺寸的图像,并采用反卷积层进行上采样,还原图像分辨率,实现“端到端”输出也即像素级分割。FCN 的出现被誉为语义分割领域的里程碑,其第一次使用深度学习技术处理语义分割任务。随后,Badrinarayanan 等[11]等提出SegNet,该网络在FCN 的基础上提出池化索引功能,在上采样过程中定向恢复相应的索引值,保持高频特征的完整性,提高了语义分割的准度。Paszke 等[24]简化传统的“编码器-解码器”结构,采用大型编码器和小型解码器,减少参数量。Wang 等[25]基于ResNet[13]提出 LEDNet(Lightweight Encoder-Decoder Network),改进深度残差学习模块,提高图像语义分割的实时性。另外,一些学者[26-28]提出了基于RNN(Recurrent Neural Networks)[29]的方法记忆历史信息,易于利用局部和全局信息。
1.2 注意力机制
注意力感知机制[30]与人类的视觉注意力感知机制类似,其原理是聚焦场景中更加有用的信息,忽略场景中的无用信息,有利于取得特征图全局的上下文信息,提高语义分割的精度。
近年来,在计算机视觉领域注意力感知机制有着广泛应用。Fu 等[31]提出DANet(Dual Attention Network),该网络将位置注意力模块和通道注意力模块并行连接,采用自注意机制整合图像的局部特征,编码上下文的依赖关系。Hu 等[32]提出SENet(Squeeze and Excitation Network)架构,设计通道注意力模块,学习各通道的依赖程度,并据此对特征图进行调整。Huang 等[33]提出CCNet(Criss Cross Network),自主设计纵横交叉注意力机制模块,该模块通过特征加权捕获垂直方向和水平方向的全局信息,得到像素与像素之间的上下文依赖关系,并减少了参数量。Wang 等[34]提出融合空间域注意力和通道域注意力,并提出残差注意力学习,不仅在当前网络的特征层加入掩码,还把上一层的特征传递到下一层。本文为了充分利用RGB 彩色信息与Depth 深度信息的互补性,提出注意力机制融合模块,分别提取RGB 特征和Depth特征的注意力分配权重,提高物体边界轮廓的分割精度。
1.3 多尺度融合
在计算机视觉领域中,极小尺度与极大尺度物体往往都会影响深度学习模型的性能,如何融合图像中多尺度的特征信息也是一个具有挑战性的任务。Zhang 等[35]提出MTCCN(Multi-Task Cascaded Convolutional Network)人脸检测算法,使用多个尺度的图像金字塔输入,获取更强的特征表示;Zhao 等[12]基于ResNet[13]提出PSPNet,该网络引入金字塔池化模块,使用不同大小的池化操作来控制感受野,融合多尺度特征;Fu 等[36]提出Big-Little Net(Big Little Network),采用不同的尺度对信息进行处理,对分辨率大的分支使用更少的卷积通道,充分利用通道信息;Chen 等[37]基于DeepLab V1 提出DeepLab V2[38],并提出带孔金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模块,该模块结合空洞卷积与金字塔池化模块,获取不同尺度的特征,并将其融合实现多尺度信息的处理;Lin 等[39]提出特征金字塔网络(Feature Pyramid Network,FPN),将高层的特征添加到相邻的低层,组合新的特征,再对每一层进行预测,解决了目标检测中小尺度物体的性能不佳问题。本文为了提高室内场景分割中小尺度物体分割的性能,设计金字塔融合模块提取场景语境,融合多尺度信息。
2 网络模型与算法
本章首先介绍本文所提出的APFNet 室内场景语义分割网络的整体架构,接着讲述两个创新型模块:注意力机制融合模块和金字塔融合模块,最后阐明网络模型训练中所使用的损失函数。
2.1 网络模型的整体架构
网络模型的整体结构如图1 所示。
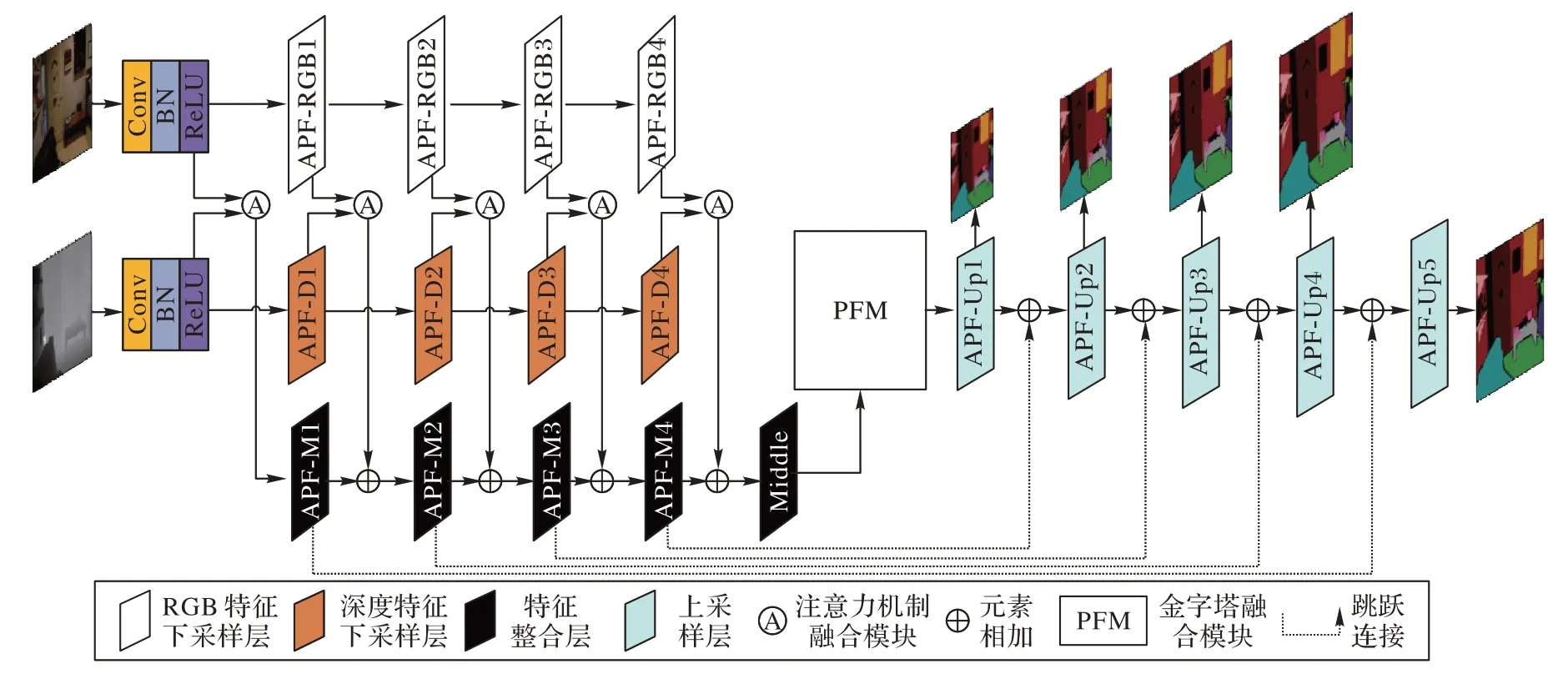
图1 基于注意力机制和金字塔融合的RGB-D语义分割APFNet网络模型整体架构Fig.1 Overall architecture of RGB-D semantic segmentation APFNet model based on attention mechanism and pyramid fusion
本文的网络模型中设计了两个创新型的模块:注意力机制融合模块和金字塔融合模块,即分别将编码器网络中4 个同级的RGB 彩色特征(APF-RGB1~APF-RGB4)和Depth 深度特征(APF-D1~APF-D4)输入到注意力机制融合模块中,通过前向误差得到两种特征的注意力权重,并利用权重增强语义信息合并得到富含彩色信息与空间位置信息的特征表示,同时将合并后的特征输入到第3 个分支,即特征整合分支中。之后,将特征整合分支的最后一层特征输入到金字塔融合模块,利用四种不同金字塔尺度的特征,融合局部和全局的信息,提高对图像全局特征的利用率。最后将金字塔融合模块的输出特征输入到解码器网络,对其进行5 次连续的上采样,恢复图像特征,其结构上与编码器相对称。经过每一次上采样,特征图尺寸增大1 倍,通道数减少1/2。另一方面特征整合分支输出的编码特征,通过对应位置元素相加的跳跃连接方式,与对应尺寸的解码特征融合,每一次跳跃连接包含一个1×1 卷积层。为对梯度消失现象进行深层监督,本文在解码过程中分别提取五个上采样层的输出特征,并输入到1×1 卷积层中,减少特征的通道数至37;最后采用Softmax 函数对像素进行分类。解码器的输出就是最终室内场景语义分割结果,实现“端到端”的输出。
2.2 注意力机制融合模块
由于室内场景复杂度高、光照不均匀,物体边界和类别判分过程中出现难分和错分的情况,导致算法语义分割精度较低。而场景中的深度信息因其受光照影响小、能够反映位置关系且与RGB 信息互补等特性,与RGB 信息结合后可以降低相似外观、相近位置物体分割的错误率。因此,本文提出一种注意力机制融合模块(AMFM),充分利用RGB 信息和Depth 信息之间的协同互补性,网络根据前向误差学习特征权重,得到信息特征含量更高的多模态融合特征,使其能够更精确地判别物体边界,提高分割精度。
注意力机制融合模块的结构如图2 所示。
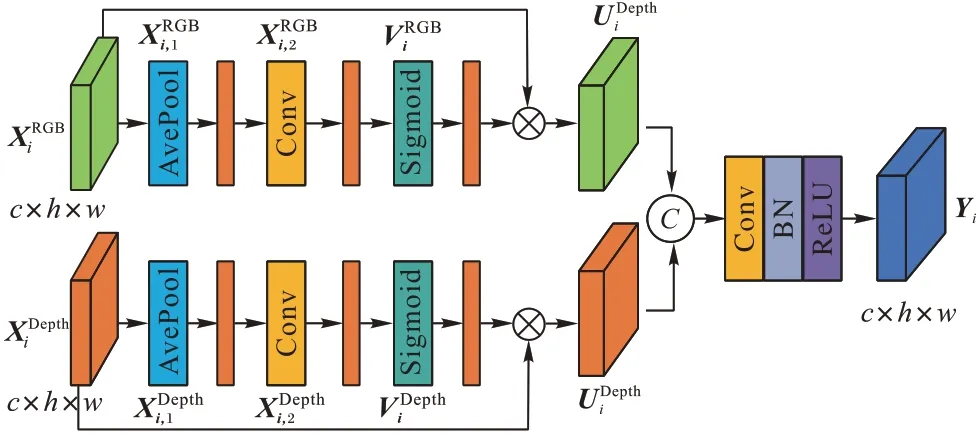
图2 注意力机制融合模块Fig.2 Attention mechanism fusion module
将编码器网络第i个层级的RGB 特征和Depth 特征分别设为,并输入到注意力机制融合模块中,其中c表示通道数,h和w分别表示特征映射的高度和宽度。首先分别对两种特征进行池化操作:

其中:AvePool 为自适应平均池化(Adaptive Average Pooling)操作,该操作能在指定输出特征的尺寸后,自动选择步长和池化核的大小;为经过平均池化后得到的特征,特征的通道个数和尺寸分别为c和1×1。接下来将两种特征输入1×1 卷积层:

其中:f1×1表示卷积核大小为1×1 的卷积操作;分别表示卷积结果。经过该卷积操作后的RGB 特征和Depth 特征尺寸和通道大小不变,且该卷积层能够挖掘通道间的相关性,从而得到这些通道间合适的权重分布。然后使用Sigmoid 激活函数对的权重值进行归一化:


最后,注意力机制融合模块的融合特征Yi由式(9)计算得到:
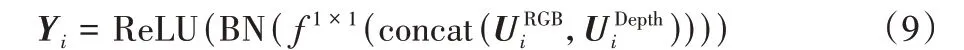
其中:concat 表示在通道维度的拼接操作,BN(Batch Normalization)表示批量标准化操作,ReLU(Rectified Linear Unit)为线性整流激活函数。通过该操作得到和输入相同通道个数和尺寸的多模态融合特征。该特征既具有原始的RGB 特征和Depth 特征,又能在后续网络中利用合并后的特征。
2.3 金字塔融合模块
上一节中,利用注意力机制融合模块已充分融合图片的RGB 特征与Depth 特征,然而在室内场景分割的实验过程中,发现许多分类错误,如外观相似物品没有得到正确分类、小尺度物体没有识别等,这些问题与不同感受野的语境关系和整体信息有关。在深度神经网络中,感受野的大小可以表示使用语境信息的程度,因此具有合适感受野大小的深度网络可以大大增强场景分析的性能。为了对得到的多模态特征进行增强,使模型更有效地利用上下文信息,进一步避免丢失表征不同子区域之间关系的语境信息,本文提出了一种包含不同尺度、不同子区域间关系的分层全局信息的金字塔融合模块(PFM),结合不同金字塔尺度下的特征信息,融合局部与全局的信息,使得对上下文信息的使用程度大大提高。
金字塔融合模块的结构如图3 所示。

图3 金字塔融合模块Fig.3 Pyramid fusion module
由于在室内语义分割中,上下文信息丢失及物体混淆问题主要出现在小物体分割上,因此将输入的融合特征Y5池化后,分成4 个尺度,图3 中最小尺度的金字塔池化层表示最粗糙的特征图为全局池,用以生成单个特征输出。下面三种金字塔池化层表示分别将特征图划分为若干个不同的子区域,并对每个子区域进行池化,得到不同的特征表示Tk(k={1,2,3,4}):

其中:AvePoolj×j表示自适应平均池化,将不同子区域池化后的特征组合起来,输出为尺寸为j×j(j={1,2,3,6})的子区域特征。而在金字塔融合模块中不同层次的输出包含不同大小的特征图,为了保持全局特征的权重,在不同尺度的池化操作后使用1×1 的卷积核,得到相应的卷积结果:

然后直接对低维特征映射进行上采样,通过双线性插值得到与原始特征映射相同大小的特征。最后,将不同级别的特征串联起来,作为最终的金字塔融合特征,融合特征W由以下计算得到:

其中,concat 表示在通道维度的拼接操作,通过该操作得到通道个数和尺寸分别为c和h×w的多模态融合特征。
金字塔级别的数量和每个级别的大小可根据输入金字塔池化层的特征图大小改变。不同的金字塔融合模型,采用不同大小的池化核,以不同的速度提取不同的感受野。本文的金字塔融合模块是一个四级的模块,其大小分别为1×1、2×2、3×3 和6×6。
2.4 损失函数
由于本文模型的最后一层使用的是Softmax 函数对像素进行分类,所以使用深层监督的方法并采用交叉熵函数来训练网络模型参数,提升梯度的收敛速度。即将语义标签图分别进行4 次下采样到解码器的前4 层对应尺寸,并分别计算其与网络模型中上采样5 次预测特征输出的交叉熵函数。则第d(d={1,2,…,5})层交叉熵函数为:

其中:m、n为像素坐标,S为标签类别,S*为输出特征的分类概率,Nd为第d层输出特征的像素个数。
再将5 层的交叉熵函数相加,作为网络模型的损失函数:

同时,本文使用跳跃连接的方式,将注意力机制融合模块中的特征对应输入到解码器网络中。该方式可以解决网络模型中存在的梯度消失问题,并有助于梯度的反向传播,加快训练进程。
3 实验与结果分析
本章在两个常用公共数据集SUN RGB-D[22]和NYU Depth v2[23]上与现有的基于RGB-D 图像的语义分割算法进行对比实验,并对模型中两个模块的作用进行实验分析,最后对算法复杂度进行评估。
3.1 实验数据集与评估指标
3.1.1 数据集
SUN RGB-D 该数据集共包含10 335 张不同室内场景的RGB-D 图像,每幅图像的每个像素都被标注一个语义类别标签,共包含37 个语义类别标签。本文使用795 个实例进行训练,654 个实例进行测试。
NYU Depth v2 该数据集共包含由Kinect[15]采集的1 449 张室内场景的RGB-D 图像,共包含40 类语义类别标签。在该数据集上本文使用795 个实例进行训练,654 个实例进行测试。
3.1.2 评估指标
本文采用三种常见的图像语义分割评估指标来评估算法的性能,分别是像素精度(PA)、平均像素精度(MPA)、平均交并比(MIoU)。
PA 为一张图片中分类正确的像素点数和所有像素点数的比值,定义如下:

其中:pii表示分类正确的像素数量,pij表示本属于类i却被预测为类j的像素数量。
MPA 为每个类内分类正确的像素点数和所有像素点数的比值的平均值,定义如下:

其中k表示类别数。
MIoU 为真实值与预测值两个集合的交集和并集的比值的平均值,定义如下:
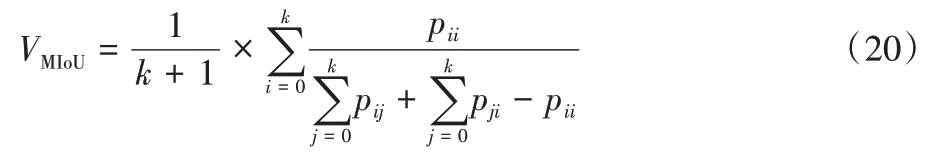
3.2 网络参数设置
在深度学习框架PyTorch0.4.1[40]上训练本文所提出的网络模型,输入为640×480 的RGB-D 图像并使用深层监督的方法并采用交叉熵函数来训练网络模型参数,提升梯度的收敛速度。计算标签图5 次下采样的输出与网络模型中五次上采样预测特征输出的交叉熵函数,并将5 层的交叉熵函数相加,作为网络模型的损失函数。本文使用预训练的三分支的ResNet-50[13]初始化编码器的权重参数,并在4 个NVIDIA GeForce RTX 2080 GPU 上训练本文网络模型。初始学习率设置为0.002,批处理大小设置为2,每100 次迭代乘以0.8减小学习率;动量系数设置为0.9,权值衰减系数设置为0.0001。
3.3 实验结果分析
3.3.1 与其他算法的对比结果
1)在SUN-RGBD 数据集上的对比结果。本文分别将SUN-RGBD 数据集代入到所提算法与现有算法中进行对比实验(如表1 所示)。
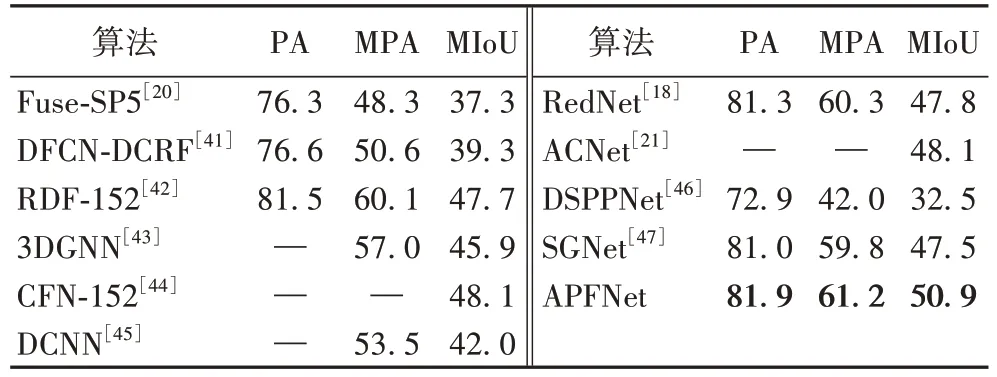
表1 各算法在SUN-RGBD上PA、MPA、MIoU比较 单位:%Tab.1 PA,MPA and MIoU comparison of different algorithms on SUN-RGBD unit:%
实验结果显示,本文算法在像素精度、平均像素精度、平均交并比三种评估指标上均优于现有算法,具体数值分别为81.9%、61.2%、50.9%。一方面,将APFNet 与其他三分支编码器-解码器架构算法相比,如与最先进的SGNet 算法相比,本文算法在像素精度、平均像素精度、平均交并比上分别提高0.9 个百分点、1.4 个百分点、3.4 个百分点;与ACNet 算法相比,本文算法的平均交并比提高了2.8 个百分点,这得益于编码器端中加入了注意力机制融合模块的三分支网络,使得模型对RGB 信息和Depth 信息有更佳的融合效果。另一方面,虽然APFNet 的编码器网络为ResNet-50,但相较于编码器网络为ResNet-152 网络的算法而言,在编码器层数从152 层降低到50 层的情况下,本文算法在3 个指标上均有提升,如与RDF-152 算法相比,APFNet 在像素精度、平均像素精度、平均交并比上分别提高了0.4 个百分点、1.1 个百分点、3.2 个百分点;与CFN-152 算法相比,APFNet 的平均交并比提升了2.8 个百分点,这归功于金字塔融合模块对多尺度特征的融合使得模型对小尺度物体和边缘信息有更精确的判别;同时使得APFNet 不需要很深层的编码器结构就可得到更好的分割性能。
2)在NYU Depth v2 数据集上的对比结果。本文在NYU Depth v2 数据集上将所提出的算法与现有算法进行对比实验,结果如表2 所示。本文算法在像素精度、平均像素精度、平均交并比上均优于现有算法。

表2 各算法在NYU Depth v2上PA、MPA、MIoU比较 单位:%Tab.2 PA,MPA and MIoU comparison of different algorithms in NYU Depth v2 unit:%
具体而言,本文算法在NYU Depth v2 数据集的三种评估指标分别为76.9%、63.2%、52.3%。一方面,与同是三分支编码器-解码器架构的RGB-D 语义分割算法对比,相较于ACNet 算法,本文算法在平均交并比上提升了4 个百分点;与新颖的TSNet 算法相比,APFNet 在像素精度、平均像素精度、平均交并比上分别提升了3.4 个百分点、3.6 个百分点、6.2个百分点。另一方面,与同是使用ResNet-50 作为编码器架构的算法对比:相较于RDF-50,本文算法的像素精度、平均像素精度、平均交并比分别提高了2.1 个百分点、2.8 个百分点、4.6 个百分点;相较于CTNet,本文算法的像素精度、平均交并比分别提高了0.6个百分点、1.7个百分点。上述实验结果表明本文算法在不同的数据集上都有较良好的性能体现,说明APFNet能适应各种各样的类别和场景。
3)结果分析。本节进一步在NYU Depth v2 数据集上分析本文所提出的算法在各个类别的交并比精度,分别与RDF-101 和RDF-152 两个RGB-D 室内场景语义分割算法进行比较,以更清晰地分析APFNet 在40 个类别上的分类情况。如表3 所示,所有40 个类别中,本文算法在26 个类别上的交并比精度都有优于这两种算法的表现。一方面,本文算法提高了易分辨物体的语义分割精度:与RDF-101 相比,APFNet在“木板(board)”“浴缸(bathtub)”“马桶(toilet)”“天花板(ceiling)”的分割精度上分别提升了26.0 个百分点、12.8 个百分点、9.2 个百分点、6.2 个百分点,得益于注意力融合模块中的Depth 信息能够反映物体的位置关系,增强物体边缘的分割精度;另一方面,本文算法提高了小尺度物体的语义分割精度:与RDF-152 算法相比,APFNet 在“灯(lamp)”“地毯(mat)”“箱子(box)”“报纸(paper)”的分割精度上分别提升了3.4 个百分点、3.3 个百分点、3.0 个百分点、2.1 个百分点,这归功于本文设计的金字塔融合模块能融合局部与全局的信息,增强物体的细节特征。注意力机制融合模块和金字塔融合模块的结合使用使得本文算法有更好的分割效果。
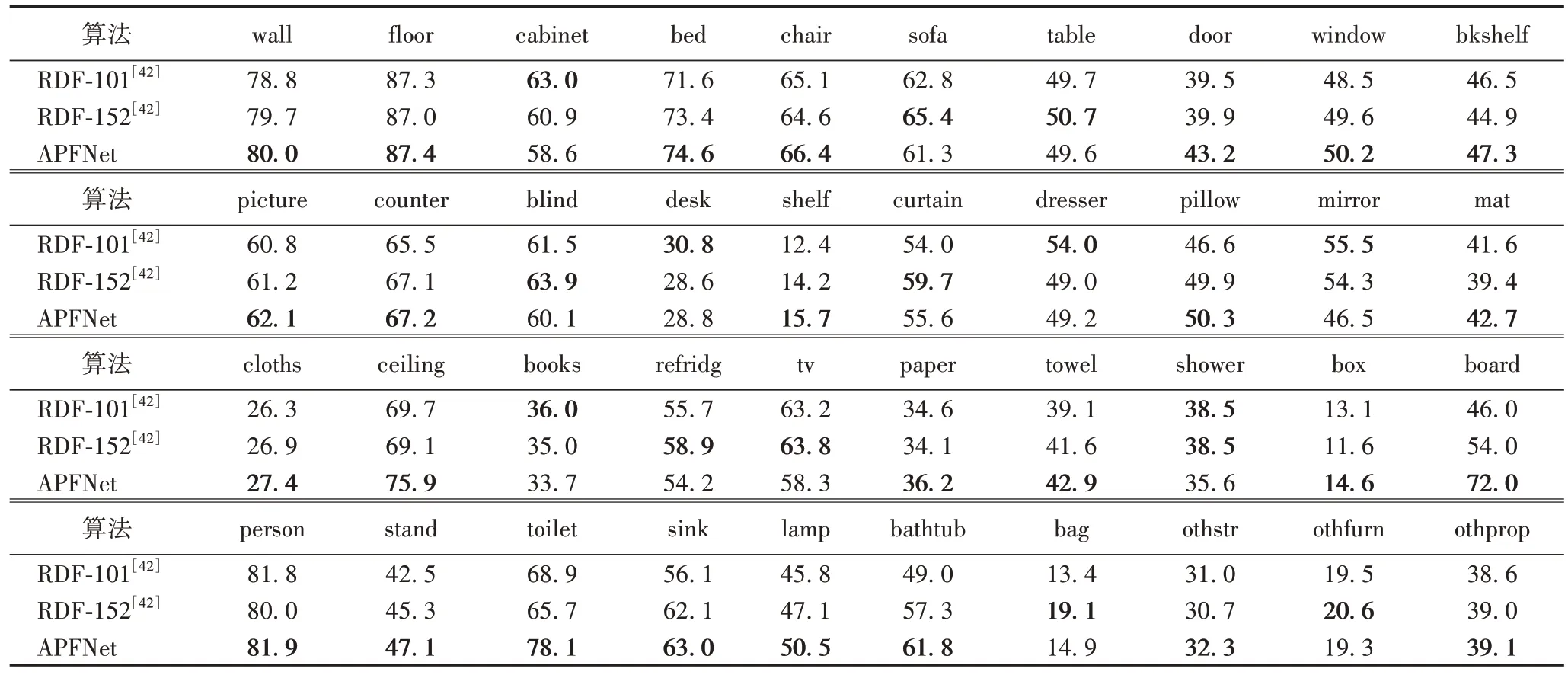
表3 NYU Depth v2数据集中40个类的IoU的比较结果 单位:%Tab.3 Comparison of IoU results of 40 classes in NYU Depth v2 dataset unit:%
3.3.2 两个融合模块的性能分析
本节分析本文提出的两个融合模块:注意力机制融合模块(AMFM)和金字塔融合模块(PFM)对语义分割结果的影响。通过去除模型中的两个融合模块,对比验证边缘划分和小尺度物体分割的精度,在NYU Depth v2 数据集上进行测试,对比结果如表4 所示。本文首先测试采用等权值拼接操作代替两个融合模块后的网络性能,并用concat 表示此网络,其三个评估指标分别为73.7%、57.5%、46.9%,与本文算法APFNet 相比分别降低了3.2 个百分点、5.7 个百分点、5.36 个百分点,表明本文提出的两个融合模块显著提升了最终的分割精度。接下来,将采取同样的方法分别去除注意力机制融合模块和金字塔融合模块,并测试去除后的网络模型性能。

表4 两个融合模块对算法模型PA、MPA、MIoU的影响 单位:%Tab.4 Impact of two fusion modules on PA,MPA and MIoU unit:%
1)注意力机制融合模块。去除了APFNet 算法中的注意力机制融合模块网络的语义分割结果如表4 第3 行所示,网络像素精度、平均像素精度、平均交并比分别降低了1.5、1.8、2.76 个百分点。
图4 呈现了去除注意力机制融合模块前后的分割结果变,可以看出,使用注意力机制融合模块的网络对物体轮廓的分割更加精细。对于由于光线较暗影响判别的物体,如第1 行的“天花板”和第2 行的“桌子(desk)”,经过学习特征权重,结合不受光线影响的Depth 信息,得到的富含空间位置信息的融合特征更能准确编码到光线较暗处的物体轮廓信息,网络的边缘分割能力有效增强,物体轮廓更加精细。

图4 注意力机制融合模块的对比结果Fig.4 Comparison results of attention mechanism fusion module
2)金字塔融合模块。去除网络模型中的金字塔融合模块,结果如表4 所示,去除网络模型中的金字塔融合模块使得像素精度、平均像素精度、平均交并比降低了1.8 个百分点、2.3 个百分点、1.96 个百分点。
图5 展示了在网络模型中去除金字塔融合模块前后的语义分割结果。对比结果表明,使用金字塔融合可以对小尺度物体实现正确的语义分割,例如第1 行的“相片(picture)”“桌子”等,第2 行的“台灯”“枕头(pillow)”等。说明金字塔融合模块能有效融合局部与全局信息,提高网络模型对图像全局特征的利用率。

图5 金字塔融合模块的对比结果Fig.5 Comparison results of pyramid fusion module
3.4 可视化结果
图6 展示了本文网络模型在NYU Depth v2 数据集上的可视化结果,其中RDF-101 算法对易分辨的大物体的分割精度较高,如第2 行的“冰箱(refridge)”、第3 行的“相片”等。本文的网络模型也能达到上述效果,如第1 行和第4 行的“门(door)”、第2 行和第4 行的“桌子”、第3 行的“窗户(window)”等;同时本文模型对一些小尺寸物体,以及和周围环境颜色相近的物体能得到较好的分割结果,如第3 行的“柜子(counter)”、第4 行的“水槽(sink)”、第5 行的“相片”等。这些说明本文网络模型的注意力机制融合模块和金字塔融合模块能有效利用RGB 特征和Depth 特征的互补性,融合局部与全局信息,提高RGB-D室内场景语义分割精度。
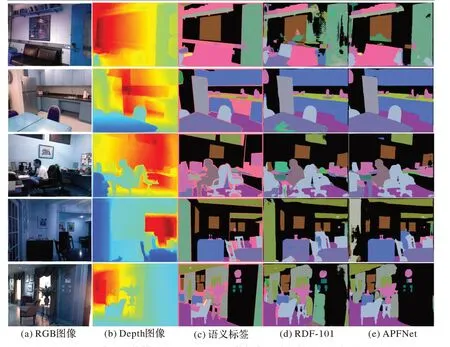
图6 本文网络模型在NYU Depthv2数据集的分割结果可视化对比Fig.6 Visualization comparison of segmentation results of APFNet model in NYU Depth v2 dataset
3.5 算法复杂度评估
本文算法的三分支编码器和单分支解码器均为ResNet-50 架构,共为200 层3×3 卷积和400 层1×1 卷积。注意力机制融合模块共含有15 层1×1 卷积,金字塔融合模块共含有4层1×1 卷积,跳层连接共含有4 层1×1 卷积。相对于编码器网络的参数量,两个融合模块和跳层连接的参数量明显较少,因此本文算法的时间复杂度和空间复杂度主要受编码器网络参数量与计算量的影响。对于同是采用ResNet-50 架构的室内场景语义分割算法而言,其时间复杂度相同。表5 展示了不同RGB-D 语义分割算法的占用内存和预测时间,可以看到由于注意力机制融合模块和金字塔融合模块参数量较少,其对占用内存和预测时间的影响较小,但两个模块能够有效提高语义分割精度。相对于RDFNet-50 和TSNet,本文算法在预测时间与内存消耗上有小幅度增加,但增加的幅度均不超过5 个百分点。

表5 不同算法的占用内存和运行时间对比Tab.5 Comparison of model size and operation time for different algorithms
4 结语
为了提高对室内场景中外貌特征相似物体与小尺度物体的语义分割精度,本文提出了一种基于注意力机制和金字塔多模态融合的RGB-D 室内场景图像语义分割网络模型APFNet,其主体为“编码器-解码器”架构,在编码器网络中构建三条网络分支,分别处理RGB 特征、深度特征以及融合特征。注意力机制融合模块利用RGB 特征和Depth特征的互补性,平衡两种特征的分布并进行融合,使网络更关注于图像的有效区域。金字塔融合模块通过融合多尺度信息,增强细节特征,获取更高质量的上下文语境信息。在解码器网络中采用跳跃连接和深层监督的方法,提高了梯度的收敛速度和模型的训练效果。本文算法在SUN RGB-D 和NYU Depth v2两个公开数据集上进行了大量的对比实验,实验结果表明,算法整体提高了边缘轮廓和小尺寸物体分割的能力,可以有效解决室内场景语义分割问题。
