基于生成对抗网络和网络集成的面部表情识别方法EE-GAN
2022-04-12杨鼎康黄帅王顺利翟鹏李一丹张立华
杨鼎康,黄帅,王顺利,翟鹏,李一丹,张立华,4,5*
(1.复旦大学工程与应用技术研究院,上海 200433;2.上海智能机器人工程技术研究中心,上海 200433;3.智能机器人教育部工程研究中心,上海 200433;4.季华实验室,广东佛山 528200;5.吉林省人工智能与无人系统工程研究中心,长春 130000)
0 引言
面部表情是人们在日常生活中最自然、最普遍的传达情感状态和意图的信号[1]。Mehrabian 等[2]的研究发现,面部表情传递的有效信息占比达55%,而通过单词传递的有效信息占比却仅仅只有7%,这表明面部表情是人们情感交流的重要特征,因此,面部表情识别(Facial Expression Recognition,FER)有助于获取更多有效信息[3],在人机交互[4]、智慧医疗[5]和安全驾驶[6]等领域有广阔的应用前景。
面部表情识别(FER)的传统方法是通过人工标注特征或浅层学习表征来完成表情识别任务,例如局部二进制模式(Local Binary Patterns,LBP)[7]、多平面LBP[8]、非负矩阵分解[9]和稀疏学习[10];但传统方法容易受到外界干扰的影响,其模型的泛化能力和鲁棒性有待提升。自2013 年以来,受FER2013[11]和野外情绪识别[12-14]等比赛的举办、运算能力的大幅提高等因素的影响,以及机器学习和深度学习迅速发展,基于神经网络的方法应用到面部表情识别任务中,这些方法[15-17]拥有较好的识别精度和鲁棒性,极大超越了传统方法取得的结果。
尽管FER 的现有研究已经取得了一些成果[18-20],但是大多数研究者仅聚焦于探索单一的网络模型结构,没有考虑不同深度网络学习到的特征表达之间的互补性[21],只能学习到特定层级的表情特征,限制了模型的泛化能力;同时由于大部分应用于FER 任务的公开数据集[22-24]中存在着表情标签源域数据分布不均衡的问题,例如某类别标签数据较少,导致模型难以学习到对应表情的特征,从而限制了FER 研究的发展和性能的提升。
为解决上述问题,本文提出了一种包含网络集成模型Ens-Net(Ensemble Networks)的端到端深度学习框架(End to End-Generative Adversarial Network,EE-GAN),用以缓解数据集样本中的数据分布不平衡问题。所述的Ens-Net 充分应用了VGG13、VGG16 以及ResNet18 等网络获取的不同深度的表情特征,并将其在特征级别进行融合。本文所提框架方法在FER2013、CK+、JAFFE 数据集上分别达到了82.1%,84.8%和91.5%的精度,验证了提出方法的有效性。
具体来说,本文的贡献包括2 个方面:
1)提出了一种集成网络模型Ens-Net,通过集成异构网络的方式,获取包含不同级别语义的融合特征,提高了分类特征向量的表征能力,以帮助模型更好地进行决策。
2)基于生成对抗网络(Generative Adversarial Network,GAN)对抗学习的思想,提出了端到端的学习框架EE-GAN,有效缓解了面部表情数据集标签分布不均衡的问题,对现有的面部表情数据集实现了数据增强和扩充。
通过与单一的卷积神经网络(Convolutional Neural Network,CNN)模型和现有基于视图学习的生成式表情识别方法比较,本文进行了大量的对比实验和消融实验,实验结果表明了该模型框架的有效性和优越性。
1 相关工作
针对基于深度学习方法的静态FER 任务,一般的步骤是图像预处理后,通过深度神经网络自动提取特征,再利用学习到的特征完成后续的表情分类。卷积神经网络能够准确地学习图像的特征信息[15-17],Krizhevsky 等[15]提出AlexNet,此方法可以加深网络结构,学习图像中更深层次和更高维度的特征信息,同时也引入Dropout 机制防止模型过拟合;Simonyan 等[16]使用卷积核的堆叠方式,使得具有相同感知野的情况下,网络结构更深;He 等[17]则通过残差学习解决深度神经网络的退化问题。先前的研究表明,多个网络特征融合方法的性能要优于单一网络的性能。Ciregan 等[25]受大脑皮层中神经元的微列启发,将多个深度神经网络(Deep Neural Network,DNN)列结合组成多列DNN,证明了增加网络宽度可以降低图像的分类误差;Bargal 等[26]将从不同网络学习到特征进行级联以获得单个特征向量来描述输入图像;Hamester 等[27]将有监督方式训练的CNN 和无监督方式训练的卷积自动编码器进行网络集成,以增强网络的多样性。与现有方法不同,本文的网络集成策略将不同深度的语义特征进行融合,以获取不同尺度下潜在的重要表情特征,使得模型能够学习到更多样、全面的特征信息。
最近,基于生成对抗网络(GAN)的方法运用到了FER 任务[27-28]中。随着更多GAN 的变体不断提出,基于对抗式学习的方法能进行更好的解耦学习和表征学习,实现针对不同场景下的FER。Yang等[28]利用从条件生成对抗网络(conditional Generative Adversarial Network,cGAN)模型中提取的非中性表情的残基成分加入分类网络中,以促进学习更精细化的表情特征。Chen 等[29]提出了一种隐私保护表示学习变体GAN,该算法结合了变分自动编码器(Variational AutoEncoder,VAE)和GAN 来学习一种身份不变的表示形式,并且可以生成用于保留表情的面部图像。Yang 等[30]提出了由两个部分组成的身份自适应生成模型:上半部分使用cGAN 生成具有不同表情的同一主题的图像,下半部分在不涉及其他个体的情况下针对子空间进行FER,因此可以很好地缓解身份变化。
尽管这些方法都提高了FER 的性能,但是却没有考虑选取的数据集内部表情标签数量分布不均衡的问题。不同数据集的数据所在源域存在差异,在不受控环境下得到的数据集中,服从长尾分布的数据源域中的表情标签极度不平衡的问题极为突出[31],例如由于现实情境的限制,Contempt 和Fear 类别的样本数量要远远小于Surprise 和Happy 类别的样本数量,难以支撑深度神经网络捕捉少样本的表情特征。
本文提出的基于生成对抗网络与网络集成的表情识别方法,通过多个异质卷积神经网络提取包含不同深度、不同语义的特征向量,保留细微且表达能力强的表情特征,随后对不同尺度特征进行融合。此外,结合生成对抗网络实现数据集标签平衡化和端到端的训练模式,使得模型能够适应不同场景下的表情识别,缓解不同面部表情数据集中标签数据分布不均衡的问题。
2 模型方法
2.1 网络集成模块Ens-Net
本文首先提出了一种网络集成模型Ens-Net,如图1 所示,该模型结构由修改后的VGG13、VGG16 以及ResNet18 组成。具体而言,输入的面部表情图片通过3 个不同卷积核大小、神经元数量以及网络层数的网络提取面部表情成分特征。Ens-Net 中使用来自VGG13 的完全连接层第5 层,完全连接层的第7 层和来自ResNet18 的全局池化层进行特征提取后得到特征向量h1、h2、h3,随后分别使用符号平方根(Sign Square Root,SSR)和L2 范数对每个特征实现归一化后,利用经典的特征级融合[32]方式将这些特征串联起来,组成具有不同语义级别的全新特征向量hconcat,该方法表示为式(1):

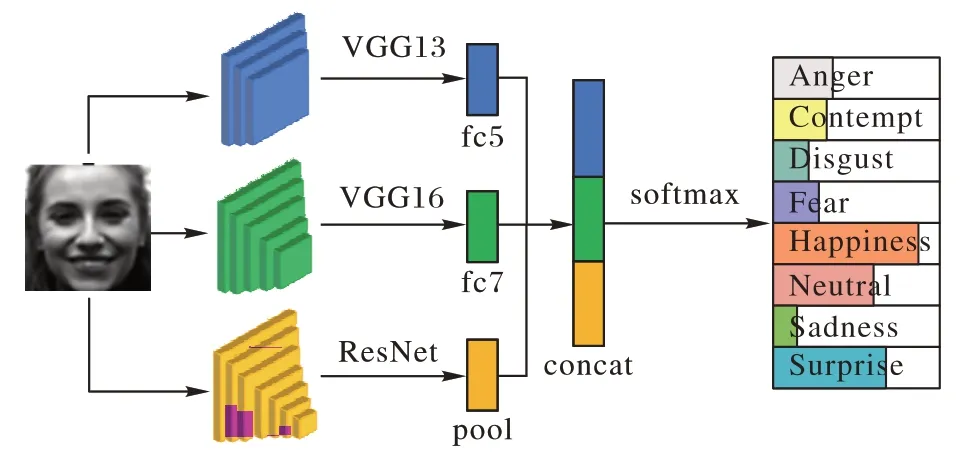
图1 Ens-Net网络结构Fig.1 Network structure of Ens-Net
随后hconcat通过具有softmax 的损耗层实现表情的分类任务。由于网络结构的互补性,通过Ens-Net 所得到的特征包含不同层次深度提取到的深层和浅层表情分量特征,即利用不同网络学习到的特征增强了面部特征的整体表征能力,尤其是在面部表情识别这样关注细节特征的任务中显得极为重要。
2.2 端到端框架EE-GAN
集成网络模型Ens-Net 旨在解决表情分类问题,称做分类器C。在Ens-Net 的基础上,本文提出一种端到端的训练框架EE-GAN,如图2 所示。EE-GAN 旨在结合GAN 的对抗学习思想[33],通过博弈训练生成更多特定标签的面部表情图片以解决数据源域标签分布不均衡的问题。在稳定生成逼真样本的前提下,将GAN 网络部分生成的逼真面部表情图像和真实图像同时送到分类器C进行训练,从而实现完整的端到端的面部表情识别网络。
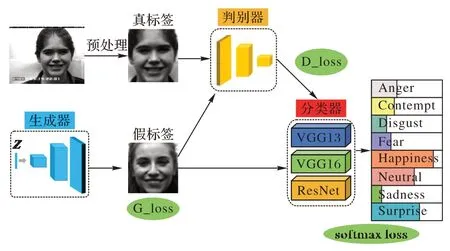
图2 EE-GAN网络结构Fig.2 Network structure of EE-GAN
EE-GAN 由生成器G、判别器D和分类器C组成。生成器G和判别器D采用深度卷积生成对抗网络(Deep Convolutional GAN,DCGAN)[34]基本结构,G通过微步卷积将输入的100 维噪声向量Z扩张到与真实样本相同的尺寸,合成假图像G(Z)。判别器D的输入是真实图像x和G合成的假图像G(Z),其目的是将真实图像和虚假图像区分开。生成器D和判别器G通过极大极小游戏而形成竞争关系,具体来说,当合成样本的分布P(G)和训练样本的分布P(D)相同时,该极大极小博弈获得全局最优解,此时生成器可以生成逼真的合成图片以欺骗过判别器,从而达到了获得新的面部表情图像的目的。
2.3 学习策略
对于Ens-Net 而言,给定一张带有表情标签ye的面部图像x,通过融合不同深度神经网络提取的表情特征向量得到hconcat,将其馈送到分类器实现表情分类。其中分类器使用softmax 交叉熵损失定义如下:
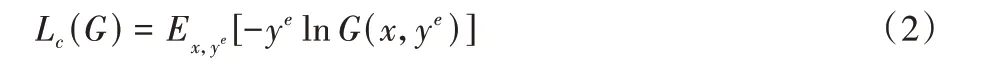
针对EE-GAN 的输入,考虑到选取的数据集的域分布差异较小,将FER2013(Facial Expression Recognition 2013)[11]和CK+(Cohn-Kanade)[35]训练集中的不同表情标签进行整合作为可靠的训练样本。在实际训练过程中,早期阶段的生成器G很差,生成的样本很容易被判别器D识别,这使得D回传给G的梯度极小,无法达到训练目的,出现优化饱和现象。将D的Sigmod 输出层的前一层记为o,则D(x) 可表示为D(x)=Sigmoid(o(x)),此时有:
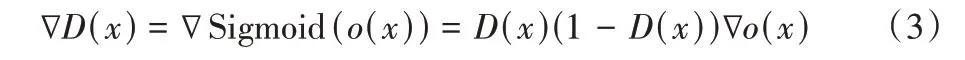
为此,训练G的梯度记为:
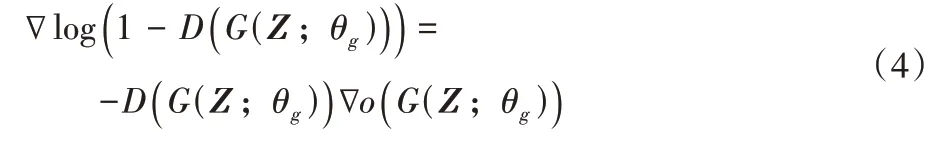
这意味着当D可以轻松辨别出假样本时,正确辨别的概率几乎为1,此时G获得的梯度基本为0。为了保证训练的稳定性,本文将G的优化值函数定义为如下:
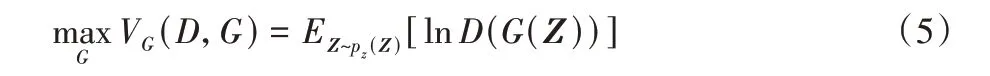
D的目的是尽可能将输入的真实图像x判别为真,将输入的合成图像G(Z)判别为假。训练的过程中G和D交替训练,保证每5 个batch 训练一次G,每1 个batch 训练一次D。此时D的优化值函数定义为:
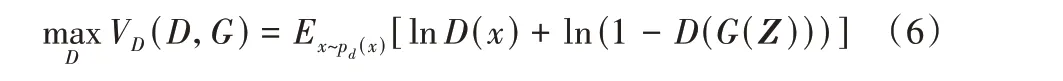
3 实验设定
3.1 数据集
FER2013 是一个由谷歌图像搜索API 自动收集的大型无约束数据库。在拒绝错误标记的帧并调整裁剪区域后,所有图像都已标注并调整为48 像素×48 像素。FER2013 包含35 887 幅表情图像,同时以8∶1∶1 的比例划分训练集、测试集和验证集,其中包含7 种表情标签,即Angry、Disgust、Fear、Happy、Sadness、Surprise 和Neutral。
CK+用于评估FER 系统的最广泛使用的实验室控制数据库。CK+包含来自123 名受试者的593 个视频序列。这些序列的持续时间为10~60 帧不等,数据包含从中性面部表情到峰值表情的转变。在这些视频中,来自118 名受试者的327 个序列被标记为面部动作编码系统(Facial Action Coding System,FACS)的七种基本表情标签,分别是Angry、Contempt、Disgust、Fear、Happy、Sadness 和Surprise。本文的数据选择方法是提取最后1~2 个具有峰形成的帧和每个序列的第一帧(中性面),随后以6∶2∶2 的比例划分训练集、测试集和验证集。
JAFFE(Japanese Female Facial Expressions)[36]日本女性面部表情数据库是一个实验室控制的图像数据库,包含来自10 名日本女性的213 个姿势表情样本。每个人有3~4 幅图像,每幅图像都有6 种基本的面部表情,包括Angry、Disgust、Fear、Happy、Sadness 和Surprise。
通过筛选数据集中清晰高质量的表情图像作为数据样本,本文在后续的实验中都遵循FER2013 和CK+数据集的划分方式进行模型训练和训练过程中的超参数优化调整。考虑到原始的JAFFE 数据集体量小且未划分,本文将FER2013、CK+的测试集和JAFFE 数据集作为测试数据。JAFFE 数据集只参与测试阶段有利于测评模型的泛化性能。在将图片输入网络之前,使用先进的68个界标的脸部检测算法[37]实现面部的对齐和裁剪,将图片尺寸规范到48×48,以减轻与表情无关变量的影响,规范由面部传达的视觉语义信息。
3.2 实施细节
为了测试Ens-Net 的性能,本文首先利用集成网络的构成组件VGG13、VGG16 以及RestNet18 单独进行训练测试在FER 任务上的性能;同时也选取了AlexNet 和ResNet34 等经典CNN 模型进行对比测试。为保证网络的维度参数和输入的图片保持一致,对于AlexNet 的平均池化进行修改,设置卷积核为1、步长为1;为了避免ResNet 的下采样倍数过高导致网络输出的尺寸过小,对于ResNet,将最后的平均池化修改为维度为1 的自适应池化,此外同样对ResNet 作者后期对于基本残差模块的改进进行了实现[38]。在基本的残差块中将提取特征-归一化-激活的步骤进行微调,对于跳跃连接的部分,首先进行归一化-激活操作,即激活函数放在了仿射变换前,这样做可以保证梯度的顺畅,以防止不平衡的网络参数初始化导致出现难以训练的情况,优化后的模型在本文中使用ResNet*表示。随后根据所提方法构建Ens-Net,在图像输入网络之前进行50%的水平翻转,完成基本的数据增强,之后设置均值为0.5、方差为0.5 进行归一化操作。训练过程中使用随机梯度下降(Stochastic Gradient Descent,SGD)优化器进行优化,设置学习率为0.001,权重衰变参数为0.95,每种网络进行300 轮训练。
相较于传统的GAN,本文的网络采用卷积-去卷积的方式代替池化层,同时在G和D中都添加了批量归一化以及去掉了全连接层,使用全局池化层替代。G的输出层使用Tanh激活函数,其他层使用线性整流函数(Rectified Linear Unit,ReLU);D的所有层都使用LeakyReLU 激活函数。训练过程中都采用Adam 优化器,betas 设置为0.999,学习率为1E-4。通过上述策略首先对GAN 部分进行4 000 轮的训练,当G可以稳定生成足够逼真的表情图像后,将GAN 生成的图像和真实的数据集图像同时馈送到分类器C中进行表情识别,实现和Ens-Net 部分结合的端到端的训练模式。此策略的优点是分类损失可以通过参数优化不断惩罚生成损失,以迫使生成器获取更好的生成表示,在提升图像合成的质量的同时提高表情识别的准确率。
4 实验结果
4.1 图像生成和数据平衡
考虑到GAN 容易出现模型坍塌[39]问题,为了防止生成样本丧失多样性,本文中输入的噪声采用均匀分布采样获取。通过将整合后的数据集送到网络进行训练,经过3 550轮左右训练后G的生成数据分布基本已经逼近真实世界下的复杂混合高斯分布[40],G和D损失趋于稳定。如图3 所示,训练后的模型可以逼真地生成8 种面部表情图像;同时,当通过插值微调的方式控制输入的噪声向量Z,在不同表情图像之间,可以实现对除表情外周围面部信息的建模,例如肤色、发型以及脸型等。在同一表情图像中,可以实现不同的表达模式,例如Happy 类别中,不同面部肌肉形变度下抿嘴和张嘴的图像都可以传达高兴、愉悦的情感。

图3 生成器生成的逼真表情图像Fig.3 Realistic expression images generated by generator
无论是FER2013 还是CK+数据集,都存在表情标签分布不均匀的问题。例如通过筛选后FER2013 中的Angry 多达3 995 张图像,然而Fear、Sadness 等标签有400~500 张图像,Disgust 标签仅仅有56 张图像。同样的情况也存在于CK+数据集中,这极大地降低了部分表情的识别准确率。为了解决此问题,本文将EE-GAN 生成的逼真图像与源域的数据集图像进行整合,通过添加和调整不同表情标签数量以降低标签不均衡的影响。
考虑到低样本标签图像生成难度大,在尽可能保证标签域平衡的前提下,本文使大部分表情标签的数量处于600~800。如表1 所示,第2~4 行展示筛选后源数据集包含的不同表情的样本数目;第5 行是经过调整后混合GAN 生成图像的最终数目。具体来说,对较少的表情标签图像进行补充,例如将原本的总体262 幅Disgust 图像补充到653 幅;对较多的表情标签进行稀释,例如将4 130 幅Angry 图像减少到800幅,从而达到平衡不同表情标签样本的目的,减缓数据集长尾分布带来的模型性能约束。

表1 FER2013、CK+、JAFFE数据集以及通过GAN整合后的不同表情图像的数量Tab.1 Numbers of different expressions’s images on FER2013,CK+,JAFFE and integrated datasets
4.2 对比实验
观察表2 可知,本文将提出的EE-GAN 与现有相似的基于视图学习的表情识别方法,如局部保留投影方法(Locality Preserving Projection,LPP)[41]、判别式高斯过程潜在变量方法(Discriminative Gaussian Process Latent Variable Model,DGPLVM)[42]、高斯过程潜在随机场方法(Gaussian Process Latent Random Field,GPLRF)[43]、向量式线性判别分析方法(GensiM Linear Discriminant Analysis,GMLDA)[44]进行对比,EE-GAN 的性能得到了最佳的结果,在3 个测试数据集上的准确率分别达到了82.1%、84.8%和91.5%。同时,与传统的单一网络结构的CNN模型AlexNet、VGG、ResNet以及ResNet*相比,EE-GAN 在3 个数据集上的准确率分别至少提高了9、10、16 个百分点。EE-GAN 出色的表现一方面得益于不同尺度表情特征融合策略下Ens-Net 模块强大的特征表征能力;另一方面受益于GAN 生成部分的数据增强和数据集标签平衡处理,缓解了表情标签不均衡对于FER 整体精度的影响。同时,通过端到端的训练模式,迫使生成损失和分类损失的不断促进优化,使得网络获取到更加精确的表情特征。
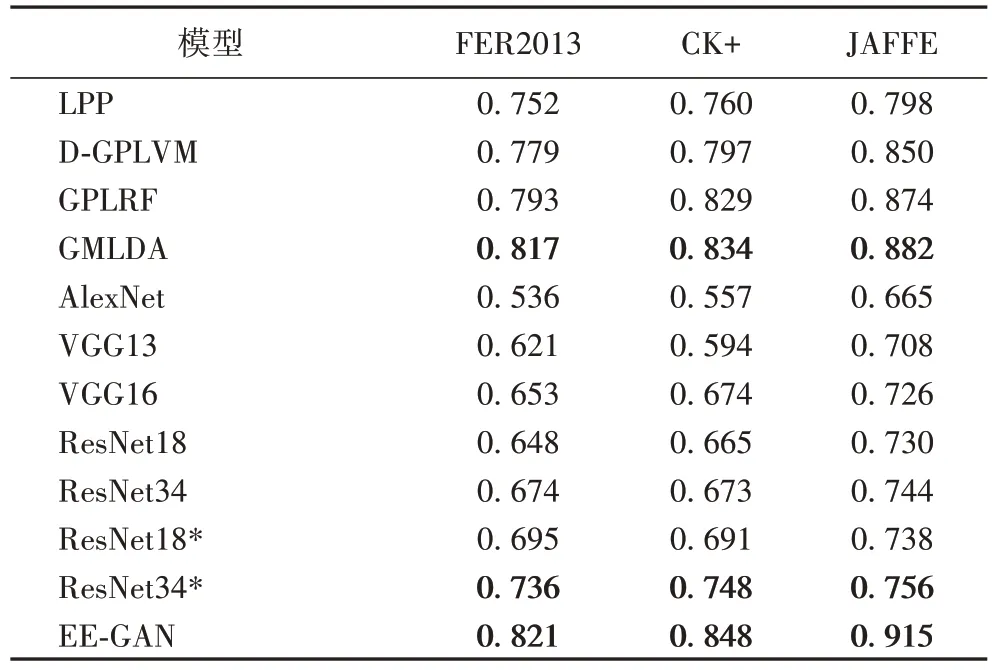
表2 不同网络模型在FER2013、CK+、JAFFE数据集的准确率Tab.2 Accuracies of different network models on FER2013,CK+,and JAFFE datasets
图4 展示了不同数据集上基于EE-GAN 的表情分类混淆矩阵,通过观察归一化之后的每种表情的预测结果发现,Angry 和Sadness 的准确率普遍要稍微低于其他表情,其中可能的原因是这两种表情的面部动作单元相对较少,影响了识别精度;同时Happy 和Fear 的识别结果经常容易混淆,很大的可能在于这两种表情拥有相似的肌肉形变度,这与Zhang等[45]和Yang 等[28]的研究结果相吻合。
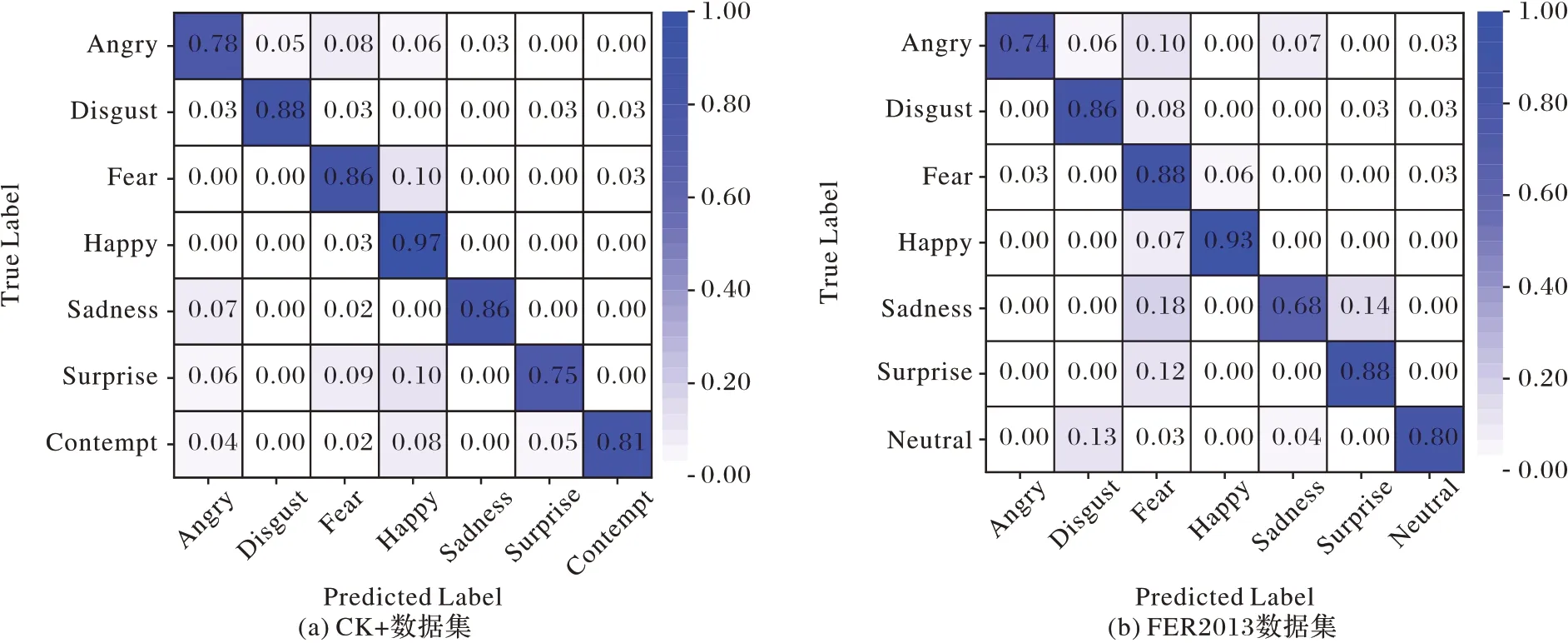
图4 混淆矩阵可视化Fig.4 Confusion matrix visualization
4.3 消融实验
为了进一步验证Ens-Net 模型和EE-GAN 框架的有效性,本文在数据集进行相同划分和数据预处理前提下,通过更换不同尺度网络集成部分得到的特征向量和改变不同的组合方式进行消融实验。具体地,将Ens-Net分为三种组合方式,分别使用VGG13 和VGG16、VGG13 和ResNet18、VGG16 和ResNet18 进行网络集成测试,随后在三种不同组合的基础上都加入GAN 部分,设置三种不同的EE-GAN 网络进行测试,观察到测试集的准确率如表3 所示。
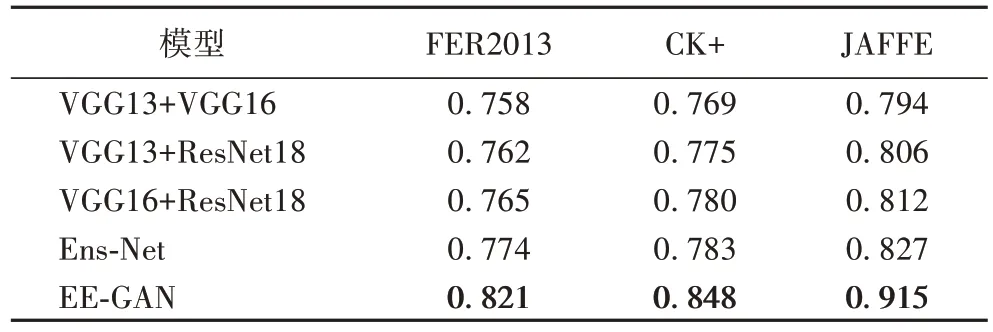
表3 FER2013、CK+以及JAFFE数据集上的消融实验结果Tab.3 Ablation experiment results on FER2013,CK+,and JAFFE datasets
消融实验结果显示,Ens-Net 网络集成方法的性能优于任意两组不同深度网络模型集成的性能,同时两组网络集成模型准确率的逐渐提高也证明了越深的网络结构将输出表示能力越强的特征。因此将不同尺度的特征进行融合,可以获取到表征能力更强的特征,这也为模型带来更强的分类能力。EE-GAN 框架使得准确率在Ens-Net 基础上均提升3%~5%,将生成对抗网络模型与网络集成思想相结合,既可以结合多个异质网络提取的不同深度的表情特征,又实现了数据增强以解决表情标签数据分布不均的问题,从而有效提高了模型的表情识别能力。
5 结语
本文提出了一种包含网络集成模型Ens-Net 的端到端深度学习框架EE-GAN。该模型通过结合不同深度的表情特征实现特征级融合,以学习到更加精确有效的情感表征。受益于端到端的训练模式,EE-GAN 在实现数据增强的同时生成具有特定表情标签的面部图像,极大缓解了数据集表情标签分布不均衡的影响,提高了表情识别的准确性。通过在3个标准数据集上的实验结果表明,本文提出的EE-GAN 在表情分类性能和准确度方面优于传统CNN 模型和现有改进模型,证明了模型的有效性。未来,研究工作将在模型的解耦表示中考虑面部遮挡、光照和姿势等其他因素的影响,进一步提高表情识别的准确性。
