基于深度注意力网络的课堂教学视频中学生表情识别与智能教学评估
2022-04-12于婉莹梁美玉王笑笑陈徵曹晓雯
于婉莹,梁美玉,王笑笑,陈徵,曹晓雯
(北京邮电大学计算机学院,北京 100876)
0 引言
表情是人类表达情感信息的主要途径,表情识别算法通常可以识别出常见的几种人脸面部情感,例如高兴、悲伤、愤怒、恐惧等。目前许多优秀的表情识别算法已经实现了该目标[1-3]。目前主流的表情识别算法结构主要依托于AlexNet[4]、ZF Net[5]、VGGNet[6]、GoogleNet[7]、ResNet[8],但表情信息总是跟其他很多因素交织在一起,比如头部姿态、光照和个体身份信息,多种外部因素的交织会对表情信息产生一定的影响。为了解决这一问题,Zhang 等[9]引入了多任务学习,将这些信息从其他相关任务中转移出来,并克服了干扰因素对表情识别任务的影响;Acharya 等[10]提出了基于流形网络结构进行协方差合并的表情识别算法,利用二阶统计量捕捉面部扭曲,利用协方差池更好地捕获了区域面部特征的畸变以及每帧特征的时间演化;Minaee 等[11]提出了一种基于注意力卷积网络的深度学习方法,能够专注于面部的重要部位,并且使用可视化技术根据分类器的输出找到重要的面部区域以检测不同的情绪。但是目前将人脸表情识别应用于真实复杂场景下的智慧教育领域,识别课堂中学生的面部表情进而分析学生对课堂的参与度、兴趣度等内容的研究并不深入。目前基于深度学习的表情识别算法,普遍使用深度卷积神经网络对图像或视频进行特征学习,但课堂场景下学生表情常常处于被遮挡状态,遮挡部分丢失的学生表情信息不可避免地会对表情特征的学习产生影响,无法获取有效学生表情特征。
针对以上问题,本文提出了一种基于深度注意力网络的课堂教学视频中学生表情识别模型,该模型致力于实现复杂课堂场景下的表情识别任务,能充分学习学生面部表情的局部特征和整体特征,进而获取学生表情细节特征,学习到的学生表情识别模型在遮挡情况下的识别能力和优势更加突出。本文在构建学生课堂表情识别模型时,首先构建了基于自注意力机制的深度注意力网络,网络结构由五路相同卷积神经网络组成,五条支路网络用来学习人脸表情局部细节区域和整体特征。为了使模型充分关注到对表情分类有重要影响的局部区域,引入自注意力机制和约束性损失函数对权重进行调节,使模型关注对表情分类有更大影响的人脸表情区域,以解决由于遮挡导致的学生表情信息丢失及无法获取有效特征等问题,相较于普通卷积神经网络,该方法有效分类复杂课堂场景下的学生表情,使整个学生课堂表情识别模型的性能有所提升。
在学生学习过程中,情感会影响学生的认知行为,所以把握学生在课堂中的情感状态,对提升课堂效率以及促进学生个性化教育发展都显得尤为重要,而学生的面部表情则是评价课堂状态的一项重要表征。目前有许多根据学生表情来评估学生听课状态的相关研究[12-14],但是目前来讲仍然存在一些潜在问题,例如对于在不知道学生处于某种行为状态下所表现出的面部表情,仅单纯地根据识别到的表情,对学生的听课状态做出评估是不严谨且不全面的。同样,单纯地根据学生课堂行为去进行学生听课状态的评估也存在一定的局限性,原因在于学生的课堂行为可以是由老师要求引导下被动发生,也可以是由学生根据自身听课状态主动发生,所以在没有得知行为发生动机的情况下,仅凭学生行为去评估听课状态是不全面的。
针对以上问题,本文提出了一种融合教学课堂视频中学生表情和行为识别[15]的智能教学评估算法(Weight_ClassAssess,WCA)。其主要思想是:首先,不再单一地仅根据学生表情或者行为状态对学生听课状态进行评估,以避免由此带来的评估结果不够全面充分的问题;其次,为了更加客观、全面地对学生听课状态进行评估,将每一位学生的表情和行为进行融合,从两个不同的特征维度综合评估学生的听课状态,其动机是根据识别到的学生在课堂中某种行为状态下的表情状态进行课堂教学评估更具参考意义。该算法分别计算积极类别的表情和行为概率,然后对两个概率值赋予不同权重计算得到最终的综合课堂状态评估值,最后针对该值进行分析,设计相应的课堂教学评估规则,得出相应的课堂教学评估等级。
本文的主要贡献和创新点如下:
1)提出了一种新颖的基于深度注意力网络的课堂教学视频中学生表情识别模型。该模型通过五路深度卷积神经网络分别学习原始人脸图像、裁剪图像和遮挡图像有效特征,进而学习到人脸图像的局部特征和整体特征,同时引入自注意力机制对五路网络进行权重分配,通过融合局部特征与全局特征,有效学习学生表情特征。
2)构建了课堂教学视频库、表情库和行为库。其中课堂教学视频库共包括90 个清晰的课堂教学视频。考虑到场景一致性,本文还建立了表情库和行为库,其中包括学生表情状态图像725 幅,学生行为状态图像2 300 幅。
3)提出了一种融合教学课堂视频中学生表情和行为识别的智能教学评估算法(WCA),通过融合教学课堂视频中的学生表情和行为对学生课堂状态进行综合评估,实现了课堂整体教学评估以及针对每个学生的听课状态评估。
1 基于深度注意力网络的学生表情识别模型
1.1 模型框架
考虑到课堂场景下学生表情常常处于被遮挡状态,遮挡部分丢失的学生表情信息不可避免地会对表情特征的学习产生影响,且仅使用一路卷积神经网络对学生表情特征的学习无法自动关注学生表情有效区域,无法获取有效表情信息,为此本文提出了基于深度注意力网络的学生表情识别模型,如图1 所示。该表情识别模型主要分为:表情特征学习、注意力特征权重分配、表情特征融合和表情分类四部分。
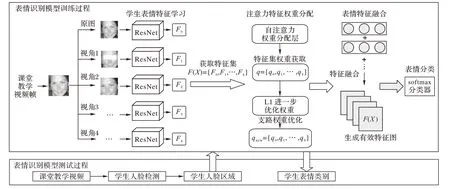
图1 基于深度注意力网络的课堂教学视频中学生表情识别模型Fig.1 Expression recognition model of students in classroom teaching video based on deep attention network
首先,对课堂教学视频帧中的原人脸图像进行裁剪和遮挡,将裁剪和遮挡后的人脸图像与原人脸图像分成五路,通过基于深度注意力卷积神经网络的学生表情特征学习模块的各支路网络分别提取人脸表情特征;然后,通过注意力特征权重分配模块,基于自注意力机制为不同支路网络学习到的特征分配不同权重,得到每个支路特征集的新的注意力权重,同时为新的注意力权重添加约束性损失函数,使被遮挡路径不能成为权重最大支路;最后,将所有的支路表情特征通过表情特征融合模块,将各支路特征及各支路权重归纳成人脸表情的全局特征表示,全局特征表示为各个支路加权注意力特征之和,即最终的人脸表情全局表示特征,在网络的末端使用softmax 分类器对学生人脸表情进行分类,从而完成整个模型的构建。
1.2 基于深度注意力网络的学生表情特征学习
由于课堂场景下学生人脸大概率存在遮挡,导致表情信息丢失,因此本文构建了基于自注意力机制的深度卷积神经网络用于学生表情特征学习。为了进一步融合局部表情特征、遮挡后的表情特征和整体表情特征,本文构建了五条支路分别提取局部特征、遮挡后的特征和整体特征,各支路网络由五路相同卷积神经网络组成,在支路网络的末端接入全连接层和激活函数,用于捕获各支路网络所占权重,同时在优化各支路所占权重时还引入了约束性损失函数,进一步调整各支路所占权重,实现局部与整体特征的融合,获得有效表情特征图。
首先在该网络前输入一张人脸图像,先将其复制,得到X0,再将X0进行裁剪和遮挡,得到X1~X4,再把每幅图像输入到相同的各支路卷积神经网络中提取各支路表情特征,其中X=[F0,F1,…,F4]为各支路得到的人脸表情特征集。将人脸表情特征集输入到特征权重分配层,每张图像特征Fi编码为一个全局特征zi,通过两个全连接层学习不同学生表情特征的注意力权重,学生表情特征注意力权重计算公式如下:

其中:qi为每个支路表情特征权重,W1和W2为全连接层权重,R为ReLU 激活函数,S为Sigmoid 激活函数。计算得到的注意力权重与通过各支路卷积神经网络学习到的特征相乘得到优化后的全局表情特征,通过自注意力机制层输出的全局表情特征计算公式如下:

其中:Fm为经自注意力机制调整后的全局表情特征,Fi为各支路卷积神经网络学习到的学生表情特征,c为支路数。
得到的Fm为局部与整体相结合的全局表情特征,表情特征通过深度注意力网络的优化为人脸表情不同区域分配不同权重,过滤了冗余信息,克服了人脸遮挡问题对表情识别造成的影响。
1.3 约束性损失与标签损失函数
为了进一步约束遮挡图像在各支路中的占比,本文对max-margin 函数进行改进,使遮挡支路的权重一定小于各支路中最大权重,改进后的约束性损失函数公式如下:
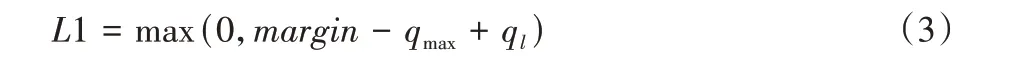
其中:qmax为各支路权重最大值,ql为遮挡支路权重,margin为阈值。
在训练过程中,各支路的自注意力的权重分配机制可以初步学习各支路在全局特征中的重要性,但人为的人脸图像遮挡必定使图像失去一定量信息,因此,对遮挡支路的约束显得尤为重要,通过限制遮挡支路所占权重最小进一步弥补人为遮挡所带来的表情信息丢失;同时将分类损失与约束性损失结合对学习到的表情特征进行优化。分类损失函数如下:
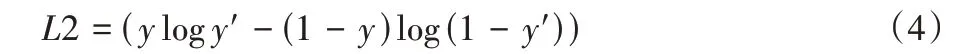
其中:y代表真实表情标签期望,y′代表预测表情标签期望。最终约束性损失函数与分类损失函数相结合对表情分类模型进行优化,优化总损失函数如下:

改进后的约束性损失函数增强了自注意力机制的效果,通过该约束性函数进一步优化各支路权重,从而进一步优化全局表情特征表示。
1.4 课堂教学视频中学生表情识别
本文基于深度注意力网络构建课堂视频中的学生表情识别模型,网络结构由深度卷积神经网络和注意力机制结合而成,目的是克服真实场景中遮挡对表情信息丢失的影响,进而用来提取每个学生的面部表情特征,相比常规深度卷积神经网络,整个学生课堂表情识别模型的性能有所提升。
在进行网络构建时,首先通过深度注意力网络学习学生表情特征;然后通过合理分配学生表情各区域权重学习到更丰富的有效表情特征表示;最后在网络的末端使用softmax分类器[16]对表情进行分类,从而完成整个模型的构建。
在进行学生课堂表情识别时,首先对载入的课堂视频数据进行关键帧的获取,并对获取到的关键帧进行灰度化、图像增强等操作;然后进行学生人脸检测并选择感兴趣区域最大的人脸;最后提取学生人脸面部的表情特征进行预测,得出各类表情概率并选择最大概率的表情类别作为输出。课堂教学视频中学生表情识别算法伪代码如下:

2 课堂教学视频中表情识别在智能教学评估中的应用
在课堂教学视频中学生表情识别的基础上,本文将其应用于智能教学评估,以实现智慧教育。为了更加精确地基于课堂教学视频实现智能教学评估,本文提出了融合学生表情和行为识别的智能教学评估算法。首先对学生课堂视频进行学生目标检测和跟踪,定位视频中的每个学生目标,对检测到的学生目标进行表情识别和行为识别;然后通过融合表情和行为的识别结果综合进行课堂教学状态评估值的计算;最后根据综合评估值判定学生课堂听课状态。提出的融合学生表情和行为识别的智能教学评估算法结构如图2 所示。
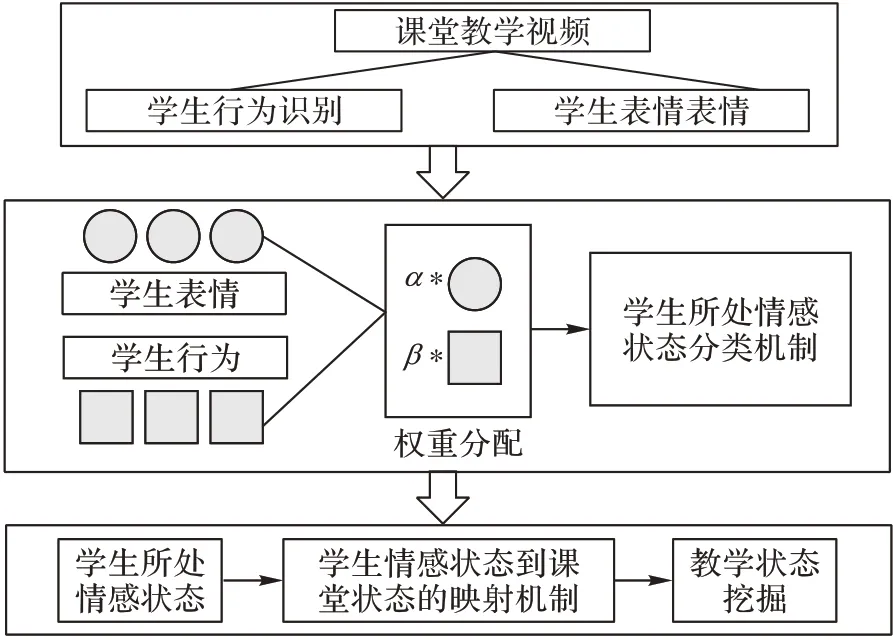
图2 融合学生表情和行为识别的智能教学评估算法框架Fig.2 Framework of intelligent teaching evaluation algorithm based on students expression and behavior recognition
首先进行学生目标检测标注出视频当中的学生目标,然后对每一个标注出的学生目标采用提出的基于深度注意力网络的表情识别模型进行表情识别,并利用基于深度卷积神经网络的行为识别算法对学生行为进行识别[17]。由于行为识别和表情识别同时进行,所以当识别到学生的行为状态是低头或者转头时会不进行表情识别以降低对最终综合评估的影响。根据记录的学生表情识别结果和行为识别结果,统计积极表情(开心、专注、理解)、消极表情(沮丧、抵抗、不屑)、中性表情(困惑)三种表情类别对应的人数及概率值,统计积极行为(听讲)、消极行为(低头、转头)、中性行为(站立)三种行为类别对应的人数以及概率值,然后对表情和行为分配权重计算得到最终的综合评估值,最后根据综合评估值分析判定学生的听课状态。
在融合课堂学生表情和行为的智能教学评估算法中,用α表示分配给表情识别结果的权重值,β表示分配给行为识别结果的权重值。
首先,用count表示各类表情或行为的人数,通过式(6)计算统计从课堂视频中识别到的学生总人数:
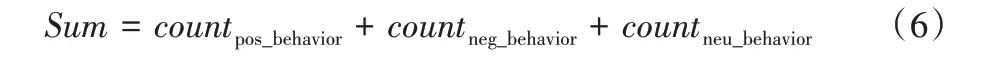
然后,分别计算积极表情和积极行为的概率值:

接着,对表情识别结果和行为识别结果分配权重,计算最终的综合评估值:

最后,针对综合评估值来分析学生的整体课堂状态评估等级。
不同条件下的课堂状态评估等级一共分成了7 个等级,分别是A+等级、A 等级、B+等级、B 等级、B-等级、C 等级和C-等,各个等级含义如下。
A+等级 认真听讲、积极参与课堂学习的学生人数比例大约占到了整个课堂人数的75%以上。
A 等级 整体课堂状态与A+等级较接近,积极人数比例占整个课堂的(70%,75%],表征整个课堂还不错。
B+等级 整体课堂状态与A 等级比较接近,大部分(67%,70%]学生处于认真听课的状态,只存在部分极少数学生听课不认真,可在课后与学生进行沟通交流。
B 等级 课堂中有一少部分学生听讲不认真,不能够积极主动地参与课堂学习,但整体来说,认真的学生人数(65%,67%]还是要大于不认真的学生人数。
B-等级 课堂当中不认真听讲、积极参与课堂的学生人数超过整体课堂总人数的近一半(45%,65%],说明整个课堂效果并不理想。
C 等级 课堂当中不认真听讲,没有积极参与课堂的学生人数过多,即积极学生人数仅占(30%,45%]。
C-等级 课堂存在诸多问题,应该及时找出根源问题,做出相应调整。
3 实验结果与分析
3.1 数据集
为了进一步验证提出的表情识别方法和智能教学评估方法的准确性,本文使用公开人脸表情数据集FERPlus 和自建课堂教学视频数据集进行验证。
FERPlus 是在ICML 2013 表征学习挑战中引入的FER2013 的延伸,它是谷歌搜索引擎收集的大规模真实人脸表情数据集,包括28 709 幅训练图像、3 589 幅验证图像和3 589 幅测试图像。数据集中的所有人脸图像将对齐并调整为48×48。FERPlus 主要标注为8 个表情标签(中性、快乐、惊讶、悲伤、愤怒、厌恶、恐惧、轻蔑),作者评估了几种训练方案,如单热点标签(多数投票)和交叉熵损失的标签分布。本文主要通过多数投票的方法测试总体准确性。
自建课堂教学视频数据集是包涵学生表情和学生行为动向的视频,共90 个课堂教学视频片段,采集于互联网真实课堂下的场景,该数据集主要用于智能教学评估方法的验证。
3.2 实验设置
将所有视频帧调整大小为224×224。实验环境为Pytorch1.6。对于五条支路卷积神经网络的主干,本文主要使用ResNet-18。在所有数据集上,学习速率初始化为0.01,在30 个epoch 后除以10。
3.3 实验结果与分析
3.3.1 实验1
本文在公开数据集FERPlus[18]上比较提出的模型与对比模型的性能,各对比模型如下:
Probabilistic Label Drawing(PLD)[18]是一种基于深度卷积神经网络从噪声中提取表情特征的模型。
Deep-emotion[11]是一种基于注意力机制专注于提取对表情识别有重要影响面部区域的模型。
Efficient-Net[19]是一种基于共享表示集成的表情识别模型。
它们在测试集上的准确率如表1 所示。

表1 各模型准确率对比 单位:%Tab.1 Accuracy comparison of different models unit:%
观察表1 的实验结果可以发现,相较于其他三种模型,本文模型在公开数据集FERPlus 上获得了最高的准确率,因为所提模型融合了局部与整体表情特征,且对表情有效区域给予更高权重,解决了遮挡情况下表情信息丢失造成的无法学习有效表情特征的问题。为了进一步验证提出的基于深度注意力网络的表情识别模型的有效性,将所提模型和基于注意力机制的Deep-emotion 模型进行了对比,实验结果如图3 所示。

图3 两种模型在测试集上的准确率对比Fig.3 Accuracy comparison of two models on test set
观察图3 发现,所提模型相较于Deep-emotion 模型,在第1 轮时准确率就已经达到80.9%,高出Deep-emotion 近30 个百分点,说明本文模型在第1 轮就已经达到较好表情识别效果,并且在第3 轮准确率曲线就已经逐渐趋于平缓,而同样基于注意力机制的Deep-emotion 在第8 轮时才趋于平缓,由此可见相较于常规基于注意力机制的表情识别模型,本文模型可以快速学习到有效的人脸表情特征。
为了验证约束性损失函数的margin值对模型准确率的影响,本文还进一步设置了不同margin值以验证所提模型对参数的敏感性,准确率结果如图4 所示。
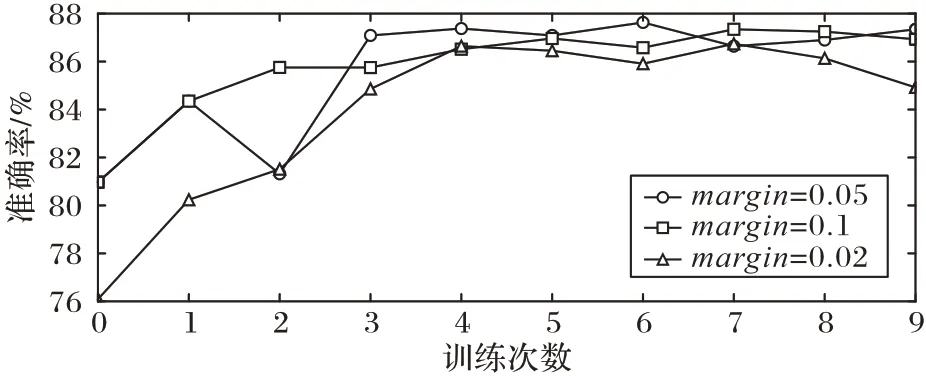
图4 参数敏感性实验结果Fig.4 Parameter sensitivity experiment results
本文设置margin值分别为0.02、0.05 和0.1。由图4 可观察到:在margin值为0.05 时可达到最好效果,并且可以在第1 轮训练就达到较高准确率,且在后续轮数中表现始终平稳,一直处于准确率较高水平;而margin值为0.02 时准确率一直较低,由此可见过低的margin值会使阈值得设定无法产生应有的作用,无法有效优化并加大各个支路的权重分配;而过高的margin值的设定会使各支路权重相差过多,失去多路网络设定的意义,因此本文margin值设置为0.05。
3.3.2 实验2
为了进一步验证约束性损失函数对模型准确率提升的有效性,本文还设计了消融实验来验证加入约束性损失函数对分类效果的影响。
本文将模型中约束性损失函数去掉对比原模型在FERPlus 数据集上进行了验证,通过图5 可以看出,约束损失性函数的加入使得模型对于表情分类的准确性有所提升,验证了约束损失函数可以对支路权重进行进一步优化,自适应地调节各支路权重占比,从而模型的性能有所提升。

图5 消融实验结果Fig.5 Ablation experiment results
3.3.3 实验3
为了进一步测试所提出的课堂教学评估算法在真实课堂场景下的性能及有效性,针对提出的融合课堂表情和行为的智能教学评估算法(WCA),对采集到的90 个学生课堂视频数据上进行了性能评估,对每位学生的状态进行准确率预测,通过对学生表情与学生行为的识别,判断课堂学生所处状态,测试部分视频准确率结果如表2 所示。
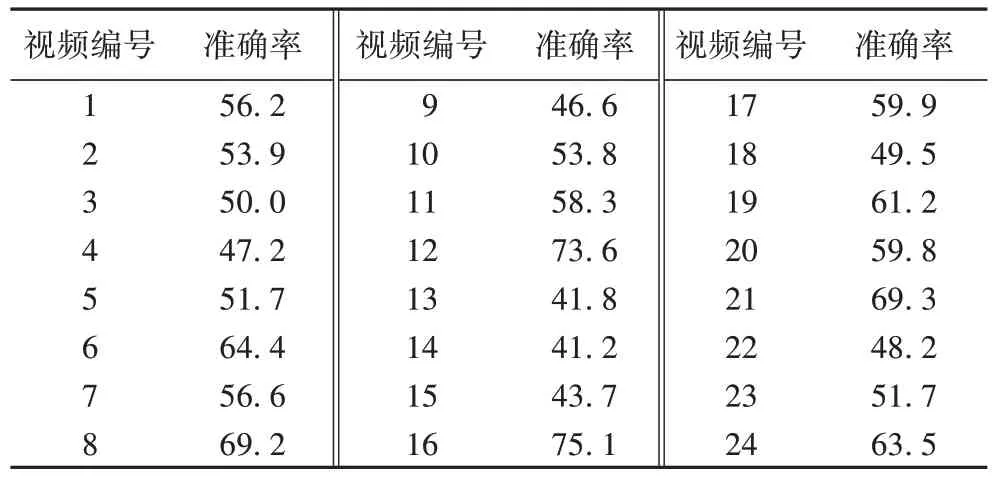
表2 WCA准确率测试 单位:%Tab.2 Accuracy test of WCA unit:%
从表中可以看出所提算法在各个视频上已经取得了较好的准确率,最高达到73.6%。但由于行为识别算法的加入也会产生一定误差,因此课堂教学视频中存在识别准确率过低的情况。此外,为了更好地验证提出的融合课堂表情和行为的智能教学评估算法,将所提算法与基于表情的课堂教学评估算法、基于行为的课堂教学评估算法和基于概率融合的课堂教学评估算法进行了对比,部分预测与标注结果如表3和表4 所示。
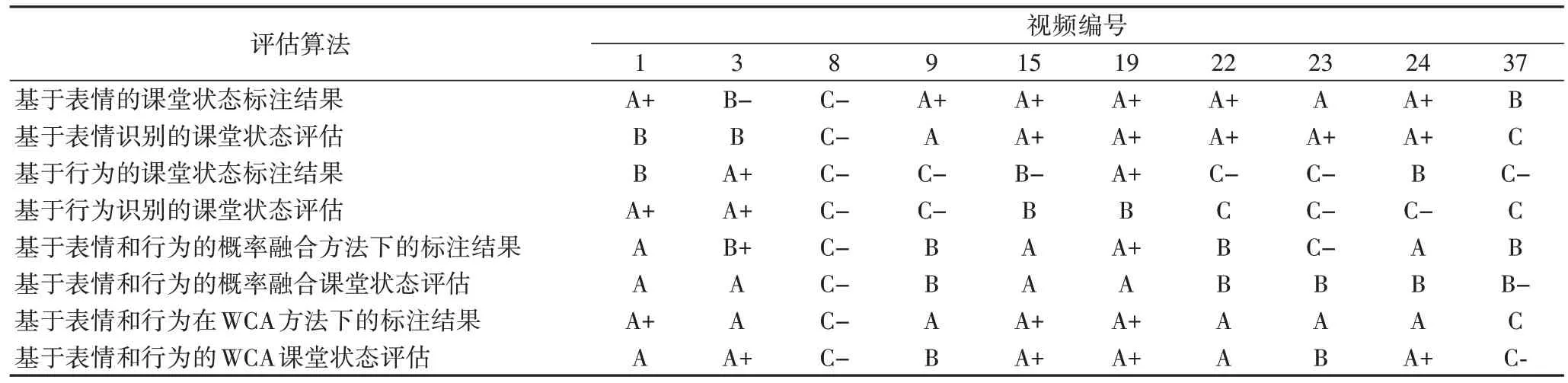
表3 各课堂教学评估算法结果对比Tab.3 Comparison of classroom teaching evaluation results among different algorithms

表4 各课堂教学评估算法平均准确率比较 单位:%Tab.4 Average accuracy comparison among different classroom teaching evaluation algorithms unit:%
通过表4 和表5 中实验结果可以发现,本文提出的融合课堂表情和行为的智能教学评估算法的平均准确率为56.7%,介于表情识别和行为识别的准确率之间,高于基于概率融合的课堂评估准确率。由于提出的融合课堂表情和行为的智能教学评估算法对表情和行为两者的结果进行了相应的权重分配,然后对综合得出的数值进行了评定等级的划分,更加充分地综合了表情和行为的识别结果,并且通过实验,选取合适的权重值会使最终的结果更加准确。本文提出的课堂教学评估方法同时融合了表情和行为,表情和行为识别的误差都会对算法的评估带来一定影响,因此虽然本文提出算法的平均准确率低于基于行为识别的智能教学评估,但基于行为识别的方法未加入表情识别的误差,本算法考虑因素更加全面,准确率结果更加客观。
4 结语
本文以课堂教学视频中的学生表情识别问题为研究对象,提出一种端到端的、基于深度注意力网络的课堂教学视频中学生表情识别模型。它通过多支路的学生表情特征学习和基于自注意力机制的权重调整,融合表情局部与全局特征,更合理地学习学生表情特征,提高对课堂学生表情识别的准确性,最后提出了融合课堂学生表情和行为的智能教学评估算法,实现了课堂状态的整体评估以及面向每个学生的听课状态评估。在课堂教学视频数据集和公开数据集上的实验结果表明,本文提出的学生表情识别模型以及智能教学评估方法优于现有的现有模型。在未来工作中,本模型还将进一步考虑时序关系对表情识别的影响,将本模型应用于视频序列中。
