数据表示和特征修正在人岗匹配研究中的应用
2022-04-12常兵褚志海印忠文赵龙军
常兵 褚志海 印忠文 赵龙军
摘 要: 人岗匹配度的合理测算是人才合理分配的基础,针对传统人岗匹配研究中主观评价占比高、数据表示粗糙等问题,对人岗匹配度测算方法进行了研究。首先构建了人岗匹配度指标体系;其次进行特征构建得到特征字段属性,采用数据表示和特征修正的技术方法进行特征表示、多区间划分及修正,完成各指标匹配度的测算;最后采用XGBoost算法构造人岗匹配度分类模型,将模型概率值作为匹配度测算值,通过真实招聘数据对该方法的有效性进行了验证。
关键词: 指标体系; 数据表示; 特征修正; 人岗匹配度
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2022)04-09-04
Application of data representation and feature modification
in resume-post matching research
Chang Bing Zhu Zhihai Yin Zhongwen Zhao Longjun
(1. CETC big data Research Institute Co., Ltd, Guiyang, Guizhou 550022, China; 2. China xiongan Group Co., Ltd)
Abstract: The reasonable estimation of resume-post matching degree is the basis of rational allocation of talents. Aiming at the problems of high proportion of subjective evaluation and rough data representation in the traditional resume-post matching research, the estimation method of resume-post matching degree is studied. Firstly, the index system of resume-post matching degree is constructed. Secondly, the feature field attributes are obtained by feature construction; the technical methods of data representation and feature modification are used for feature representation, division, modification, and the calculation of the matching degree of each index. Finally, the XGBoost algorithm is used to construct a classification model of resume-post matching degree and the model probability value is used as the matching degree estimation value. The effectiveness of the method is verified by real recruitment data.
Key words: index system; data representation; feature modification; resume-post matching degree
0 引言
眾多企事业单位在评价简历与岗位是否匹配时往往采用主观评定的方法,该方法一般对评价人的经验积累和精力投入要求较高,在时间充裕、小批量的情况下,效果较好,但是在互联网信息技术高速发展的今天,主观评定法已经无法满足短时间内、大量人岗数据快速匹配的需求。如何快速、准确地测算人才与岗位的匹配度,从而科学合理地进行人岗分配管理成为众多企业研究的重点。
近年来,人岗匹配研究主要集中在概念、评价指标体系、数据维度、数据处理与量化、计算模型等几个方面。李晓宁等[1]从员工职业胜任力与企业需求方面研究了员工与岗位需求的匹配情况;袁珍珍等[2]和易斌等[3]分别研究了BP神经网络和支持向量机在人岗匹配测算中的应用;李娟等[4]进行了基于灰色系统理论的人力资源岗位匹配度研究;李松等[5]研究了基于直觉模糊的多指标人岗双边匹配决策方法;PAZZANI等[6]和GOPALAN[7]等根据岗位要求和应聘者简历研究了基于内容匹配的方法。尽管目前人岗匹配测算的研究取得了一定成果,但是多数研究停留在人岗匹配度指标体系构建和简单的数值匹配层面,且评分公式权重的确定大多依赖于调查问卷或专家评估,存在数据利用程度低、智能化难度大、计算结果不准等问题。因此,本文提出了一种基于数据表示和特征修正的人岗匹配度测算方法:首先构建了人岗匹配度测算指标体系;其次采用特征数据修正和数据处理与表示的技术方法对数据集进行特征表的构建、特征数据修正、多区间划分及表示;最后,采用XGBoost算法构建人岗匹配度分类模型,将模型输出的概率值作为匹配度测算值,最终实现人岗匹配度测算。
1 人岗匹配度测算指标体系的构建
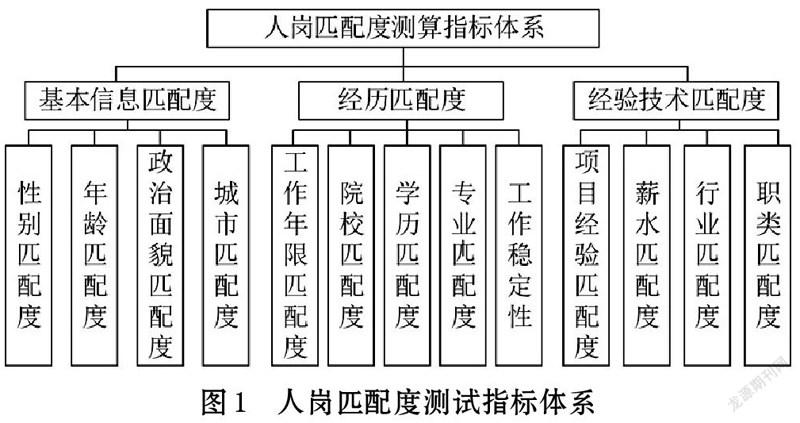
本文基于科学性、简单性、有效性、可实施性、可量化性、统一性的指标体系构建原则,结合真实招聘数据的统计分析结果和经验常识,确定影响人岗匹配的指标因素,构建的人岗匹配度测算指标体系如图1所示。735EF330-3615-4D53-B292-BA567E9EE863
图1所示的人岗匹配度测算指标体系中一级指标包含3个维度:基本信息匹配度、经历匹配度、经验技术匹配度,其中基本信息匹配度包含4個二级指标,主要为人员与岗位中性别、年龄、政治面貌、城市的匹配程度;经历匹配度包含5个二级指标,分为学业经历和工作经历两个方面,二级指标包括学历匹配度、专业匹配度、院校匹配度、工作年限匹配度和工作稳定性;经验技术匹配度包含4个二级指标,主要为项目经验匹配度、薪水匹配度、行业匹配度和职类匹配度。
2 特征数据修正及数据表示
2.1 构建特征表字段
为了得到能够应用于模型训练测试的特征数据集,根据上述人岗匹配度测算指标体系,对各大在线招聘网站的数据进行统计分析,构建简历特征和岗位特征,其中简历特征属性反映了人员的背景信息及相应的求职意愿,主要包括性别、年龄、政治面貌、居住地、专业、院校、工作经验、行业、职类等属性;岗位特征反映的是该岗位的特性及需求,主要包括岗位名称、学历要求、年龄要求、职位、性别要求、岗位描述、工作年限等属性。
2.2 特征数据修正
结合上述所构建的岗位特征,对简历、岗位的真实数据进行特征匹配和统计分析发现特征数据几乎相同的两条数据其匹配的结果是不一样的,如同一份简历特征数据,针对两条特征相同的岗位信息其匹配结果是不同的。针对上述问题,本文针对数据中匹配不一致的数据进行统计分析发现,在结构化特征字段相同的情况下,岗位特征表中的“岗位描述”字段属性中包含了“性别要求”、“年龄要求”、“政治面貌要求”、“毕业院校类别要求”、“工作年限要求”、“岗位职责”、“福利待遇”等信息,如“年龄不超过35周岁”、“具有3~5年的工作经验”。由于“岗位描述”在进行人岗匹配过程中是招聘单位和人员所关注的重点信息,同时“岗位描述”中的长文本信息无法直接用关键字匹配方式直接进行处理,因此需要通过自然语言挖掘技术对其字段属性进行信息解析和提取。
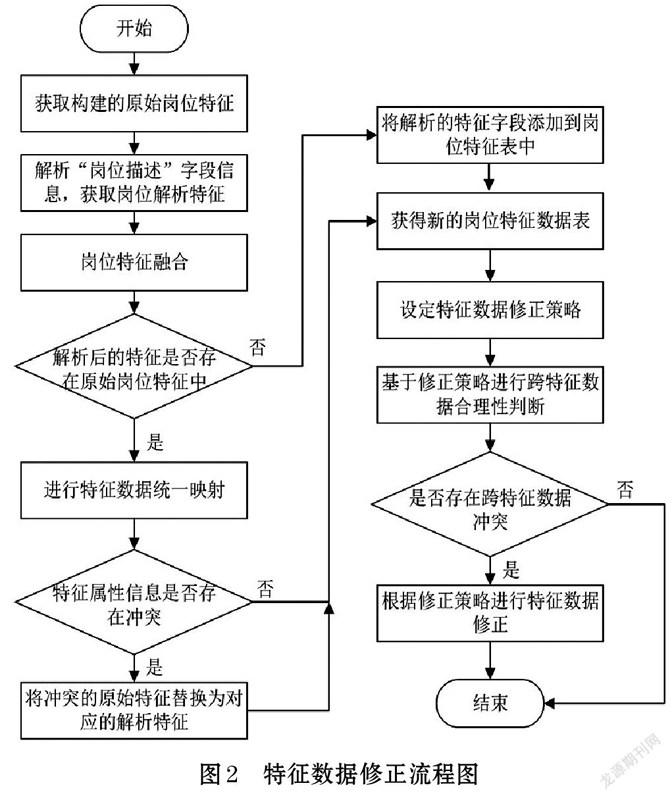
本文中基于岗位特征表的“岗位描述”字段信息,解析得到的特征主要包括:“年龄”、“学历”、“性别”、“政治面貌”、“工作年限”、“院校类型”,由于招聘单位结合实际要求描述的“岗位描述”会与招聘系统默认生成的特征信息会存在一定程度的偏差,因此,解析特征与原始岗位特征表中已有的“年龄要求”、“工作年限要求”、“性别要求”等特征数据存在一定程度的冲突。同时,跨特征属性信息也存在不合理的要求,如学历要求为“硕士研究生及以上”且年龄要求为“不超过25周岁”,这在实际中大多情况下是不合理的。因此,需将“岗位描述”解析后的特征与原始特征数据进行融合和修正,得到新的岗位特征表,具体操作有以下步骤:①获取上述2.1构建的原始岗位特征信息。②解析“岗位描述”特征字段的长文本信息,获取岗位解析特征(“年龄”、“学历”、“性别”、“政治面貌”、“工作年限”、“院校类型”)。③将解析后的特征与原始岗位特征进行融合,首先依次判断解析后的特征是否存在于原始岗位特征中,若不存在,则直接将解析特征添加到岗位特征表中;若存在,则将解析特征与原始特征进行统一数据映射,在此基础上判断特征属性信息是否存在冲突,如不存在冲突,则对此特征信息不做更改。若存在冲突则将解析特征替换掉原始特征;④基于步骤③获得新的岗位特征数据集,在此基础上对特征重要性进行排序,设定岗位特征数据修正策略。⑤基于修正策略进行跨特征联合交叉分析的合理性判断,若不合理,则根据特征修正策略对数据中存在的异常属性信息进行逆向反推对特征数据进行缩放和修正,否则不做修正。⑥完成特征数据的修正,获得最终岗位特征数据表。具体操作流程如图2所示。
2.3 数据处理及表示
基于2.1和2.2构造的特征表和特征数据修正结果,对人岗匹配度测算指标体系中的二级指标性别匹配度、政治面貌匹配度、城市匹配度、学历匹配度等结构化数据进行处理与表示,具体方法为:①建立结构化文本数值映射表,如男性为1,女性为0;②通过构建的文本数值映射表将所有结构化数据表示为数值型数据;③基于数据表示结果进行人岗特征属性匹配获得各指标匹配值。
人岗匹配度测算指标体系中的二级指标年龄匹配度、工作年限匹配度、项目经验匹配度、行业匹配度、职类匹配度、工作经验等由特征表中非结构化数据解析匹配得到,如“年龄不超过35周岁”、“具有3~5年的工作经验”,由于此类数据无法直接用关键字匹配方式进行处理,因此需要通过自然语言挖掘技术对其字段属性进行数据处理与表示,具体方法为:①首先,采用关键词匹配算法进行关键信息定位;②其次,从定位点分别向左右两侧进行窗口滑动提取文本信息作为待分析内容;③对待分析内容进行解析,采用临界值判断法则建立临界值映射策略对指标数据进行多区间覆盖划分,设定上下界阈值,将其映射为对应的区间数据,如“具有3~5年工作经验”映射为[3,5],“年龄不超过35周岁”映射为(0,35];④参照步骤③完成长文本特征数据表示。
2.4 指标体系特征匹配度计算
基于上述人岗匹配度测算指标体系和特征数据处理与表示方法,采用临界值修正匹配法、余弦相似度、编辑距离相似度计算联合计算公式完成上述指标匹配度测算,获得用于模型训练测试的特征数据集。
3 人岗匹配测算模型的构建及应用
3.1 构建特征数据集
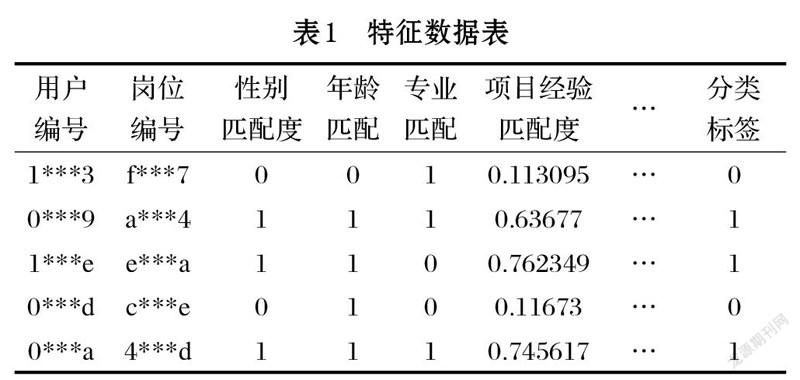
基于人岗匹配度测算指标体系,使用或参考章节2中的特征数据修正及数据表示的计算方法进行人岗匹配度特征数据集的构建,其中分类标签来源于人岗评定的人岗匹配结果数据,1表示匹配,0表示不匹配,得到的部分特征数据如表1所示。
3.2 模型构建
XGBoost的算法思想是通过不断进行特征分裂生成一棵树,用于拟合上一轮预测的残差。当完成模型的训练之后会得到一系列的树并根据样本特征分布组合,最后将每棵树计算得到的分数累加即为样本的预测值。
为验证本文构建的人岗匹配度测算指标体系和提出的特征数据修正和数据表示技术及特征数据构建的有效性,本文在Python3.6环境下,以特征数据集中分类标签作为训练样本中的标签,采用交叉验证和XGBoost算法构造训练人岗匹配度分类模型,将模型输出的概率值作为人岗匹配度测算值,最终实现人岗匹配度的测算。基于XGBoost的人岗匹配度测算模型拥有学习的能力,可以有效地克服传统人岗匹配度测算对主观评价或专家判断等主观因素的依赖。735EF330-3615-4D53-B292-BA567E9EE863
3.3 模型应用
将特征数据集输入XGBoost人岗匹配度分类模型并完成模型的训练和优化,将模型输出的概率值作为人岗匹配度的测算结果,实现人岗匹配度的测算。表2为本文提出的人岗匹配度测算方法在部分真实数据上的测算结果。
表2中人岗匹配度为XGBoost人岗匹配度分类模型计算出的概率值,范围为[0,1],计算的概率值越接近于0表示人岗匹配度越低,反之,计算的概率值越接近于1表示人岗匹配度越高。以0.5为分类阈值,匹配度大于等于0.5标签分类结果为1,小于0.5标签分类结果为0,通过将人岗匹配度换算为标签分类结果可知:上述实验结果中的标签分类结果与特征数据中的标签基本一致,从而验证了本文构造的指标体系及数据表示和特征数据修正技术方法在人岗匹配度测算中的有效性。
4 结论
针对传统人岗匹配测算方法中存在的问题,文本对人岗匹配度测算指标及测算方法进行探讨,构建了人岗匹配度测算指标体系,提出了一种基于数据表示和特征数据修正的人岗匹配度测算方法,该方法一定程度上减少了传统人岗匹配方法中指標对主观评价或专家判断等人为主观因素的依赖,提升了人岗匹配度的测算准确性和智能化程度,具有较强的普适性。
参考文献(References):
[1] 李晓宁,王素伟,王成刚.员工职业胜任力与企业需求匹配度研究[J].中小企业管理与科技,2020(9):120-121
[2] 袁珍珍,卢少华.BP神经网络在人岗匹配度测算中的应用[J].武汉理工大学学报(信息与管理工程版),2010,32(3):515-518
[3] 易斌,姜飞.支持向量机在人岗匹配度测算中的应用[J].中南林业科技大学学报(社会科学版),2011,5(6):92-94
[4] 李娟,高百宁.基于灰色系统理论的人力资源岗位匹配度研究[J].中国商界(下半月),2008(3):103-104
[5] 李松,袁安琪.考虑直觉模糊的多指标人岗双边匹配决策方法[J].计算机工程与应用:1-8[2021-05-13].http://kns.cnki.net/kcms/detail/11.2127.TP.20210420.1121.040.html.
[6] PAZZANI M J, BILLSUS D. Content-based recommen-dation systems[J].The Adaptive Web,2007: 325-341
[7] GOPALAN P K, CHARLIN L, BLEI D. Content-basedrecommendations with poisson factorization[J].Advances in Neural Information Processing Systems,2014,27:3176-3184735EF330-3615-4D53-B292-BA567E9EE863
