基于ARIMA 模型的北京市GDP 分析及预测研究
2022-04-08刘癑婷LIUYueting
刘癑婷 LIU Yue-ting
(北京信息科技大学经济管理学院,北京 100192)
0 引言
国内生产总值能够综合反映出一个地区或者国家在经济发展方面的实际情况。GDP 可以反映出经济增长状况、生活水平、区域发展速度等,所以GDP 对于未来政策制定和发展方向确立有着至关重要的作用。因此,众多学者运用多种数学方法来预测国家或地区GDP。在GDP 预测方面,国内学者展开了丰富研究,预测方法主要包括时间序列分析法[1]、人工神经网络法[2]、灰色预测法[3]。研究表明,国内生产总值呈现非平稳趋势规律,符合时间序列分析的预测条件。
北京市在经济、文化、社会生活等发展进程中发挥了举足轻重的作用。北京市拥有着众多企业、高等院校、科研院所,中关村科技园是中国第一个国家级高新技术产业开发区,经过不断地壮大发展,中关村科技园成为科技创新高地。北京市以科技创新发挥辐射带动作用,助力区域经济发展。因此,选择研究北京市GDP 未来发展趋势,这将有利于协助相关部门做出经济决策,进一步助力北京市高质量发展。
1 文献综述
ARIMA 模型主要应用在GDP 和人口数量预测方面。在GDP 预测研究方面,王佳佳[4]选用1978-2019年安徽省GDP 数据,建立ARIMA(2,1,3)模型。王芳芳[5]选用2000-2018年陕西省GDP 数据,建立了ARIMA(5,2,1)模型。在人口数量预测方面,赵子铭[6]利用中国1949-2017年人口数据,研究发现ARIMA(1,2,1)模型较能完整合理的对中国人口总数进行预测。郭敏等[7]构建了ARIMA(0,1,2)模型预测了未来三年人口出生率。孙鑫鑫等[8]通过对1949-2017年全国人口出生率的原始数据进行分析,建立了ARIMA(1,2,2)模型。
通过查阅文献,学者对陕西省、山东省等地研究较多,但是还未有学者对北京市GDP 进行预测分析。因此,选取北京市1997-2019年的GDP 数据作为研究对象,以此来预测北京市2020-2025年GDP。之所以以1997年作为开始数据,主要因为1997年是北京市GDP 首次超过2 千亿元,从此以后北京市GDP 不断加速增长,更具参考价值。
2 建立ARIMA 模型步骤
2.1 模型原理
ARIMA 模型全称为差分自回归移动平均模型,由博克思和詹金斯提出。ARIMA 模型所预测随时间发展的数据是一个随机序列,可以通过数学模型来预测和描述此随机序列,利用时间序列的已发生数据结合模型去预测出未来数据,可认为是自回归(AR)模型与滑动平均(MA)模型的差分组合,一般适用于非平稳时间序列建立的模型。ARIMA 模型包括AR、MA 和自回归移动平均模型(ARMA)几种特殊情况[8]。
ARIMA(p,d,q)模型数学表达式为:

其中:p-自回归次数;q-滑动平均次数;d-差分次数(阶数),指原始序列转化为平稳序列的差分次数;L-滞后算子。不平稳的时间序列数据在有限次差分运算后可将变为平稳序列,通过差分后重新得到的时间序列,称之为齐次非平稳时间序列,差分一次,即称为一阶齐次非平稳时间序列,以此类推。
2.2 建模步骤
①平稳性检验。利用Eviews 软件进行ADF 单位根检验判断序列是否平稳。若统计量值均小于各水平段的临界值且概率值小于0.05,则序列是平稳的,反之不平稳。利用Eviews 软件可以更加直接和客观的反映出序列是否平稳。
②模型选择。首先通过差分次数确定d;其次通过自相关函数(ACF)和偏向关函数(PACF)或BIC 准则,综合确定p,q。ARIMA 模型要求序列为平稳序列,可通过ACF 和PACF 图来判断p 和q。如果ACF 图在q 阶处截尾,并且PACF 图呈现拖尾,ARIMA 模型可简化为MA(q);如果PACF 图在p 阶处截尾,同时ACF 图拖尾,ARIMA 模型可简化为AR(p);如果ACF 图和PACF 图都明显呈现拖尾状态,可考虑ACF 图中最显著的阶数设为q 值,PACF 中最显著的阶数设为p 值;如果ACF 图和PACF 图都呈现截尾状态,说明序列为白噪声序列,不能使用ARIMA 模型。
③残差检验。为了验证模型的预测精度,需要对残差进行检验。利用SPSS 软件绘制残差自相关图与偏相关图,确定残差序列是否为白噪声序列。
通过以上三个步骤,可以对北京市GDP 数据进行验证和建模预测。
3 实例分析
3.1 数据来源
首先选取北京市1997-2019年地区生产总值数据为研究对象,所有数据均来源于《中国统计年鉴》,具体见表1。

表1 北京市生产总值数据 单位:亿元
3.2 平稳性检测
利用Eviews 软件对北京市1997-2019年地区生产总值进行平稳性检验。首先,利用SPSS 软件绘制北京市GDP 时序图(见图1)。
腰椎间盘突出症属于常见老年疾病,合并基础疾病较多,治疗难度较大[5]。该病治疗方式较多,但临床中不同治疗方案下疗效各不相同,在术后疼痛与功能障碍方面也有显著差异。本研究旨在探讨经皮椎间孔镜治疗腰椎间盘突出症患者的临床效果。
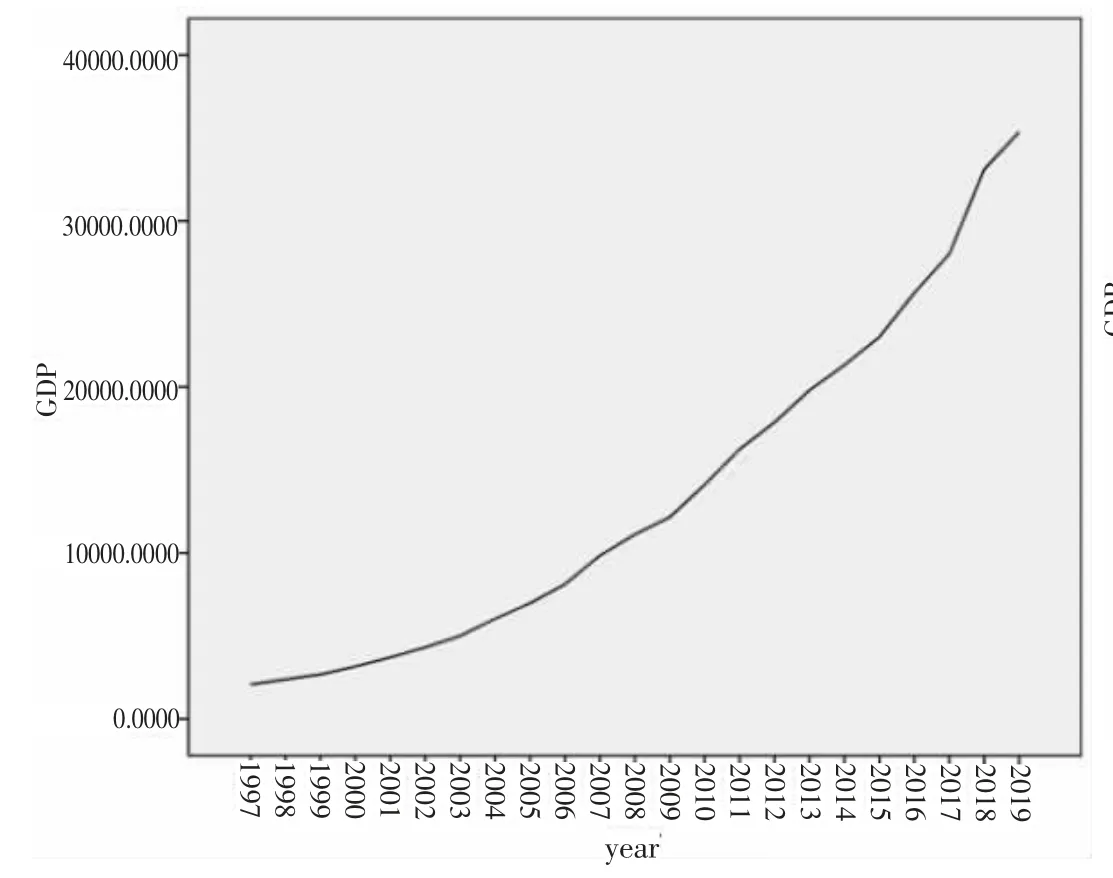
图1 北京市1997-2019年地区生产总值时序图
由图1 可以看出,北京市地区生产总值总体呈上升趋势,并且速度较快,是典型的非平稳序列,说明北京市1997-2019年地区生产总值为非平稳时间序列。
其次,应用对数法使序列平稳化使其可以进一步分析。应用对数法绘制出的时序图,见图2。

图2 北京市1997-2019年地区生产总值自然对数的时序图
运用Eviews 软件对取对数之后的北京市GDP 序列进行单位根检验,见表2。

表2 原序列取对数后ADF 检验表
ADF 检验结果如表2 所示,单位根统计量ADF=-0.142491,大于显著性水平(1%-10%)对应的ADF 临界值,P=0.9902>0.01,不拒绝原假设,序列为非平稳序列。因此对原始数据在取对数的基础上进行一阶差分,检验其是否平稳。
由图3 可以看出,该序列始终在0 点左右随机波动,并且波动范围有界,因此,能够确定原始数据取对数再进行一阶差分之后的序列平稳。为了保证客观,利用Eviews软件对其进行单位根检验,判断其是否平稳。

图3 北京市1997-2019年地区生产总值自然对数一阶差分时序图
ADF 检验结果如表3 所示,单位根统计量ADF=-5.489635,小于显著性水平(1%-10%)对应的ADF 临界值,P=0.0003<0.01,说明拒绝原假设,序列为平稳序列。因此,应该建立ARIMA 模型,且差分的阶数d=1。

表3 原序列取对数后一阶差分ADF 检验表
3.3 偏(自)相关性检验及差分运算
利用Eviews 进行偏(自)相关性检验,见表4。

表4 Eviews 自相关检验和偏自相关检验表
3.4 ARIMA 模型拟合及预测
由表5 看出,R 方为0.994,p=0.009<0.01,拟合程度良好。

表5 模型统计量
对2019年往后五年进行预测,见表6。

表6 预测值
通过表5 中预测值可以看出,2020年至2025年北京市GDP 一直不断稳定上升。
4 结束语
大部分GDP 原始数据都是不平稳的,因此需要将数据平稳化后,才能对其构建ARIMA 模型。
本文对北京市GDP 指数进行未来五年的预测,通过对北京市1997-2019年GDP 数据时序图进行分析发现,该时间序列并不平稳,而平稳性是建模的基础。
因此,运用ADF 检验,发现在原始序列取对数的基础上再进行一阶差分后的时间序列数据是平稳的,可以构建ARIMA 模型。
然后,对平稳的时间序列模型进行p,q 阶数的确定,利用时间序列分析方法,建立ARIMA(0,1,0)模型,并对2020-2025年的北京市GDP 值进行预测,预测结果发现北京市GDP 不断提升。
未来,还需对此研究进行进一步改进。本文没有考虑宏观和微观外部环境对经济发展的影响。比如2020年突如其来的新冠肺炎疫情,打破了全世界的经营秩序,生产经营活动按下了暂停键,多各地经济发展产生严重冲击。但是通过该模型预测2020年北京市GDP 仍是比较大幅度提升,与实际情况比较偏离。
基于ARIMA 模型的GDP 分析与预测,仅从历史GDP数据建立模型,没有考虑外界其他因素的影响,会造成预测结果不准确,后续可以进一步研究,不断提高预测精度,为国民经济发展提供指南。
