模态自适应的红外与可见光图像融合
2022-04-08曲海成王宇萍高健康赵思琪
曲海成,王宇萍,高健康,赵思琪
模态自适应的红外与可见光图像融合
曲海成,王宇萍,高健康,赵思琪
(辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)
为解决低照度和烟雾等恶劣环境条件下融合图像目标对比度低、噪声较大的问题,提出一种模态自适应的红外与可见光图像融合方法(mode adaptive fusion, MAFusion)。首先,在生成器中将红外图像与可见光图像输入自适应加权模块,通过双流交互学习二者差异,得到两种模态对图像融合任务的不同贡献比重;然后,根据各模态特征的当前特性自主获得各模态特征的相应权重,进行加权融合得到融合特征;最后,为了提高模型的学习效率,补充融合图像的多尺度特征,在图像融合过程中加入残差块与跳跃残差组合模块,提升网络性能。在TNO和KAIST数据集上进行融合质量测评,结果表明:主观评价上,提出的方法视觉效果良好;客观评价上,信息熵、互信息和基于噪声的评价性能指标均优于对比方法。
图像融合;模态自适应;对抗生成网络;残差网络
0 引言
图像融合属于信息融合的一部分,其目的是针对同一场景,将来自不同传感器的图像联合起来,生成一幅信息丰富的融合图像,以便于后续处理。CT、磁共振成像、可见光图像与红外图像属于不同成像类型的源图像,在这些源图像组合中,本文重点研究红外与可见光图像融合,原因如下:第一,红外图像通过捕获物体热辐射信息成像,可见光图像通过捕获反射光成像,二者成像原理不同,因此可以从不同的角度提供互补信息。第二,红外图像和可见光图像几乎可以呈现所有物体的固有特性。可见光图像分辨率高,色彩和纹理信息丰富,但容易受到恶劣天气的影响;红外图像中热辐射信息丰富,目标突出,不受天气影响,但分辨率低,细节不清晰,利用二者的优势进行图像融合可以得到一幅信息丰富的图像。此外,这些图像可以通过相对简单的设备获得。因此,红外与可见光图像融合技术可以比其它融合方案应用范围更广,例如可以应用到目标识别[1]、目标检测[2]、图像增强[3]、监控[4]和遥感[5]等领域。
图像融合包括像素级融合、特征级融合和决策级融合方法。像素级融合方法只对图像信息作特征提取并直接使用,代表性的方法包括变换域的各向异性扩散融合(anisotropic diffusion fusion, ADF)[6]、交叉双边滤波(cross bilateral filter, CBF)[7]和最小加权二乘法(weighted least square, WLS)[8]和稀疏域的自适应稀疏表示(adaptive sparse representation, ASR)[9]、拉普拉斯金字塔(laplacian pyramid, LP)[10]等方法。在变换域方法中,比较热门的是基于多尺度变换[11]的方法,但其忽略了融合过程中的空间一致性,容易在融合图像中引入光晕。稀疏域的方法[12]需要构建一个过完备字典,需要多次迭代,非常耗时。近年来,针对特征级图像融合,国内外学者提出了许多基于深度学习的融合方法。2017年,Prabhakar等人[13]提出了基于卷积神经网络的图像融合方法,该方法适用于多曝光图像融合,网络结构简单,仅使用编码网络中最后一层计算的结果,会造成中间层有用特征信息丢失的问题。2018年,Ma等人[14]提出了一种以生成对抗网络为模型的图像融合方法(FusionGAN),该方法通过生成器与判别器对抗性训练产生融合图像,无需预训练,是端到端的无监督学习模型,但其生成器与判别器网络结构相对简单,可以进行优化改进。2018年,Li等人[15]提出了一种基于深度网络的红外与可见光图像融合方法,该方法使用VGG网络为特征提取工具,在计算时参数较多,耗费大量计算资源。2019年,Li等人[16]提出了以密集连接网络为模型的图像融合方法(Dense Fuse),训练时只考虑编码层与解码层,不考虑融合层,测试时需要根据不同情况来设计融合规则。2020年,董安勇[17]等人改进了以卷积神经网络为模型的图像融合方法,有效地解决了低频子带融合模式给定的问题,同时又克服了手动设置参数的缺陷。2020年,Xu等人[18]提出了一种端到端的统一无监督学习(U2Fusion)图像融合方法,可以解决多模态、多聚焦和多曝光图像融合问题,但这种方法训练起来非常复杂,且占用大量内存资源。
上述方法主要针对清晰明亮的图像进行融合。可见光图像在照明条件良好的情况下纹理清晰,红外图像在光照较差和存在烟雾的条件下也能较好地凸显出目标,二者在不同条件下各有所长,考虑到图像融合应该适应环境改变为源图像分配权重,从而更加合理地利用多模态信息,于是,本文提出一种模态自适应的红外与可见光图像融合方法(MAFusion)。主要工作如下:①采用双路特征提取网络针对性的提取成像特点不同的两类图像特征,以减少特征丢失;②建立自适应加权模块,通过双流交互学习红外与可见光图像差异,得到当前环境条件下两种模态在融合图像中所占的权重;③在图像融合过程中加入残差块与跳跃残差组合模块,补充融合图像的多尺度特征,提升网络性能;④在TNO和KAIST数据集上将MAFusion与其他方法进行对比实验,实验结果证明本文方法效果较好。
1 相关理论与分析
1.1 对抗生成网络模型
生成对抗网络是由Goodfellow等人[19]提出的,由生成器(generative,G)和判别器(discriminative,D)组成。生成器用来生成需要的图片,判别器类似图像分类器,判断图片是由生成器生成的融合图像还是真实的可见光图像。训练后得到一个比较智能的自动生成器和一个判断能力较强的分类器。GAN模型的优化函数公式(1)所示:
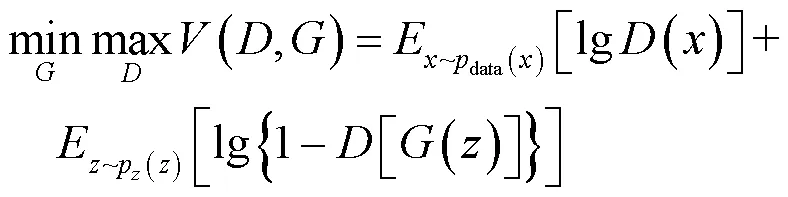
式中:(*)表示分布函数的期望值;表示输入的真实值;表示输入生成器的噪声大小;data()表示真实样本的分布;p()是定义在低维的噪声分布;希望()越大越好,[()]越小越好,函数的目的是将最大损失最小化,即可得到损失函数的最优解。
1.2 残差网络模型
为解决模型增加网络深度后网络性能变差的问题,何凯明等人[20]创新性地提出了深度残差网络ResNet。残差网络的主要思想是将输入层通过跳跃连接与卷积层后的输出相加,有效地解决了梯度消失问题。残差块的结构如图1所示,其中()为残差学习函数,该函数的学习相对容易,有助于提取深层特征信息,激活函数为Relu。
1.3 问题分析
在深度学习图像融合方法中,大多数方法采用相同的编解码网络进行特征提取,由于红外与可见光图像来自不同的信号,采用相同的编解码网络会造成突出特征提取不当的问题,因此,本方法将采用双流特征提取网络更具针对性地提取两类图像的特征。
传统的模态堆叠策略在训练过程中对两类源图像在通道维按1:1的权重直接Concat级联,没有考虑两类图像在不同环境条件的优缺点,容易引入冗余特征,降低融合图像质量,因此需要一种融合策略能够自适应环境改变提取红外与可见光两个模态的重要特征,因此设计自适应加权模块为两个模态分配合理的权重。
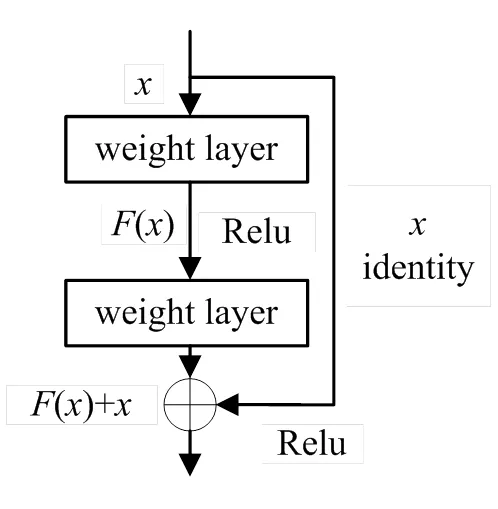
图1 残差块结构图
为了提高模型性能,使网络训练更加容易,同时解决反向传播时的梯度消失问题,本文方法引入了残差块,将Conv1的输出直接连接到Conv3后。利用残差块的恒等映射和跨层连接使前向传播与反向传播更加容易,同时有助于补充多尺度特征。在生成器网络中构建跳跃残差块,这种大幅度跨层连接方式使前后层特征联系更加密切,可以获取更多有利特征信息。
2 模态自适应的红外与可见光图像融合方法
本方法主体网络为GAN,包括生成器与判别器。生成器是整个模型的主要网络,影响最终融合图像的质量,主要用来生成可以骗过判别器的融合图像。判别器的作用不被生成器生成的图像骗过,经过训练达到很强的区分可见光图像与生成器生成的融合图像的能力。生成器与判别器均参与训练过程,测试时则直接利用训练好的生成器模型生成融合图像。
训练过程如下:
1)将红外与可见光图像随机采样级联输入生成器,得到初步融合图像(标记为假数据),记为();
2)将可见光图像作为真实数据,随机采样记为;
3)将前两步中某一步产生的数据(标记为假数据的融合图像和标记为真实数据的可见光图像)输入判别器,判别网络的输出值为该输入属于真实数据(可见光图像)的概率,真为1,假为0。
4)然后根据得到的概率值计算损失函数;
5)根据判别模型和生成模型的损失函数,利用反向传播算法,更新模型的参数。先更新判别模型的参数,然后通过再采样得到的红外与可见光图像更新生成器的参数。
2.1 网络框架
生成器包含了双路输入与特征提取模块、自适应加权模块、残差块、跳跃残差块、特征重构模块和输出模块6个部分,其网络结构图如图2所示。
生成器首先对红外图像和可见光图像进行特征提取,然后通过Concat操作将二者特征图级联为256通道特征图,再输入权值学习融合网络,完成权值分配。然后,重新分配权值的融合特征输入一个普通卷积Conv1后,进入残差块与跳跃残差模块,以实现提取深层特征的同时保留浅层特征;最后,通过输出模块进行特征重构得到融合图像。其具体网络结构参数见表1。
表中字母及缩写定义如下:VIS代表可见光图像,IR代表红外图像,ir_weight为红外图像权重,vis_weight为可见光图像权重,表示卷积核大小,表示移动步长,1表示输入通道数,2表示输出通道数。
判别器希望训练出来的模型具有很强的判别输入图像是融合图像或可见光图像的能力,它以可见光图像为真实参考值,希望不被生成器生成的融合图像骗过,输出的判别值在(0, 1)之间,该值越趋近于1表明判别能力越强,即越趋向于真实参考值(可见光图像)。其网络结构如图3所示。
判别器由4个卷积层、一个特征线性转换模块和一个线性层组成,卷积层以3×3大小的卷积核进行特征提取,填充方式均为VALID,激活函数为LeakyReLU,卷积层2、3和4使用BatchNorm来提高模型收敛速度。判别器的网络结构及参数信息见表2。
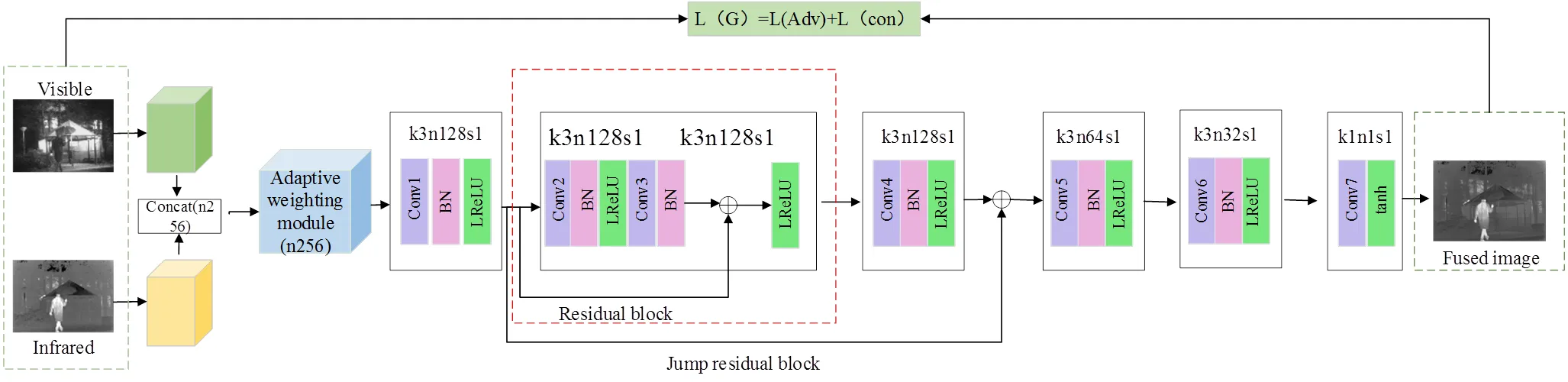
图2 生成器网络结构图
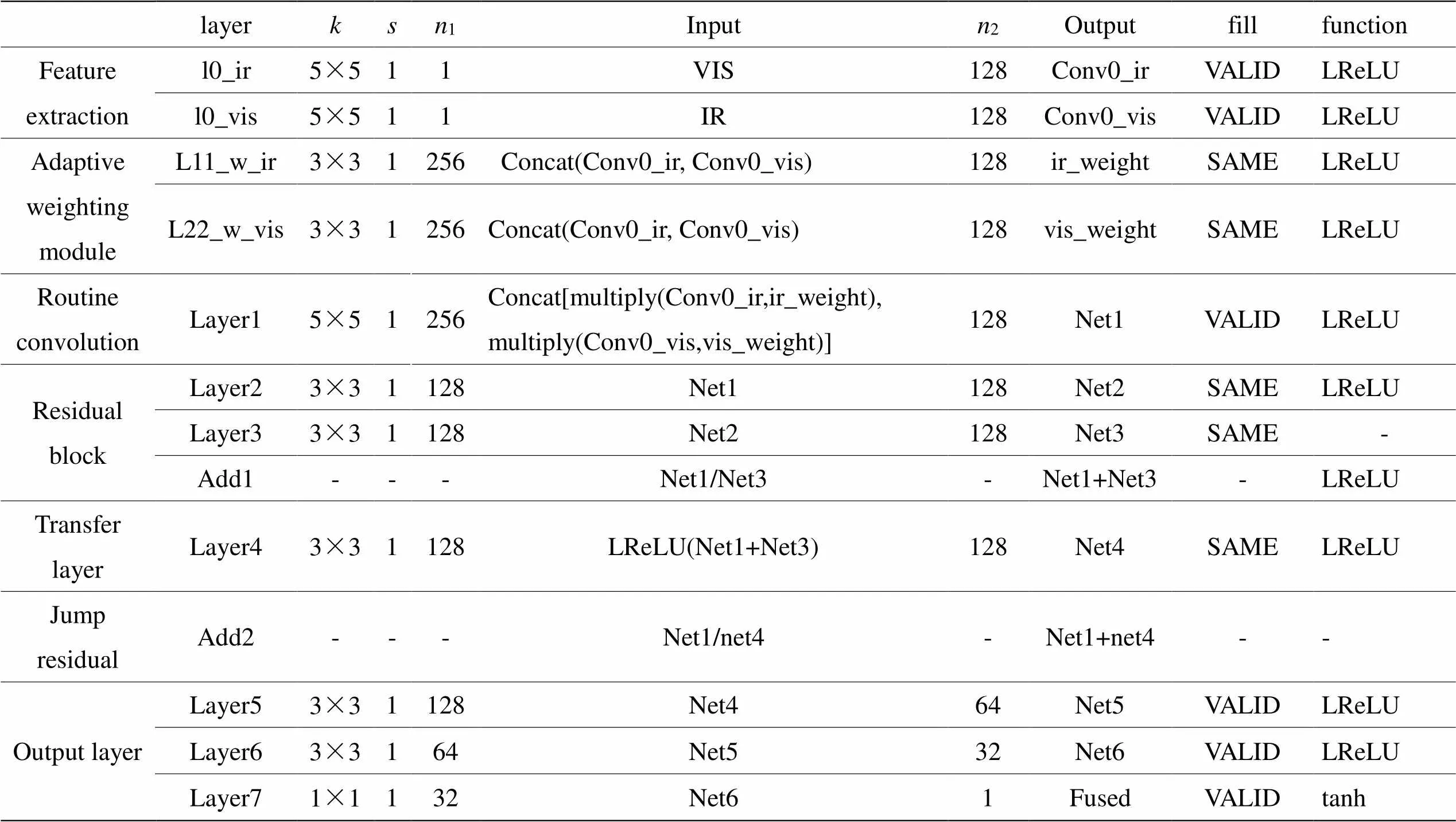
表1 生成器网络整体结构
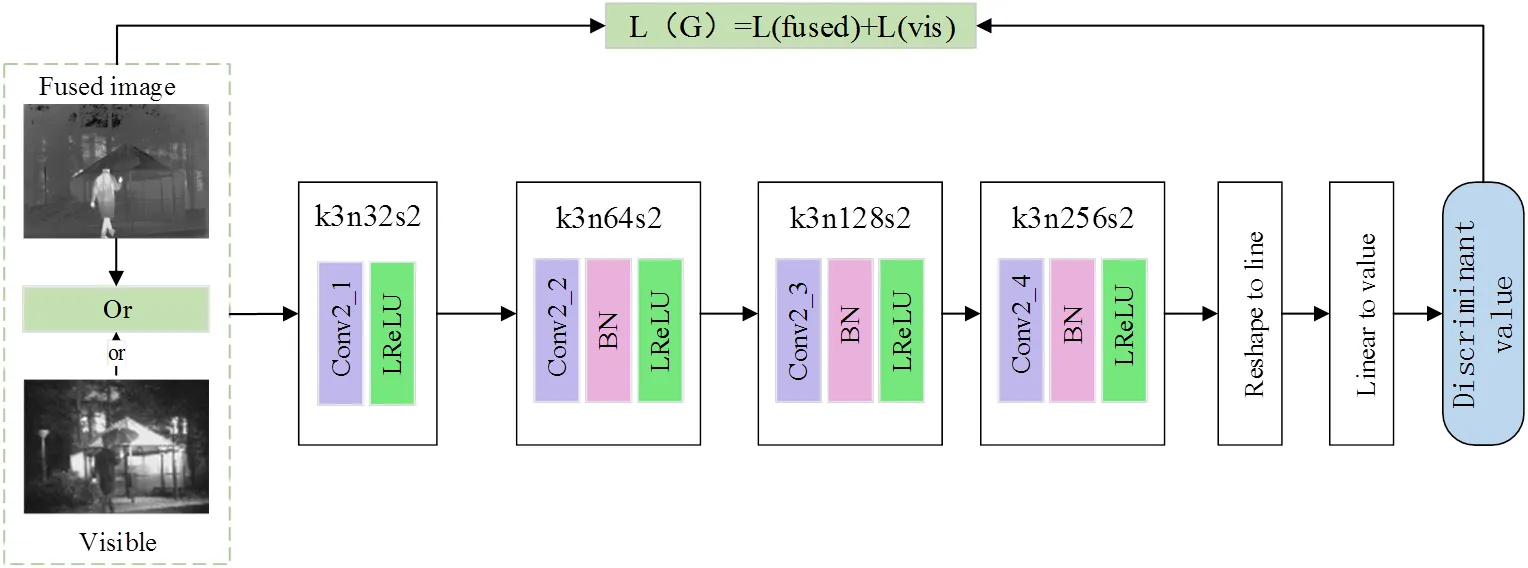
图3 判别器网络结构图
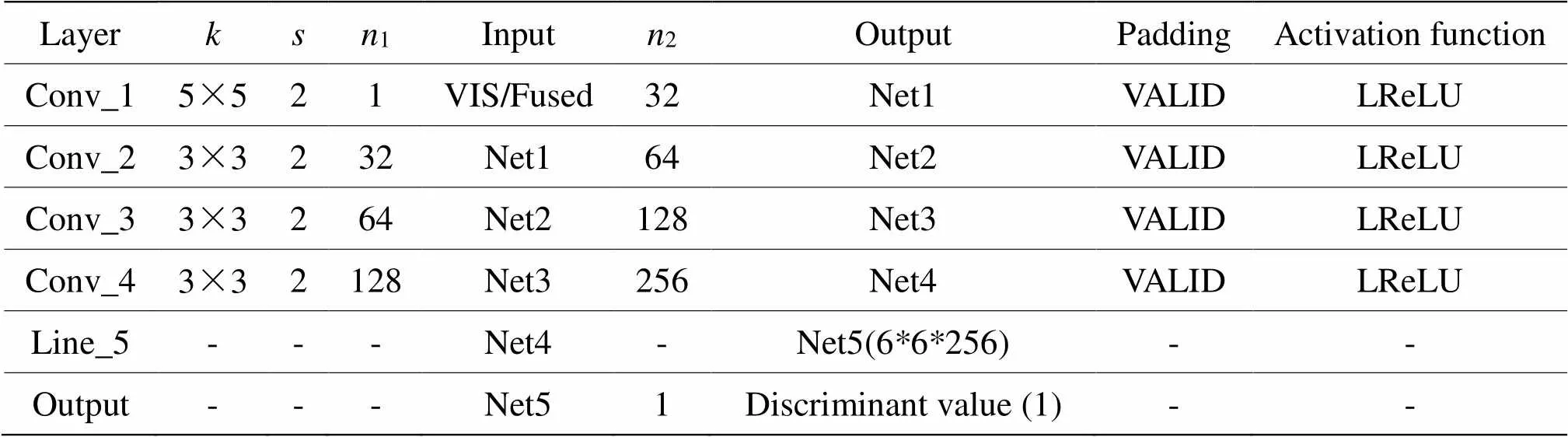
表2 判别器网络整体结构
表中字母缩写定义如下:VIS代表可见光图像,Fused代表融合图像,表示卷积核大小,表示移动步长,1表示输入通道数,2表示输出通道数。
2.2 自适应加权模块
为了在融合图像中充分利用红外图像目标区域的热辐射信息,保留可见光图像有利的纹理信息,抑制噪声等干扰信息引入融合图像,提出自适应加权模块来根据环境变化为两个模态分配合理的权重值,将源图像在当前环境条件下的优势充分体现出来。在生成器中,将该模块嵌入红外图像与可见光图像输入之后,最终得到一个包含两模态重要特征的融合特征图。其网络结构图如图4所示。
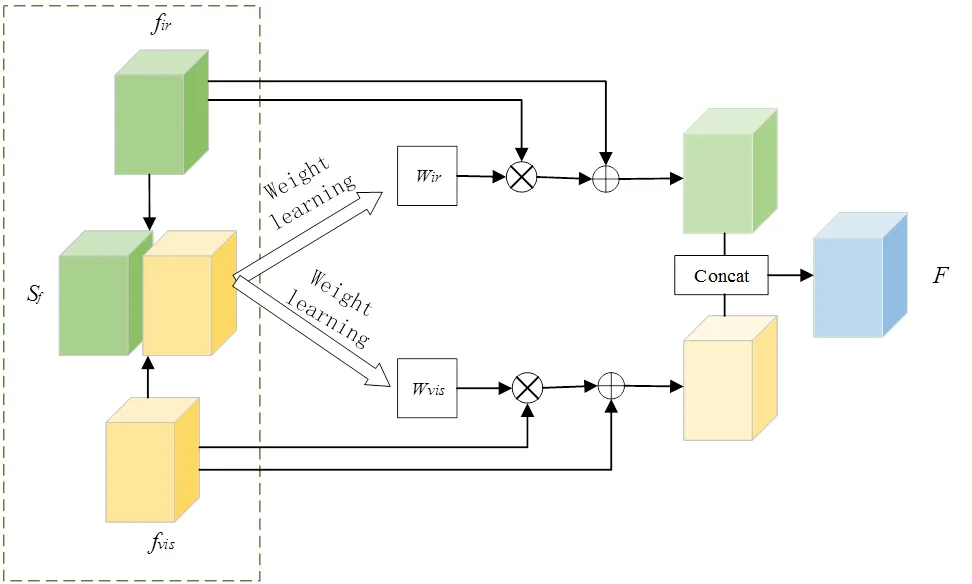
图4 自适应加权模块结构图
该模块以前一阶段得到的红外与可见光各自特征图Concat作为输入,首先通过一个3×3卷积分离两类特征,然后通过sigmoid函数计算当前环境下的红外图像与可见光图像所占的比例,红外权重矩阵ir和可见光权重矩阵vis的计算公式如式(2)所示:

式中:1和2表示卷积权重;1和2为卷积偏置;ir和vis通过自主学习得来。最后将获得的权重与原始特征图像在通道维相乘,再与源图像相加以避免特征丢失,从而得到两个模态的优势特征,干扰信息被很好地抑制。
2.3 残差块与跳跃残差块
为解决由于网络过深导致反向传播时梯度消失的问题,本文方法引入了残差块,学习到的残差信息有助于补充多尺度特征。同时,为了增加特征图前后层的关联性,降低网络训练复杂性,在残差块的输入与其后卷积层的输出通过跳跃连接相连,构建了一个跳跃残差模块。残差块与跳跃残差块的结构图如图5所示。
2.4 损失函数与优化方法
MAFusion的损失函数包括两部分:生成器损失和判别器损失。生成器损失计算融合图像与源图像之间的差别;判别器损失以可见光图像作为标签,训练辨别可见光图像与融合图像的能力。
1)生成器损失函数
生成器损失G包含对抗损失Adv及内容损失con,其定义如式(3)所示:
G=Adv+con(3)
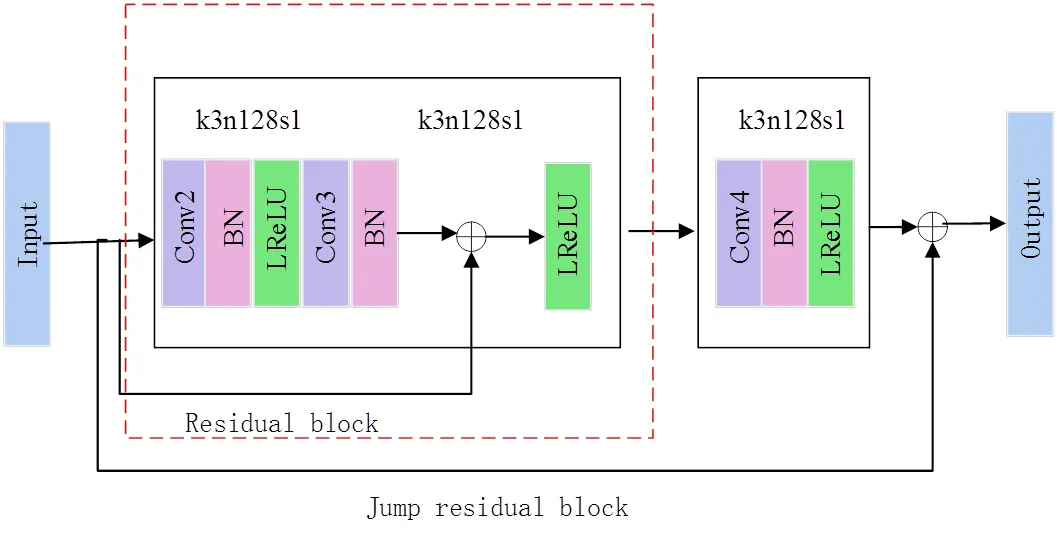
图5 残差块及跳跃连接组合模块
内容损失con是生成器的主要损失函数,约束了融合图像与源图像间的相关性及重点提取红外图像与可见光图像的有利信息。内容损失越小,融合图像中源图像的特征越多,其定义如式(4)所示:
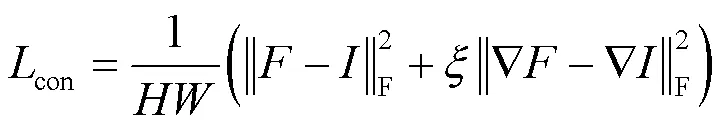
对抗损失Adv是生成器与判别器交互的损失函数,其定义如式(5)所示:
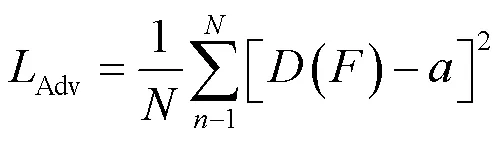
式中:()为判别器对融合图像的判别结果,在(0,1)之间;为软标签(取值不确定的标签)。判别器希望融合图像向可见光图像靠近,其值越大越好,又要保证损失最小,根据文献[14]将软标签的取值范围设置为(0.7, 1.2)。
2)判别器损失函数
判别器损失D的目的是约束判别器网络反向传播参数更新,使判别器在训练后具有分辨可见光图像和融合图像的能力,其定义如式(6)所示:
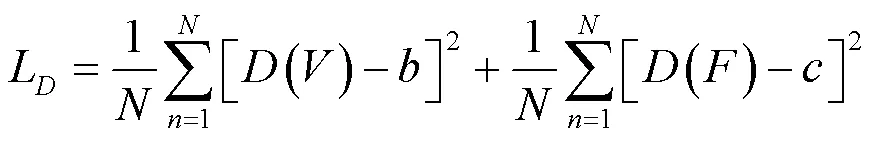
式中:()表示判别器对可见光图像的判别结果;()表示判别器对融合图像的判别结果,、为软标签(取值不确定的标签),根据文献[14]将的范围设置为(0.7, 1.2),将的范围设置为(0, 0.3)。
3 实验及结果分析
实验在Windows10操作系统和NVIDIA GTX 1080Ti GPU上完成,框架为TensorFlow 1.12.0,训练与测试平台为PyCharm。本文方法的训练集是在TNO[21]数据集中选择了39对不同场景的红外和可见光图像,以步长15将39对图像分成30236对120×120的红外图像与可见光图像,最后的融合图像为生成器输出图像的拼接。判别器训练次数设置为2,学习率设为0.00001,将batch_size设置为32,训练迭代次数设置为20次。本节采用TNO数据集的18对白天图像和KAIST[22]数据集的14对夜间图像评估MAFusion的性能。选择ADF[6]、CBF[7]、WLS[8]、FusionGAN[14]、Densefuse[16]和U2Fusion[18]6种方法与MAFusion作对比实验,对融合图像进行主观评价和客观评价。对比实验图片由MATLAB及PyCharm程序生成,客观评价指标计算通过MATLAB软件编程实现。
3.1 主观评价
MAFusion与对比方法在KAIST数据集中夜晚路灯下的“道路与行人”实验结果如图6所示。
从图6的实验结果可以看出:图6(c)中,道路右边的车轮廓模糊,整幅图像清晰度较低;图6(d)中,整体噪声大,路灯中心有明显的黑块;图6(e)中,道路右边的人边缘不清晰,整体纹理细节信息少;图6(f)中,人和车的轮廓模糊;图6(g)中,整体背景偏暗,视觉效果较好;图6(h)中,图像整体较为平滑,路灯周围有光晕;图6(i)中,整体背景较亮且清晰,目标突出,抑制路灯周围的光晕,能清楚地识别楼层、路灯、行人和车辆等目标。

图6 KAIST数据集中“道路与行人”融合结果
MAFusion与对比方法在TNO数据集中的“烟雾中的士兵”实验结果如图7所示。

图7 TNO数据集中“烟雾中的士兵”融合结果
从图7的实验结果可以看出:图7(c)、(h)中,能看到士兵与树木,但轮廓较模糊;图7(d)中,图像整体上被烟雾笼罩,无法识别士兵,图像整体噪声较大,且有不连续的黑块;图7(e)中,士兵轮廓不清晰,烟雾的干扰信息较多,图像不平滑;图7(f)中,人与汽车的轮廓都比较模糊,图像较平滑,仍有烟雾的干扰信息;图7(g)中,图像较清晰,但没有抑制烟雾的干扰,士兵轮廓不清晰;图7(i)中,士兵与树木轮廓清晰可见,抑制了烟雾的干扰,重点目标突出,图像整体平滑,有利信息得到了良好地体现。
MAFusion与对比方法在TNO数据集中的“士兵与车辆”实验结果如图8所示。

图8 TNO数据集中“士兵与车辆”融合结果
从图8的实验结果可以看出:图8(c)中,背景较暗,图像整体不够平滑;图8(d)中,整体呈现颗粒状,有不连续的黑块,视觉效果差,整体噪声较大;图8(e),图像整体较模糊,窗户与左侧暗处的树木轮廓不清晰;图8(f)中,人的轮廓信息不清楚,部分可见光图像细节信息丢失;图8(g)中,整体偏暗,人、车、树木、房屋均较清晰,但天空中的云轮廓较模糊;图8(h)中,图像较平滑,但房屋的窗户、车窗与左侧树木的轮廓不清晰;图8(i)中,整体较清晰,图像平滑,可以清晰看到房屋窗户的轮廓,车辆、房屋、士兵、地面、路灯和树木都清晰可见,细节信息丰富,热辐射信息也得到了较好的体现。
3.2 客观评价
为了进一步评价融合图像的融合效果,使用客观评价方法进行评估。选择信息熵EN、互信息MI和基于噪声评估的融合性能abf为测评指标,从图像信息丰富度、信息互补性和噪声等不同角度对融合图像进行评价。以下为测评指标的计算公式。
1)信息熵[23]EN。其值大小能够体现融合图像中平均信息量的多少,其定义如式(7)所示:
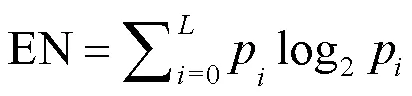
信息熵越大越好,表明图像所含信息越丰富。
2)互信息[24]MI。该指标表示融合图像包含源图像的信息量大小,其值越大越好,计算方法如式(8)所示:
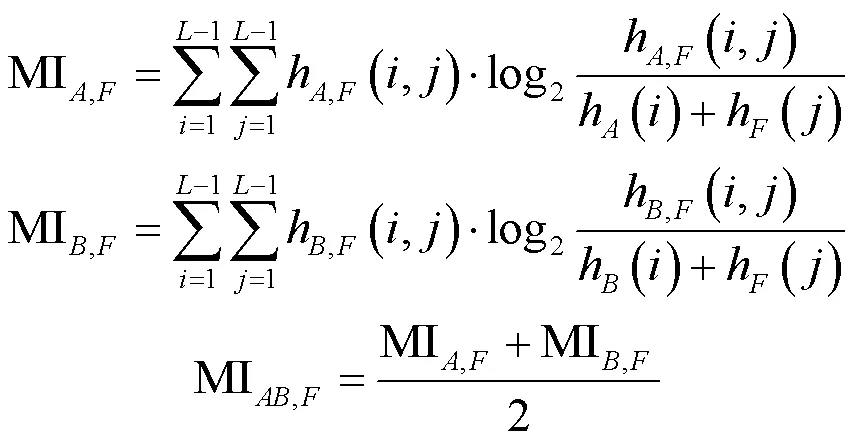
式中:、为源图像;为融合图像。
3)基于噪声评价的融合性能[25]abf。该指标反映了图像中包含的不必要或冗余的干扰信息的多少,其值越小,图像噪声越少。
首先,在照明条件差且行人较小的KAIST数据集上选取14对红外与可见光图像对进行实验,图片“道路与行人”的融合效果如图6所示,CBF方法得到的融合图像视觉效果差,所以直接由其他5种方法与MAFusion分别生成的融合图像进行测评,“道路与行人”的测评结果见表4。EN和MI指标的值越大越好,abf的值越小越好。
由表4可见,MAFusion在“道路与行人”的融合图像在EN和MI两个方面都是最优的,abf值也接近于最优值。KAIST数据集中图像偏暗,MAFusion中模态自适应权值学习功能很好地感知了光照条件,为两个模态分配合适的权值,在目标区域保留红外图像的热辐射信息,背景区域保留可见光图像的纹理信息,使融合图像测评指标值进一步优化。
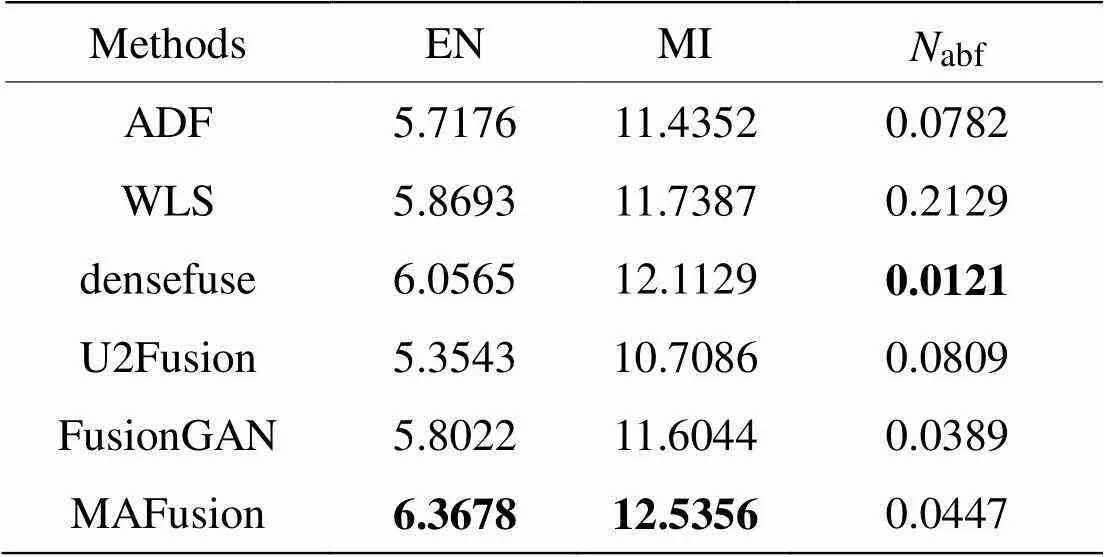
表4 KAIST数据集“道路与行人”融合图像客观评价
Note:Bold font is the best value
以KAIST数据集中14对红外与可见光图像为源图像,MAFusion与6种对比方法的测评结果见表5。表中数值均为每种方法生成的14张融合图像在EN、MI和abf指标上测评结果的平均值,EN和MI指标的值越大越好,abf的值越小越好。
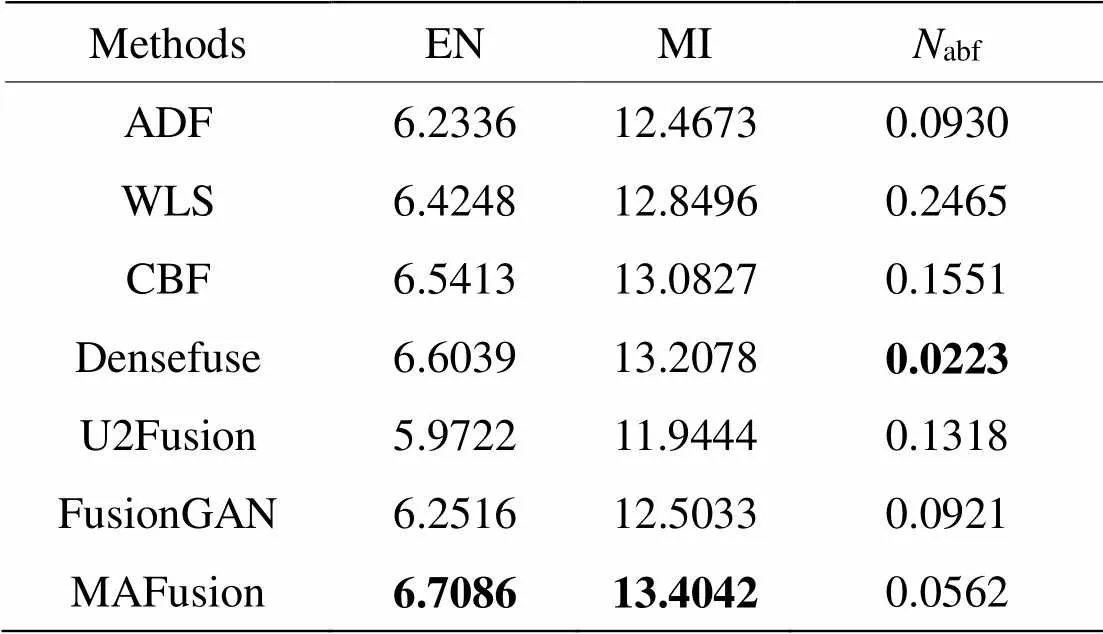
表5 KAIST数据集14组融合图像客观评价指标均值
Note:Bold font is the best value
由表5可见,MAFusion在KAIST数据集上的融合图像在EN和MI两个方面都是最优的,abf也与对比方法最优值相近,算法性能良好。
然后,在TNO数据集上选取18对红外与可见光图像进行实验,由MAFusion与6种对比方法分别生成融合图像进行测评,图片“烟雾中的士兵”的融合结果如图7所示,其中CBF与WLS方法得到的融合图像视觉效果差,DenseFuse与U2Fusion有大量烟雾干扰信息,无法识别图中目标,所以直接由ADF、FusionGAN与MAFusion这3种方法分别生成的融合图像进行测评,“烟雾中的士兵”的测评结果见表6。EN和MI指标的值越大越好,abf的值越小越好。
由表6可见,MAFusion在“烟雾中的士兵”的融合图像在EN和MI两个指标中取得最大值,相比其他方法有明显地提高,说明得到的融合图像信息更丰富,源图像转移到融合图像的信息量较大。abf值最低,说明融合图像与对比方法相比噪声最小,抑制干扰信息引入融合图像。
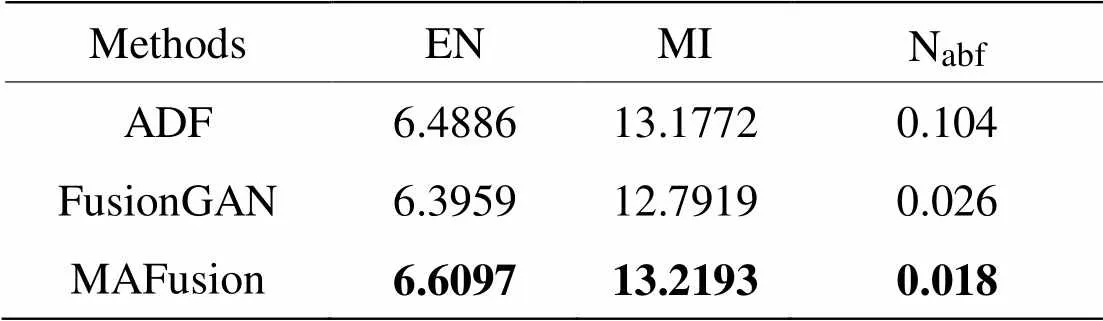
表6 TNO数据集“烟雾中的士兵”融合图像客观评价
Note:Bold font is the best value
TNO数据集中图片“士兵与车辆”的融合结果如图8所示,其中由CBF方法生成的融合图像含有大量不连续的黑块,图像视觉效果差,所以直接由其他5种方法与MAFusion分别生成的融合图像进行测评,“士兵与车辆”的测评结果见表7。EN和MI指标的值越大越好,abf的值越小越好。
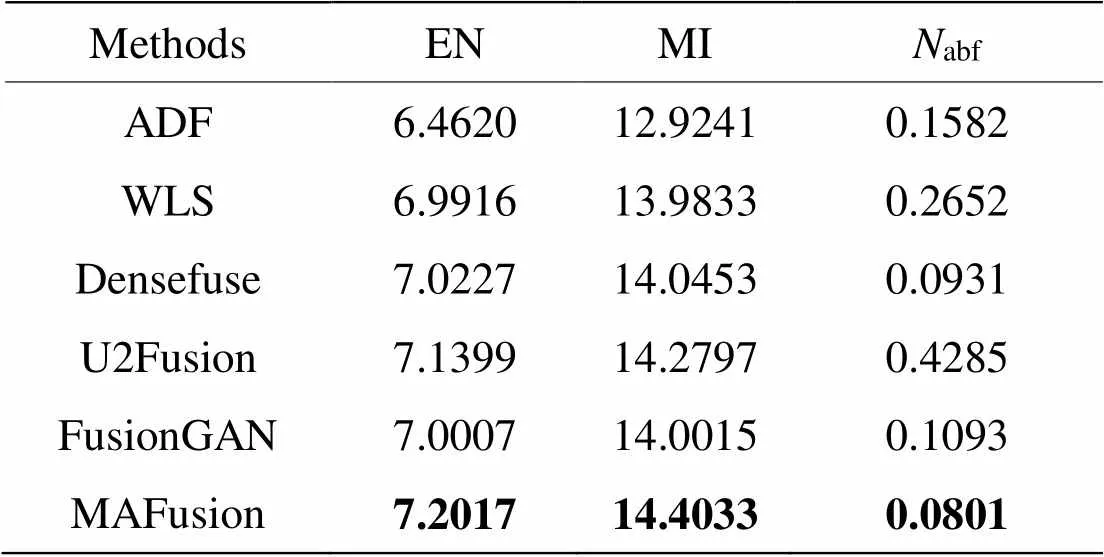
表7 TNO数据集“士兵与车辆”融合图像客观评价
Note:Bold font is the best value
由表7可见,MAFusion在“士兵与车辆”的融合图像在EN和MI两个指标中取得最大值,abf取得最小值,相比其他方法的性能有明显提高,说明MAFusion得到的融合图像信息更丰富,噪声较小,融合质量较好。
以TNO数据集中的18对红外与可见光图像为源图像,由MAFusion与6种对比方法分别生成融合图像进行测评,测评结果见表8。表中数值均为每种方法生成的18张融合图像在EN、MI和abf指标上测评结果的平均值,EN和MI指标的值越大越好,abf的值越小越好。
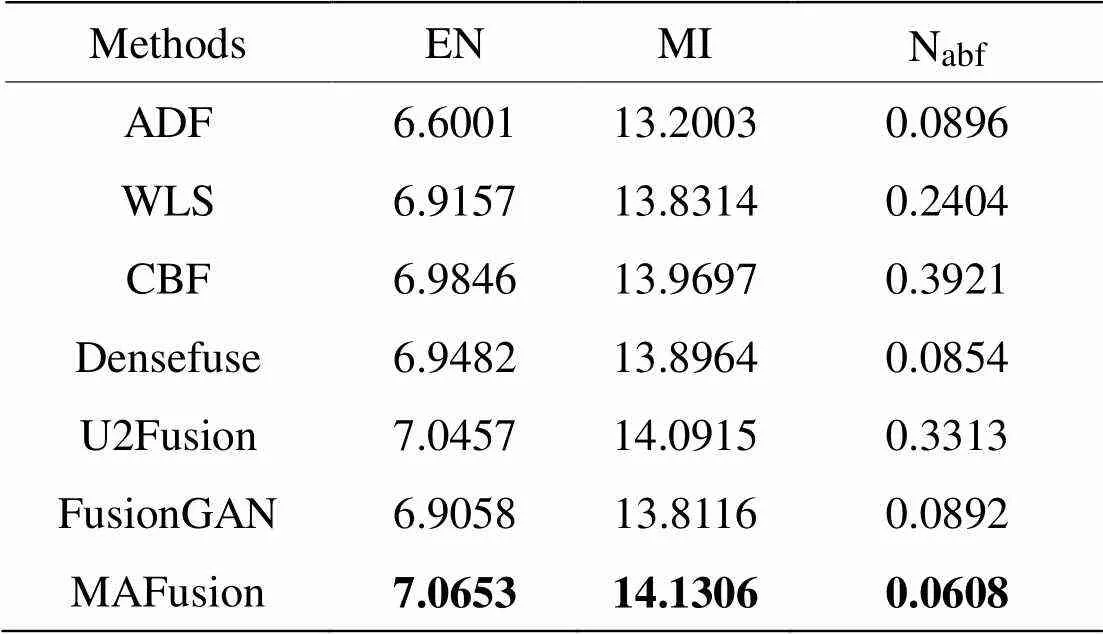
表8 TNO数据集18组融合图像客观评价指标均值
Note:Bold font is the best value
由表8可以看出,MAFusion在EN和MI两个指标中取得最大值,较对比方法有提高,说明得到的融合图像有利信息更多,源图像转移到融合图像的信息量较大,噪声较小。
为验证MAFusion中双路特征提取与自适应加权模块、残差块及跳跃残差块的作用,使用KAIST数据集中的14对典型红外与可见光图像做消融实验,采用客观评价对所有方法生成的融合图像进行测评,测评结果见表9。表中数值均为每种方法生成的14张融合图像在EN、MI和abf指标上测评结果的平均值,EN和MI指标的值越大越好,abf的值越小越好。
在表9中,方法①为FusionGAN方法,其采用直接堆叠策略将红外与可见光图像Concat后输入特征提取网络,特征提取阶段也使用普通卷积完成;方法②在FusionGAN的基础上,在特征提取阶段采用残差块与跳跃残差块,得到的图像经测评后3个指标值均优于方法①,体现了残差块和跳跃残差块恒等映射的优势,加强浅层特征与深层特征的联系,获得的融合图像能较好地兼顾不同种类源图像信息。方法③在方法②的基础上,将红外与可见光图像送入双路特征提取网络并进行权值自适应学习,得到的图像测评后的指标值均优于方法②。方法③即MAFusion生成的融合图像如图6、图7和图8所示,图像中的信息更丰富,视觉效果良好。

表9 KAIST数据集消融实验客观评价
Note:Bold font is the best value
4 结论
针对恶劣环境条件下红外与可见光图像融合效果较差且容易引入噪声的问题,本文提出了一种模态自适应的红外与可见光图像融合方法。该方法使用双路特征提取及权值学习融合网络,自适应提取两个模态的重要信息,并分配权重,强化对重要信息的学习。同时,在生成器特征提取阶段加入残差块与跳跃残差块,使得深层网络特征提取能力增强,反向传播也更加容易,增强模型学习能力。实验结果表明,提出的方法在图像的视觉观察、目标清晰度、图像信息丰富性和抑制噪声等方面具有良好的性能。
[1] 段辉军, 王志刚, 王彦. 基于改进YOLO网络的双通道显著性目标识别算法[J]. 激光与红外, 2020, 50(11): 1370-1378.
DUAN H J, WANG Z, WANG Y.Two-channel saliency object recognition algorithm based on improved YOLO network[J]., 2020, 50(11): 1370-1378.
[2] 李舒涵, 宏科, 武治宇. 基于红外与可见光图像融合的交通标志检测[J]. 现代电子技术, 2020, 43(3): 45-49.
LI S H, XU H K, WU Z Y. Traffic sign detection based on infrared and visible image fusion[J]., 2020, 43(3): 45-49.
[3] Reinhard E, Adhikhmin M, Gooch B, et al. Color transfer between images[J]., 2001, 21(5): 34-41.
[4] Kumar P, Mittal A, Kumar P. Fusion of thermal infrared and visible spectrum video for robust surveillance[C]//, 2006: 528-539.
[5] 常新亚, 丁一帆, 郭梦瑶. 应用整体结构信息分层匹配的红外与可见光遥感图像融合方法[J]. 航天器工程, 2020, 29(1): 100-104.
CHANG X Y, DING Y F, GUO M Y. Infrared and visible image fusion method using hierarchical matching of overall structural information[J]., 2020, 29(1): 100-104.
[6] Bavirisetti D P, Dhuli R. Fusion of infrared and visible sensor images based on anisotropic diffusion and karhunen-loeve transform[J]., 2016, 16(1): 203-209.
[7] Kumar B S. Image fusion based on pixel significance using cross bilateral filter[J]., 2015, 9(5): 1193-1204.
[8] MA J, ZHOU Z, WANG B. Infrared and visible image fusion based on visual saliency map and weighted least square optimization[J]., 2017, 82: 8-17.
[9] LIU Y, WANG Z. Simultaneous image fusion and denoising with adaptive sparse representation[J]., 2014, 9(5): 347-357.
[10] Burt P, Adelson E. The Laplacian pyramid as a compact image code[J]., 1983, 31(4): 532-540.
[11] 马雪亮, 柳慧超. 基于多尺度分析的红外与可见光图像融合研究[J]. 电子测试, 2020, 24(4): 57-58.
MA Xueliang, LIU Huichao. Research on infrared and visible image fusion based on multiscale analysis[J]., 2020, 24(4): 57-58.
[12] LI S, YIN H, FANG L. Group-sparse representation with dictionary learning for medical image denoising and fusion[J]., 2012, 59(12): 3450-3459.
[13] Prabhakar K R, Srikar V S, Babu R V. DeepFuse: A deep unsupervised approach for exposure fusion with extreme exposure image[C]//the 2017, 2017: 4724-4732.
[14] MA J Y, YU W, LIANG P W, et al. FusionGAN: A generative adversarial network for infrared and visible image fusion[J]., 2019, 48: 11-26.
[15] LI H, WU X J, Kittler J. Infrared and visible image fusion using a deep learning framework[C]//The 24(ICPR), 2018: 2705-2710.
[16] LI H, WU X. DenseFuse: A fusion approach to infrared and visible images[J]., 2019, 28(5): 2614-2623.
[17] 董安勇, 杜庆治, 苏斌, 等. 基于卷积神经网络的红外与可见光图像融合[J]. 红外技术, 2020, 42(7): 660-669.
DONG Anyong, DU Qingzhi, SU Bin, et al. Infrared and visible image fusion based on convolutional neural network[J].2020, 42(7): 660-669.
[18] XU Han, MA Jiayi, JIANG Junjun, et al. U2Fusion: A unified unsupervised image fusion network[J]., 2020, 44: 502-518.
[19] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//27, 2014: 2672-2680.
[20] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//(CVPR), 2016:770-778.
[21] Figshare. TNO Image Fusion Dataset[OL]. [2018-09-15]. https://flgshare. com/articles/TNO Image Fusion Dataset/1008029.
[22] Hwang S, Park J, Kim N, et al. Multispectral pedestrian detection: benchmark dataset and baseline[C]//2015(CVPR), 2015: 1037-1045.
[23] Roberts J W, Aardt J V, Ahmed F. Assessment of image fusion procedures using entropy, image quality, and multispectral classification[J]., 2008, 2(1): 023522-023522-28.
[24] QU G, ZHANG D, YAN P. Information measure for performance of image fusion[J]., 2002, 38(7): 313-315.
[25] Kumar B K S. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform[J]., 2013, 7(6): 1125-1143.
Mode Adaptive Infrared and Visible Image Fusion
QU Haicheng,WANG Yuping,GAO Jiankang,ZHAO Siqi
(School of Software, Liaoning Technical University, Huludao 125105, China)
To solve the problems of low contrast and high noise of fused images in low illumination and smoky environments, a mode-adaptive infrared and visible image fusion method (MAFusion) is proposed. Firstly, the infrared and visible images are input into the adaptive weighting module in the generator, and the difference between them is learned through two streams interactive learning. The different contribution proportion of the two modes to the image fusion task in different environments is obtained. Then, according to the characteristics of each modal feature, the corresponding weights of each modal feature are obtained independently, and the fusion feature is obtained by weighted fusion. Finally, to improve the learning efficiency of the model and supplement the multi-scale features of the fused image, a residual block and jump connection combination module are added to the image fusion process to improve the network performance. The fusion quality was evaluated using the TNO and KAIST datasets. The results show that the visual effect of the proposed method is good in subjective evaluation, and the performance indexes of information entropy, mutual information, and noise-based evaluation are better than those of the comparison method.
image fusion, mode adaptive, GAN, ResNet
辽宁省教育厅一般项目(LJ2019JL010);辽宁工程技术大学学科创新团队资助项目(LNTU20TD-23)。
TP391
A
1001-8891(2022)03-0268-09
2021-07-18 ;
2021-09-23.
曲海成(1981-),男,博士,副教授,主要研究方向:图像与智能信息处理。E-mail:quhaicheng@lntu.edu.cn。
