基于层次聚类的多策略未知协议分类方法*
2022-04-08代先勇邓金祥俞祥基
代先勇,胥 雄,邓金祥,俞祥基,熊 竹,熊 民
(成都深思科技有限公司,四川 成都 610000)
0 引 言
随着近些年互联网的不断发展,网络应用呈现爆发式增长,其中不乏大量使用自定义协议的应用。对于网络监管部门来说,自定义协议的标准非公开,属于未知格式的协议。未知协议无法参考标准协议的识别方法以准确解析其数据结构,使得直接通过网络流量来识别所属应用协议存在较大的阻碍,增加了对网络数据进行合法性审计监测的难度。同时,越来越多的恶意程序使用未知协议进行通信,容易隐藏在正常通信流量中,难以与其他正常的私有协议数据进行区分,给网络监管带来大量分析工作与难点。本文的研究重点在于把基于传输控制协议(Transmission Control Protocol,TCP)传输的未知协议数据流通过分类的方法,对相似的未知协议数据流进行标记,分类到同一集合;在后续进行流量分析时,由于集合中流量具有相似性,只针对同一集合的部分数据进行分析,即可得知当前集合所有数据的情况,减少分析过程数据量,提高分析效率。
1 模型与方法
本文提出的未知协议分类模型,主要基于层次聚类算法,并结合多种策略进行结果数据调整,最终实现数据的分类。
1.1 相关理论和方法
1.1.1 聚类算法分析
聚类是指根据数据间的相似性,将具有相同属性的对象划分到对应数据集合的过程。聚类所生成的不同组称为簇(cluster),一个簇包含一组数据对象的集合,具有簇内对象彼此相似,簇间对象相异的特点。
常见的数据聚类方法可分为以下几类:基于划分的聚类算法,例如K均值聚类算法(K-means Clustering Algorithm,K-means);基于密度的聚类算法,例如基于密度的噪声应用空间聚类算法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN);基于层次的聚类算法,例如基于代表点的聚类算法(Clustering Using REpresentatives,CURE);基于网格的聚类算法,例如基于网格的多分辨率的聚类算法(STatistical INformathon Gird,STING);基于模型的聚类算法,例如基于高斯混合模型的算法(Gaussian Mixture Models,GMM)等。不同的聚类算法适用于不同的应用场景。在实际网络中,未知协议不能预先分析其规则信息,故无法预先提取标签数据进行学习。在基于层次的聚类算法中,通过计算不同类别数据点间的相似度来创建一棵有层次的聚类树。在聚类树中,以不同类别的原始数据点为树的最底层,聚类的根节点为树的顶层,可不直接依赖k值和初始聚类中心点的设置进行聚类,由聚类过程自动调整,最终把相似类别聚集在一起,满足未知协议在真实网络中的分类需求。
1.1.2 相关工作研究
网络协议是指在特定网络环境中进行通信而建立的标准或者规则,包含语义、语法、时序三要素。本文中,按协议是否公开标准格式或者开发文档进行划分,分为已知协议和未知协议两类。协议分类经过多年的发展,也探索出较多不同的识别路线,目前主要有端口匹配技术、深度包检测(Deep Packet Inspection,DPI)/深度流检测(Deep Flow Inspection,DFI)[1]技术、机器学习技术等。汪立东等人[2]提出基于端口的网络流量分类,该方法具有识别速度快的优点,但对没有公开的未知协议就无法完成分类识别,并且现在还存在很多使用动态端口以及端口复用技术的服务,会使此方法出现识别错误的情况;镇佳等人[3]提出基于DPI/DFI的协议分类识别,通过规则库匹配应用层数据的内容,该方法可以对部分存在少量字节特征的未知协议进行分类识别,但其准确性依赖于人工提取协议特征的准确性,对于复杂的未知协议无法直接通过人工找到特征,需要借助协议逆向技术[4]来完成,无疑提高了对复杂协议识别的门槛,同时对计算机的计算能力也有一定的要求,对字节特征不明显或几乎不存在字节特征的加密协议无法进行识别;张凤荔等人[5]提出了零知识下的比特流未知协议分类模型,该方法解决了K-means聚类算法的k值确定问题,对常规协议的分类正确率较高,但无法对加密流量进行分类;Singh[6]提出了基于网络行为的无监督聚类方法,使用基于关联系数的特征选择技术,对比K-means算法和EM算法的聚类效果,实验结果表明K-means的聚类准确度更高;Zhang等人[7]借助少量带标签的数据,使用半监督学习的未知协议分类方法,此方法的三元组关联算法和投票算法都可以提升分类器的准确率,但在真实网络中,三元组关联会受到很大限制,使得带标签数据的扩展效果低于实验室数据的测试结果,识别结果的类别也会受到标签数量的限制,需要标签足够完备才能得到较好的结果;Ma等人[8]借助卷积网络对未知协议进行识别,将网络流负载当作图像数据进行处理,需要在训练阶段使用带标签的数据,筛选测试阶段计算出的结果,将概率低于0.8的流作为未知流,该方法只能识别标签范围内的协议类型和“未知协议”类型,无法对未知协议进行更细粒度的区分。
在以上协议分类识别技术中,均存在各类不足。如对未知协议不适用,需要搜集大量未知协议(加密协议)样本进行训练学习,耗费大量时间和人力,无法自动适应新出现的未知协议分类需求等。故本文提出一种新的未知协议分类模型。
1.2 协议分类模型设计
在本模型中,协议在语义和时序上具有一定统计特征,并对所有类型的协议具有普适性,故分类算法主要提取协议的语义和时序两个维度的统计特征作为数据输入,对已知协议和未知协议(包括加密协议)均适用。同时采用无监督的层次聚类算法进行分类,该算法可不依赖于预先定义的类或带类标记的训练实例,无须预先获取大量的未知协议样本数据,由聚类过程自动确定标记,把相似的对象归到同一个簇中[9],符合未知协议网络流量无先验知识的实际情况。由于使用协议交互统计特征作为原始数据输入,不需要搜集样本进行标记训练,所以也适用于新出现的未知协议。
首先对网络流量进行捕获抓取,经过数据筛选、规范化等处理,在聚类前先根据流字节特征进行可读性分类,针对可读和不可读数据使用不同的分类参数进行差异化区分。同时使用马尔科夫链(Markov Chain)[10]来强化原始数据特征的表征能力,信息熵(Entropy)[11]对层次聚类(Hierarchical Clustering)过程进行优化,并结合距离矩阵的对称性,对层次聚类算法进行改进,降低计算距离矩阵的复杂度,减少聚类过程时间和计算设备内存消耗。最后对分类结果进行调整与合并,提高分类结果准确性和聚集度。功能模块主要包括流量提取、特征预处理、可读性分类和应用层协议分类4个部分,在测试调优的过程中还会引入结果评估模块,如图1所示。
流量提取支持通过网卡实时捕获流量和从磁盘读取离线数据包两种方式,对进入系统的数据包进行流关联,以TCP流为单位进行特征统计和预处理,然后借助预处理后的流量特征进行一次粗颗粒度的可读性分类,得到可读性数据流和不可读数据流两大类,接着对这两类数据流分别进行应用层协议分类。单个聚类策略的分类效果很难达到较高的水平,本方法提出类簇合并算法和类簇调整算法,极大程度地提升本方法的分类效果。应用层协议分类通过层次聚类的多种策略得到多组结果,这些结果经过类簇合并算法合并、类簇调整算法调整后,再借助二元组[7](目的IP和目的端口)合并得到最后的分类结果。
1.2.1 流量采集预处理
对实时流量的采集,为了能适应大流量的真实网络环境,采集预处理中采用数据平面开发套件(Data Plane Development Kit,DPDK)[12]作为流量采集的基础框架。对采集到的流量包通过五元组(源IP、目的IP、源端口、目的端口、传输层协议)进行关联,将包间时间间隔较小且具有相同五元组的数据包视为一个流单元。后续所有的处理,均以一个流单元作为研究的基本单位。
针对捕获到的每一个流单元(以下简称为流),进行协议识别、丢包检测、流重组等操作,过滤能被协议识别的流、流连接初始阶段存在丢包的流和携带载荷的包数量小于pkt_cnt_min(一条流统计的包个数总量最小阈值)或者载荷总字节数小于payload_total_min(一条流统计的载荷字节数总量最小阈值)的流。经过上述过滤后,剩余的流具有更稳定的网络行为和字节特征,也使整个方法能适应真实的网络环境,而不仅限于实验室数据。
每一个TCP流的前面部分都包含了流中的关键信息[8],因此在对流进行特征提取时,更关注TCP流的前面部分流特征。经过过滤后,进行流特征统计[8,10,13],主要包括:
(1)前pkt_cnt_min个带负载包的每个包最多前payload_max(一个数据包统计的载荷数据最大字节数)个字节的字节分布;
(2)前pkt_cnt_max(一条流统计的包个数总量最大阈值)个带负载包的包大小、时间间隔及包大小的状态转换;
(3)单方向带负载包的包大小及时间间隔,统计计算包大小的均值、标准差、最大值和最小值;
(4)双方向带负载包的包大小,统计计算包大小的均值、标准差、最大值和最小值;
(5)单方向的每秒发包量(packet per second,pps)与每秒字节数(bits per second,bps),双向的pps与bps;
(6)TCP各标记位次数、双向初始窗口大小;
(7)上下行流的字节占比和包占比;
(8)单方向的带负载包的包总大小,连接时长。
引入马尔科夫链对特征进行处理。在选取的特征集合中,包大小的状态转换矩阵来自马尔科夫链[10,14]。从TCP流第一个带负载的数据包开始计算,每一个带负载的数据包都具有一个状态Si,即负载大小的变换状态,i与数据包长度L之间的计算方法如式(1)所示:
从如上关系看出,状态集合一共包含10个状态元素。状态转换矩阵P用于记录,TCP流在时间上相邻的前pkt_cnt_max个带负载包,包间状态转换关系计算算法如下:
Input:一条TCP流中,按包到达时间排列的数据包长度状态序列S[0,1,…,n]
Output:状态转换矩阵P,具有10行10列
1 初始化矩阵P的所有项为0,初始化状态计数器cnt[0,1,…,9]=[0,0,…,0]
2 for遍历S中的元素,在相邻两个包的状态中,前置状态记为si,后置状态记为sj:
2.1P[i][j]=P[i][j]+1
2.2cnt[i]=cnt[i]+1
3 for遍历P中的所有元素,行索引记为i,列索引记为j,计算P[i][j]=P[i][j]/cnt[i]
4 输出二维矩阵P
对于同类型的网络协议来说,在通信过程中产生的数据包长度状态转换过程具有相似性,因此,在本方法中采用马尔科夫链的状态转换矩阵作为流特征。
在预处理的最后,对数据进行去除值单一的列、标准化及去除强关联特征等处理,形成可用于聚类算法的特征集合。
1.2.2 可读性分类
在测试过程中发现,对于某些数据而言,在特征预处理阶段和算法聚类阶段,采用不同的参数设定比统一的参数设定的分类效果更好。经深入研究,这些数据差异符合可读性分类标准。
可读性分类是指将TCP流分成可读数据流和不可读数据流两大类。可读数据流是能通过肉眼分析,发现一些协议规律的数据流。不可读数据流是加密程度较高或其他二进制的数据流。
可读性分类以可打印字符占比和字节分布熵作为分类依据。当可打印字符占比大于设定阈值,或字节分布熵小于设定阈值时,则为可读数据流,否则为不可读数据流。其中,字节分布熵是指在特征预处理时字节分布统计的基础上,计算字节分布对应的信息熵。字节分布熵值越大,代表TCP流负载越没有规律。
可读性分类不仅能使分类效果更好,同时能降低聚类过程的数据规模,从而提升分类过程的计算性能。
1.2.3 凝聚型层次聚类
层次聚类不直接依赖于k值的设置进行聚类,这是符合未知协议在真实网络中的情况的。此外,像K-means这类算法的多次运行结果是无法保证一致的,这使聚类结果具有不确定性,从而对聚类结果的后续处理带来一定的阻碍。此方法的层次聚类采用凝聚型层次聚类算法,并采用最近邻链(Nearest Neighbor Chain,NNCHAIN)算法[15]来构建层次树,NN-CHAIN算法的时间复杂度和空间复杂度均优于传统的层次聚类算法。
样本点之间的距离计算采用Bray-Curtis距离,样本i和样本j之间的距离dij通过式(2)进行计算,n表示样本的特征维度总数:
类簇之间的距离计算采用簇平均(Average-Linkage)方法,其中dxz代表类簇ci与cj中两个点的距离值,对于类簇ci与cj,通过式(3)来计算距离:
基于NN-CHAIN算法的凝聚型层次聚类过程描述如下:
Input:所有的特征化的样本点
Output:聚类后的类簇
1 把每个样本归为一类,计算任意两个类之间的距离,形成距离矩阵
2 创建一个栈,栈中的元素为当前活动的类簇
3循环处理,直到最终被合并为一个类簇:
3.1 当栈为空的时候,从当前活动类簇集合中随机挑选一个放入栈中
3.2 查找与栈顶元素距离最近的类簇,记为C
3.3 若C不在栈中,将C入栈
3.4 若C在栈中,则必然是原栈顶元素的前一个元素,需要将原栈顶元素和C一同出栈并合并为类簇D,将类簇D放入活动类簇集合,然后在活动类簇集合中删除合并前的两个元素,最后更新距离矩阵
4根据步骤3生成的层次树,使用适当的聚类策略,生成结果类簇
在整个聚类过程中,步骤1的时间复杂度为O(n2),步骤3的时间复杂度为O(n2logn)。相对于传统的凝聚型层次聚类的时间复杂度O(n3),性能提升明显。在聚类过程中的聚类策略,主要借助不一致系数inconsistent和类簇距离distance两个策略。当不一致系数或类簇距离在设定范围内时,允许在层次树的相应位置进行合并,否则不合并。这两种策略会得到两个相互独立的聚类结果,需要后续进行合并处理。
1.2.4 改进的层次聚类算法
在实际的程序运行过程中,由于数据样本的特征维度数量较大,所以层次聚类算法中的步骤1的实际耗时远大于步骤3。因此这里考虑对步骤1进行性能优化。步骤1的一般实现算法如下:
Input:所有的特征化的样本点为p[n][m],样本数量为n,特征维度数量为m
Output:所有样本点两两间距离矩阵为d[n][m]
1 forifrom 0 ton-1:
2 forjfrom 0 ton-1:
3d[i][j]=dist(p[i],p[j],m)
该算法中的dist函数为Bray-Curtis算法,时间复杂度为O(m),所以计算距离矩阵的时间复杂度为O(n2×m)。由于样本i与样本j的距离等价于样本j与样本i的距离,所以通过上三角矩阵对内存进行压缩,并去掉主对角线,可以减少一半的内存占用与一半的计算量。压缩后的距离矩阵用数组a[n×(n-1)/2]表示。从矩阵d的索引(i为行索引,j为列索引)到数组a的索引k映射关系如式(4)所示:
将上式中i≤j的情况,把j假设为n-1,反解关于i的一元二次方程,得到式(5):
借助式(5),得到从数组a的索引k到矩阵d的索引i和j的映射关系如式(6)和式(7)所示:
分析计算距离矩阵的传统算法得出,计算距离矩阵中的各个元素的过程互不影响,故可将计算过程拆分为多个计算任务进行独立处理。通过压缩矩阵索引的正向和反向映射关系,对原算法进行多线程优化,发挥现代计算机的多核优势。对于压缩后的矩阵,即数组a,按block_size(分块大小)对数据进行分块,每个块就是多线程任务队列中的一个任务,由线程池中的多个线程对任务队列中的计算任务进行处理,如图2所示。
Bray-Curtis算法使用大量的数值计算指令,除循环条件判断外,没有其他分支语句。这样的算法特点可以发挥出单指令流多数据流(Single Instruction Multiple Data,SIMD)系列[16]指令的性能优势,因此,除使用多线程对距离计算进行加速外,还能使用SIMD技术对Bray-Curtis算法加速。
1.2.5 类簇调整算法
对于TCP流量来说,相同的目的IP和目的端口,同属相同的网络服务,因此具有相同的目的IP和目的端口的TCP流,使用相同的应用协议进行通信[10]。基于该结论对类簇进行调整。将所有样本构成的集合表示为A={a1,a2,…,an}。
对于具有相同二元组的(即目的IP和目的端口)TCP流,直接作为一个相同的类别。所有类别的集合表示为T={t1,t2,…,tn}。其中ti为一个独立的类别,表示为ti={b|所有样本b具有相同的二元组},且ti与任意不同于ti的tj满足ti∩tj=∅,ti∈T,tj∈T,i≠j,集合T与集合A应满足∪ti=A,ti∈T。经过聚类得到的类簇集合表示为C={c1,c2,…,cn},其中ci为一个独立的类簇,且ciA,ci∈C。
类簇调整算法(Cluster Adjustment Algorithm,CAA)具体描述如下:
Input:基于二元组的类别集合T,聚类得到类簇集合C,调整阈值h_thre和m_threOutput:调整后的类别集合R
1 forEachtiinT:
2 集合H=ti在集合C所有元素的交集中,元素最多的那个交集(记为ti与ck的交集)
3 forEachcjinC:
4 if |ti∩cj|<|H|×h_thre,则 将ti与cj交集中的元素由集合cj移动到集合ck中
5 else if |ti∩cj|<|ti|×m_thre,则将ti与cj交集中的元素由集合cj移动到集合ck中
6 else 不移动
7 结果类别集合R=处理后的集合C
在此算法中,调整阈值h_thre和m_thre对结果的影响较大,通过调节这两个参数能减少最终分类结果的错误率。
1.2.6 类簇合并算法
聚类过程产生的多策略聚类结果,需要合并在一起,合并后的结果经过CAA处理后,需要再次与二元组进行合并得到本方法的分类结果。类簇合并算法(Cluster Merging Algorithm,CMA)具体描述如下:
Input:类别集合A={a1,a2,…,an},ai代表一个独立的类别,为一个样本集合;类别集合B={b1,b2,…,bn},bj代表一个独立的类别,为一个样本集合
Output:合并后的类别集合D={d1,d2,…,dn},dk代表一个独立的类别,为一个样本集合
1p=0
2 for 遍历集合A中所有元素ai:
3p=p+1
4 将一个空集加入集合D中,记为dp
5 调用子算法fm(ai,A,B,D,p),子算法定义如下:
6 初始化集合G为空集
7 for 遍历集合ai中的所有元素air,且air不在集合D所有元素的并集集合中:
8 元素air加入集合dp中
9 在集合B中查找样本元素air所在的集合bj,并将bj加入集合G
10 for 遍历集合G中的元素gs:
11 递归调用子算法fm(gs,A,B,D,p)
12 输出集合D
2 实验结果分析
对本方法的结果评估主要考虑借助已知协议数据来模拟未知协议的方式。
2.1 评估方法
为了对分类结果进行合理的评估,本方法提出了准确率和聚集度两个评估维度。
2.1.1 准确率
在分类结果中,结果类别没有被标记为特定协议的类别标签,因此无法使用简单的方法直接计算分类结果的准确率。这里定义一个对已知流量实验的准确率计算方法。将某一结果类别中,实际协议类别样本数量最多的协议类别作为结果类别的协议标记。将此结果类别中样本实际协议与此协议标记一致的样本量,与此结果类别样本总量的比值作为此结果类别的准确率。如在分类后的众多结果类别中,其中某个结果类别ci,包含m种不同实际协议的样本,这m种不同实际协议的样本数量分别为w1,w2,…,wm,其中的最大值为wj,wj对应的实际协议为pj,则结果类别ci被看作实际协议pj的类别,即类别ci中实际协议为协议pj的样本被认为分类正确的样本,类别ci的分类准确率计算方法如式(8)所示:
分类结果的整体C={c1,c2,…,cn}的准确率计算方法如式(9)所示:
经分析可知,准确率的取值范围为[0,100%],且越接近100%分类效果越好。
2.1.2 聚集度
仅根据上面定义的准确率来评估分类结果,无法对下面的情况进行合理评估:当实际为同类型协议pj的样本被分到不同的n个结果类别中时,这些结果类别中的实际协议pj的样本量分别为u1,u2,…,un,此时按准确率进行评估,会发现当n=1时与n=10时的分类结果的准确率是相同的,但实际上,n=1时的分类效果优于n=10时的分类效果。因此定义了聚集度来体现这一差异,借助信息熵来定义协议pj的聚集度,计算方法如式(10)所示:
对所有协议P={p1,p2,…,pn},在分类结果中的聚集度计算方法如式(11)所示:
经分析可知,聚集度的取值范围为[0,+∞],且越接近0分类效果越好。
准确率体现的是被分到同一个类别中的样本实际上也是同一个类别的程度,聚集度体现的是实际为同类型协议的样本在结果类别中被聚集在一起的程度。
2.2 结果分析
本文采用的数据,在多种真实的网络环境出口处抓取获得。去掉其中占比极高的超文本传输协议(HyperText Transfer Protocol,HTTP)数据和传输层安全协议(Transport Layer Security,TLS)数据。经过预处理后共计得到97460条TCP流,包含19种不同的应用协议,其中包括比特流协议(BitTorrent,BT)、简单邮件传输协议(Simple Mail Transfer Protocol,SMTP)、简 单 邮 件 传 输加密协议(Simple Mail Transfer Protocol Transport Layer Security,SMTP_TLS)、可扩展通讯和表示协 议(Extensible Messaging and Presence Protocol,XMPP)、Telnet远程终端协议、简单对象访问协议(Simple Object Access Protocol,SOAP)、邮局协议(Post Office Protocol,POP)、安全外壳协议(Secure Shell,SSH)、文件传输协议(File Transfer Protocol,FTP)、交互邮件访问协议(Internet Message Access Protocol,IMAP)、Mysql数据库协议、实时消息传输协议(Real Time Messaging Protocol,RTMP)、微信应用协议、基于HTTP的自适应码率流媒体传输协议(HTTP Live Streaming,HLS)、WebSocket网络传输协议、文件传输协议(File Transfer Protocol Data,FTP-DATA)、SOCKS4代理协议、SOCKS5代理协议、远程显示协议(Remote Display Protocol,RDP)。在这些协议中,SMTP、POP、IMAP、Telnet、XMPP、RTMP等属于非加密协议,BT、SOCKS4/5、微信协议、RDP、FTP-DATA则属于加密协议。不可读数据流具有424个特征维度,可读数据流具有416个特征维度,下面分别对不可读数据流和可读数据流(加密流)进行分析。
测试环境说明:Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz,Cent OS 7.2 x64。
如表1所示,不可读数据流(加密流)的分类准确率为96.78%,聚集度为1.23,说明本模型针对加密流量具有较好的分类效果。其中总计的标签数量并非其他协议标签数量的累加,因为在分类结果中协议之间存在混合在一起的情况。在运行聚类算法、CAA和CMA的过程中,耗时24秒,其中CAA和CMA仅耗时0.5秒。在计算耗时方面,聚类算法远大于其他算法。
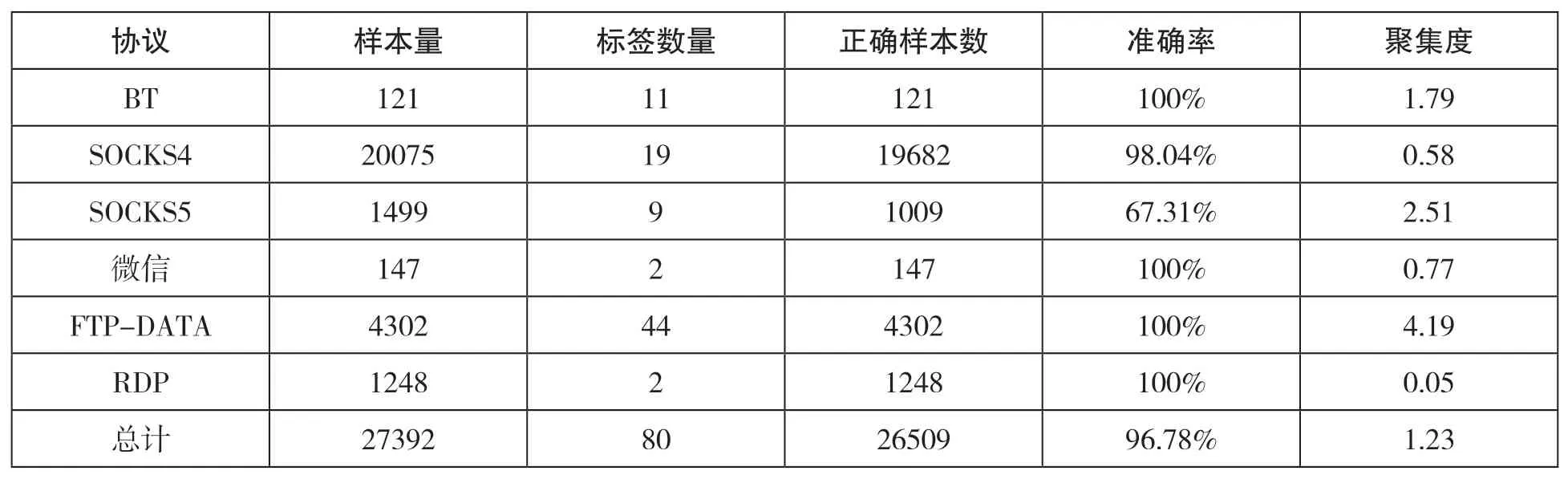
表1 不可读数据流的分类结果
如表2所示,可读数据流的分类准确率为99.81%,聚集度为0.25,说明本方法对明文流量也具有较好的分类效果。在运行聚类算法、CAA和CMA的过程中,耗时151秒。对比不可读数据流和可读数据流分类结果发现,可读数据流的分类结果无论是准确率还是聚集度,都明显优于不可读数据流的分类结果。原因在于,不可读数据流在负载方面的特征对协议的区分度远低于可读数据流。
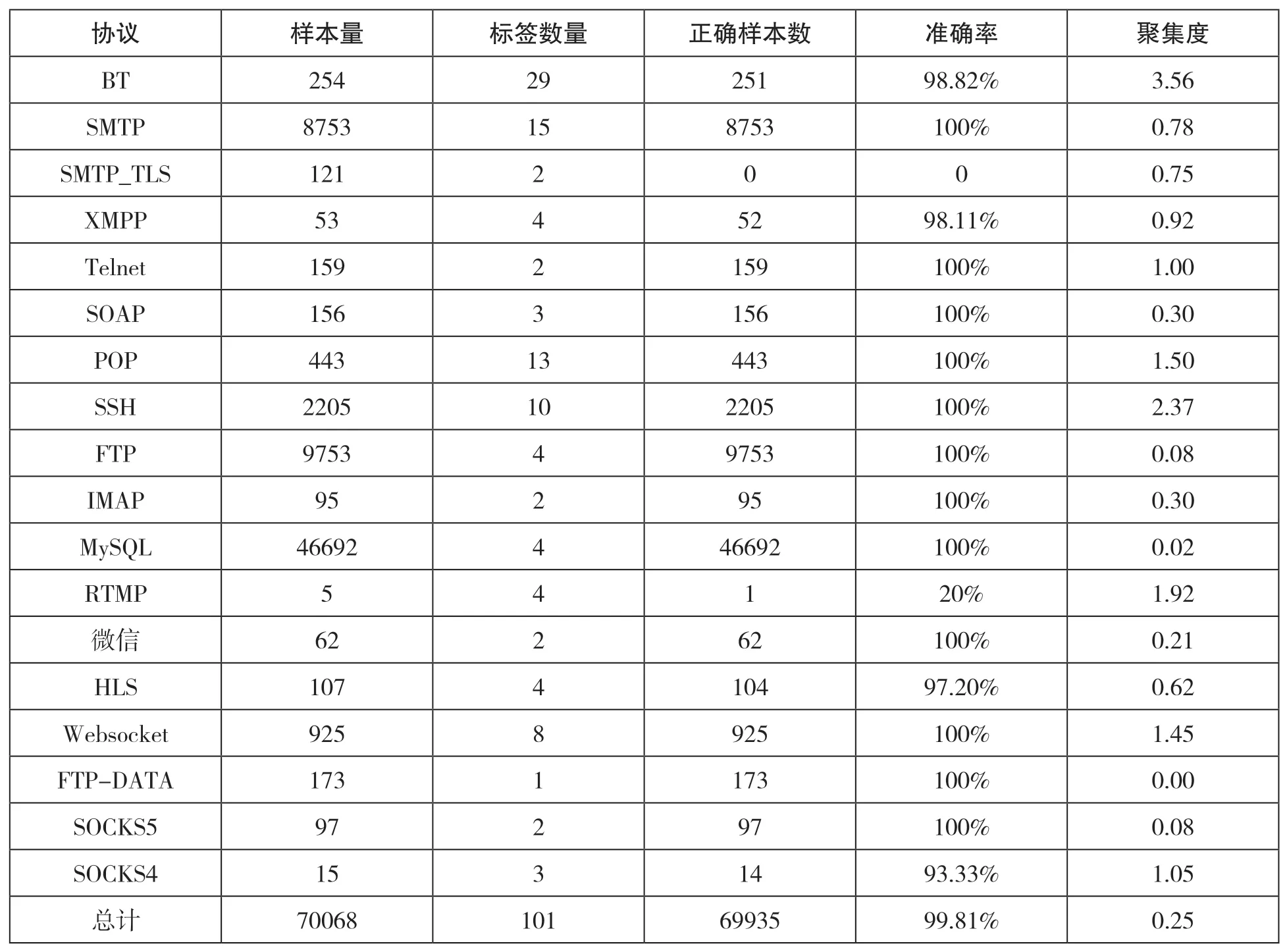
表2 可读数据流的分类结果
BT和FTP-DATA这类协议的负载与其传输文件有着密切的联系,当传输文件为加密文件或其他二进制文件时,会被作为不可读数据流;当传输文件为文本文件时,会被作为可读数据流。这类协议在特征上的变化也比较多,使其分类结果的聚集度偏高。与之相反,RDP、FTP、MySQL等协议在特征的表现比较固定,使其分类结果的聚集度更低,效果更好。从以上结果可以看出,本模型针对已知协议和未知协议(包括加密协议)流量均具有较好的分类效果,并且过程中不需要预先确定聚类中心点,不依赖原始样本数据进行标记学习,也能应对新出现的未知协议类型,具有普适性;同时算法经过多种策略调整,在准确率和聚集度上均能达到较好效果。
2.3 多策略效果分析
2.3.1 可读性策略分析
如表3所示,综合上述不可读数据流和可读数据流的整体分类结果:准确率为98.96%,聚集度为0.53,耗时175秒。在不使用可读性分类的整体结果:准确率为98.94%,聚集度为0.88,在运行聚类算法、CAA和CMA的过程中,耗时313秒。对比可知,经过可读性分类,分类结果的准确率和聚集度均有提升,计算性能也有较大提升。此外,可读性分类在某些数据集中会对结果带来更大的提升。
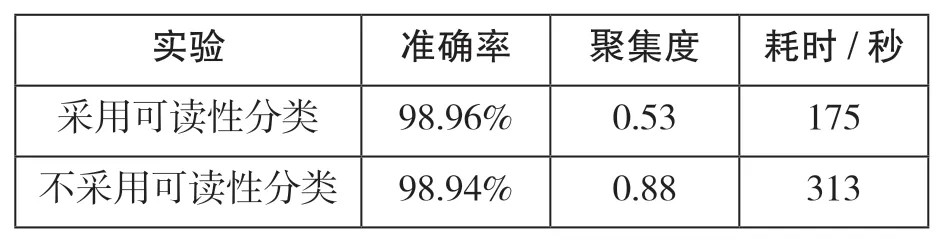
表3 采用与不采用可读性分类的效果对比
2.3.2 CAA与CMA策略分析
对27392个不可读数据流进行对比测试,如表4所示,无论单独使用哪一种聚类策略,其分类结果的准确率和聚集度都比不上采用CAA与CMA策略的准确率和聚集度。CAA与CMA可以规避单一策略的缺点,充分发挥各种策略的优势,从而使分类结果达到更优的效果。
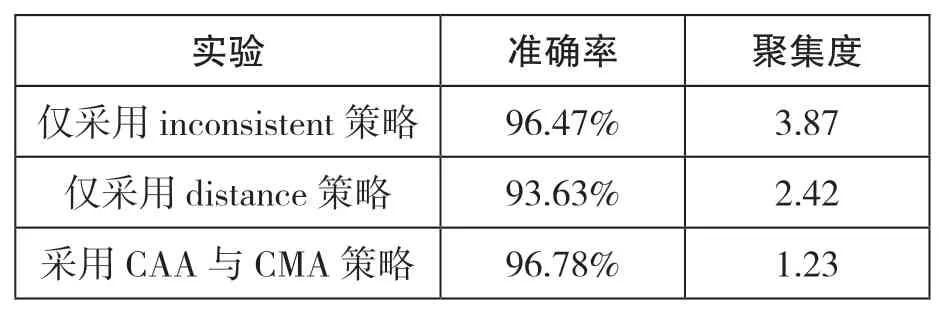
表4 是否采用CAA与CMA的分类效果对比
2.3.3 计算策略性能分析
聚类算法是整个过程中最耗时的部分,在本方法中,聚类计算性能优化通过单线程和多线程实现,并将其与scipy.cluster.hierarchy.linkage(Python层次聚类函数)进行对比。如图3所示,使用单指令多数据流(Single Instruction Multiple Data,SIMD)技术优化后的算法(对应单线程的曲线),比Python软件包库中的算法实现速度提升了近一倍。再使用多线程对算法进行加速,速度约为scipy库中的算法实现的8倍。
3 结 语
本文将层次聚类运用于未知协议的分类中,提出了一种基于层次聚类的多策略未知协议分类方法。借助马尔科夫链来强化特征的表征能力。使用可读性分类机制提升分类效果和计算性能。利用最近邻链算法、SIMD技术与多核技术加速本方法的计算速度。将CAA和CMA引入到本方法中,规避了单一聚类策略带来的弊端,发挥出了多种聚类策略的优势,提升了分类效果。最后提出了使用已知协议数据集合模拟未知协议数据集合的结果评估方法。实验结果表明,与原始的层次聚类算法相比,本分类方法的分类效果更优,且计算速度更快。
本文使用真实网络数据进行测试,无须对数据进行前提假设和设置要求,此方法能适用于各种现实网络中,较为通用,具有极强的工程应用能力。
