基于Landsat数据和农田概率时间序列子序列的退耕监测方法
2022-04-08吴伟伟李培军
吴伟伟 李培军
基于Landsat数据和农田概率时间序列子序列的退耕监测方法
吴伟伟 李培军†
北京大学地球与空间科学学院遥感与地理信息系统研究所, 北京 100871; †通信作者, E-mail: pjli@pku.edu.cn
提出一种利用 Landsat 数据和时间序列子序列的退耕监测方法。首先利用随机森林方法, 对每年的Landsat 数据统计值进行分类, 得到每个像元属于农田的概率, 由每年的农田概率构成年际的农田概率时间序列; 然后, 对退耕(农田变为非农田)及相关地物类别的农田概率时间序列进行分析, 得到代表退耕的时间序列片段, 即特征子序列; 最后, 计算未知像元的农田概率时间序列与退耕的特征子序列之间的距离, 提取退耕区域和退耕时间。利用内蒙古自治区察右后旗土牧尔台镇地区的多年Landsat时间序列影像验证该方法的有效性, 结果表明, 与现有的方法相比, 该方法在退耕区域和退耕时间提取方面均获得更高的精度。
退耕; 变化监测; 时间序列子序列; Landsat数据; 概率时间序列
土地覆盖和土地利用变化是全球变化的一个重要过程, 也是生态环境和气候变化的驱动因素之一[1]。土地覆盖和土地利用变化是自然过程和人类活动共同作用的结果, 与人类社会经济状况以及政策的变化密切相关。例如, 前苏联的解体导致大面积农田废弃[2‒3], 土地政策导致农田大规模扩张[4], 禁伐令导致森林砍伐率降低[5]。因此, 快速、准确地监测土地覆盖和土地利用变化对理解地表空间变化规律和分析区域生态环境的影响因素具有重要意义[6]。
2000 年以来, 中国实施规模最大、资源投入最多、持续时间最长的退耕还林工程[7], 即停止耕种严重沙化、盐溃化及其他具有重要生态功能的耕地, 采取人工种植或自然封育等方式恢复植被, 修复退化生态系统。这项工程实施以来, 不少学者利用遥感数据研究和监测退耕还林的过程及其生态效应。例如, 利用两个时相的遥感图像提取农田的变化[8], 但无法得到退耕还林的准确时间。有研究者利用低分辨率的植被指数(如 NDVI)时间序列, 分析退耕还林工程的有效性[9‒10], 但无法得到地表类别变化(不同土地覆盖类型间的转换)的信息。中分辨率的时间序列遥感数据(如 Landsat 系列数据)可提供更丰富的地表类别信息, 能够从中得到退耕还林的时间和空间分布状况。例如, Yin 等[11]结合Landsat 时间序列数据与影像分割方法, 提取高加索地区的农田退耕情况; Fabian 等[12]对每年的Landsat 影像进行分类, 利用连续的多年分类结果提取农田变化。
需要指出的是, 利用单一的光谱指数难以有效地区分不同土地覆盖类型间的变化, 如易混淆的农田与草本植物和灌木[11]。因此, 需要探索利用其他的特征, 更准确地提取农田变化。Yin 等利用年际MODIS 数据的统计值和随机森林分类得到的土地覆盖类别的概率来描述不同类别的变化[13], 并利用由 MODIS 数据得到的农田和林地的概率时间序列提取内蒙古地区退耕还林的情况[14]。Dara 等[2]利用从 Landsat 数据得到的农田概率时间序列, 提取废弃和复耕农田。上述研究通过农田及相关地物类别的概率时间序列监测农田变化, 利用时间序列分割进行时间序列降噪和突变点提取, 并进一步得到地表类别发生变化的时间, 但这些退耕提取方法严重地依赖时间序列分割结果的质量。
近年来, 基于时间序列子序列的分析方法在计算机视觉领域受到广泛关注[15‒16]。该方法的提出基于以下认知: 一些时间序列的片段或子序列可以代表该时间序列的类别属性, 即具有判别能力的特征, 故从整个时间序列中识别出这些具有代表性的子序列(特征子序列)即可对时间序列进行分类[17]。该方法对时间序列的局部特征敏感, 为遥感时间序列分析提供了有用的工具。然而, 现有研究主要关注如何提取特征子序列, 对其在遥感时间序列分析中的应用和有效性评价研究目前还很少[18‒19]。
本文提出一种新的利用时间序列子序列和 Lan-dsat 时间序列的农田退耕监测方法, 利用农田的概率时间序列来描述土地覆盖状态, 采用时间序列的特征子序列来提取退耕区域和退耕时间。
1 研究区域与数据
研究区域为内蒙古自治区乌兰察布市察右后旗土牧尔台镇及周边地区(图 1(a))。区域内干旱少雨, 降水集中在 7—9 月, 年平均气温为 3~5℃。广泛分布干旱、半干旱草原植被, 畜牧业发达。主要农作物有马铃薯、小麦、莜麦、胡麻、青贮玉米和油菜等[20]。该区域连接着北部牧区与南部农区, 是典型的农牧交错带, 生态环境脆弱。20 世纪 50 年代以来, 乌兰察布对粮食的需求持续增加, 大面积毁林开荒和垦草种粮, 耕地面积快速增加, 导致水土流失和土地荒漠化等问题日益突出。为了改善生态环境, 2000 年后开展大规模退耕还林[21], 极大地改变了该区域的土地覆盖状况和生态环境。因此, 利用时间序列遥感数据对该地区进行退耕监测, 及时掌握其退耕还林的时空变化及其对生态环境的影响, 具有重要意义。

(b)中短波红外1波段、近红外波段和红光波段分别显示为红色、绿色和蓝色
本文使用 Landsat 5 和 Landsat 7 的地表反射率数据, 所用数据均从 Google Earth Engine 平台下载。获取研究区 1998—2012 年 Landsat 系列卫星的所有可用数据, 共 875 景影像。受数据获取条件及云量的影响, 每年可用的影像数量不均衡, 其中1998, 1999, 2003 和 2012 年可用的 Landsat 影像数量较少(图 2)。利用 CFMask 对影像中的云、阴影、条带、水体和雪进行掩膜[22]。
本研究利用野外实地考察数据和 Google Earth高分辨率遥感影像, 选取两类样本数据。第一类样本用于对图像数据进行土地覆盖分类, 参照 Dara等[2]的方法, 选取稳定农田(1998—2012 年间一直为农田)与稳定的非农田(1998—2012 年间一直为非农田类别)两类的训练样本, 其中非农田类别包括建成区、林地、裸地、草地和湿地等。每类的训练样本数为 500 个像元。第二类样本用于分析与评价退耕提取的精度, 选取退耕与非退耕两类样本, 每类样本数为 300 个像元, 其中对于退耕类, 2000—2009年间每年选取 30 个发生退耕的像元。
2 方法
如图 3 所示, 本文提出的方法主要步骤如下: 首先, 采用随机森林分类方法, 对每年的 Landsat 数据统计值进行分类, 得到每年每个像元属于农田的概率, 由多年农田概率构成年际农田概率时间序列; 然后, 分析不同土地覆盖类别的农田概率时间序列样本, 得到退耕区域中农田概率时间序列的特征子序列; 最后, 计算每个像元的农田概率时间序列与退耕类别的特征子序列之间的距离, 并确定合适的距离阈值, 得到退耕区域, 同时估算退耕发生的时间。

图2 本研究使用的不同年份的Landsat影像数量

图3 本文方法流程
2.1 构建农田概率的时间序列
首先利用随机森林分类方法[23], 对每年 Landsat数据的统计值进行分类, 得到每年农田类别的概率。分类过程中使用的图像特征包括红、绿、蓝、近红外、短波红外 1、短波红外 2、NDVI (norma-lized difference vegetation index)、NBR (normalized burn ratio)和 MSAVI2 (modified soil-adjusted vege-tation index)共 9 个波段在特定时间窗口内的最大值、最小值、中值、均值、方差和百分位数值(包括 5%, 25%, 75%和 95%)共 9 个统计值, 共得到 81个特征值。为了降低由于数据缺失以及影像数量分布不均匀对分类结果的影响, 本研究采用的时间窗口是目标年份及其前后一年[2,11], 例如 1999 年的统计值是利用 1998—2000 年 3 年的 9 个特征波段计算得到的。
随机森林方法是近年提出的基于决策树的集成分类方法, 其中决策树在训练过程中随机选择用于分类的特征, 因此该方法对分类的特征数量不敏感, 能够处理高维数据, 适用于本研究的情况。在对每个像元进行分类时, 每棵相互独立的决策树都进行分类, 每个类别的概率是随机森林分类中该类别的决策树占总决策树棵数的比例[24]。
本文利用稳定的农田与稳定的非农田样本训练随机森林分类器, 得到每个像元属于农田的概率, 由每年的农田概率构成年际农田概率时间序列。利用窗口大小为 5 年的中值滤波, 对概率的时间序列进行降噪, 并将降噪后的时间序列用于后续的计算与分析中。
2.2 提取基于子序列的退耕区域
2.2.1 确定特征子序列
特征子序列(shapelet)是时间序列中最能代表类别特征的一段连续子序列或片段[15‒16]。通过计算每个像元的时间序列与特定类别的特征子序列的相似性, 可得到该像元所属的类别, 对时间序列进行分类。该方法可减少时间序列中噪声对分类的影响[17]。与其他时间序列分类方法相比, 基于特征子序列的分类方法具备更强的解释性, 可以直观地表明类别之间的差异, 无须对整条时间序列进行比较与分析。
现有的提取特征子序列的方法大致分为 3 类: 基于搜索的算法[15]、基于梯度下降的学习算法[25]以及基于样本选取的方法[18]。基于搜索的算法假设类别的特征子序列存在于训练样本中, 通过逐样本、逐窗口搜索得到特征子序列。为降低基于搜索的算法的计算复杂度, 有学者提出基于梯度下降的学习算法, 但该方法学习到的特征子序列往往不存在于训练样本中, 可解释性较低[24‒25]。基于样本选取的方法则根据目视解译确定类别的特征子序列, 对时间序列简单、子序列特征明显的问题能取得较好的效果[18]。
本文采用基于样本选取的方法来确定退耕的特征子序列。为了说明如何确定合适的特征子序列, 本文为退耕、稳定农田和稳定非农田 3 个类别分别选取 5 个参考样本, 作为实例来分析这 3 个类别的时间序列特征。图 4 显示 3 个类别的农田概率时间序列。从图 4(a)可以看出, 退耕区域的农田概率时间序列总体上呈现下降趋势, 其中具有判别意义的是 2000—2004 年间的片段(灰色竖线间的片段)。稳定的农田类别属于农田的概率一直高, 而稳定的非农田类别属于农田的概率一直低, 两者的时间序列变化小。因此, 退耕区域与非退耕区域具有显著不同的特征子序列。需要注意的是, 由于各像元之间下降时间长度和斜率有差异, 所以特征子序列并不唯一。
本文通过目视解译, 确定退耕的参考样本在时间序列中下降趋势开始和结束的位置(图 4(a)中灰色竖线的位置), 作为特征子序列的时间区间, 这样就可以得到退耕样本的特征子序列, 用于退耕区域的提取。
2.2.2 计算时间序列与特征子序列的距离
本文利用像元的农田概率时间序列与特征子序列间的距离表达二者间的相似性, 并根据相似性程度确定像元是否发生退耕。
给定长度为的时间序列={1,2, …,e}和={1,2, …,r}, 则二者之间的欧氏距离为

假定一个子序列是长度为的时间序列, 记为= {1,2, …,s}。一个长度为(≥l)的完整的时间序列和子序列之间的距离为



SetDist(, SE)反映一个时间序列与退耕类特征子序列之间的相似度。本研究中, SE 为退耕类别特征子序列样本集, SetDist(, SE)越小, 表明此像元发生退耕的可能性越高。
2.2.3 确定距离阈值
计算各个像元的农田概率时间序列与退耕类别特征子序列的距离后, 通过确定合适的距离阈值来判断该像元是否发生退耕。如果一个像元的农田概率时间序列与退耕类别特征子序列的距离小于选定的阈值, 则该像元为退耕像元, 否则为非退耕像元。因此, 距离阈值的确定是提取退耕的重要环节。目前已有不少确定阈值的方法, 如人工试错(trial and error)法和 Otsu法[26]。上述两种方法容易受噪声影响, 得到的阈值精度较低。本文采用蒙特卡洛交叉验证法[27]确定退耕区域提取的最佳阈值。蒙特卡洛交叉验证法通过随机重复选取固定数量的训练样本和验证样本, 利用训练样本确定合适的阈值, 使用验证样本评价该阈值提取的分类精度。在每次迭代中, 选择最适合训练样本的阈值, 并计算所选阈值在验证样本中的分类精度。迭代结束后, 选取在验证样本中取得最大分类精度的阈值为最佳阈值, 并利用该阈值来提取退耕区域[28]。
2.3 估计退耕时间
在基于特征子序列的退耕检测中, 除得到各像元的农田概率时间序列与退耕特征子序列的最小距离外, 还得到该最小距离对应的时间序列片段(interval)位置, 该片段代表发生退耕的时间区间。本文在此区间内进一步确定退耕的时间点。从2.2.1 节的论述可知, 该时间区间内退耕像元的农田概率呈现从高到低的变化。因此, 通过设定一个农田概率的阈值来确定退耕的时间点: 当像元的农田概率大于等于选定的阈值时为农田, 否则为非农田, 退耕年份为得到的时间区间中第一个小于该阈值的年份的前一年。
为了准确地确定农田概率阈值, 本文选取 30 个退耕样本点, 分别计算不同概率阈值对应的退耕时间。选取时间精度最高的阈值作为最终的农田概率阈值, 用来确定各退耕像元的退耕时间。
3 实验结果与分析
3.1 特征子序列的提取与参数设定
本文选取 100 个时间序列参考样本作为参考数据, 依此确定退耕的特征子序列。图 5 按照特征子序列的时间长度(年), 归类展示利用 100 个退耕的参考样本得到的退耕特征子序列。可以看出, 退耕像元的农田概率特征子序列都具有随时间推移而下降的趋势, 即从高农田概率逐渐变为低农田概率。这些特征子序列的时间长度通常在 2~10 年之间, 其中时间长度为 3, 4, 5, 6 和 8 年的特征子序列数量相对较多。不同参考样本的农田概率时间序列有一定的差异, 概率时间序列下降的速率和长度不同, 导致图 5 中不同长度特征子序列的数量有差异。
为了利用蒙特卡洛交叉验证法确定合适的距离阈值, 用来提取退耕区域, 本文随机选取 600 个样本数据中的 30%来确定距离阈值, 其中 22.5%作为训练样本, 7.5%作为验证样本, 剩余 70%的样本用于退耕区域提取结果的精度分析与评价。利用蒙特卡洛交叉验证法进行 10 次迭代, 得到提取退耕区域的最佳阈值。经过实验, 本文选取 7.14 作为最佳阈值来提取退耕区域。
为确定农田概率阈值, 计算各退耕像元的退耕时间, 本文分别测试45%, 50%, 55%和60%共 4 个农田概率阈值, 分别得到 4 个阈值的退耕时间结果。利用 30 个退耕样本点, 计算不同阈值下的退耕时间精度, 最后选取时间精度最高的55%为农田概率阈值。
3.2 退耕监测精度分析
通过随机森林方法得到的农田概率是退耕监测的重要基础, 准确的农田概率可以提高退耕监测的精度。本文在 1999—2011 年中每年选取 150 个样本(农田样本和非农田样本均为 75 个), 采用总体精度(OA)和值来度量通过随机森林分类得到的农田概率的准确性。
对本文方法精度的评价包含退耕提取精度(分类精度)和退耕发生时间精度两个方面。度量分类精度的指标包括总体精度、值、生产者精度(pro-ducer’s accuracy, PA)和用户精度(user’s accuracy, UA) 4 个指标。除定量指标外, 本文还通过目视观察, 定性地分析退耕提取结果。
采用精确匹配与模糊匹配两种方法, 计算退耕时间精度[2]。精确匹配是提取的时间与参考年份完全一致时才算正确, 模糊匹配是以参考年份及前后一年为正确的区间来计算退耕时间精度。
为了全面地评价所提方法的有效性, 选取一种基于时间序列分割的退耕监测方法[2]进行对比。该方法利用 LandTrendr[29]对农田概率的时间序列进行分割, 使用 6 年的移动窗口提取退耕区域和时间, 已应用于哈萨克斯坦北部区域的退耕监测中。
3.2.1 农田概率评价
利用随机森林分类得到的类别概率, 将每年的地表覆盖分类为农田与非农田两类。通过对每年的农田分类结果进行精度评价, 度量得到的农田概率的准确性。从图 6 可以看出, 1999—2011 年的分类总体精度绝大部分高于 85%, 只有 2006 年的分类精度在 80%~85%之间。值的变化趋势与总体精度大致相同。从这两个指标来看, 随机森林方法可以较好地区分农田与非农田, 得到的农田概率时间序列可用于农田退耕监测。
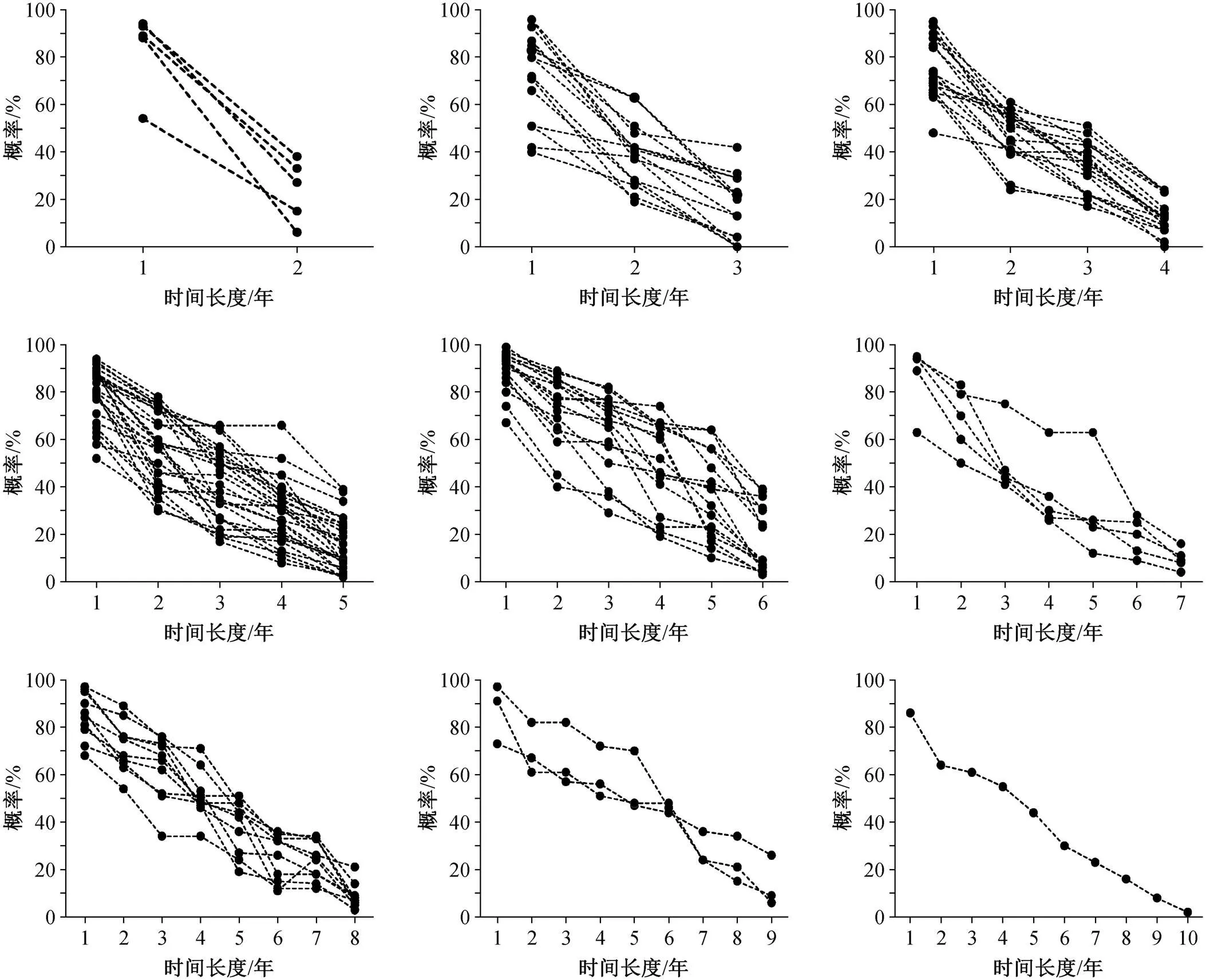
图5 退耕类别的特征子序列
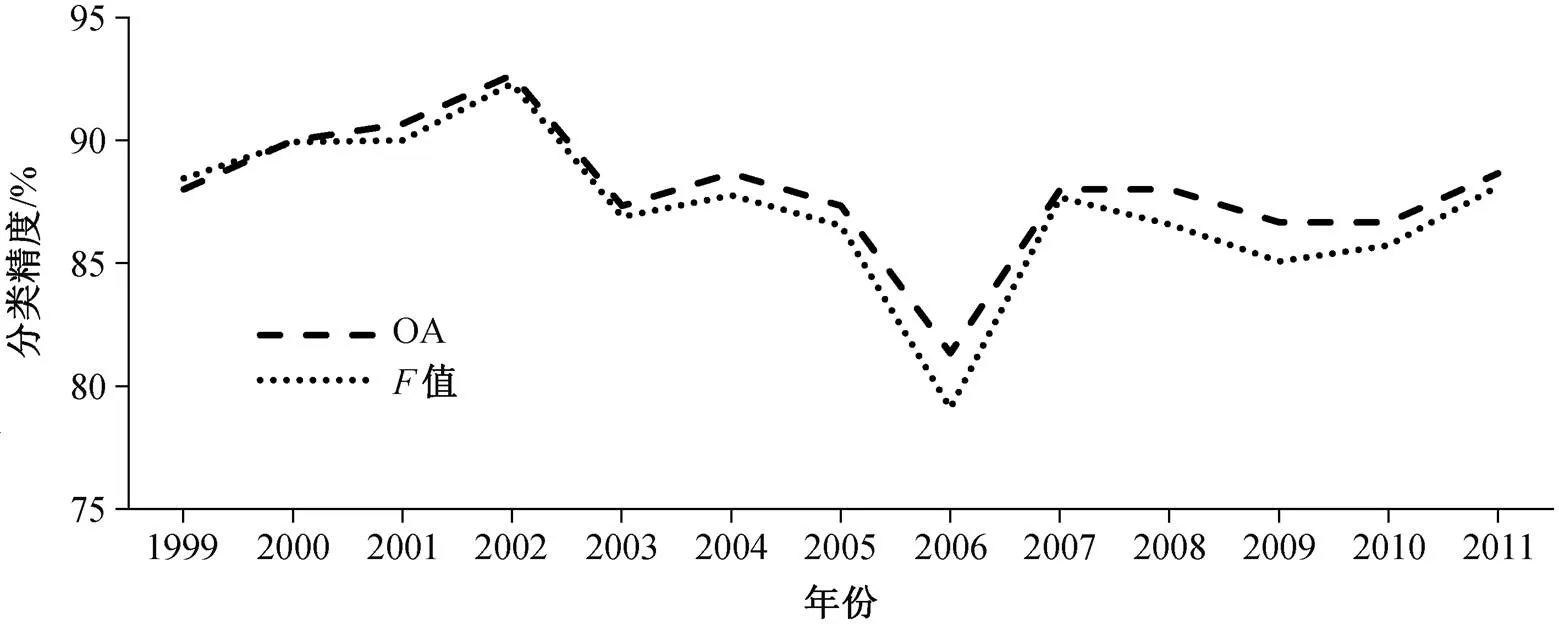
图6 基于随机森林的各年分类精度
3.2.2 退耕区域提取结果
表1显示两种方法提取退耕区域的精度, 可以看出, 本文方法的总体精度和值比基于时间序列分割的方法[2]分别高 1.91%和 1.34%。从退耕类别的精度来看, 现有方法有较高的 PA (92.85%)和相对较低的 UA (84.05%), PA 与 UA 差距较大; 本文方法具有较为均衡且较高的 PA 和 UA, 两者均在 90%左右。从 4 个评价指标来看, 本文方法均优于现有方法, 表明本文提出的方法是一种有效的退耕区域检测方法。

表1 不同方法退耕区域提取结果精度(%)
为了进一步验证本文方法的有效性, 选取研究区局部的提取结果进行分析, 定性地比较两种方法的提取结果与地面实际情况的异同, 结果如图 7 所示。区域 A 的田块在 1999—2011 年间发生退耕, 基于时间序列分割的方法[2]提取出部分退耕区域, 但出现部分漏分区域(区域 A 中白色像元); 本文方法提取到更完整的退耕区域, 漏分的面积较小。区域B 在 1999—2013 年期间一直为农田, 基于时间序列分割的方法[2]将其中部分区域提取为退耕区域, 属于错分; 尽管本文方法也出现错分, 但错分面积较小。因此, 从区域 A 和 B 两个局部提取结果可以看出, 本文方法好于基于时间序列分割的方法[2], 可以更准确地提取退耕区域。
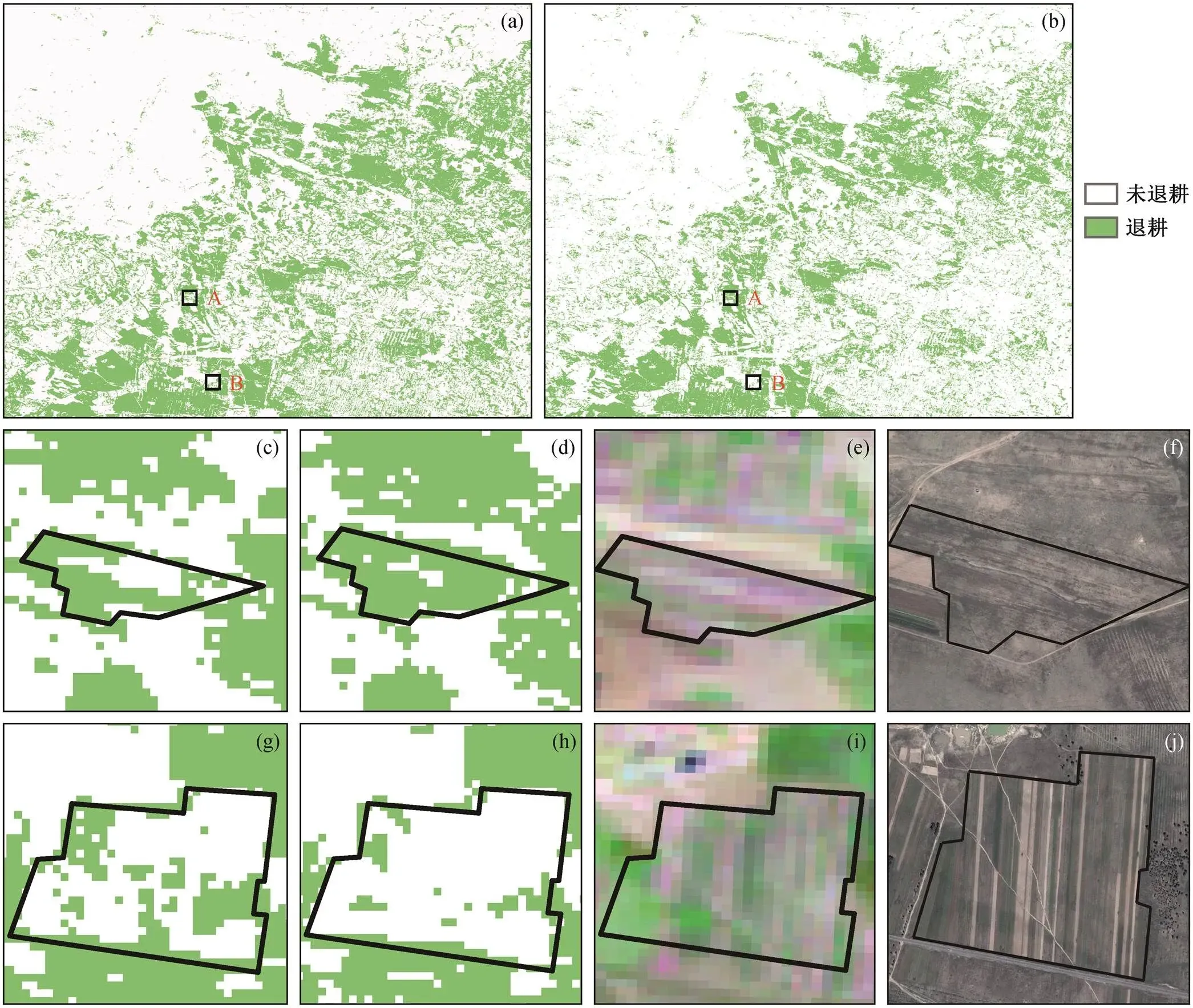
(a)和(b)分别为时间序列分割法与本文方法的提取结果; (c)和(d)分别为时间序列分割法与本文方法对区域A的提取结果, (e)和(f)分别为区域A退耕前的Landsat影像数据与退耕后的高分辨率影像; (g)和(h)分别为时间序列分割法与本文方法对区域B的提取结果, (i)和(j)分别为区域B不同年份的Landsat影像数据和高分辨率影像。(e)和(i)1999 年 8月 26 日, 其中短波红外波段、近红外波段和红光波段分别显示为红色、绿色和蓝色; (h)和(j) 2013 年 8 月 23 日
3.2.3 退耕时间提取结果
图 8 给出不同方法提取的退耕时间。图 8(a)中出现较多的蓝色区域, 表明基于时间序列分割的方法将退耕时间识别为较晚的年份; 图 8(b)的左下角出现较多的红色区域, 表明本文方法对此区域的退耕时间识别为较早的年份。从表 2 看出, 本文方法的精确匹配精度和模糊匹配精度比基于时间序列分割方法分别高 10.34%和 17.67%。因此, 本文方法在退耕时间提取方面显著优于现有方法。
综上所述, 从定性和定量两个方面看, 本文提出的方法在退耕区域和退耕时间提取两方面均优于基于时间序列分割的方法[2]。

(a)基于时间序列分割的方法; (b)本文方法

表2 不同方法的退耕时间提取精度(%)
3.3 讨论
本文方法的分类精度优于基于时间序列分割的退耕提取方法[2], 时间精度也显著提高。一方面, 传统的时间序列分析方法是通过模型拟合或时间序列分割, 对整个时间序列进行分析, 时间序列中那些带有噪声且不具有分类判别能力的子序列(非特征子序列)可能会影响分析结果; 本文提出的基于特征子序列方法是利用子序列对时间序列进行分类, 探测农田概率时间序列中是否有相同的模式(子序列), 避免了非特征子序列噪声对分类的影响, 能够提供可靠的时间序列分类结果, 有效地区分退耕区域与非退耕区域。另一方面, 传统的时间序列分析方法需要利用时间序列分割来简化时间序列和提取突变点, 时间序列分割结果的质量直接影响最终分类的精度; 本文提出的基于特征子序列的方法能直接对时间序列进行相似性判别, 避免引入时间序列分割模型误差, 显著地提高了退耕提取精度。
本文方法存在需要改进的地方。特征子序列的选取对分类结果有一定的影响, 通过目视解译提取特征子序列的方法容易受到主观因素影响。未来工作中可探索自动提取特征子序列的方法, 降低主观因素对特征子序列选取的影响。另外, 本文方法利用分类得到属于农田的概率, 分类结果的误差可能会影响后续的处理和分析, 可以考虑直接利用能够反映农田特征的指标构建时间序列, 用于退耕区域的提取。
4 结论
本文提出一种利用 Landsat 数据和时间序列子序列的退耕监测方法, 使用时间序列的特征子序列区分退耕区域与非退耕区域, 并在退耕区域中估计退耕年份。实验结果表明, 与基于时间序列分割的退耕监测方法相比, 本文方法可以得到更高的退耕区域和退耕时间提取精度。与传统的时间序列分析方法相比, 本文方法利用局部特征对概率时间序列进行分类, 不需要对时间序列进行分割, 是一种有效的监测退耕方法。
[1] Foley J A, Defries R, Asner G P, et al. Global con-sequences of land use. Science, 2005, 309: 570‒574
[2] Dara A, Baumann M, Kuemmerle T, et al. Mapping the timing of cropland abandonment and recultivation in northern Kazakhstan using annual Landsat time series. Remote Sensing of Environment, 2018, 213: 49‒60
[3] Kuemmerle T, Radeloff V C, Perzanowski K, et al. Cross-border comparison of land cover and landscape pattern in Eastern Europe using a hybrid classification technique. Remote Sensing of Environment, 2006, 103(4): 449‒464
[4] Miao L J, Zhu F, He B, et al. Synthesis of China’s land use in the past 300 years. Global and Planetary Change, 2013, 100: 224‒233
[5] de Blas D E, Perez M R. Prospects for reduced impact logging in central african logging concessions. Forest Ecology and Management, 2008, 256 (7): 1509‒1516
[6] Roy D P, Wulder M A, Loveland T R, et al. Landsat-8: science and product vision for terrestrial global change research. Remote Sensing of Environment, 2014, 145: 154‒172
[7] Liu J G, Li S X, Ouyang Z Y, et al. Ecological and socioeconomic effects of China’s policies for ecosys-tem services. Proceedings of the National Academy of Sciences of the United States of America, 2008, 105(28): 9477‒9482
[8] Kraemer R, Prishchepov A V, Muller D, et al. Long-term agricultural land-cover change and potential for cropland expansion in the former virgin Lands area of Kazakhstan. Environmental Research Letters, 2015, doi: 10.1088/1748-9326/10/5/054012
[9] Tian H J, Cao C X, Chen W, et al. Response of vege-tation activity dynamic to climatic change and ecolo-gical restoration programs in Inner Mongolia from 2000 to 2012. Ecological Engineering, 2015, 82: 276‒ 289
[10] Tong X W, Wang K L, Yue Y M, et al. Quantifying the effectiveness of ecological restoration projects on long-term vegetation dynamics in the karst regions of Southwest China. International Journal of Applied Earth Observation and Geoinformation, 2017, 54: 105‒113
[11] Yin H, Prishchepov A V, Kuemmerle T, et al. Mapping agricultural land abandonment from spatial and tem-poral segmentation of Landsat time series. Remote Sensing of Environment, 2018, 210: 12‒24
[12] Fabian L, Elisabeth F, Iskandar A, et al. Mapping abandoned agricultural land in Kyzyl-Orda, Kazakh-stan using satellite remote sensing. Applied Geogra-phy, 2015, 62: 377‒390
[13] Yin H, Pflugmacher D, Kennedy R E, et al. Mapping annual land use and land cover changes using MODIS time series. IEEE Journal of Selected Topics in App-lied Earth Observations and Remote Sensing, 2017, 7(8): 3421‒3427
[14] Yin H, Pflugmacher D, Li A, et al. Land use and land cover change in Inner Mongolia — understanding the effects of China’s revegetation programs. Remote Sensing of Environment, 2018, 204: 918‒930
[15] Ye L X, Keogh E. Time series shapelets: a novel technique that allows accurate, interpretable and fast classification. Data Mining and Knowledge Disco-very, 2011, 22(1/2): 149‒182
[16] Baydogan M G, Runger G, Tuv E. A bag-of-features framework to classify time series. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11): 2796‒2802
[17] Grabocka J, Wistuba M, Schmidt-Thieme L. Fast classification of univariate and multivariate time series through shapelet discovery. Knowledge and Information Systems, 2016, 49(2): 429‒454
[18] Maire G L, Dupuy S, Nouvellon Y, et al. Mapping short-rotation plantations at regional scale using MODIS time series: case of eucalypt plantations in Brazil. Remote Sensing of Environment, 2014, 152: 136‒149
[19] Ye S, Rogan J, Sangermano F. Monitoring rubber plantation expansion using Landsat data time series and a shapelet-based approach. Journal of Photo-grammetry & Remote Sensing, 2018, 136: 134‒143
[20] 汪芳甜, 安萍莉, 刘毅, 等. 近 30 年阴山南北麓农牧交错带标准耕作制度变化研究. 中国生态农业学报, 2014, 22(6): 690‒696
[21] 范亚娟. 乌兰察布市柠条资源开发与利用. 内蒙古林业调查设计, 2018, 41(5): 74‒75
[22] Foga S, Scaramuzza P L, Guo S, et al. Cloud detec-tion algorithm comparison and validation for opera-tional Landsat data products. Remote Sensing of En-vironment, 2017, 194: 379‒390
[23] Breiman L. Random forests. Machine Learning, 2001, 45(1): 5‒32
[24] Adam E, Mutanga O. Spectral discrimination of papy-rus vegetation (L.) in swamp wet-lands using field spectrometry. Journal of Photo-grammetry and Remote Sensing, 2009, 64(6): 612‒ 620
[25] Grabocka J, Schilling N, Wistuba M, et al. Learning time-series shapelets // Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. New York, 2014: 392–401
[26] Otsu N. Threshold selection method from gray-level histograms. IEEE Transactions on Systems Man and Cybernetics, 1979, 9(1): 62–66
[27] Xu Q S, Liang Y Z. Monte Carlo cross validation. Chemometrics and Intelligent Laboratory Systems, 2001, 56(1): 1–11
[28] Dubitzky W, Granzow M, Berrar D. Fundamentals of data mining in genomics and proteomics. Funda-mentals of Data Mining in Genomics & Proteomics, 2007, doi: 10.1007/978-0-387-47509-7
[29] Kennedy R E, Yang Z, Cohen W B. Detecting trends in forest disturbance and recovery using yearly Lan-dsat time series: 1. LandTrendr — temporal segmen-tation algorithms. Remote Sensing of Environment, 2010, 114(12): 2897–2910
A Method for Monitoring Cropland Retirement Using Landsat Images and Time Series Subsequence of Cropland Probability
WU Weiwei, LI Peijun†
Institute of Remote Sensing and Geographical Information System, School of Earth and Space Sciences, Peking University, Beijing 100871; † Corresponding author, E-mail: pjli@pku.edu.cn
A method for monitoring cropland retirement using Landsat images and time series subsequence of cropland probability was presented. First, random forest was used to classify the statistical values of intra-annual Landsat images to obtain the probability of belonging to cropland for each pixel. These cropland probabilities obtained constitute annual time series of cropland probability. Next, the time series of cropland retirement (cropland to non-cropland) and other landcover change were analyzed to obtain the time series subsequence representing cropland retirement, that is, the characteristic subsequence. Finally, the distance between the cropland probability time series of an unknown pixel and the characteristic subsequence of the cropland retirement was calculated to extract the area and timing of cropland retirement. The proposed method was validated in cropland retirement mapping using Landsat time series of Tumuertai Town, Chahar Right Back Banner, Inner Mongolia Autonomous Region. The results shows that compared with existing methods, the proposed method produced higher accuracy in the extraction of both the area and timing of cropland retirement.
cropland retirement; change detection; time series subsequence; Landsat imagery; time series of probability
10.13209/j.0479-8023.2021.120
国家自然科学基金(42071307)资助
2021–03–03;
2021–04–28
