基于改进YOLOv3网络的烟梗识别定位方法
2022-04-07刘新宇郝同盟张红涛逯芯妍
刘新宇 郝同盟 张红涛 逯芯妍
(华北水利水电大学电力学院,河南 郑州 450011)
烟叶分级是根据烤烟的外观质量特征,如烟叶的部位、颜色、成熟度、身份、油分等多种特征来分级[1-3]。目前,烟叶分级系统的难点之一在于对不同姿态、不同等级、不同产地烟梗部位的精准识别。烟叶含梗率是指烟叶中烟梗占有的比例,含梗率与烟梗粗细、叶片厚薄有关。部位不同含梗率差异很大(下部最高,中部次之,上部最低[4])。烤烟含梗率一般约为25%。含梗率高低影响着烟叶的使用价值,反映烟叶可用性大小。传统烟叶分级主要依靠专家经验,依靠人的感官来判断烟叶的品级,效率低,成本高,很难保证烟叶分级的客观性和正确性,越来越无法满足烟草行业对烟叶质量的要求。此外,由于烤烟的特性,经过烤烟收集上来的烟叶由于烟油等因素的影响往往会粘连在一起,给烟叶分级智能化带来了不利影响。
基于机器学习技术的发展与计算机算力的不断提升,利用机器学习对农业进行辅助生产成为了卷烟生产、加工的新方向[4-7]。朱文魁等[8]采用低能X射线透射成像,结合形态学滤噪、灰度阈值分割等方法对烟梗识别率达到94.5%。崔云月等[9]基于BP神经网络利用烟梗的灰度占比作为输入实现了误差为3.91%的烟梗长短检测率。宋洋等[10]利用MPC08SP四轴运动控制卡,基于Visual C++底层控制程序实现了烟把的智能定位。席建平等[11]利用烟叶、烟梗在X光下的透射率不同的特性,基于FPGA图像处理实现了90%的烟梗检测率。汤龙[12]采用高功率红外透射光源,基于灰度算法实现了检测率82%的烟梗检测。郑茜等[13]基于高频低强度震动技术,以高频低强度激振力实现分选筛的往复运动实现了烟梗的选筛。上述烟梗识别模型都借用了传统机器学习识别手段,其大多数根据烟梗在高能量光线下透视的物理特性来辅助烟梗的检测识别,当下关于烟梗识别的研究关注点在于卷烟加工生产过程中的烟梗的剔除,虽都提高了检测的精度,但未提高检测效率。因为目前烟草行业的智能烟叶分级项目处于研发且保密阶段。公开的烟梗定位研究资料较少,而众多文献对于烟叶智能分级系统的关注点都在于对单片烟叶的分类识别,对烟梗识别定位缺乏一定的关注。
试验拟以YOLOv3为基础网络,在主干网络引入新的单元模块以增强网络的特征提取,使用Swish激活函数提高语义信息的利用来提高网络精度,通过卷积网络视觉处理来提高烟梗检测的准确率与检测效率,以期为烟叶智能化分级提供先决条件。
1 YOLOv3原理
1.1 YOLOv3网络结构与原理
目标检测算法主要分为两大类别,一类是两阶段的目标检测器,即基于候选区域的目标检测,另一类是单阶段的目标检测器,即将目标检测任务作为回归处理的检测算法[9-13]。YOLO系列算法是在RCNN的基础上提出来的,属于典型的单目标检测算法,其优点是省略了候选区域生成的步骤,通过检测目标的位置输入,将目标分类与位置回归问题融合到一个卷积网络中,提高了目标检测的速度,增强其工程应用性[14-16]。YOLOv3网络是在YOLOv2的网络结构基础上改进而来的,其将YOLOv2的主干特征提取网络由Darknet-19更换为效果更好的Darknet-53。YOLOv3的结构图如图1所示,其特征提取模块由Darknet-53网络与多尺度融合模块构成,通过Darknet-53主干网络对输入图像的特征压缩,分别提取经过压缩3次,4次,5次作为后续网络的输入,得到13×13,26×26,52×52 3个不同大小尺度的特征图。为了提取更多有效的特征信息YOLOv3通过上采样的方式,将52×52与26×26的特征图进行融合,同时将26×26与13×13的特征图进行融合。通过交互层进行特征融合构建特征金字塔模型,提取更深层次的语义信息,有利于提高网络的检测精度。
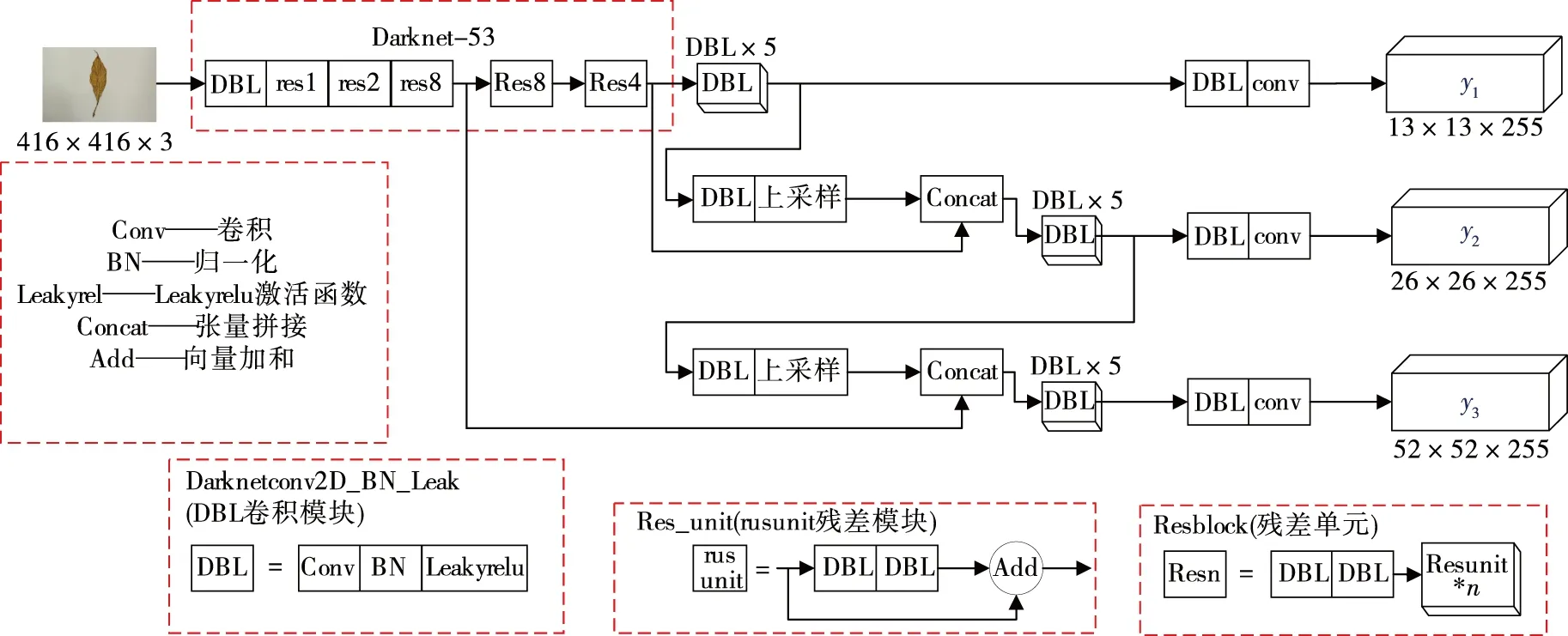
图1 YOLOv3网络结构Figure 1 YOLOv3 network structure
1.2 DenseNet-53网络
卷积网络中通过加深网络层数,与加宽网络结构来提升网络的整体性能,但层数的增加往往伴随着特征信息的高度提炼与丢失[17-20]。针对在网络训练过程随着网络层数增加梯度消失问题,DenseNet网络如图2所示,其引入DenseBlock模块,DenseBlock模块的使用使网络每层计算量减少,特征得以重复利用。DenseNet使一层的输入直接影响到之后的所有层,提高网络的特征信息的利用,其输出为:

图2 DenseNet网络结构Figure 2 DenseNet network structure
Xn=Hn([X0,X1,…,Xn-1]),
(1)
式中:
[X0,X2,…,Xn-1]——特征图像(feature map)以通道维度合并后的特征图;
Hn——特征拼接函数;
Xn——经特征拼接后的特征图。
DenseNet-53主要有两个特性:① 在一定程度上减轻在训练过程中梯度消散的问题。在反传时每一层都会接收其后所有层的梯度信号,不会随着网络深度的增加,靠近输入层的梯度会变得越来越小。② 由于大量的特征被复用,使得使用少量的卷积核就可以生成大量的特征,最终模型的参数也会减少,有利于提高网络的识别速度。
2 改进的YOLOV3网络
在传统YOLOv3网络结构中使用Leakyrelu激活函数如式(2),Leakyrelu的作用在于反向传播过程中,对于LeakyReLU激活函数输入小于零的部分,也可以计算得到梯度避免上述梯度方向锯齿问题,但如图3所示,随着输入的负值越大,其影响逐渐增大。其对样本的训练精度的影响会增大,为避免负样本的影响率过大的问题,使用Swish激活函数如式(3),如图3所示其相对Leakyrelu激活函数在X负无穷方向更加平滑且在保证有负样本输入的前提下,弱化了其对网络整体的影响,允许信息深入网络,提高网络精度。
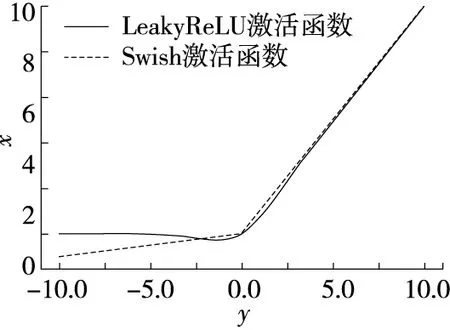
图3 激活函数Figure 3 Activation function
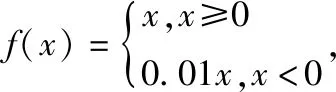
(2)
f(x)=x×[1/(1+e-x)]。
(3)
DenseNet-53中的Dense Block由Bottleneck模块构成,如图4所示,将原有的Bottleneck模块结构替换为如图5所示的结构单元,使用Swish激活函数,在经过DepthwiseConv2D升维后,增加了一个关于通道的注意力机制,利用自注意力机制,可以在模型训练和预测过程中实现全局参考,最后利用1×1卷积降维后增加一个大残差边。利用残差神经网络增大神经网络的深度,通过更深的神经网络实现特征提取。
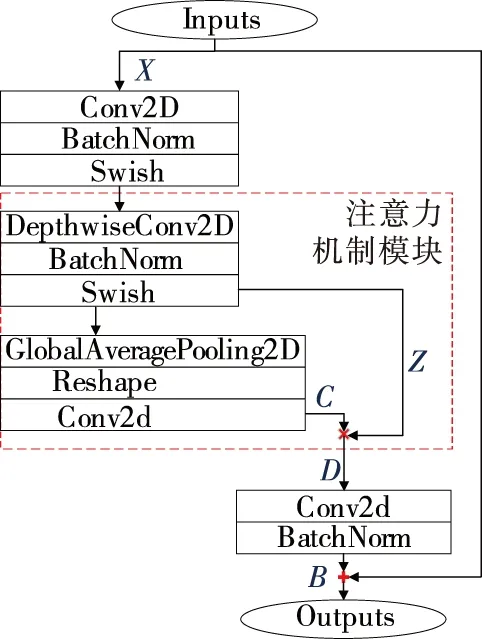
图5 文中使用模块算法流程Figure 5 This article uses module algorithm flow
D=C⊗Z,
(4)
式中:
D——经注意力机制输出的特征图;
Z——输入X经过CV2D卷积核、BN层与Swish激活等网络结构的输出;
C——以Z为输入经过如图4所示的模块化卷积、BN层的输出;
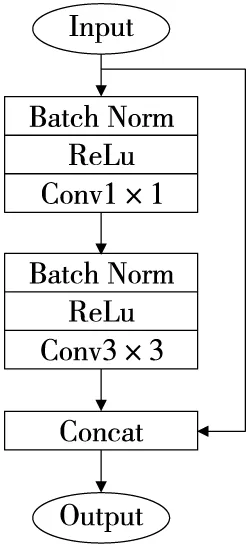
图4 Bottleneck模块算法流程Figure 4 Bottleneck module algorithm flow
⊗——矩阵元素点成。
注意力机制将特征图像(feature map)中的每个像素作为一个随机变量,计算所有像素点之间配对的协方差,根据每个预测像素在图像中与其他像素之间的相似性来增强或减弱每个预测像素的值,在训练和预测时使用相似的像素,忽略不相似的像素,其原理如式(5)~式(7)。
(5)
(6)
(7)
X、Y——随机变量;


Cov(X,Y)——随机变量X、Y的协方差。
3 试验与结果分析
3.1 数据集的采集与制作
采集设备来源中国烟草总公司职工进修学院,烟叶样本采集器如图6所示。

1.高清工业线阵数字相机 2.专业镜头 3.高显色性LED光源 4.烟叶放置平台 5.试验平台 6.滑轮 7.工作站级计算机及iPad 8.高显色性LED光源控制器图6 烟叶样本采集器Figure 6 Tobacco leaf sample collector
试验共收集到2 500张烟叶样本,经过专家挑选各个地区的代表样本,来自不同地区的42个烟叶样本等级。
烟梗数据集通过Pycharm环境下labelImg制作,其包含多类数据格式文件,样本集使用PascalVOC格式制作标签文件,主要标注信息包含烟梗的位置与部位名称。将制作好的标签文件存放到Annotations文件夹中,将样本图集存入JPEGImages文件夹中。为便于试验,将烟叶样本图像统一变更为416×416像素大小。其中250张样本作为验证集,1 575张样本图片作为训练集,675张样本作为测试集,验证集与训练集与测试集样本比例为10∶63∶27。训练集与测试集符合7∶3的比率,采用数据增强的方法提高网络的泛化能力,包括反转180°,亮度调整,图片拉伸等。
康复机器人具有不同的康复训练模式,可以适应不同患者以及患者在不同恢复阶段的不同情况。患者主动发起的模式考虑到了患者的意图和主动参与的能力,较被动模式更有效。许多的证据证明这种患者-机器人互动的模式对促进患者的恢复非常有效。机器人可以感受到患者的状态并且根据患者的不同状态进行顺应性的匹配,同时,“按需辅助”的理念在机器人辅助康复中也得到较好的贯彻,机器人只为患者提供必需的辅助以便鼓励患者得到最大程度的参与[11]。
3.2 试验配置
试验在Intel I510400f处理器,基础频率2.9 GHz,6核12线程,内存16 G,显卡为华硕的1660s的PC上,在Windows系统下利用Pycharm框架进行训练。训练所设置参数如表1所示。

表1 部分试验参数Table 1 Some experimental parameters
3.3 模型训练
从标记的样本中选取1 575张作为训练集,675张样本作测试集,改进前与改进后的模型参数统一设置,从零开始训练,将改进前与改进后的模型做对比试验,训练卷积层,全连接层与池化层根据损失函数不断自动反向调整网络结构模型参数,最后到达一个loss函数的极小值点,训练时通过Adam算法优化初始学习率,设定网络学习率的衰减因子为0.6,当网络loss函数接连两次不下降时,网络的学习率会自动调整为原来的60%,以助于网络的loss函数跳出局部最优解。改进前与改进后网络训练的loss与测试集的val_loss结果如图7~图10所示。
由图7和图9可以看出,改进前的YOLOv3的训练集的loss图像在第60次迭代后loss函数变动不大逐渐走向稳定,最终收敛于10.31,测试集的val_loss图像在经过80次迭代后逐步稳定,最终收敛于11.62。由图8和图10可以看出,改进后的YOLOv3模型的测试集loss图像在第30次迭代后逐步稳定,最终收敛于2.95,训练集的val_loss在第50次迭代后逐步稳定,最终收敛于3.162。通过试验结果对比可以得出,改进后的YOLOv3模型能更快的收敛,且收敛效果更佳。
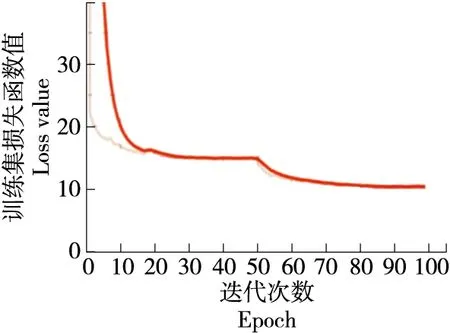
图7 传统YOLOv3 loss曲线Figure 7 Traditional YOLOv3 loss curve
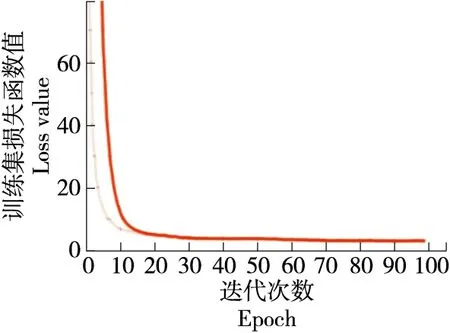
图8 改进后YOLOv3 loss曲线Figure 8 The improved YOLOv3 loss curve
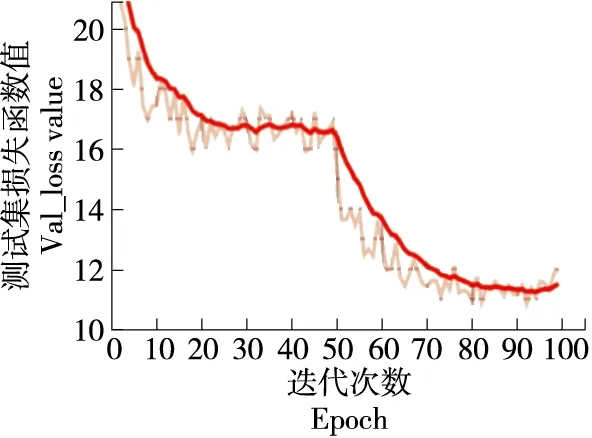
图9 传统YOLOv3 val_loss曲线Figure 9 Traditional YOLOv3 val_loss curve
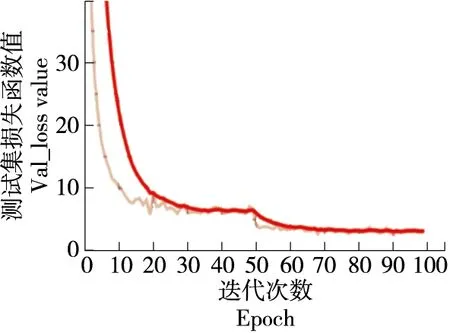
图10 改进后YOLOv3 val_loss曲线Figure 10 Improved YOLOv3 val_loss curve
3.4 模型测试与对比分析
使用同样的数据集,同样的测试集样本输入至YOLOv3、Faster-rcnn、YOLOv4、Efficientdet与文中算法中,其在经100次迭代后,输入训练模型,分别选取训练好的模型参数载入模型网络,通过准确率与召回率曲线覆盖面积的比率(mAP)、准确率(Precision)、召回率(Recall)来衡量模型结构,如式(8)所示,其值越高,网络的识别效果越好。YOLOv3与文中算法对比如图11所示,对比分析发现文中算法其mAP提升7.02%,准确率提升2.02%,回归率提升11%。
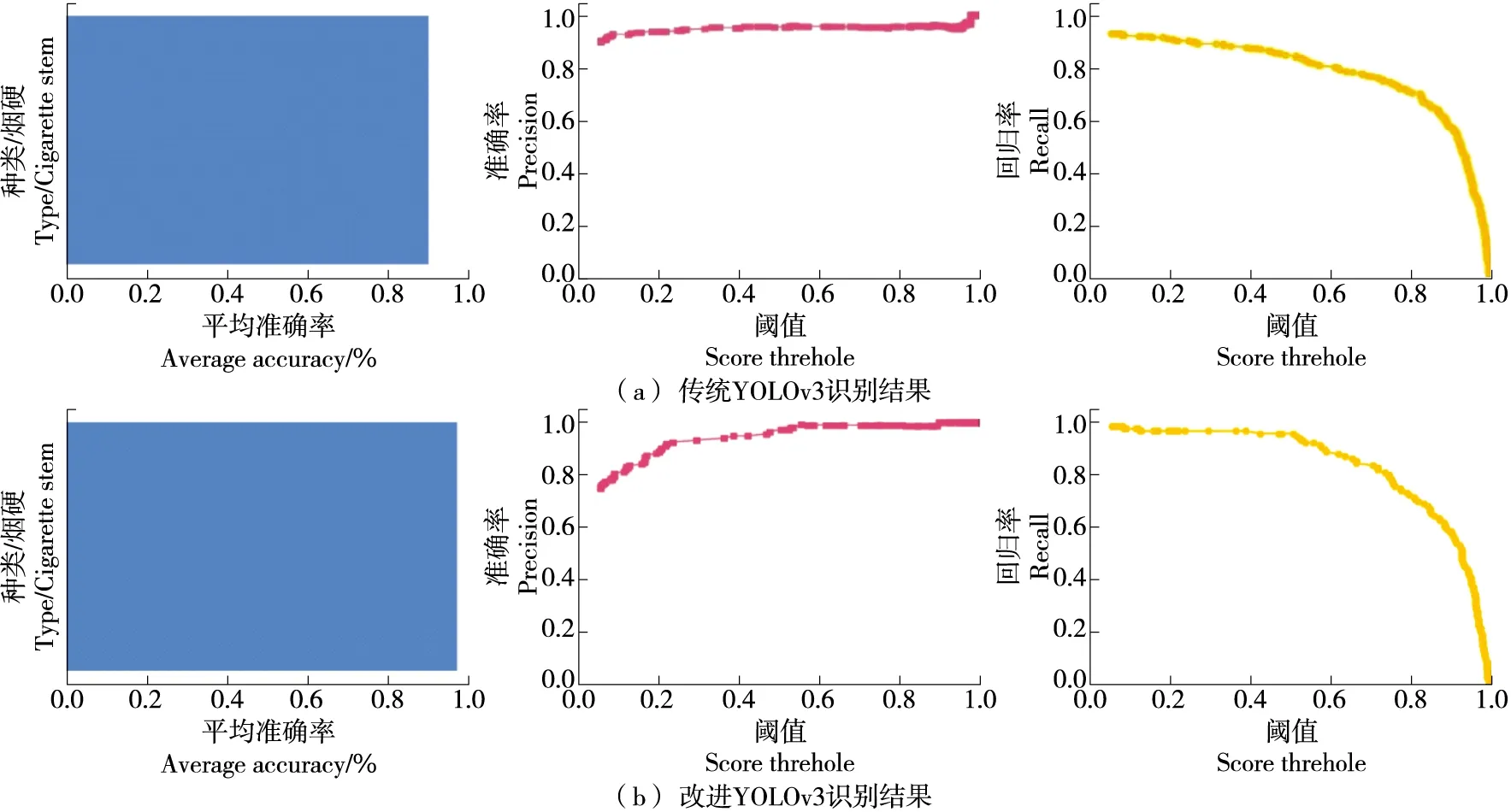
图11 传统YOLOv3与改进YOLOv3识别结果Figure 11 Traditional YOLOv3 and improved YOLOv3 recognition results
(8)
式中:
R——样本召回率,%;
P——样本准确率,%;
TP——被判为正类的正类;
FP——正类的负类;
FN——负类的正类。
测试结果如表2所示。由表2可知:在模型的识别性能上,YOLOv4与改进的YOLOv3模型的准确率与召回率曲线覆盖面积的比率(mAP)、准确率、回归率,明显优于传统YOLOv3、Faster-rcnn与Efficientdet模型;在模型权重大小上,改进后的算法与Efficientdet相对轻量化,大幅提高了网络的可移植性,减少后期工程应用中对设备的配置要求,具有一定的经济效应;在识别速率上,改进后的算法与YOLOv3、Faster-rcnn、YOLOv4、Efficientdet的识别速率(FPS)差值分别为+1、+6、+3、-1。通过表2的试验结果综合对比分析,在识别速率与模型轻量化上,Efficientdet与改进后的算法存在明显的优势,但Efficientdet的识别效果相对较差;在识别的准确度上,改进后的算法在准确度与回归值的对比中分别高出YOLOv4 1.16%,1.26%。出于工程实际的需求,复杂的网络结构需要配置性能更加优异的烟梗识别工作站,从模型的可移植性、识别速率、识别效果、工程中的经济效应来考虑,改进后的YOLOv3模型更加适用于智能烟叶分级系统的布置。
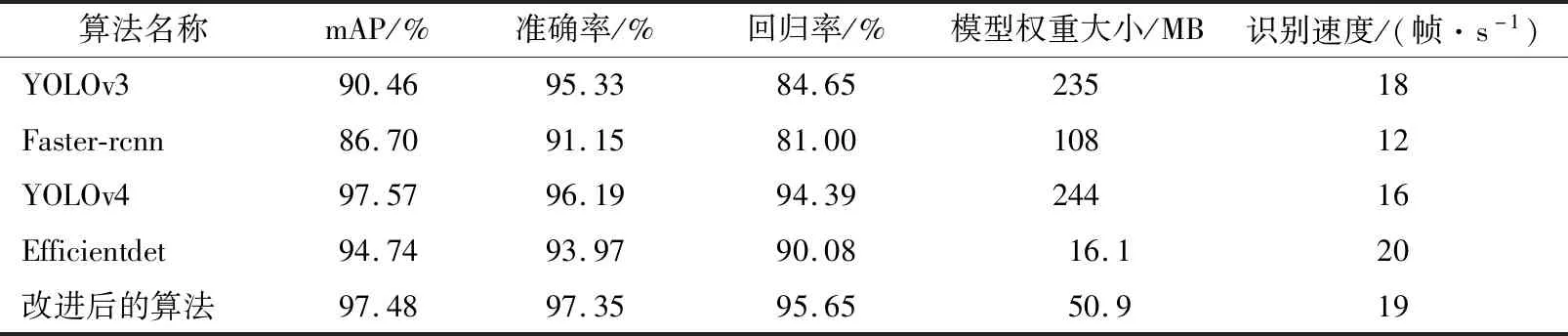
表2 烟梗识别模型对比Table 2 Comparison of tobacco stem recognition models
3.5 模型的定位识别
为方便以后烟梗的抓取工作通过BOX的坐标定位烟梗位置坐标Xmin、Ymin、Xmax、Ymax,输出烟梗的中心位置坐标Y如式(9)所示,其识别结果如图12所示。

图12 改进模型识别图Figure 12 Improved model recognition diagram
Y=[(Xmax-Xmin)/2+Xmin,(Ymax-Ymin)/2+Ymin]。
(9)
命名识别率为0.57的框图为Box1,同理识别率为0.73,0.55,0.88分别为Box2,Box3与Box4,其烟梗中心输出结果如表3所示。

表3 识别输出坐标Table 3 Identify Output Coordinates
4 结论
提出了一种改进的YOLOv3的烟梗识别定位检测算法,经专家选取代表性烟叶制作数据样本,在数据源头上提高模型的性能,训练后得到的烟梗检测模型优于YOLOv3、Faster-rcnn、YOLOv4、Efficientdet等烟梗识别定位模型,能在对智能烟叶分类平台硬件需求配置最低的基础上,满足回归率、准确率、准确率与召回率曲线覆盖面积的比率的需求,具有较好的实用性与经济性。由于不同烟叶产地烟叶样本同等级之间个体差异巨大,自主采集,制作烟叶样本数据集存在一定难度,对模型的验证实验的不同产地的样本太少,存在一定的误检率,后续工作中将提高不同产地的烟叶样本的采集,进一步提高模型的泛化能力。
