Personalized movie recommendation method based on ensemble learning①
2022-04-07YANGKunDUANYong
YANG Kun(杨 堃), DUAN Yong
(School of Information Science and Engineering,Shenyang University of Technology, Shenyang 110870, P.R.China)
Abstract Aiming at the personalized movie recommendation problem, a recommendation algorithm integrating manifold learning and ensemble learning is studied. In this work, manifold learning is used to reduce the dimension of data so that both time and space complexities of the model are mitigated.Meanwhile, gradient boosting decision tree (GBDT) is used to train the target user profile prediction model. Based on the recommendation results, Bayesian optimization algorithm is applied to optimize the recommendation model,which can effectively improve the prediction accuracy. The experimental results show that the proposed algorithm can improve the accuracy of movie recommendation.
Key Words: gradient boosting decision tree(GBDT), recommendation algorithm, manifold learning, ensemble learning, Bayesian optimization
0 Introduction
Recently, computer technology and Internet technology are constantly evolving. Internet has brought a huge amount of information and data. This aggravates the phenomenon of information overload. Although the resources for users to select increase, it is difficult to obtain effective information from a large amount of data. Therefore, improving the efficiency of information utilization is a critical issue in the development of contemporary Internet. At present, there are many ways to filter information. However, these methods can only meet the mainstream demands of users without considering personalizations. Therefore, the problem of information overload has not been well solved. On the other hand, as an effective way of data screening, the problem of information overload can be solved through personalized recommendations[1-2].
Collaborative filtering and the content-based recommendation are algorithms widely studied. The term‘collaborative filtering’ was first proposed in Ref.[3].The content-based recommendation algorithm uses attribute characteristics to build model. It is based on the feature data of the items that users like. It learns from user profiles, matches features of user profiles to attribute features of items and finally carries out personalized recommendation for users. In 2017,Ref.[4] proposed interest points recommendation algorithm considering real-time traffic information. The algorithm fused user interest points and real-time traffic support to form the final recommendation result. Ref.[5] used multi-attribute networks and clustering technology to form one content-based multi-attribute network recommendation algorithm. It alleviated sparse data problem in some degree. In 2018, Ref.[6] proposed a new contentbased film recommendation algorithm. This algorithm solved the problems of inaccurate content similarity calculation and user profiles changing with time in content-based recommendation algorithm. This algorithm fused film review content similarity and long-short-term interest model to calculate film similarity. Different recommendation algorithms are combined to form a hybrid recommendation algorithm recently. Ref.[7] proposed a hybrid recommendation algorithm combining user clustering and rating profiles. Ref.[7] used data mining knowledge and collaborative filtering algorithm.
It is a trend to apply machine learning in the field of recommendation algorithm. Ref.[8] proposed a support vector machine(SVM) collaborative filtering topNrecommendation algorithm. This algorithm was based on positive and negative feedbacks. Ref.[9]proposed a collaborative filtering algorithm combining user profiles classification and dynamic time. This algorithm was based on decision tree classification technology. Ref.[10] used BP neural network technology.This algorithm alleviated the sparsity problem.Ref.[11] studied collaborative filtering algorithm based on Bayesian network technology. There are many researchers who use ensemble learning to study recommendation algorithm. Ref.[12] proposed a multi-agent framework algorithm based on decision tree technology.In 2020, Ref.[13] proposed a recommendation algorithm by training a single network in a set and integrating it into the same learning. Personalized recommendation algorithm based on ensemble learning has become one of the hot spots in the field of recommendation.
The content-based recommendation algorithm needs thorough content analysis. In the era of large data,there are a lot of connections between users and items.The algorithm needs rich item content description and complete user profiles before recommending. Using a single weak learners for content analysis is often not thorough enough and the accuracy is low since the stability of the model is poor with insufficient user experience.
A content-based personalized recommendation method based on ensemble learning is studied to solve these problems. Ensemble learning constructs multiple weak learners to generate recommendation model iteratively.The model can accurately predict the user behavior.Besides,ensemble learning can flexibly process various types of data. It has robust loss function. And it can more effectively obtain the potential user behavior information. The recommendation model based on ensemble learning has higher prediction accuracy and more stable performance.
Based on the movie data set, this paper studies personalized recommendation method. It predicts the user profile according to user behavior information and movie attribute information. It predicts essentially users ratings of movies. Then it sort the ratings. Finally, it recommends movies with high ratings to users. This study uses ensemble learning to build the personalized movie recommendation model. It uses manifold learning to reduce dimension processing. Based on this, a personalized recommendation model having manifold learning and ensemble learning fused is built. Bayesian parameter optimization method is used to further optimize the model and improve its accuracy.
1 Personalized movie recommendation method based on ensemble learning
1.1 Movie recommendation problem description
Personalized recommendation is the process of recommending items to users according to their profiles. Movie recommendation is to predict the user’s degree of preference in unknown movies according to user’s demographic information and movie information rating information. Then it will recommend movies that interest users. The higher the rating,the higher the user’s preference in the movie.Based on this, this paper uses ensemble learning to build a personalized movie recommendation model.Firstly, user-movie associated data is trained. Then,the user rating prediction model is built and this model is sorted according to the prediction. Finally, the movies with high rating are recommended to users. Meanwhile, the user’s recommendation list is obtained. It can be seen that the personalized recommendation problem is to predict the user’s rating of an unknown movie. The accuracy of the predicted rating determines the accuracy of the recommendation.
1.2 Personalized movie recommendation method based on ensemble learning
Based on the study of content-based recommendation algorithm, this paper studies the content-based recommendation algorithm based on ensemble learning.The movie recommendation method based on ensemble learning integrates the prediction results of multiple weak rating prediction learners to form a strong rating prediction model. This method does not only refer to a single rating prediction algorithm, but also applies the idea of fusing multiple weak learners to form a strong learner. Furthermore, on the eve of model building,manifold learning dimension reduction method is selected to reduce the data storage cost and time and space complexities of the model. At the same time, Bayesian optimization method is used to optimize the model parameters in the process of using this method to train the model, and finally a rating prediction model with high prediction accuracy is built. This method can not only avoid over-fitting, but also improve the generalization and stability of the model and achieve better recommendation performance. The overall process of this study is shown in Fig.1.
1.2.1 Feature engineering Feature engineering is to select better data features from the original data by a series of engineering methods. The aim is to improve the training effect of the model. Feature engineering includes data preprocessing and data dimension reduction in the proposal of this paper.(1) Data preprocessing Before modeling, method in this paper preprocesses the data, which includes data association, data format transformation, feature construction and normalization processing. Rating data, user feature data and movie feature data are associated to obtain the ‘usermovie’ association data. After processing, the method used in this paper analyzes data types and transforms them into types of data that ensemble learning can handle.

Fig.1 Overall flow chart
Through the analysis, the same movie can be classified into multiple movie types at the same time,and the same movie type contains multiple movies.This paper uses One-Hot encoding to encode movie types and extends them to multiple columns.

where,viis the original value of the data sample,medianis the median of the data sample,IQRis the quartile distance of the data sample.
(2) Data dimension reduction
In this paper, manifold learning is used to reduce dimension. It can effectively shorten the training time.And it can improve and optimize training results. Locally preserving projection (LPP) is a manifold learning dimension reduction method. It preserves the spatial relationship between the distant and near intimate sample pairs in projection mapping.
LPP algorithm is used to solve the eigenvalue problem of sparse matrix to find the global optimal solution analytically. At the same time, LPP algorithm makes the points close to each other in the high space and also close to each other in the low dimensional space. This algorithm has high efficiency and the lowest loss of information.
The data set used in this paper contains multiple rating data information, movie data information and user attribute information for multiple movies, which belong to nonlinear data. Manifold learning can deal with this part of data well and is more suitable for the problems to be solved in this paper. LPP method is to construct the affinity-disaffinity relationship between the sample pairs in the space, and maintain this relationship in the projection, so as to reduce the dimension and preserve the local neighborhood structure of the samples in the space. This method builds a graph containing neighborhood information of data set, and calculates a transformation matrix that maps data points to subspace by using the concept of Laplace transformation of graph. This linear transformation preserves local neighborhood information optimally in a certain sense.The representation map generated by the algorithm can be regarded as a linear discrete approximation of the naturally generated continuous map of manifold geometric properties. When the high-dimensional data is located on the low dimensional manifold embedded in the ambient space, the local preserving projection is obtained by finding the optimal feature approximation of the characteristic function of Laplace Beltrami operator. Therefore, compared with other dimensionality reduction methods, LPP has many nonlinear techniques such as Laplacian eigenmaps or locally linear embedding, which can not only transform data more accurately, but also have higher conversion efficiency. But at the same time, this method can’t preserve the global geometry of manifold effectively.
In this study, the high dimension user-movie data is projected to the low dimension. And the relationship with the original space location is consistent. Suppose that the user-movie data sample in the original space is(age, title, occupation...). The corresponding points in lower dimension space are defined asY=(y1,y2,y3...). And suppose the data in the original sample space isX=(x1,x2,x3...),then position relationship betweenXandYis consistent after dimension reduction.

where,Dis a diagonal matrix, the values of the elements on the diagonal are the sum of the rows (or columns) of the adjacency matrixW,Lis a Laplacian matrix.
Suppose that the solution of Eq.(4) isa0,a1,…,al-1. Their corresponding eigenvalues are sorted from small to large. The projected transformation matrix is
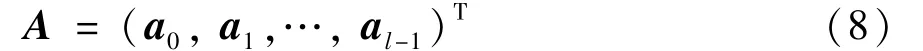
1.2.2 Build the user-movie rating prediction model
Personalized movie recommendation is to predict the user profile for the movie and then recommend it.In this paper, GBDT method is used to train the rating prediction model. Since GBDT method is suitable for low dimensional data, the original data is firstly processed by feature construction and dimension reduction, which effectively reduces the time and space complexity of the model at the data level. And on the basis of no loss of information, reducing data dimension can be more conducive to model learning, reduce model training time, improve model learning performance and effect. Finally, the preprocessed data is used as the input of the model, and the GBDT method is used to establish the movie personalized recommendation model. Then the obtained data is used as the input of the model. The GBDT method is used to build the personalized movie recommendation model, which is used to predict user ratings.
GBDT is an iterative decision tree rating prediction method, which has the ability of automatic combination of features and high efficiency. GBDT can deal with non-linear data and various types of data flexibly,including continuous values such as user activity and discrete values such as user age. GBDT method is through multiple iterations, each iteration produces a decision tree, and each decision tree is trained on the basis of the residual error of the previous round of decision tree, so the prediction accuracy of GBDT method is higher. In addition, GBDT has robust loss function,and the model trained by this method has the advantages of better stability, stronger robustness and higher accuracy. Based on this, GBDT method is used to train the rating prediction model.
This paper builds the user rating prediction model for the movie based on GBDT. And it uses multiple rounds of iterative decision tree. Then each iteration produces a weak learner. Each weak learner is trained on the basis of the rating residual of the previous round. Finally, a strong learner is got.
It is assumed thatft(x) represents the rating prediction learner of thet-th round.ht(x) represents thet-th score prediction decision tree. The formula which defines rating prediction model based on GBDT is

The iterations will be continued until the loss function converges. The method of gradient boosting is used to integrate multiple rating prediction decision trees. The problem of over fitting can be solved effectively.
1.2.3 Model optimization

Grid-search finds the most suitable parameter combination from all. It gets the best parameter based on the global characteristics. However, when the data set is large and there are many parameters, the grid search needs a lot of time. Greedy algorithm selects the optimal solution at each step. However, the global features are not fully considered. Bayesian optimization algorithm has significant effect in dealing with the input characteristic variables and numerical variables of categories, which can better solve the problems existing in the above two methods. Based on this, this paper uses Bayesian optimization method to optimize the hyper parameter of the rating prediction model based on GBDT,so as to improve the recommendation accuracy and performance of the model.
The process of Bayesian optimization of GBDT model is as follows. Firstly, the acquisition function is constructed based on the past evaluation value of the objective function. The objective function is defined as that the function input is all the hyper parameters of GBDT, and the output is the negative mean absolute error(MAE) value of the model after 5-fold cross validation. The hyper parameter combination of the next GBDT is calculated by the acquisition function; Then,GBDT selects the given hyper parameter combination for training, and calculates the MAE value ; Finally,the hyper parameter combination of maximizing the objective function is found by cyclic iteration.
Bayesian optimization algorithm is used to optimize the GBDT ranting prediction model. This algorithm is based on the past evaluation value of the objective function to construct the acquisition function.Finally, the parameter values of the minimization objective function are found. Suppose that the range of parameters to be optimized in GBDT rating prediction model isX=(x1,x2,x3,…,xn). The inputs of the objective functionfare all the parameters of GBDT.The output offis the MAE value of 5-fold cross validation of the rating prediction model. The process of Bayesian optimization of GBDT rating prediction model is shown as Algorithm 1.

Algorithm 1 Bayesian optimization GBDT Input: f: objective function X: parameter search space S: acquisition aunction GBDT rating prediction model Output:xj←max(f)1.Initialize dataset D =(x1, y1),…,(xn, yn),where yi =f(xi);2.The GBDT rating prediction model uses the selected parameter combination xi for training, calculate f(xi);3.Use the acquisition function to calculate the next parameter combination to the parameter xi+1;4.Repeat steps 2 and 3 for T iterations.
2 Experimental results and analysis
In this paper, the experimental process first carries out data preprocessing, including data association,data format conversion, feature construction and data normalization. Then manifold learning is used to reduce the dimension of the data, and GBDT method is used to build the personalized movie recommendation model. Finally, Bayesian optimization algorithm is used to optimize the model.
MovieLens dataset has been used by the majority of researchers. It is the most classic dataset in the recommended research field. In this experiment, MovieLens 1 M dataset was used. The dataset contains rating data from more than 6000 users, more than 3900 movies and more than 1 million ratings.Each user evaluates at least 20 movies. Ratings are integers between 1 and 5. The higher the rating, the higher the user’s preference for the movie. This dataset contains the movie category, user occupation, gender, age and other feature data.
In this paper, thek-fold cross validation method is used to verify the performance of the model.k-fold cross validation first splits all data intoksubsamples,selects one of them as test set without repeating, and otherk-1 samples are used for training. A total ofktimes are repeated, and the results of averagektimes obtain a single estimation. In order to select optimumk, it must be weighed between deviation and variance.Ifkis small, a large deviation will be obtained in estimating the test error, but the variance will be small; If thekis larger, the deviation will be smaller and the variance will be larger.
The estimation of the average prediction error by cross validation is related to the amount of data. If the sample data is small, the data set will be smaller after the data is segmented by cross validation, which will easily lead to large estimation deviation. Therefore, in general, if the sample data is sufficient, 5-fold cross validation is a better choice[14]. The MovieLens dataset used in this paper has sufficient sample data, so this paper finally selects the 5-fold cross validation method to evaluate the prediction error of the algorithm and verify the model performance.
In this experiment, the user-movie association data is obtained after feature engineering. A personalized recommendation model based on GBDT is built. The performance of the model was verified by 5-fold cross validation. MAE was used to evaluate the model. MAE reflects the actual situation of prediction error. Low MAE value means low prediction error and better prediction result. MAE is defined as

here,ois the user’s observation value of the movie rating,pis the predicted value of the user’s score on the movie.
In the experiment, in order to verify the superiority of the model, this paper chooses linear regression,decision tree regression, random forest regression and multi-layer perceptron regression as the comparison models. At the same time, it is compared with the traditional collaborative filtering algorithms, including user-based collaborative filtering (UserCF) and itembased collaborative filtering (ItemCF). The MAE of each movie rating prediction model obtained is shown in Fig.2. The experimental results show that the prediction error of the rating prediction model constructed by machine learning method is obviously lower than that of UserCF and ItemCF. At the same time, it can be seen that the GBDT method of ensemble learning in machine learning method is better, and the error in solving the prediction of movie rating is smaller. The accuracy of model is higher, and the accuracy of movie recommendation to users according to the rating is higher, and the recommendation performance is better.

Fig.2 Model comparison of MAE results

Fig.3 Comparison results of LPP methods
In order to verify the effectiveness of manifold learning dimension reduction, the original dimension data are tested under the proportion of 25%, 50%, 75% and 100%. The experimental results are shown in Fig.3. It is clear that the data error after dimension reduction is higher. The reason is that the data dimension reduction will bring loss to the original data features. By increasing model training times, data information can be mined at a deeper level.
Then, it further verifies the superiority of the reduced dimension data in error,and still use the method of dimension partition in the previous experiment. By increasing the number of model training, the experimental error results are recorded. Fig.4 shows the experimental results. As can be seen from the figure, the prediction error of the model in the previous stage is relatively high. However, with the increasing model training times, it can be seen that the prediction error of the model is gradually reduced. The error of 50%and 75% is the smallest. Therefore, data dimension reduction can improve the accuracy of recommendation.
In this experiment, the dimension is reduced to 75% of the original one. In order to verify the superiority of Bayesian optimization algorithm, grid-search method and baseline are selected for comparison. The experimental results are shown in Fig.5. It can be seen from Fig.5 that both grid search and Bayesian optimization can optimize the model performance to a certain extent and reduce the prediction error. And MAE is reduced by about 0.04 by using the grid-search method compared with the baseline. The error is reduced by about 0.08 after Bayesian optimization. Therefore,Bayesian optimization rating prediction model improves the accuracy of the model.

Fig.4 Experimental results of different numbers of weak classifiers

Fig.5 Comparison of parameter optimization results
In a word, the recommendation algorithm which fused manifold learning and ensemble learning improves the accuracy of recommendation after the dimension reduction and model optimization of manifold learning.
3 Conclusion
This paper has made full use of item information,user information and user behavior information. And it trains the user-item association feature data to build the scoring prediction model. Then the user’s interest can be obtained. Compared with the traditional collaborative filtering algorithm and content-based recommendation algorithm, this study not only improves the accuracy of rating prediction, but also improves the efficiency of information utilization. Manifold learning LPP algorithm is used to reduce the dimension of data. In addition to reducing the complexity of the model, its generalization and robustness are also improved. GBDT algorithm is used to build the rating prediction model,and compared with linear regression, decision tree regression, random forest regression and multi-layer perceptron regression model in order to verify the superiority of the personalized recommendation model based on GBDT. Bayesian optimization method is used to optimize the GBDT model, which further improves the accuracy of the prediction.
杂志排行

High Technology Letters的其它文章
- Deep convolutional adversarial graph autoencoder using positive pointwise mutual information for graph embedding①
- A joint optimization scheme of resource allocation in downlink NOMA with statistical channel state information①
- An improved micro-expression recognition algorithm of 3D convolutional neural network①
- Resonance analysis of single DOF parameter-varying system of magnetic-liquid double suspension bearing①
- Computation offloading and resource allocation for UAV-assisted IoT based on blockchain and mobile edge computing①
- A load balance optimization framework for sharded-blockchain enabled Internet of Things①