Smoother manifold for graph meta-learning①
2022-04-07ZHAOWencang赵文仓WANGChunxinXUChangkai
ZHAO Wencang (赵文仓), WANG Chunxin, XU Changkai
(College of Automation and Electronic Engineering, Qingdao University of Science and Technology, Qingdao 266061, P.R.China)
Abstract Meta-learning provides a framework for the possibility of mimicking artificial intelligence. However, data distribution of the training set fails to be consistent with the one of the testing set as the limited domain differences among them. These factors often result in poor generalization in existing meta-learning models. In this work, a novel smoother manifold for graph meta-learning (SGML) is proposed, which derives the similarity parameters of node features from the relationship between nodes and edges in the graph structure, and then utilizes the similarity parameters to yield smoother manifold through embedded propagation module. Smoother manifold can naturally filter out noise from the most important components when generalizing the local mapping relationship to the global.Besides suiting for generalizing on unseen low data issues,the framework is capable to easily perform transductive inference. Experimental results on MiniImageNet and TieredImageNet consistently show that applying SGML to supervised and semi-supervised classification can improve the performance in reducing the noise of domain shift representation.
Key words: meta-learning, smoother manifold, similarity parameter, graph structure
0 Introduction
The difference between human intelligence and artificial intelligence is that humans can learn quickly and accurately from a small number of examples, because humans have the ability to learn from prior knowledge[1]. In contrast, traditional deep learning has made tremendous progress in various fields, such as image classification[2-3], object detection[4-5]and image semantic segmentation[6-7]. However, the strong deep learning algorithm heavily relies on a lot of labeled data. The human label cost and the scarcity of some classes tremendously limit the further development of deep learning. Just as humans can use the previous background and knowledge to effectively learn new knowledge, artificial intelligence algorithms also need to learn quickly and efficiently to contain new and invisible information. So meta-learning has aroused strong interest in various fields, especially few-shot learning[8-10], learn to learn[11-12]and continual learning[13-14]. This work focuses on few-shot learning,which aims to identify novel categories with very few labeled examples.
A key challenge of meta-learning is inference ability, inferring the new data representation by the efficient and fast neural network based on training. Because the operation of few-shot learning needs to make full use of the information in the dataset, especially it is sensitive to the slight change of data distribution,and graph neural network (GNN) can perform neighborhood feature aggregation iteratively to express the complex interaction between data instances[15]. Therefore, the research on solving few-shot learning with GNN has attracted more and more attention in related fields. For example, Ref.[16] obtained the prior knowledge of classifier by training similar few-shot learning tasks. Ref.[17] proposed a model based on node labeling framework to obtain node classification tasks. In addition, there are a large number of literatures containing regularization techniques, such as dropout[18], batch normalization[19], and manifold mixup[20-21], which analyzed the generalization capability.
This paper tries to use simple smoother manifold combined with GNN to address the few-shot classification problem. A method called smoother manifold for graph meta-learning (SGML) is proposed. Specifically, it is believed that the similarity of node features can be obtained by iteratively updating node features and edge features in the graph network, then map them to the embedded propagation network to obtain a set of interpolation features, and then the image is labeled by the classifier. The embedded propagation network can increase the smoothness of the embedded manifold.
1 Related works
Because GNN is extremely powerful in modeling the dependencies between nodes, some revolutionary breakthroughs have been made in the study of graph structure. Refs[22,23] combined graph node characteristics with graph topology to classify graph nodes.On this basis, Ref.[24] proposed an edge-labeling graph neural network (EGNN) to make full use of edge information, which solves the problem that graph convolutional network (GCN) can only handle one-dimensional edge features and that noise with original adjacency matrix in graph attention network (GAT) model may not be optimal. However, combining graph structure and few-shot learning are still unnoticed, and there are few unreliable solutions to classify for unknown categories with only a small amount of data.Ref.[25] proposed a label-based propagation transmit network, built an undirected graph containing both unlabeled data and labeled data, and obtained labels of all unlabeled data by means of label propagation. By learning to predict edge labels, the network can explore the direct connection state by using intra-cluster dissimilarity and inter-cluster similarity. By iteratively updating edge labels, the clustering representation can be advanced and the classification performance can be improved by combining with transductive propagation network (TPN). This approach is used to construct the network by using the relationship between edges and nodes.
When constructing machine learning, if a mess of complex neural network area is used to fit the data, it is easy to cause over-fitting, which will cause the generalization ability of the model to decline. At this time,regularization is needed. The absence of the free lunch theorem has clearly show that there is no optimal regularization method, and a more appropriate regularization can only be chosen from different tasks. Ref.[26]proposed the thought of batch normalization expression,which is more universal and can solve problems such as slow training, gradient disappearance and gradient explosion caused by inconsistent distribution. Ref.[27]showed that self-supervised technology can fully exert the advantages of manifold, especially when used with manifold mixup, it can significantly improve the fewshot learning performance. Ref.[21] proposed the embedding propagation network (EPNet) utilizing embedded interpolation to capture high-order feature interactions, so as to use manifold smoothing to solve the problem of poor generalization ability caused by different data set distribution in few-shot learning. This work tries to combine this manifold smoothing with GNN and achieves unexpected results.
Semi-supervised learning and transductive learning are similar to the core ideas of meta-learning, so they are widely used in this field. The former enables learners to use unlabeled samples to improve their learning performance without relying on external interaction, while the latter can train specific training samples to predict the samples to be determined. Semi-supervised learning is applied in few-shot learning in order to improve classification performance through adding unlabeled data. Three ProtoNets semi-supervised variants were proposed based on k-means method, which adjusted clustering information by using a large amount of unlabeled data[28]. Based on this,Ref.[29] proposed a meta-learned cherry-picking method which based on the self-training and meta gradient descent method without redesigning the semi-supervised network. Experiments have proved that transductive learning achieves better performance than inductive learning in the few-shot classification task[30].They proposed a transduction network for a meta-learning framework that uses feature embedding, graph construction, label propagation and the four steps of loss calculation realizing end-to-end learning. Furthermore,the meta-learned confidence transduction (MCT) was proposed in Ref.[31] in order to update the confidence weighted average of all supporting samples and query samples of each prototype class and perform meta-learning on the parameters of distance measurement to improve the performance of transduction inference.The transduction learning method is applied to the framework to improve performance and improve semisupervised learning results.
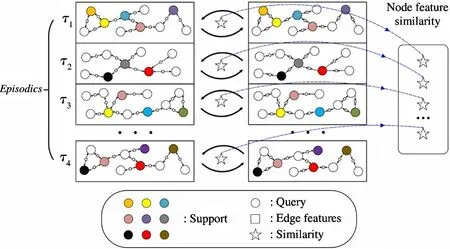
Fig.1 Extract similarity from mutually updated node and edge features
As shown in Fig.1,theLiterations update of node features and edge features is completed in each episodes, and then the similarity features between the two nodes are extracted as the input of the next stage.
2 Method
In this section, the few-shot classification task is defined and the proposed smoother manifold for graph meta-learning is described. Firstly, the node features are initialized by using feature extractor for inputting images and edge features. Then, node feature transformation network and edge feature transformation network are adopted to update each other with new node features and edge features, and get the similarity between nodes. Finally, the similarity is input into the embedding propagation module to map the features to a set of interpolated features and into the label propagation module to get logit value for each query examples of the class.
2.1 Problem definition
Episodic training is utilized to complete classification taskT, whereTincludes a support setSwith labeled samples (ksamples per class), and a query setQwith unlabeled samples (qsamples per class). And query set does not contain the samples of support set i.e.S∩N=Ø.
More specifically, the training and testing tasks forn-wayk-shot problems are as follows.T=S∪V∪
Q,S= {(xi,yi)}n×k i=1,wherexiandyi∈{C1,…,CN}=CT∈Care theith input image and its label.Q={(xj,yj)}n×k+tj=1are thejth input image and its label,trepresents the number of samples from the query set.AlthoughSandQare uniformly sampled from the dataset, they do not included in each other, i.e.S∩Q=Ø. The samples in the verification datasetVintersect with neitherSnorQ,but are only used for hyperparameter search.In each episode,the training model is optimized in the support setQwith the labels,and then the loss of the model is predicted in the query setQ.The training program iterates until the convergence according to the given episodes.
2.2 Model
This section describes the SGML framework for the few shot classification. Firstly, the convolutional neural network is used to extract the feature representation of the input image to construct the full connection graphG= (P,W;M),nodes and edges represent samples and types of relationships between samples, respectively,whereMrepresents amount of samples task.P:= {Pi}i=1,…,|M|andW:= {Eij}i,j=1,…,|M|respectively represent nodes set and edges set, wherepiis the node feature ofPiandeijis the edge feature ofEij.Then apply the obtained similarity between the nodes in the embedded propagation matrix and the label propagation matrix and finally use the classifier to obtain the loss.

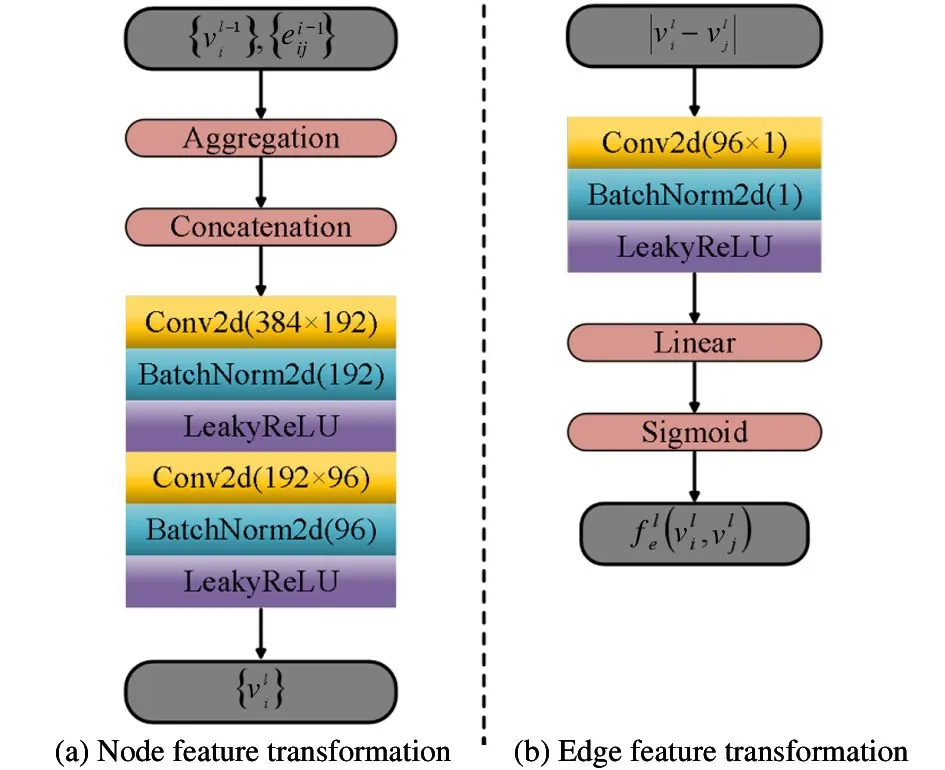
Fig.2 Detailed network structure of feature transformation



Algorithm 1 Framework of SGML 1 Input:T = S ∪V ∪Q,where S = {(xi, yi)}n×k i=1, Q ={(xj, yj)}n×k+t j=1 .2 Initialize:v0 i = fθ{xi}, e0 ij by Eq.(1).3 For l = 1,…,L do:4 vL i =NodeUpdate{vL-1 i , eL-1 ij } by Eq.(3);5 eL ij,zL = EdgeUpdate{vL-1 i ,eL-1 ij }by Eq.(4) and Eq.(5).6 End 7 ~zi =propagation module{zL,θe} by Eq.(5), Eq.(6),Eq.(7) and Eq.(8),where θe is the is corresponding parameter sets.8 Pre-training phase:9 Predict the class labels of examples in support set S by Eq.(10), Eq.(11) and Eq.(12).10 Output:argmin∑∑(Lc + Lr).11 Episodic learning phase:12 Learn to inference unseen classes by Eq.(13),Eq.(14), Eq.(15) and Eq.(16).13 Output:argmin∑∑(LP + 1 2 LC).
3 Experiments
This section mainly describes the experimental results on two commonly used datasets, MiniImageNet and TieredImageNet.
3.1 Datasets
MiniImageNet is one of the most commonly used few-shot classification datasets proposed by Ref.[33].Total of 100 categories, each category has 600 images,all in RGB color, adjusted to 84 ×84 pixels. Divide it into three (64,16 and 20) disjoint parts for training,verification and testing.
TieredImageNet is a subset of the alternative imagenet dataset that has a larger number of images than MiniImageNet[34]. There are a total of 608 categories(all sampled from the 34 high-level categories in imagenet), all RGB colors, adjusted to 84 ×84 pixels. It is divided into 351(20 high-level categories), 97(6 high-level categories), and 160(8 high-level categories) groups for training, verification, and testing.
3.2 Experimental setting
Baseline methods For feature extractors module,two common convolutional neural networks are used.One is a basic embedding network Conv-4 (Fig.3(a)),the other one is a much more complicated network Res-Net-12 (Fig.3(b)).
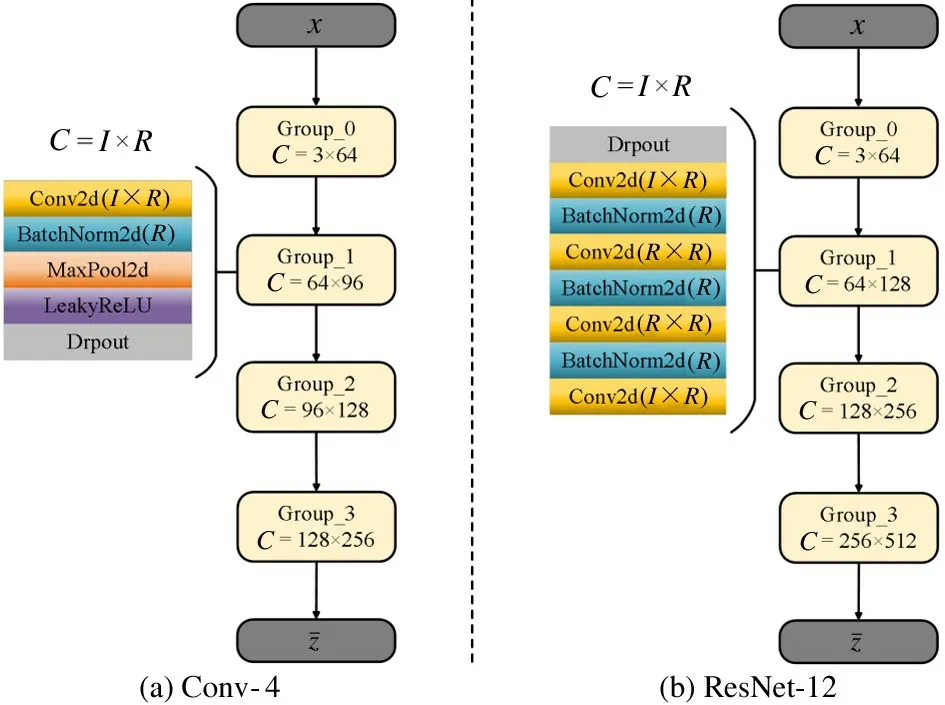
Fig.3 Detailed network structure of feature extractors= fθ(xi)
Implementation details To verify the accuracy of the implementation on these two datasets, 5-way 1-shot and 5-way 5-shot experiment will be conducted.To assess the fairness of the experiment,15 query images will be selected from each class for 5-way 1-shot and 5-way 5-shot in each episode. The proposed SGML model is optimized using SGD with initial learning rate of 5 ×10-4and weight decay of 10-1.For MiniImageNet, the model iterated 100 epochs in total, and the batch size of the meta-training task is set to 60. For TieredImageNet, because it is a larger dataset, more iterations are needed to better converge. The model iterated 150 epochs and the batch size of the task is set to 40. All of the experiments were carried out in Pytorch and run with two NVIDIA GTX 1080Ti GPUs.
Few-shot classification The proposed SGML with the latest meta-learning model are compared in Table 1.In which, all models are tested by using transductive and non-transductive settings; T means transductive setting, where it classifies all query samples at once at a single episode; F means non-transductive setting,where it performs the query inference one by one. Notably, almost all the transductive settings improve the performance of SGML. Furthermore, in the transductive setting, SGML performed better than EGNN[15]with 50 parameters, which only classifies the results by predicting edge labels. Likewise, since TPN[25]has fixed node features during the label propagation process, its label propagation equation requires additional parameters. On the contrary, the node features and edge features are adopted to the given task in the process of mutual update. The accuracy of model-agnostic meta-learning (MAML)[35]has been greatly improved after transduction, but it is still insufficient compared with other models. It can be guessed that because MAML is prone to overfitting when processing high-dimensional data, SGML is better for this problem. MetaOpt[8]increases the amount of calculation to improve the generalization ability under high-dimensional embedding, which is inconsistent with the ideas of this work. Different from EPNet[21], this work uses graph network to generate smoother embedding manifold, SGML network architecture is bigger and the effect is better. It is worth mentioning that the worst experimental results of SGML will not lag behind the reported performance by more than 1. 5% (74. 88%vs. 76.37%).
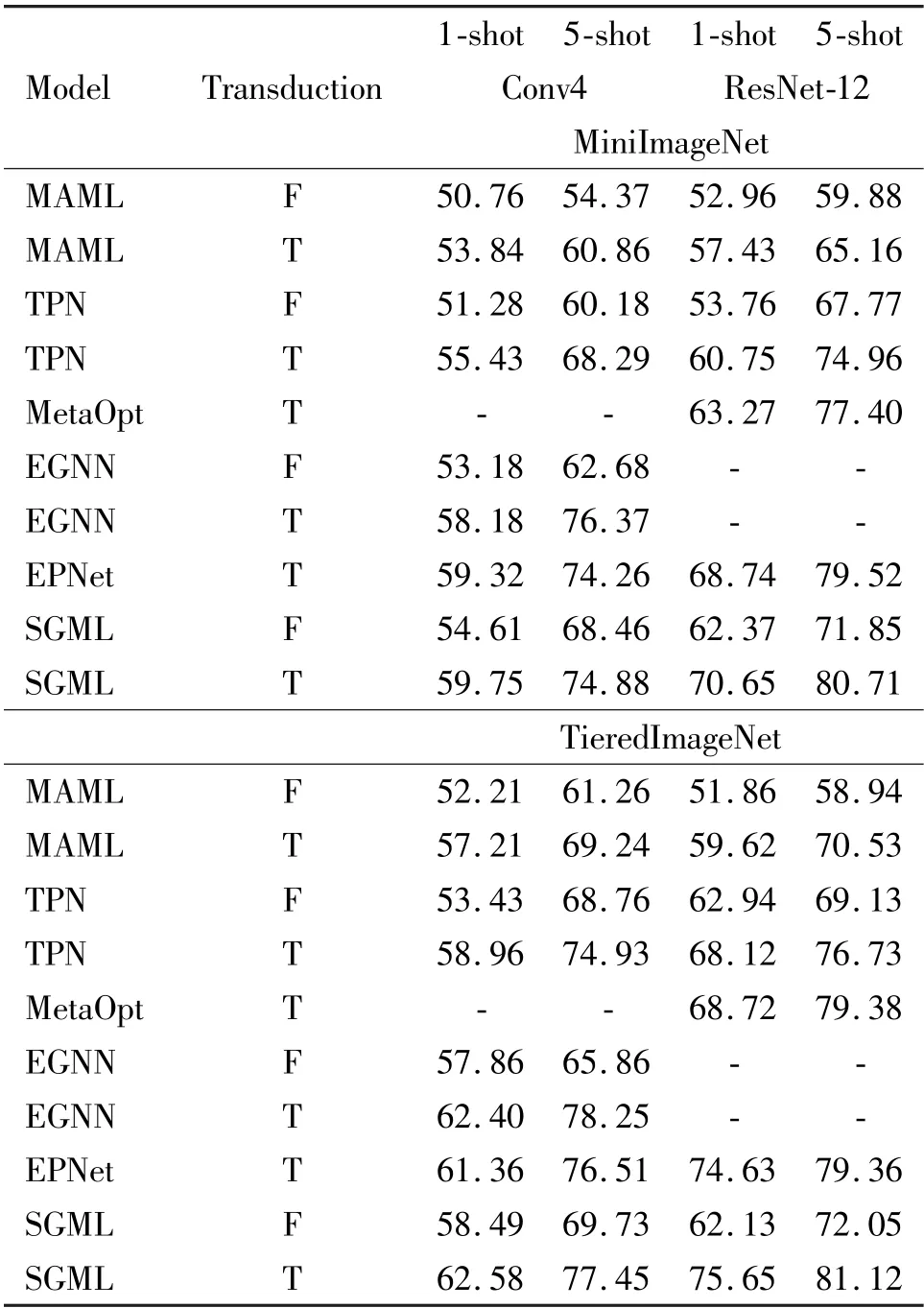
Table 1 Classification results in 5-way setting
Semi-supervised classification This work conducts a fair comparison with the same settings in the 5-way 5-shot experiment, that is, all classes in the support set samples are labeled with the same number. In order to fully demonstrate the effectiveness of the proposed method, this work conducts experiments on MiniImageNet and TieredImageNet datasets with Conv-4.The experimental results are shown in Table 2. SGML can increase the maximum accuracy by 2.81% on MiniImageNet (66. 84% vs. 64. 03%, when 60% labeled) and up to 4.89% on TieredImageNet (72.41%vs. 67.52%, when 60% labeled). It is worth noting that SGML performs the worst at 20% labeled,and only has a 0.18% improvement at 40% labeled (64.50%vs. 64.32%). It can be assumed that better accuracy may be achieved with Resnet-12, which will be studied in future work.
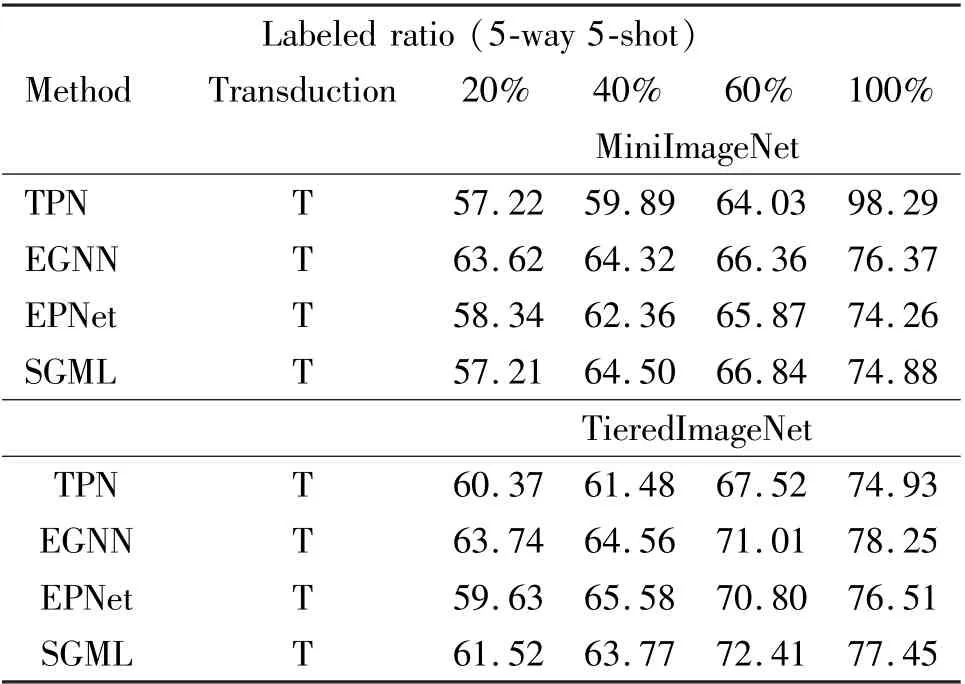
Table 2 Semi-supervised results for Conv-4
Visualization Fig.4 shows the effect of embedding manifolds. In Fig.4(a), all the samples are scattered in the characteristic space, with different colors representing different classes. In the pre-training stage, all samples were classified. As shown in Fig.4,different categories are distributed in different circles,and the classification boundary is relatively obvious.The density of nodes also shows that the relationship between nodes in the feature space is complex and interactive. In the next stage, the sample interaction is spread more intensively, the relationship between nodes is more complex, the density and smoothness of the decision boundary are also increased,and the noise representation of the previous stage is reduced(the noise may cause missing manifolds, which may affect the embedding result in severe cases). GNN is a deep architecture composed of several nodes and edges. To validate the idea that interaction between task samples should be easier as the number of iterations increases.
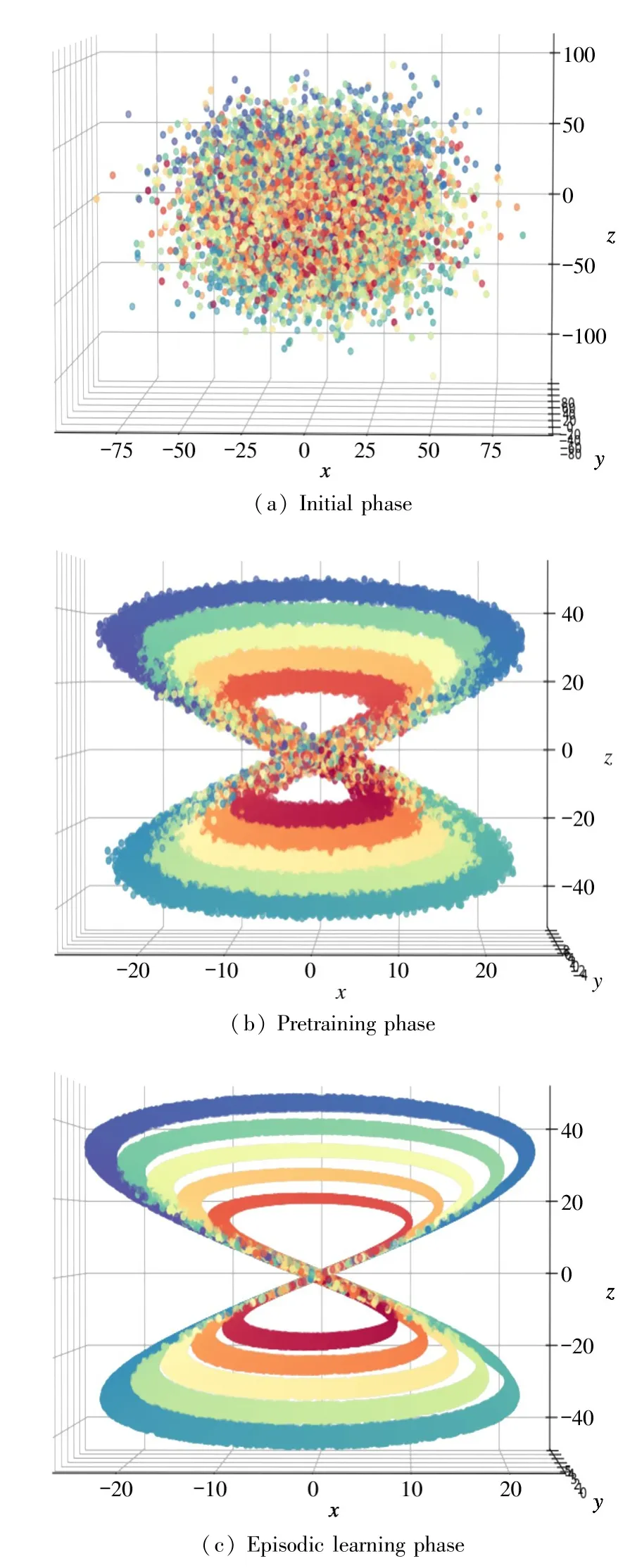
Fig.4 Visualization of feature space at different phase
The SGML is compared at different layers, and the results are shown in Fig.5. Since TieredImageNet is a larger dataset, more iterations are required to converge (100 epochs vs. 150 epochs). With the increase of the number of iteration layersLbetween node features and edge features, the classification effect of the two datasets is also better. WhenL= 3,the classification accuracy is the best, and the curve is relatively flat; whenL= 2, the classification accuracy is reduced, and the curve is relatively tortuous; whenL=1,the classification accuracy is the worst. This indicates that SGML tends to show good clustering in more iterations, but it does not indicate that more iterations will make the effect better.
4 Conclusion
A novel smoother manifold for graph meta-learning is proposed, which aims to addressed the problem of few-shot classification task. In the process of SGML,the similarity between nodes is obtained by updating nodes and edges features with different parameter layers, and then the similarity is sent to the embedded propagation module to complete the classification task.The experiment results show that the proposed method not only can improve the classification performance,but also can increase the smooth classification boundaries. Future work aims to explore other way of adding graph networks to manifold in meta-learning such as graph embedding, that will address more challenging problems to larger number of shots.
杂志排行

High Technology Letters的其它文章
- Deep convolutional adversarial graph autoencoder using positive pointwise mutual information for graph embedding①
- A joint optimization scheme of resource allocation in downlink NOMA with statistical channel state information①
- Personalized movie recommendation method based on ensemble learning①
- An improved micro-expression recognition algorithm of 3D convolutional neural network①
- Resonance analysis of single DOF parameter-varying system of magnetic-liquid double suspension bearing①
- Computation offloading and resource allocation for UAV-assisted IoT based on blockchain and mobile edge computing①