一种机器人的栅格-语义地图构建方法
2022-04-06张波涛
李 东,洪 涛,张波涛
(杭州电子科技大学自动化学院,浙江 杭州 310018)
0 引 言
地图是机器人工作空间中障碍物、目标等关键信息的载体,也是机器人规划、导航、自定位的基础[1]。常见的栅格地图[2]、拓扑地图[3]可以描述环境中存在的障碍物及其环境结构信息,但没有对环境中实例物体的类别、功能以及位置等信息进行描述[4]。移动机器人在目标搜索任务中,不仅需要获取目标的位置信息,而且需要获取目标的语义信息,因此,地图不仅要包含环境结构信息,而且要包含环境中实例物体的语义信息[5]。语义地图不仅包含结构信息而且具有更高层次的语义信息,如:物体类别、功能属性等信息[6]。
近年来,国内外研究者提出了多种不同的语义地图构建方法,包括基于栅格地图的2D语义地图构建、基于点云的3D语义地图构建等。李秀智等[1]在二维栅格地图中,使用卷积神经网络对生活场景出现的沙发、桌子等物体进行语义识别及标记,构建了较为初始的2D语义地图。Tateno等[7]将所识别物体的点云信息与目标点云先验库进行匹配,将匹配成功的目标点云插入到三维地图的对应位置,完成三维点云语义地图的构建。Salas-Moreno等[8]通过卷积神经网络(Convolutional Neural Networks, CNN)预测物体类别,并运用Elastic Fusion[9]提取环境的结构信息,将所提取的环境结构信息与语义分割信息融合起来,构建了稠密3D语义地图。Kunze等[10]在目标物体与所处场所之间建立联系,利用语义信息缩小了目标搜索空间,使得机器人在大规模环境下进行高效目标搜索,但该方法没有对区域进行自动划分。对于非结构化或者半结构化的动态室内环境,随着时间的推移,语义信息与实际环境的偏差会越来越大,最终可能导致较高的任务执行成本,甚至任务执行失败。同时,直接修改或存储点云具有较高的时间复杂度和空间复杂度,增大3D语义地图的维护和更新难度。此外,在室内动态环境中,目标物体容易受到遮挡以及位置移动等影响,可能无法检测到该物体,致使建立的语义地图不完善。针对以上问题,本文提出一种环境模型分层构建方法。将易于维护的二维栅格地图作为底层架构,在此基础上,对环境语义信息进行自主提取,完成语义信息与栅格地图之间的映射,建立上层语义地图。本文方法采用分层结构对环境结构信息和语义信息进行描述,对语义信息进行动态更新的同时避免产生过大的计算量和空间复杂度,提高了目标搜索任务的执行效率。
1 融合栅格-语义地图的构建
1.1 空间区域的划分和物体归属关系的建立
本文针对非结构化或半结构化的机器人工作环境,提出无监督区域划分方法,使用无监督聚类对机器人可行工作区域进行划分,并在目标物体与划分区域之间建立归属关系。首先,对非结构化的室内环境进行随机采样,使用K-means聚类算法[11]对随机采样点进行欧式聚类;然后,以聚类中心作为区域中心,完成对非结构化空间区域的划分;最后,建立物体位置信息与所划分区域的映射关系,完成物体与空间区域归属关系的建立。
对于采样点{x1,…,xN},根据距离将其划分为K类。通过不断迭代,求解合适的聚类中心,使得损失函数J最小。损失函数计算如下:
(1)
式中,μk为第k类的聚类中心,rnk表示第n个采样点是否属于第k类,k=1,2,…,K,取值为:
(2)
第n个采样点属于距离最近的聚类中心μk为:
(3)
所得聚类中心μk为划分后各个子区域的中心。利用自适应阈值建立目标物体与所在子区域的映射,基于该映射关系执行目标搜索时,机器人可在目标对应的映射区域中进行详细搜索。
1.2 实时目标语义信息的获取
使用深度学习方法对目标进行语义检测时,移动平台上有限的计算资源无法保证算法实时性的要求。为此,本文采用轻量化的目标检测网络YOLO-v3-tiny[12]对目标进行检测,获取该物体在栅格地图坐标系下的统一表示。但是,将真实环境中的物体映射到像素坐标系的过程中,丢失了物体的深度信息Zc,所以本文采用飞行时间测距原理的深度相机来补充物体深度信息,完成目标三维位姿的获取。
实时获取物体语义信息的流程如图1所示。首先,使用深度相机分别获取当前环境的色彩信息(Red, Green, Blue, RGB)与深度信息Depth,并将RGB坐标平面的像素映射到Depth像素平面内;然后,使用YOLO-v3-tiny算法检测RGB图像中的语义信息,并获取其对应的像素坐标;接着,获取所识别语义目标的三维坐标,经过坐标变换得到物体相对于机器人参考系的位置表示;最后,采用自适应蒙特卡洛算法对机器人进行定位,获取机器人在栅格坐标系下的位置变换关系,得到目标物体在全局栅格地图坐标系下的位置表示。
将像素平面坐标映射至成像平面,经过坐标变换得到:
(4)
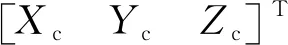
(5)
式中,旋转矩阵R和平移矩阵T表示相机坐标系相对于机器人坐标系的旋转及平移变换关系。
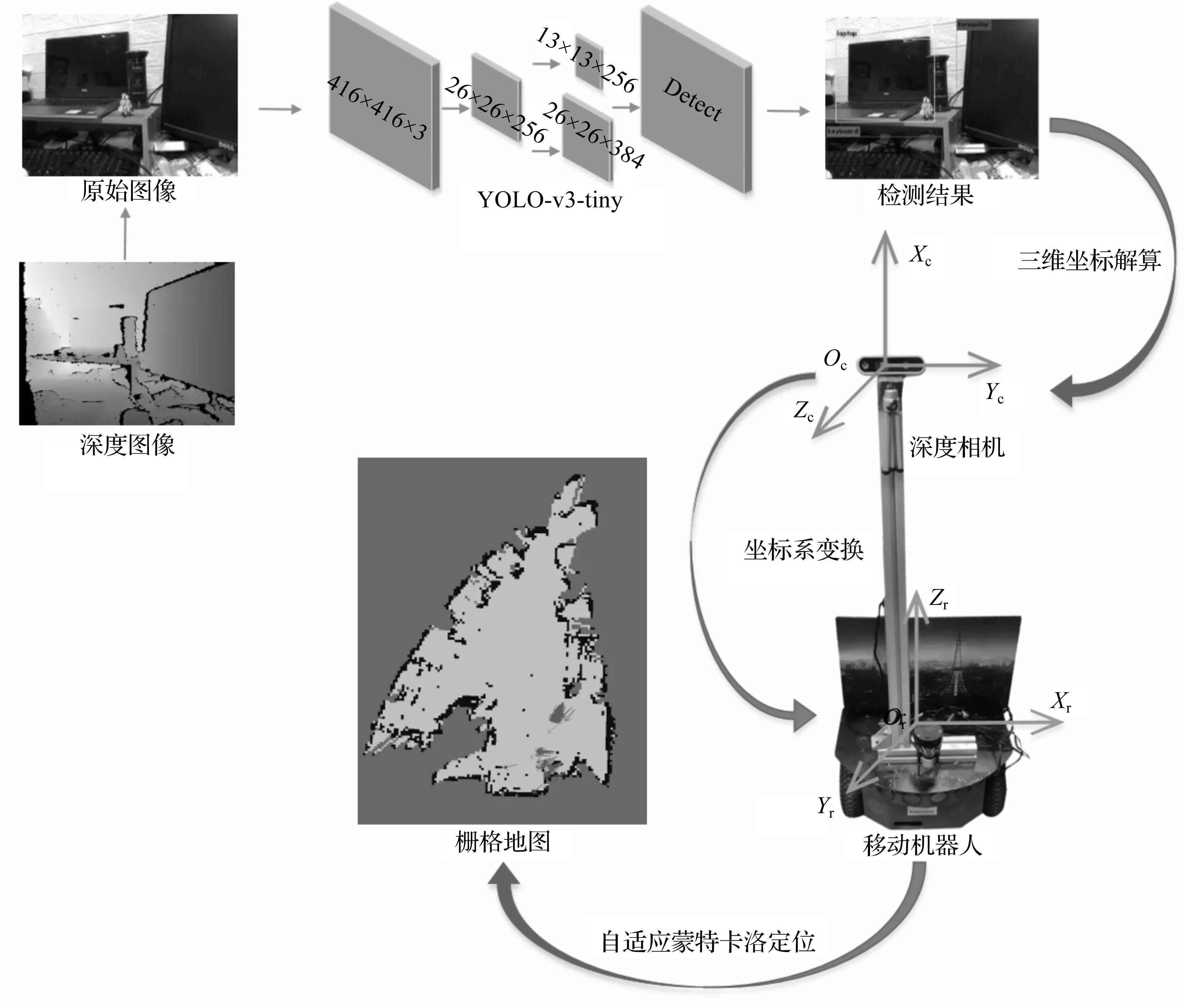
图1 目标语义信息及三维位姿获取
1.3 语义标记点的筛选
机器人在移动过程中,外界环境因素或机器人运动速度过快,导致相机误识别或重复识别的现象不可避免[14]。对语义信息进行标记过程中,若不区分有效标记点和无效标记点,大量无效标记点将被保留,影响融合地图的构建。本文采用双重阈值法分别对标记点进行时间和空间的筛选,删除无效标记点,并实现语义信息的增量式更新。假设输入物体类别class,空间阈值r,栅格地图坐标系下的物体坐标(xm,ym),时间戳t,筛选无效标记点主要过程如下:
(1)初次识别到某类物体时,以该物体位置(xm,ym)作为空间阈值的中心Cf。
(2)对后续待标记点求解其坐标位置与Cf的欧式距离。若该标记点在以Cf为中心,以空间阈值r为半径的邻域内,则将该标记点删除;若该标记点在邻域外,则将该点设为初始标记点并将其坐标(x′m,y′m)作为空间阈值的中心C′f,然后对其邻域内标记点进行过滤。
(3)设置时间阈值Ti。
(4)当相邻的同类物体待标记点时间间隔|ti-ti-1|小于Ti时,删除时间戳较近的待标记点;当相邻的同类物体待标记点时间间隔大于Ti时,添加新标记点。
2 实验结果与分析
实验配置为Ubuntu16.04,ROS Kinetic,机器人工作场景为室内环境。目标检测网络采用COCO数据集[15]的训练权重,采用深度相机完成目标三维位姿的获取。实验前对相机内参进行标定,标定结果如表1所示。

表1 深度相机内参标定结果 单位:Pixel
由于Depth相机与RGB相机之间存在一定的平移和旋转,需要将Depth成像平面像素对齐到RGB成像平面对应像素。Depth相机与RGB相机旋转矩阵RD表示为:
(6)
Depth平面与RGB平面平移矩阵TD表示为:
(7)
2.1 空间区域的划分
实验采用P3-DX移动机器人,甲板上搭载TX20激光雷达,实验场景如图2(a)所示。首先,利用激光雷达构建环境的栅格地图,在栅格地图上进行随机采样,采样结果如图2(b)所示;然后,对随机采样点进行无监督聚类,生成的聚类中心分布与聚类类别k有关,k分别取10,15,20时,区域中心点分布情况分别如图2(c)—图2(e)所示。
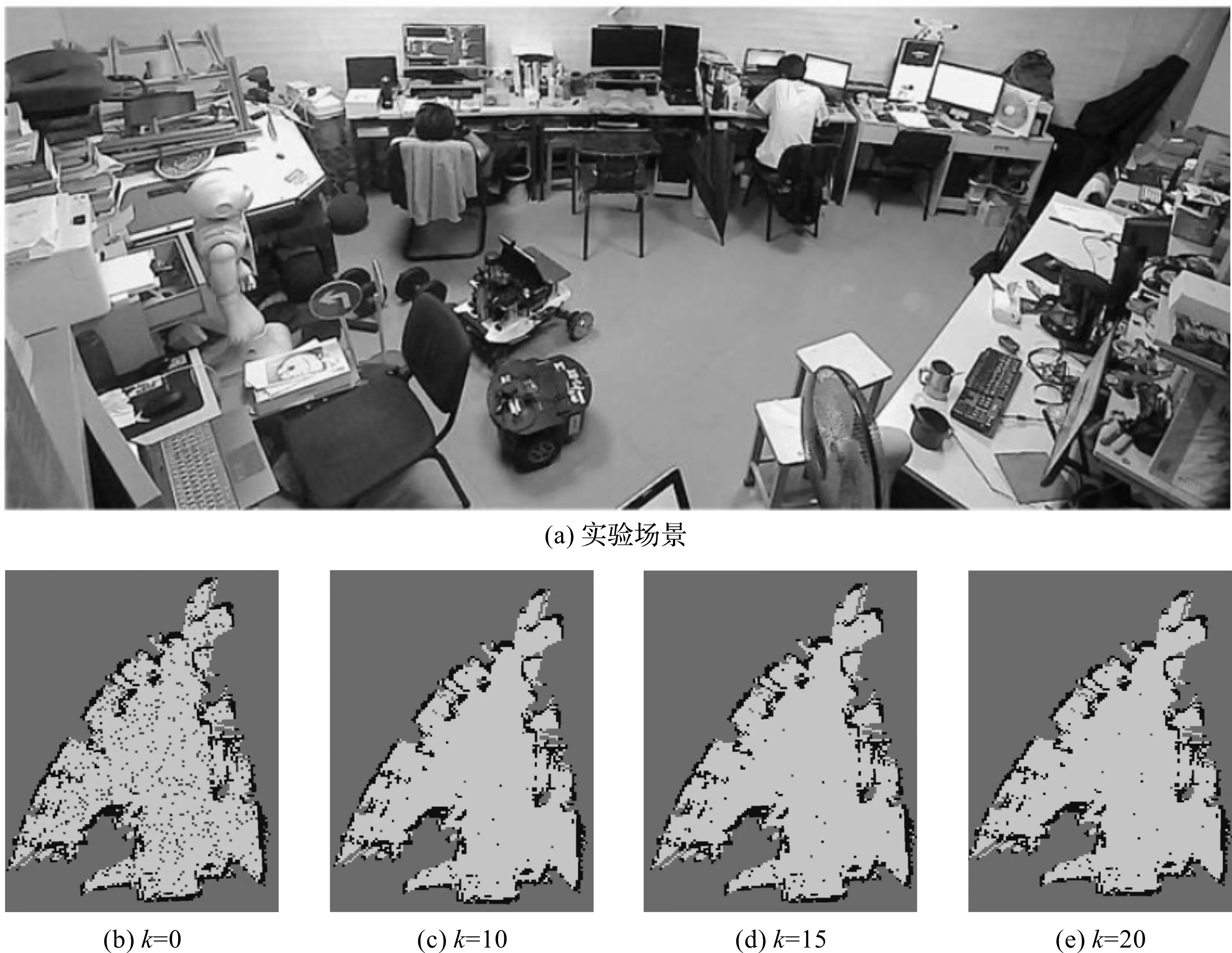
图2 实验场景与区域划分结果
2.2 融合栅格-语义地图的构建
移动机器人搭载深度相机在栅格地图上进行环境语义信息的获取和融合地图的构建。首先,获取机器人在栅格地图中的坐标信息;然后,对物体进行检测并求取物体在栅格地图上的三维坐标;最后,对各个物体的语义信息进行标记,构建融合栅格-语义地图。本文构建融合栅格-语义地图如图3所示。在对语义信息标记过程中,各个语义标记节点会获取距离此标记点最近的区域中心点,以便引导机器人在执行目标搜索等任务时,对相应区域进行搜索。
语义标记点的颜色代表物体种类,图3中,标记点①代表显示器在栅格地图中的映射,标记点②代表椅子在栅格地图中的映射。在进行语义标记时能够对动态物体进行无效标记点筛选,避免产生冗余语义信息。同时,对语义信息和环境信息进行独立维护,方便对目标语义信息进行动态更新。
图3 融合栅格-拓扑地图示意图
2.3 目标搜索实验
在2.2节所构建的地图中,分别采用穷举式目标搜索和具有融合地图语义信息引导的目标搜索方法进行目标搜索和规划测试,比较2种算法搜索成功所花费的平均时间代价,结果如表2所示。

表2 不同目标搜索算法的时间代价对比 单位:s
从表2可以看出,相较于穷举式目标搜索算法,在融合地图语义信息的引导下,移动机器人采用本文方法进行目标搜索时,时间代价减少了74.8%。机器人执行目标搜索任务时,首先,根据目标物体的种类来搜索对应的空间区域中心点,根据各区域中心点与机器人当前位置的实际距离进行目标点优先级排序,并加入优先搜索队列;然后,依次按照搜索队列将对应空间区域中心点设为机器人导航目标点,引导机器人导航至各目标点附近,进行目标搜索。该方法可提高机器人对于动态环境的适应能力,同时,在目标搜索过程中,机器人能够进行局部路径规划,对动态物体进行规避。相比穷举式目标搜索算法,在本文构建的融合栅格-语义地图中进行目标搜索时,语义信息的引导及目标与各个划分区域的映射,极大缩小了移动机器人的搜索范围,提高了机器人的搜索效率。
3 结束语
本文提出一种室内未知环境下分层语义地图的构建方法,将环境中的语义信息与结构信息进行融合,解决了传统语义地图算力消耗大、空间复杂度高的问题,具有良好的实时性,可为室内机器人的决策提供环境及目标信息。执行目标搜索任务时,相比穷举遍历搜索算法,在语义信息引导下进行的搜索具有更高的搜索效率。但是,目标受遮挡情况下,本文构建的融合语义地图存在语义信息不完善情况,后期将设计鲁棒性更强的栅格-语义融合方法,提高融合地图的信息完整性及目标搜索任务成功率。
