基于增强可逆性插值滤波器设计的编码方法
2022-04-06张秋阳黄晓峰殷海兵
张秋阳,黄晓峰,殷海兵
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
0 引 言
帧间预测运用视频时间域的相关性,使用邻近已编码图像像素来预测当前图像的像素,有效降低了相邻帧之间的时间冗余度,在提升编码效率上起着重要作用。帧间预测主要分为运动估计和运动补偿。编码时,运动估计在选定的参考帧中搜索最佳参考块,并使用运动矢量来确定其位置;解码时,根据残差和参考块来恢复当前块。由于数字视频固有的空间离散性,实际的物体运动可能不会与视频帧的离散采样保持一致,即实际物体运动可能不是整像素级,仅仅只在参考帧中搜索,效果可能不够理想。为了解决这个问题,编码标准将运动估计分为2个阶段,即整像素运动估计和分像素运动估计。先在整像素中搜索,找到整像素级下的最佳块,再使用滤波器对其附近的所有块进行插值,继续在这些生成的分像素块中搜索,直到找到真正的最佳块。在H.264[1]和H.265[2]中均采用了这种基于滤波器的分像素运动估计,使用的是基于离散余弦变换的插值滤波器(Discrete Cosine Transform Interpolation Filter,DCTIF)[3]。
近年来,深度学习在计算机视觉和图像处理领域取得了辉煌成就,比如图像分类、图像修复、图像超分辨[4]以及图像降噪[5]。在视频编码方面,深度学习同样应用于各大模块,如帧内预测[6]、环路滤波[7]、模式选择[8]等。由于卷积神经网络(Convolutional Neural Network, CNN)在图像特征提取方面展现出巨大潜力,随后产生了基于CNN的分像素插值滤波器[9-12]。尽管基于深度学习的插值滤波器具有许多优点,但仍存在一个无法回避的问题,即分像素插值任务不同于其他回归任务,并不具有所谓的“真实样本”。所以,如何设计合适的目标样本成为研究热点,其中具有里程碑意义的研究便是可逆性插值滤波器(Invertibility Interpolation Filter, InvIF)的设计[13]。但是,InvIF的设计仍有不足,首先,InvIF使用的卷积神经网络只包含简单的卷积层,其卷积核恒为方形,核中参数大小在训练完成后就不再变化,使得卷积层带来的感受野无法匹配视频帧中事物的轮廓,也无法控制不同位置像素在卷积运算中的权重,导致其特征提取效果的不理想;其次,原始InvIF的正则项和重建函数都使用了均方差函数,当训练轮数变大时,两者产生冲突,使得网络收敛不够充分;最后,InvIF使用DCTIF生成正则项,目标图像不足以反映现实世界中的运动情况,影响最终训练的效果。针对以上不足,本文对其进行优化,提出一种增强的可逆性插值滤波器(Enhanced Invertibility Interpolation Filter, EInvIF)方案。
1 EInvIF设计
InvIF的结构如图1(a)所示。为了解决分像素插值任务中没有真实样本的问题,InvIF引入模拟信号来处理领域中的可逆性。在模拟信号处理中,插值可以视为离散采样的逆运算,采样后得到的整像素位通过内插函数重新恢复原始信号,内插函数是无数个最佳滤波器的结合。针对采样的整像素值,使用对应位置的最佳滤波器进行插值,得到特定的分像素位值。如果将上述操作中的整像素位和分像素位进行位置调换,分像素位使用同样的最佳滤波器也可以插值出整像素位。所以,这种可逆性可以用于分像素插值滤波器的训练,对应的端到端训练模型如下:
(1)
InvIF存在3个方面的问题:(1)只使用简单的卷积层;(2)正则项与重建函数有冲突;(3)正则目标生成方法不够真实。本文对这3个方面分别进行优化,提出EInvIF,如图1(b)所示。首先,引入可变形卷积网络[14-15],增加了网络感受野形状的灵活度;其次,在正则项中引入生成对抗网络(Generative Adversarial Networks, GAN)[16],使得网络输出更加收敛;最后,使用运动模糊生成的图像作为正则目标。
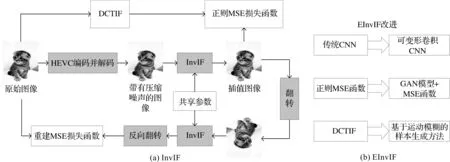
图1 InvIF及改进的EInvIF结构
1.1 可变形卷积网络
传统卷积层的卷积核形状固定,完成训练后的参数不变,对不同视频中丰富内容的适应性不足,影响编码的性能。为了解决这一问题,EInvIF引入可变形卷积层进行特征提取。卷积层输出特征图像的每个像素点px对应的卷积运算表示为:
y(px)=∑W(px+py)X(px+py)
(2)
式中,W表示卷积核中的参数矩阵,py表示从px移动到每个参与运算的像素的向量。W和X表示相同大小的矩阵。
3×3可变形卷积的实例如图2所示。在传统卷积层的基础上添加了一个额外的卷积层用来计算偏移矩阵和幅度矩阵,偏移矩阵包含每个参与计算的像素点的偏移向量,幅度矩阵则是每个像素点的权重。可变形卷积表示为:
y(px)=∑W(px+py)X(px+py+Δpy)Δmy
(3)
式中,Δpy和Δmy表示每个像素的偏移和幅度。在输入输出的大小关系上,可变形卷积和传统卷积是相同的。
额外卷积层的输出由3K个通道组成,前2K个通道存储了每个像素点的x轴偏移量和y轴偏移量;后K个通道将输入1个sigmoid层,得到0~1之间的数字并作为每个像素点的权重。在训练阶段中,该额外卷积层和执行可变形卷积的卷积层同时通过反向传播进行训练。
实际情况中,Δpy通常包含分数,故本文使用线性插值来求得分数位的值:
X(p)=∑B(q,p)X(q)
(4)
式中,q表示整数位,p表示分数位,B(·)表示线性插值操作。
本文设计的可变形卷积网络(Deformable Convolutional Network Interpolation Filter, DCNIF)的结构如图3所示。DCNIF是一个全卷积网络,其结构主要参考文献[9]。考虑到计算复杂度对编码时间的影响,本文仅将网络的第1个用于特征提取的卷积层替换为可变形卷积层。网络采用线性整流函数(ReLU)作为激活函数。在可变形卷积层进行特征提取后,将特征图输入到后2层卷积层中进行特征增强和特征映射。值得注意的是,第2层和第3层都由2个卷积核构成,不同大小的卷积核分别计算有利于去除图像中的伪影,对视频编码标准中不同大小的编码单元(Coding Unit,CU)均有更好的适应效果。
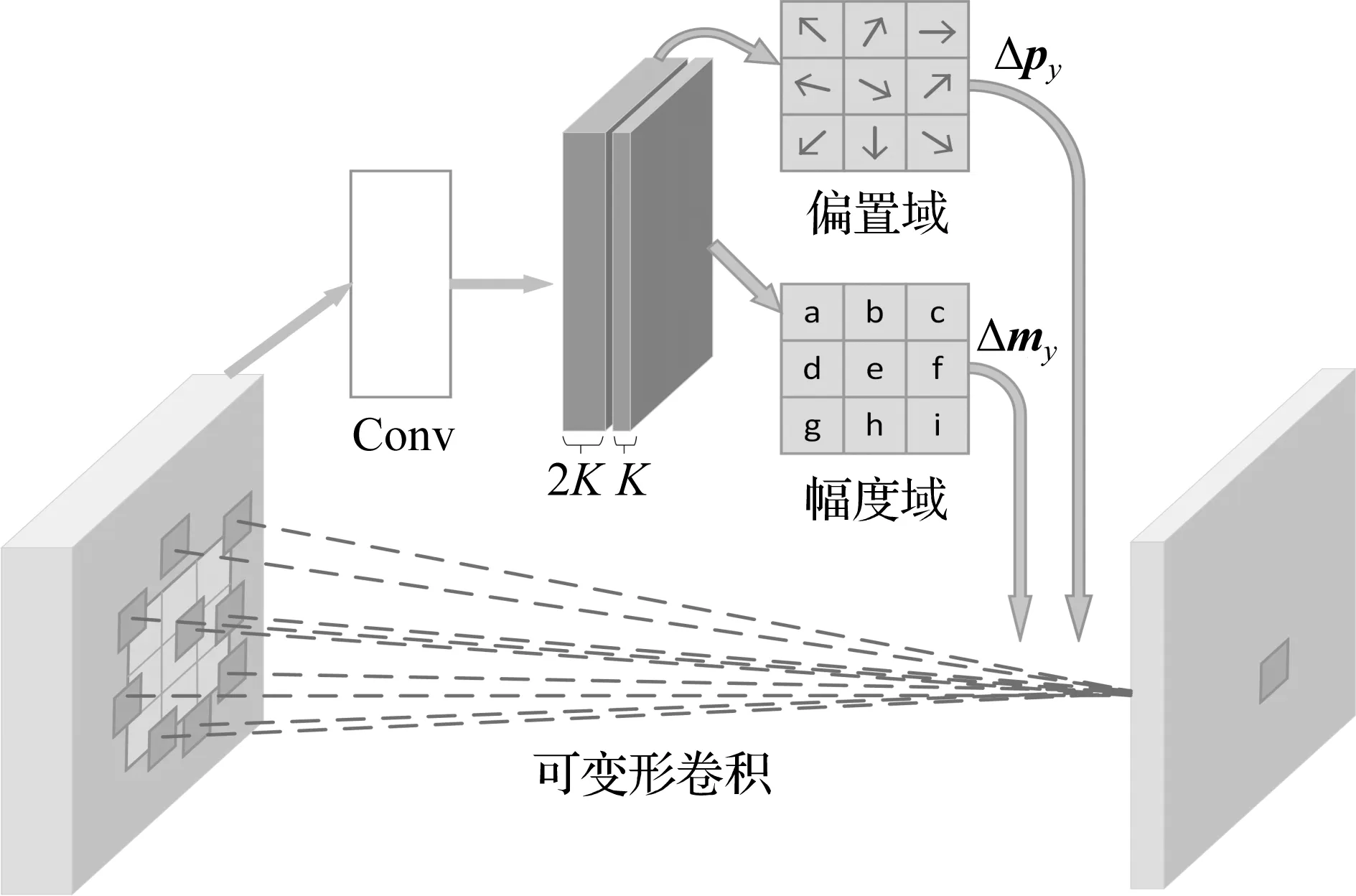
图2 3×3可变形卷积示例图
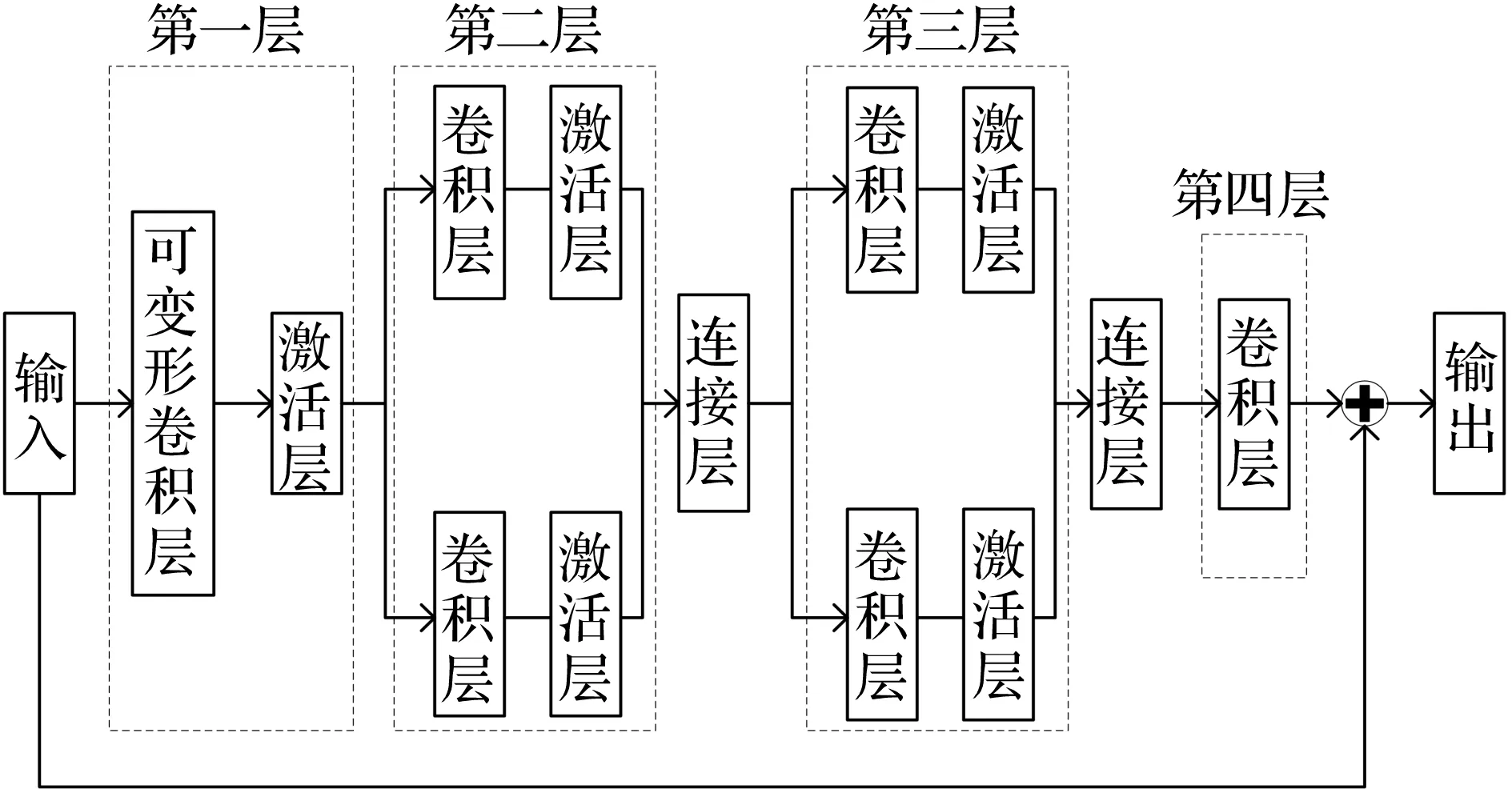
图3 DCNIF结构图
本文使用MSE损失函数作为训练的损失函数,表示为:
(5)
式中,n表示训练样本总数,θ表示所有需要学习的参数,F表示网络的正向传播,Si和Yi分别表示训练对中的整像素位图像和分像素位图像。
1.2 基于GAN的正则项设计
InvIF使用可逆性作为端到端训练的原理,但仅靠可逆性无法得到某个特定分像素位置的最佳滤波器,所以,InvIF通过加入正则项将滤波器训练约束到特定的分像素位。在InvIF原始方案中,正则项使用MSE函数作为损失函数。在训练中后期,2个MSE函数将产生冲突,导致模型无法完全收敛。为了解决这一问题,本文将GAN模型引入到EInvIF正则项的构造,在正则项里新加入1个鉴别器,对网络输出和分像素位真实训练样本进行鉴别。图1(a)中的第1个InvIF模型作为GAN中的生成器,生成插值图像去逼近正则项样本;鉴别器则是通过图像分类的方式来区分生成器生成的样本和正则项样本。生成器的目标是生成更接近正则项样本分布的图像,使得鉴别器区分不出2种图像,两者以对抗的形式进行训练。鉴别器的网络结构如图4所示,k为卷积核大小,n为卷积核数量,s为步长。最终的模型损失函数表示为:
L总=λLGAN+(1-θ)Lrec+θLreg
(6)
式中,λ和θ表示调节各部分权重的超参数,L总表示训练损失函数的总和,LGAN表示GAN模型中鉴别器的损失函数,即交叉熵函数,Lreg表示正则项损失函数,Lrec表示重建项损失函数,两者都是MSE函数。通过实验,本文将λ设置为0.005,θ设置为0.5。
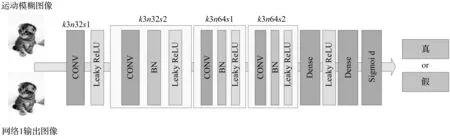
图4 鉴别器结构图
1.3 基于运动模糊的训练样本生成方法
正则项可将滤波器约束到特定分像素位上,故在实际训练中,可以通过调节正则项来训练不同位置的模型。原始InvIF使用H.265中采用的DCTIF来生成正则项中的正则图像,本文采用对高分辨率图像作运动模糊的方法来替换DCTIF。运动模糊操作有2个关键参数,分别是模糊核的长度和运动方向。通过调节2个参数可以模拟真实运动,达到比简单超分辨更好的效果。运动模糊操作可表示为:
B=C(L,β)X+N
(7)
式中,C表示运动模糊核,L表示模糊核的长度,即有多少个像素点参与模糊运算,β表示运动方向与0°的夹角,B表示运动模糊样本,N表示均匀白噪声。本文采用L为6的模糊核,生成了15幅不同位置的分像素图像用于训练,示意图如图5所示。
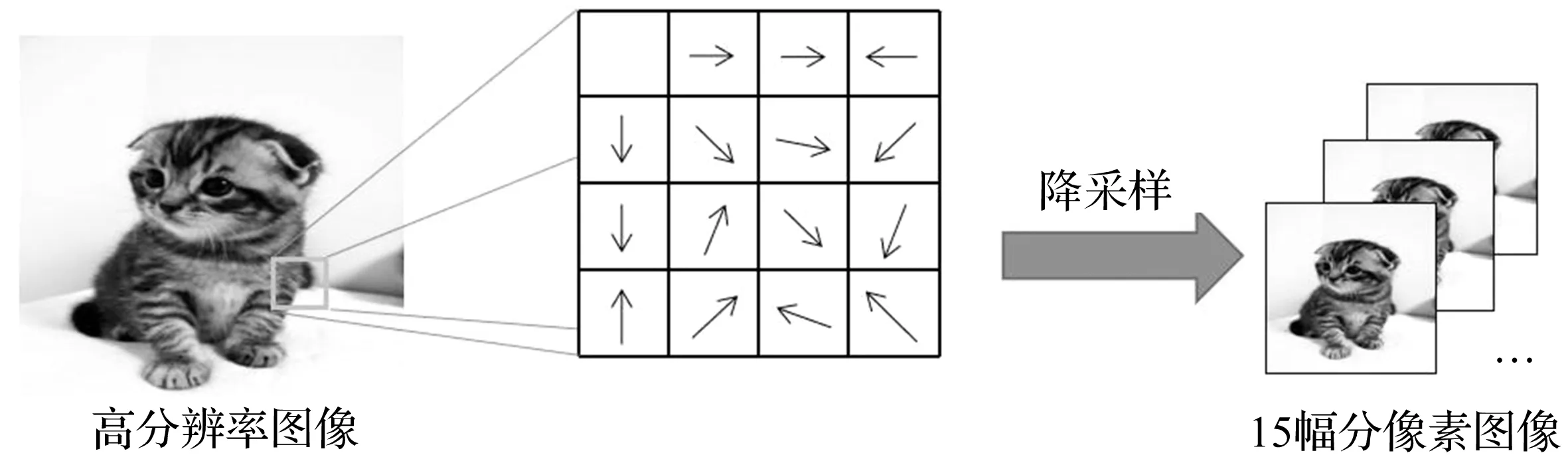
图5 基于运动模糊的训练样本生成方法示意图
2 实验结果与分析
使用caffe[17]框架进行训练,实验均在NVIDIA GTX 1080TI GPU上进行。每个分像素位置包括3个1/2像素位,12个1/4像素位,及4个不同的量化参数(Quantization Parameter, QP),分别为22,27,32,37,共训练60个不同的模型。得益于残差学习带来的跳接效应,训练时间大幅缩短,每个模型的训练只需要5 h。训练集使用FIR2K图片集的1 000张图片,经过处理的每张图片被划分为33×33的小块输入网络。训练使用Adam优化器,学习率为1×10-5,迭代次数为200 000次。
将本文提出的EInvIF植入H.265的参考软件HM-16.7中进行实验。实验中,使用一个CU级的率失真优化器对EInvIF和原本的DCTIF进行选择,采用BD-rate指标[18]进行性能评价。在单向预测Low Delay P模式和双向预测Low Delay B模式下,选择4个不同的QP进行对比实验并计算BD-rate,相比于HM,EInvIF的BD-rate指标提升情况如表1所示,表1中,Y表示亮度分量,U和V表示色度分量。
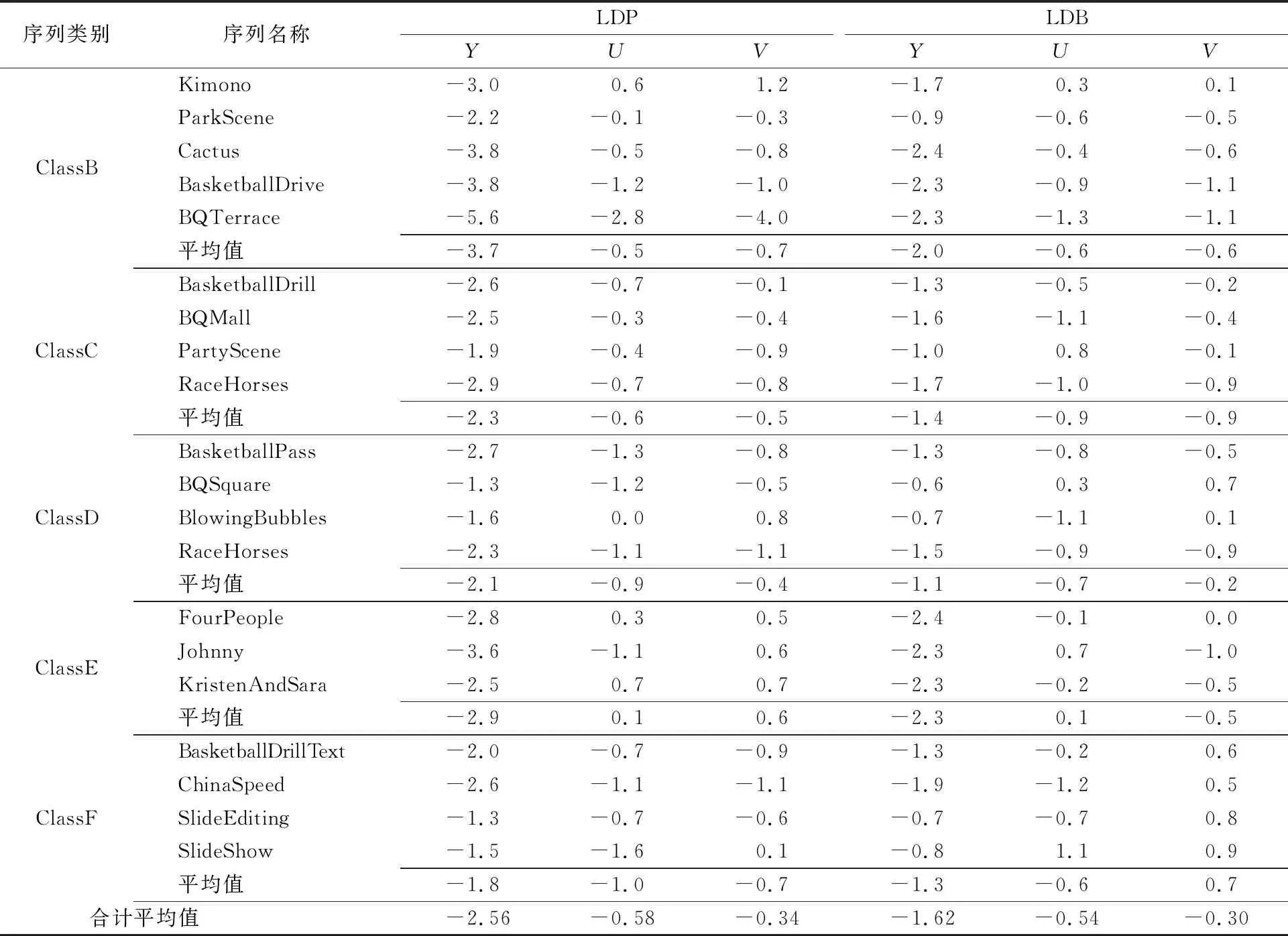
表1 LDP和LDB模式下,相比于HM,EInvIF的BD-rate性能提升情况 单位:%
从表1可以看出,相比于HM,在LDP模式下,在亮度分量Y上,本文提出的EInvIF达到平均2.56%的提升。BQTerrace序列获得了最高的5.6%的性能提升。
在LDP模式下,分别使用EInvIF方法、CNNIF方法[9]、GVNIF方法[10]、DINIF方法[11]及InvIF方法[13]进行编码实验,相比于HM,各方法的BD-rate提升情况如表2所示。

表2 LDP模式下,相比于HM,不同方法的BD-rate性能提升情况 单位:%
从表2可以看出,EInvIF方法和InvIF方法的BD-rate性能提升都超越了CNNIF方法,说明可逆性训练模型在分像素插值任务中的有效性。进一步分析可知,相比于InvIF,EInvIF的BD-rate性能提升有较大提升,这得益于EInvIF的可变形卷积带来的网络灵活性,GAN训练模型提升了训练阶段模型的收敛能力,使得运动模糊方法生成的训练样本更加真实。值得注意的是,在纹理丰富的ClassF类视频编码结果中,InvIF和EInvIF的BD-rate性能提升远超其他方法,说明基于可逆性训练的模型在复杂视频要素下能发挥更好的性能。
对可变形卷积层、GAN模型、运动模糊方法及其组合GAN+运动模糊模块分别进行消融实验,相比于纯净的HM,各个模块及其组合和原始InvIF的BD-rate提升情况如表3所示。

表3 相比于HM,3个模块及其组合和原始InvIF的BD-rate性能提升情况 单位:%
从表3可以看出,相比于原始InvIF,3个模块中,可变形卷积带来的BD-rate提升最大,可变形卷积网络达到2.40%的提升,相比于原始InvIF的2.12%提升了0.28%。其他2个模块分别有0.16%和0.15%的提升,而GAN+运动模糊模块则达到0.27%的提升。所以,得出以下结论:可变形卷积因具有增大CNN感受野的能力,在复杂视频编解码环境中更能提升分像素插值预测的准确性,对最终性能的提升较大;GAN模型解决了训练过程中重建MSE函数和正则项MSE函数冲突的问题,进入较高迭代次数后,降低了训练阶段CNN的损失值,使得CNN模型生成更逼近目标分布的图像;相比于DCTIF的方法,运动模糊方法能生成更逼近真实情况的分像素位置图像,使得CNN模型在实际编解码阶段生成更接近参考块的分像素块,提升了BD-rate性能;GAN模型和运动模糊结合使用后,GAN模型使得网络输出的分布更加接近由运动模糊生成的更真实的正则样本的分布,相较于单独使用其中一个模块,两者结合使用后的性能有明显提升。
为了进一步分析EInvIF的结果,本文计算了在CU级率失真优化器(Rate-Distortion Optimizer,RDO)启动后,选择EInvIF的CU占所有CU的比例。在LDP模式下,选择4个不同QP(分别为22,27,32,37),对ClassB到ClassF的所有序列的前100帧进行测试,得到选择EInvIF的CU占所有CU的比例情况如表4所示。
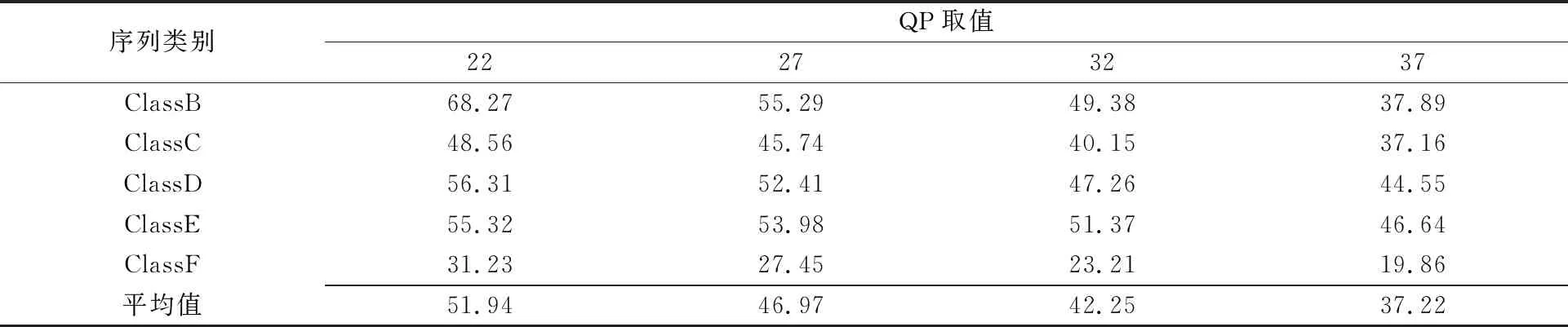
表4 选择EInvIF的CU占所有CU的比例结果 单位:%
从表4可以看出,QP越低,即视频质量越高时,编码器更倾向于使用EInvIF,因为EInvIF中包含可变形卷积层的神经网络,对高质量图像进行特征提取的能力明显优于DCTIF;当QP较高,图像质量较低时,输入图像带有更多的压缩噪声,使得CNN更难学习到正确的特征分布,最终导致EInvIF的效果下降。
深度学习的方法普遍存在一个不足之处,即较高的计算复杂度带来的时间花费。本文对EInvIF方法、CNNIF方法[9]、GVNIF方法[10]、DINIF方法[11]及InvIF方法[13]的计算复杂度进行定量分析。LDP模式下,和HM相比,采用5种深度学习方法对所有序列进行编码和解码,编/解码耗时增幅如表5所示。

表5 相比于HM,不同深度学习方法的编/解码耗时增幅 单位:%
从表5可以看出,相比于原始HM,EInvIF方法花费了更多的时间,因为卷积神经网络花费了大量的卷积计算量,同时,神经网络计算额外增加了数据格式的转换耗时。不过,表5数据是在仅使用CPU进行计算得到的结果,如果使用擅长并行计算的GPU设备,编/解码时间将大幅缩短。
3 结束语
本文提出一种增强的可逆性分像素插值滤波器设计方法。在InvIF原有结构的基础上,通过引入可变形卷积层来增加网络对不同视频要素的适应性,并在正则项中加入GAN结构以提高模型的收敛能力,使用运动模糊的方法生成正则项的训练样本,提高了编码效果。但是,在训练模型中,本文方法只使用MSE函数,没有考虑码率,即残差的分布情况,没有达到最佳效果。下一步将在训练模型中加入码率估计模块,使用双损失函数进行率失真优化型的网络训练,进一步提高模型的率失真同步优化能力。
