基于跳跃连接的生成对抗网络人脸修复算法
2022-04-02张宇航苏江涛
张宇航,张 乾,江 漫,苏江涛
(1. 贵州民族大学 a. 数据科学与信息工程学院,b. 教务处,贵阳 550025;2. 贵州省模式识别与智能系统重点实验室,贵阳 550025)
随着计算机视觉和人工智能的发展,人脸识别技术得到了广泛的应用,人们往往只需露出面部,即可被识别出.但是,在实际生活中人们常常会因为佩戴口罩、眼镜、帽子等物品,对面部有部分遮挡,尤其是在新冠疫情以来,许多公众场所要求人们必须佩戴口罩,人脸识别的效果进而受到了影响.因此,如何利用计算机视觉技术对被遮挡的面部进行修复,使其逼近原始未被遮挡的人脸图像,以达到人脸识别的目的,这在实际生活中有着重要意义.
早期的人脸修复算法主要以传统修复方法为主,分为纹理修复和结构修复2 类.Criminisi 等[1]基于图像的纹理,利用边缘像素优先级,依次对图片的空洞区域进行填充修复.Barnes 等[2]根据图片纹理合成的方法提出了匹配块(patch match)算法,该算法利用匹配块随机搜索图片中类似的图像块来对缺失区域进行修复.结构修复方法主要通过保留图片重要结构来提高图像完成的质量.Huang 等[3]通过透视平面的规则性来修复图像空白区域;Kopf 等[4]基于分片搜索空间约束方式对图像进行修复.传统修复算法主要依赖于利用图片中已有的信息对图像进行修复,随着破损区域的变大,造成的信息缺失会增多,进而导致修复的图像变得模糊,修复效果变差.
随着深度学习以及计算机技术的飞速发展,Goodfellow 等[5]提出了生成对抗网络(generative adversarial network, GAN).该网络解决了传统修复方法生成图片模糊、细节体现不佳等问题,为图像修复问题开辟了新的道路.Mirza 等[6]提出了一种带有约束性的生成对抗网络(conditional generative adversarial nets, CGAN),通过将数据和条件变量一同输入到模型中,来提高原始GAN生成图像的质量.
Salimans 等[7]对GAN 的训练过程进行了改进,通过结合特征匹配(feature matching)和小批量判别(minibatch discrimination)等方法来提升模型训练过程中的稳定性.Arjovsky等[8]针对GAN训练不稳定的问题,对其损失函数进行了改进,引入Wasserstein距离代替GAN 中的KL和JS散度,提出了W-GAN (Wasserstein GAN).
但后来,Gulrajani 等[9]发现采用W-GAN 损失函数后,存在的大部分权重只集中在2 个数上,无法充分发挥神经网络的拟合能力,便在W-GAN基础上又加入梯度惩罚,对Lipschitz 连续性限制条件进行了改进,提出了WGAN-GP,使得收敛速度更快,模型训练更加稳定.Iizuka 等[10]提出一个双判别器模型,使得GAN 由传统的单判别器模型转换为多判别器模型.该模型由1 个局部判别器和1 个全局判别器构成,全局判别器对整张图像进行判别,而局部判别器只对以修复区域为中心的部分区域进行判别.采用该方式可以加强对图像边缘的修复效果,使得修复图像看起来更连贯.李泽文等[11]提出基于残差生成对抗网络的人脸图像复原方法,在原始GAN 中引入残差网络,利用人脸的特征轮廓对人像进行修复,使局部修复细节更加明显.
本文针对现有模型在人脸图像修复任务中存在的修复效果不佳、细节体现不足、修复边缘生硬等问题,将跳跃连接引入到生成器中,并结合双判别器模型,提出一种新的人脸图像修复的生成对抗网络算法并加以验证、比较.
1 相关理论
1.1 生成对抗网络原理
生成对抗网络(GAN)的原理主要源于博弈论中的二人“零和博弈”思想.该模型主要由生成器和判别器2 部分构成.其生成器的作用是根据输入的随机样本(噪声),生成一个假图像;判别器的作用则是对输入的图片进行判别,并将判别结果反馈给生成器.如果输入的图像越接近原始图像,则判别结果越接近于1;反之,判别结果越接近于0.GAN 的基本网络结构如图1 所示.
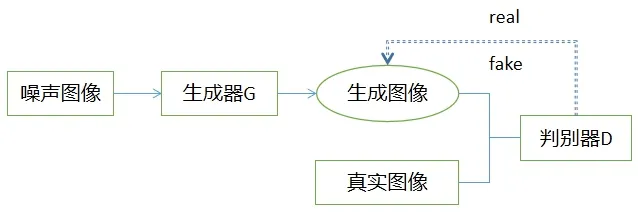
图1 GAN 基本网络结构
生成器的目标是生成一个判别器无法判断的假图像,而判别器的目标则是尽力去正确判别输入图像的真假.整个模型生成器和判别器交替训练,能力同步提升,最终达到“纳什均衡”状态,生成一个可以以假乱真的假图像.
1.2 GLCIC 模型
为提升图像修复效果,使修复后的图像整体与局部保持连贯,细节更加真实,Iizuka 等[10]提出了GLCIC 模型,相比于传统生成对抗网络仅有1 个生成器和1 个判别器模型,该模型最大的贡献在于采用了双判别器模型对图像进行判别,其网络结构如图2 所示.
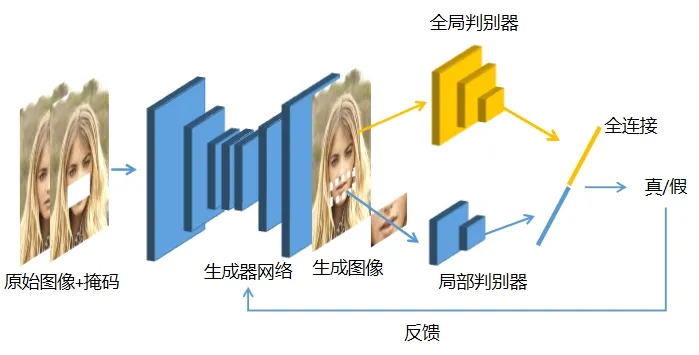
图2 GLCIC 模型网络结构
由图2 可知,整个模型以卷积网络为基础,分为2 部分和3 网络.第一部分为生成器,只包括生成网络;第二部分为判别器,包含局部判别器和全局判别器2 个网络.通过局部判别和全局判别联合的方法,可以在很大程度上增加修补区域和其他区域的联系[12],对图像的整体修复效果进行提升,优化生成图像的细节.
2 跳跃连接式GAN
2.1 生成器网络
本文生成器模型采用编码器-解码器结构,通过在层间加入跳跃连接[13],提出了新的跳跃连接式生成对抗网络,并对其网络结构和激活函数进行改进.整个网络由14 层卷积层网络构成,生成器模型如图3 所示.
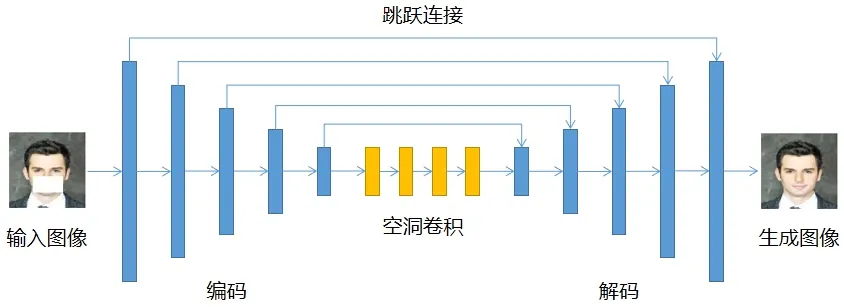
图3 生成器网络模型
由图3 可知,该生成器分为编码器、解码器和空洞卷积3 部分.其中,编码器由5 层卷积层构成,采用stride=2 的步长卷积进行下采样,来降低输入图片的分辨率,卷积核大小为3×3;解码器则采用与编码器相对应的5 个反卷积层构成,其卷积核大小亦为3×3,并利用stride=1/2的 微 步 长 卷 积 操 作 (fractionally-strided convolutions),将输出恢复到原始分辨率.
该网络采用跳跃连接将编码器和解码器连接起来,可以将更多的低层特征传送到高层特征来获取更多的层间特征.同时,在编码器和解码器中间还使用了4 次空洞卷积(dilated conv)来增大感受视野,可在不改变图像大小的情况下,获取更多的上下文信息,得到生成图像.生成器模型除最后1 个卷积层使用Tanh激活函数外,在每个卷积层之后,均采用ReLU激活函数.生成器网络体系结构见表1.
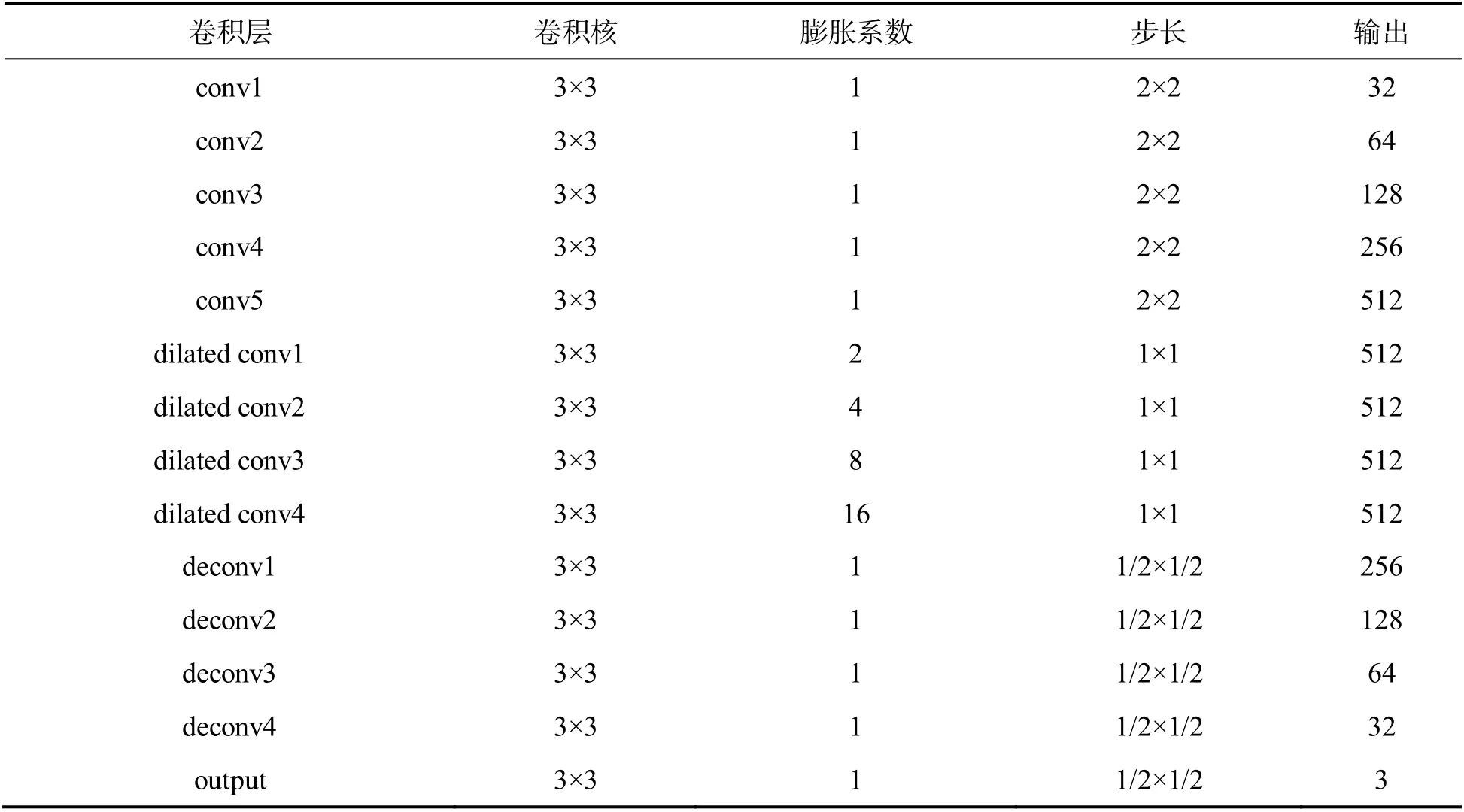
表1 生成器网络体系结构
2.2 判别器网络
本文判别器网络大致采用文献[10]提出的局部和全局双判别器模型,其结构如图4 所示.

图4 双判别器网络模型
在图4 中,全局判别器对整张人脸图像进行判别,其输入为128×128×3 的全局图像;局部判别器仅对以修复区域为中心的原始图像1/4 区域进行判别,其输入为64×64×3 的局部图片.2 种判别器的网络卷积层均采用5×5 的卷积核,并用stride=2 的步长卷积来降低图像分辨率;再通过全连接层,得到2 个1 024 维的向量,进一步将其连接成1 个2 048 维向量;最后经过全连接层输出1 个对应图像判别结果的值.在本文所用判别器模型中,去掉了最后一层的Sigmoid激活函数.除最后一层外,各层均采用Leaky_ReLU激活函数,且每层都加入batch norm 层对其进行批量归一化处理,以提升训练的稳定性.判别器网络体系结构见表2.

表2 判别器网络体系结构
2.3 损失函数
损失函数直接采用文献[10]的损失函数.整个模型的损失函数由均方误差损失(mean square error, MSE)和GAN 损失联合构成.MSE 损失用于计算原图与生成图像像素间的差异,可以提高模型训练的稳定性和结果的真实性,其表达式如公式(1)所示.


其中α为加权参数.
2.4 算法流程

8)生成器和双判别器网络交替训练.
9)更新生成器网络和双判别器网络的参数.
10)end if.
11)end while.
3 实验与结果分析
3.1 实验环境
本文实验使用百度云服务器AI Studio,框架为PaddlePaddle 1.8.0;Python 版本为Python3.7;使用GPU 训练,GPU 为Tesla V100;显卡内存32 GB,RAM 32 GB,磁盘100 GB.
3.2 预处理
实验所用数据集为公开数据集CelebA[14],该数据集包含202 599 张大小为178×218×3 的人脸图像.本文从CelebA 人脸数据集中选择20 000张人脸图片进行训练,其中19 000 张图片用作训练数据,1 000 张图片用作测试数据.实验先将图像大小归一化为128×128×3,并在其随机区域随机添加大小为24×24×1 至48×48×1 的空洞掩码,输入到生成器中进行修复.预处理后的图像如图5 所示.

图5 预处理后的图像
3.3 实验参数
整个模型在实验过程中共训练150个epoch(一代训练).为了缩短模型训练时间,先单独训练生成器50 个epoch,之后再将生成器与双判别器交替训练100 个epoch,总共耗时4 h.在训练中优化器采用Adam 优化算法[15].其中,batch_size设置为 128;学习率设置为 0.001;β1=0.9,β2=0.999;加权参数α设为0.1.
3.4 结果分析
图6 为采用本文算法和其他文献算法对不同人脸图像修复前后的效果对比.
由图6 可知,采用本文算法修复后的人脸图像,细节表现更加逼真,整体更加连贯;在遮挡面积几乎覆盖整个面部时,文献[10]的方法出现了修复模糊、图像失真等问题,而本文算法仍能较好地对人脸图像进行修复,且修复结果自然生动,与原始图像对比没有明显差异.

图6 图像修复效果对比
图7 为采用本文算法对同一张人脸采用随机遮挡后的修复效果.

图7 随机遮挡图像的修复效果
随机遮挡是指对人脸不同部位采取随机大小的遮挡块对其遮挡.从图7 可以看出,本文算法可以很好地对人脸部不同器官(如眼睛、鼻子、嘴巴、脸颊等)的复杂图像进行修复,且修复后的图像与原始图像图7(a)相近,其细节刻画明显,表情较丰富和逼真.
为更进一步评价修复效果,本文采用峰值信噪比(PSNR)和结构相似性(SSIM)这2 个常被用来评价图像相似度的指标,对不同方法下人脸图像的修复效果进行对比,其结果见表3.
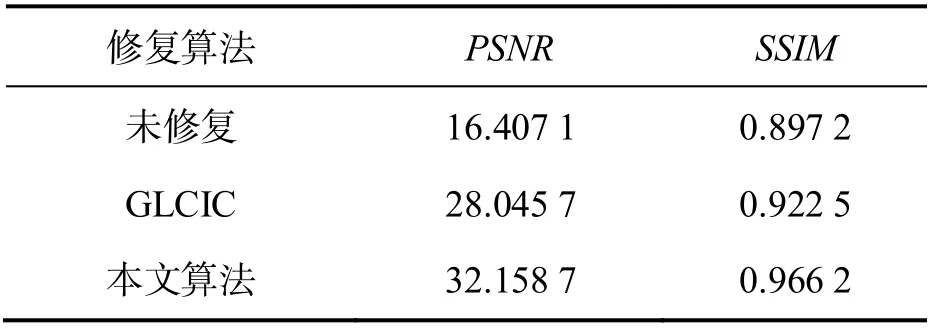
表3 不同修复方法的PSNR 和SSIM 平均值
由表3 可知,相较GLCIC 算法,采用本文算法修复图像的PSNR值为32.158 7,提高了14.67%;SSIM值为0.966 2,提高了4.35%.这说明本文所提方法的图像修复效果更佳.
4 结语
本文提出了一个基于跳跃连接的生成对抗网络人脸修复模型.在采用双判别器网络模型的基础上,对生成器网络结构进行了改进,并在层间加入跳跃连接以获得更多特征信息,通过步长卷积减少采样过程导致的信息损失,最终使其对人脸不同部位、不同大小的遮挡都有较好的修复效果,且修复后的人脸图像更逼真、连贯、生动.对比其他已有模型,其不仅有更好的修复效果,训练速度也有明显提升,在实际应用中具有良好的鲁棒性和泛化能力.然而,整个模型在训练过程中仍会出现训练不稳定,造成梯度消失和梯度爆炸等情况.针对该模型的局限性,今后的实验可从此方面进行改进.
