利用粗糙集和支持向量机的银行借贷风险预测模型
2022-04-02吴尚智王旭文王志宁任艺璇
吴尚智, 王旭文, 王志宁, 任艺璇
(西北师范大学 计算机科学与工程学院,兰州 730070)
个人信用评估是银行对借款人信用的一种评估方式,通过科学方法,综合考察影响个人的主客观环境,评估用户能否履行对银行的经济承诺。
大数据时代,数据量越来越大。粗糙集理论是由波兰数学家Z.Pawlak[1]提出,处理数据中模糊性、不可分辨性和不确定性问题的数学工具。属性约简是在保持知识库分类能力不变的条件下,删除其中不相关或不重要的知识,从而减少其对计算过程及最终结果产生的影响。因属性约简已被证明是一个NP[1]难题,且大量研究表明,对于复杂的问题,融合智能优化算法比单一算法使用相同参数时性能优化和鲁棒性均有大幅度提升[2-3]。近年来,各类数据分析方法和预测模型在银行借贷风险中得到广泛应用,S.Chatterjee等[4]将KNN算法应用到评分模型中,先利用聚类将已有的客户分开,再计算新用户在欧式空间下与已有用户的距离,判断其属于哪个类别;J.C.Wiginton[5]将Logistic回归模型引入个人信用评估中有着稳定性、准确率高的优点,得到大量使用;P.Makowski[6]将决策树用于个人信用评估,主要用来处理确定信息;M.D.Odom等[7]将神经网络用于风险评估,其具有自主学习和高速寻找优化解的能力;T.C.Forgarty等[8]将遗传算法运用到风险评估中的模型优化;张佳维[9]将模糊理论和神经网络结合的模糊神经网络算法,通过调节参数,得到准确性和精确性都很好的个人信用评分模型;B.Basense等[10]将支持向量机使用到个人信用评估中,研究表明数据维度较高的情况下,支持向量机模型明显优于神经网络和线性回归模型;杜婷[11]将模糊支持向量机与一般的支持向量机模型对比,发现前者的准确度更高,粗糙集不足在于对测试集的拟合功能不好,并且只能处理离散数据[12];Jerzy Baszczyński等[13]使用了一种基于优势的粗糙集平衡规则集成(DRSA-BRE),提出一种探索金融诈骗的技术;CHEN Hui-Ling等[14]将粗糙集和支持向量机结合使用乳腺癌数据,用RS属性约简算法进行特征选择,提高了支持向量机的诊断精度;PAI Ping-Feng等[15]提出了一种混合ST和DAGSVM的模型,利用SRST和HGSVM在分析中的独特优势来预测汇率变动;ZHANG Xiaoyuan等[16]将粗糙集和支持向量机结合建立一种分类器,分析诊断HGU的振动故障,描述故障与其症状之间的复杂映射;李村合等[17]使用不等距超平面距离改进原始的标准模糊支持向量机,通过计算样本距离得到模糊隶属度函数来改善样本分布不均和噪声数据导致的分类准确率下降问题。
粗糙集对原始数据集进行属性约简。支持向量机(support vector machine,简称SVM)模型能够将复杂的高维非线性问题映射到线性空间,解决了高维非线性小样本问题,同时SVM模型在优化过程中收敛速度快、泛化能力强;因此,SVM的特点恰好和粗糙集互补,将其相互结合用于个人信用评估是非常必要的,为预防个人银行借贷风险提供新的解决方法和思路[18-19]。
1 相关理论
1.1 粗糙集

知识表达系统的数据以关系表的形式表示。关系表的行对应要研究的对象,列对应对象的属性,对象的信息是通过指定对象的各属性值来表达。容易看出,一个属性对应一个等价关系,一个表可以看作是定义的一族等价关系,即知识库[20]。
定义2假定R是论域U上的关系划分,B是对任意属性的子集,这里有B⊆R,假设IND(B)是一个不可分辨的二元关系,则有如下关系
IND(B)={(x,y)|(x,y)∈U2,
∨b∈B(b(x)=b(y))}
(1)
定义3设知识表达系统S=〈U,R,V,f〉,令X⊆U,B是X上的不可分辨关系,那么根据不可分辨关系B将X的下、上近似集定义如下
(2)
∧Yi∩X≠∅)}
(3)
其中U|IND(B)={X|(X⊆U∧∀x∀y∀b(b(x)=b(y)))} 为不可分辨关系B对论域U的划分,同时也称属于X的论域U的基本集合。根据X的下、上近似值概念,定义如下
(4)
(5)
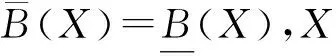
定义4定义决策表S=(U,C∪D),其中属性C∩D=∅,令∅⊂X⊆C,∅⊂Y⊆D,U/Y≠U/δ={U}(这里,δ是全体划分)。若有X0⊆X满足:
①SX0(Y)=SX(Y),即决策属性∅⊂Y⊆D关于条件属性∅⊂X⊆C的支持子集等于决策属性Y⊆D关于条件属性X0⊆X的支持子集。
②SX(Y)⊃XX′(Y),若X′⊂X0⊆X。
按照上述描述,总能找到X的一个极小子集X0,即称X0是X的一个约简。空集∅的约简为∅。
定义5属性相似度[21]在一个知识表达系统S=〈U,C∪D,V,f〉中,C是条件属性集,D是决策属性,那么它们的相似度为
(6)
其中{c}可以是一个条件属性或者几个条件属性的集合。相似度代表2个属性之间或者2个属性集之间的相关程度,如果相似度的值越大,就代表2个属性之间或者2个属性集之间的相关程度越高;若2个条件属性之间的相关程度比与决策属性间的相关度高,则2个条件属性间的冗余性比较大。属性ci与属性cj的相似度为
(7)
当s=1时,2个属性可以相互替代;当s=0时,2个属性之间相互独立,没有任何关系。
1.2 基于相似度的属性约简算法
属性约简算法[21]基本思想:前提是在不改变决策表相似度的情况下,得到属性的约简。如果2个条件属性间的相似度大于它们与决策属性间的相似度,那么2个条件属性间的冗余比较大,则将它们中相似度较小的一个条件属性放入冗余属性集,将其他的条件属性集继续与决策属性集计算相似度,若相似度不变,则删除该条件属性,反之则保留。
1.3 支持向量机
支持向量机[18-19]是一类按监督学习方式对数据进行二元分类的广义线性分类器。假设训练样本为{(x1,y1),(x2,y2),…,(xn,yn)},其中yi∈{-1,1}, (i=1,2,3,…,n),SVM利用样本空间中的超平面将类别进行区分(图1)。
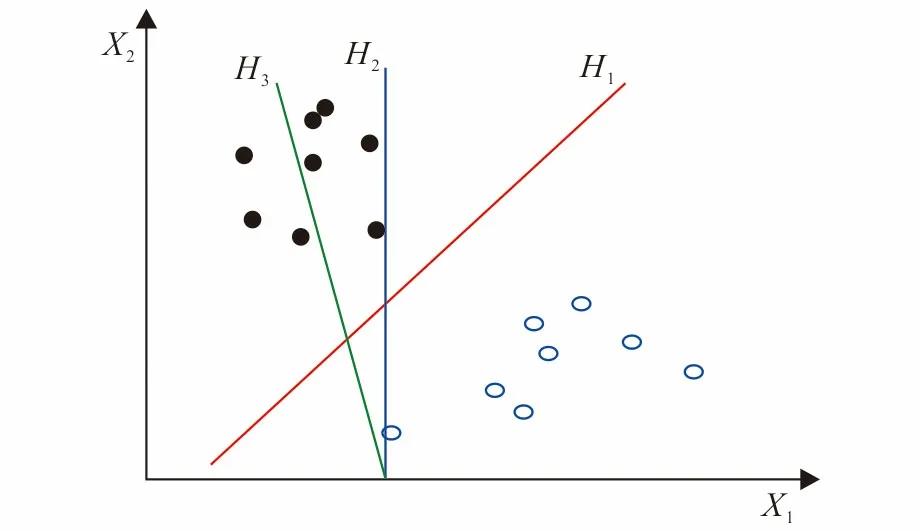
图1 存在多个划分超平面将两类训练样本分开Fig.1 Multiple partition hyperplanes separating the two types of training samples
图1可以直观地看出直线H1完美地将实心点和空心点分为2类。位于不同训练样本正中间,称为超平面。接下来根据训练样本集计算最佳超平面(记为W)的方程,即W的方程表示为
wTx+b=0
(8)
其中,W的方向由法向量w=(w1,w2,…,wn)决定,原点与超平面的距离记为b。知道w和b之后,可以得到超平面W,此时划分超平面可以记作(w,b),任意一点与(w,b)的距离可以记作
(9)
假设划分超平面可以将训练样本集进行正确地分类。
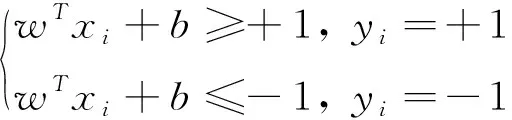
(10)
图1中平面上的几个点使公式(10)成立,这些点被称为支持向量。2个类别都有支持向量,2个类别中的支持向量到超平面W的距离之和为
(11)
称为间隔,如图2。
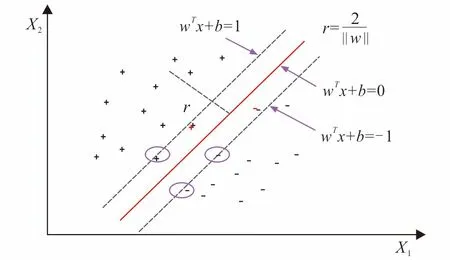
图2 支持向量与间隔Fig.2 Support vector and interval
根据以上描述,目标函数可以被表现,得到目标函数最优解集后就可以找到最佳超平面W

(i=1,2,…,n)
(12)
为了解出w和b的估计值,只需要将‖w‖2最小化
(i=1,2,…,n)
(13)
公式(13)是支持向量的基本形式,简称为SVM。如果能求出目标函数的最优解,就可得到满足条件的划分超平面。
利用SVM分类的前提条件是训练样本空间为线性可分;但在实际工作中部分数据比较复杂,要使这些数据满足要求,就需要借助一个核函数,将样本集映射到高维空间,映射以后满足了线性可分,就找到一个划分超平面对样本进行分类。核函数有线性核函数(Linear)、多项式核函数(Poly)、高斯核函数(RBF)等,其公式分别如下:
(14)
多项式核函数:K(xi,x)=(xixT)d, (d≥0)
(15)
高斯核函数:K(xi,x)=exp(-γ|xi-x|2)
(16)
核函数还可以通过函数组合得到,例如:若k1和k2为核函数,则对于λ1和λ2其线性组合
λ1k1+λ2k2
(17)
2 利用粗糙集和支持向量机的银行借贷风险预测模型
2.1 构建模型
将粗糙集的属性约简和支持向量机的分类各自优势综合,提出了一种属性相似度的约简算法与不同核函数的支持向量机相结合的银行借贷风险预测模型。其基本思路是根据银行借贷的特点和影响因素,借助某银行的部分实例数据,用相似度的启发式属性约简算法,对数据实现降维,同时降低了支持向量机模型的复杂度和计算量。最后用构建预测模型对属性约简后的测试样本进行分类和借贷预测分析。预测模型流程图如图3。
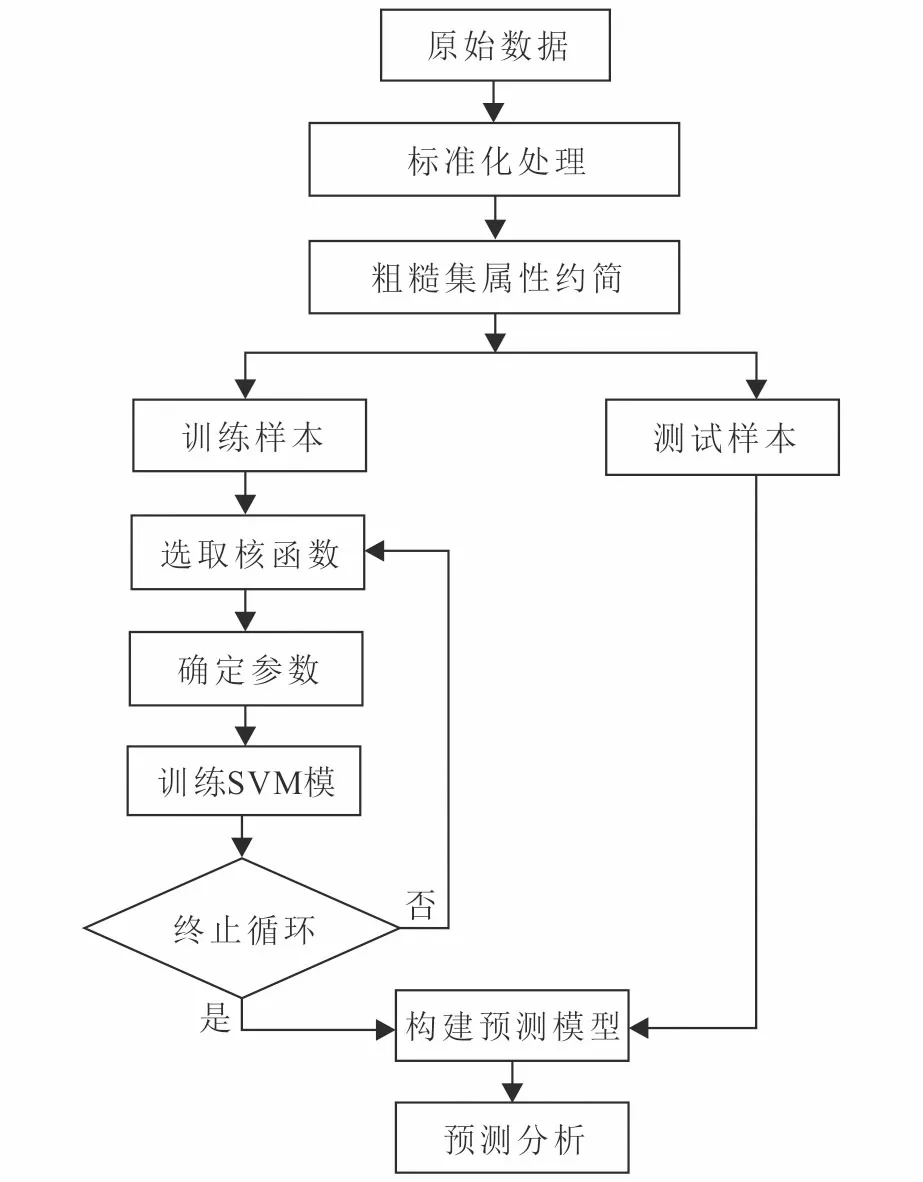
图3 预测模型流程图Fig.3 Flow chart of prediction model
2.2 模型描述
利用粗糙集和支持向量机的银行借贷风险预测模型:
输入:个人信息数据表。
输出:银行是否同意借贷。
步骤1:将原始数据集进行整理,删除那些缺失值和异常值太多的样本。
步骤2:用属性相似度的约简算法删除那些冗余性过高的属性。
①计算各个属性与决策属性的相似度。
②根据相似度大小进行降序排序。
③完成遍历条件属性与决策属性间的相似度判断,去掉冗余属性。
④找到最小属性约简,进行步骤3。
步骤3:建立不同核函数的SVM模型。
①选择公式(14)~(16)的不同核函数,确定核函数的参数。
②将训练样本映射到高维空间。
③用SVM在样本特征空间中找出2类样本间的最优超分类平面。
④得到代表各样本特征的支持向量集。
⑤形成判断类别的判断函数。
⑥建立稳定的SVM模型。
⑦将3种核函数都采用之后结束此步骤。
步骤4:对模型预测结果进行分析。
2.3 影响因素分析
一般认为,银行借贷有2个基本条件:一是还贷能力,申请借贷的个人是否具有还贷能力,调查其现在拥有的资产情况,以及以后发展是否具有上升的潜力;二是信用情况,是调查其过去的借贷信息,落实其是否有过违约,违约次数、违约严重程度。因此银行借贷与否与申请借贷人的还贷能力和信用情况有关。
3 实验结果及分析
文中用外国某银行用户信用数据集进行实证研究,通过建立不同的模型得到的结果进行分析比较,得出最后结论。
3.1 数据预处理
初始获取的数据集中有1 136个样本,每条数据含有24个变量。前23个输入变量描述用户信息特征,最后一个输出变量描述银行借贷情况,“0”表示拒绝借贷,“1”表示同意借贷。其中有8个变量为数值型数据,14个变量为分类型数据。变量描述如表1。

表1 数据集中的变量描述Table 1 Variable description in data set
所获取的数据往往存在各种各样的问题,例如数据丢失、异常值等,会影响后续实验。因此对数据集先进行手动预处理,删除那些属性值丢失和异常值太多的数据。该数据集中有11个样本的变量的属性值缺失太多,作为无效数据舍去。因此,经过前期处理后得到的实际样本数为1 125条。本文将预处理后的样本数据根据十折交叉验证[22]随机划分为两部分,其中90%作为训练集训练模型,剩下10%作为测试集测试模型的效果。
3.2 实验结果分析
3.2.1 属性约简
输入变量较多,推测条件变量中可能有冗余变量,不利于模型的训练预测,反而增加了训练模型时的复杂性,因此需要先进行属性约简,剔除冗余性比较高的变量。
通过属性约简算法,对24个变量进行属性约简,结果剩22个变量。可以判定在条件属性中,有2个属性与其他属性相似程度过高,删除之后对决策属性也无影响。根据属性约简算法输出的结果,被删除的变量为最高学历与出生日期。对照原始数据集,可以看出最高学历与教育水平相似度较高,出生日期与年龄相似度较高,而最高学历较为规范,出生日期较为复杂,有比较大的冗余性,被删除。
3.2.2 不同核函数分类效果对比
由于数据集所含的样本比较多,属性约简后的数据集按照十折交叉验证的方法将数据集分为10等份,其中9份作为训练集,1份作为测试集,对信贷问题进行分类最后计算10次预测准确率的平均值,得到该核函数分类的准确率。使用Python程序实现算法,选取带有不同参数不同核函数的支持向量机进行分类,对预测结果进行对比,根据预测准确率分析其适用银行借贷的程度。实验选用线性核函数、高斯核函数、多项式核函数以及组合核函数(线性核函数+多项式核函数)等几种常用核函数。其中核函数中有一个非常重要的参数,实验中P(惩罚系数)均采用默认值,改变各个核函数中最主要的一个参数进行对比。
a.线性核函数分类结果及分析
线性核函数支持向量机(LN-SVM)模型预测的准确率为77.04%,运行时间为4.429 s。
线性核函数唯一的参数是P,其默认值为1,P值越大越好,但可能会过拟合,线性核函数比较简单,迅速知道哪些特征是最重要的。实验结果是线性核函数支持向量机模型的预测准确率不高,运行时间较快,分析得出其原因是线性核函数主要适用于线性可分数据。
b.高斯核函数分类效果及分析
高斯核函数支持向量机(RBF-SVM)模型不同参数预测的准确率以及运行时间如表2。
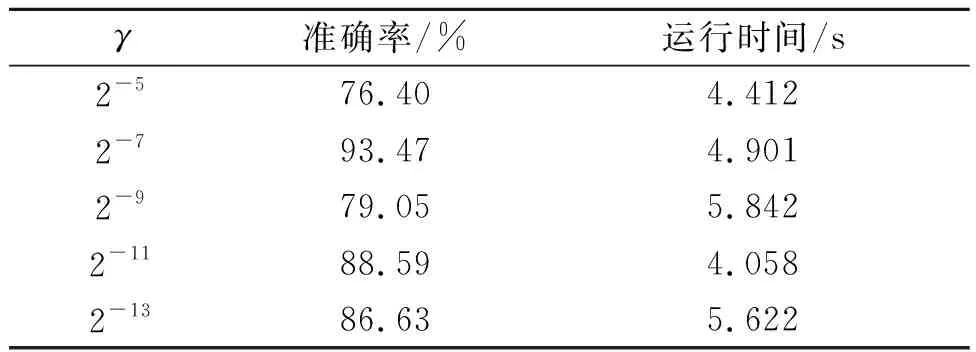
表2 高斯核函数SVM模型运行结果Table 2 Operation results of SVM model of Gaussian kernel function
高斯核函数支持向量机模型不同参数预测运行时间折线如图4。
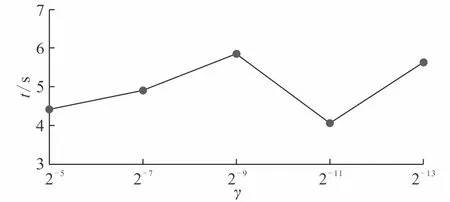
图4 高斯核函数运行时间折线图Fig.4 Graph showing Gaussian kernel function operation time
高斯核函数是一种局部性强的核函数,其将一个样本映射到一个更高维的空间内,采用向量作为自变量,局部性强、参数较少、有比较好的抗干扰能力,是核函数中应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数[19]。其参数γ值越小,分类界面越连续;γ值越大,分类界面越分散,分类效果越好。其函数作用范围随着参数γ的减小而减弱。由折线图看,高斯核函数采用不同参数的情况下,运行时间差异不大,运行时间也不长。从实验结果看,当γ=2-7时,分类准确率最高,运行时间与其他参数运行时间相比也不算最长,因此是比较理想的实验结果。
c.多项式核函数分类效果及分析
多项式核函数支持向量机(PL-SVM)模型不同参数预测的准确率以及运行时间如表3。
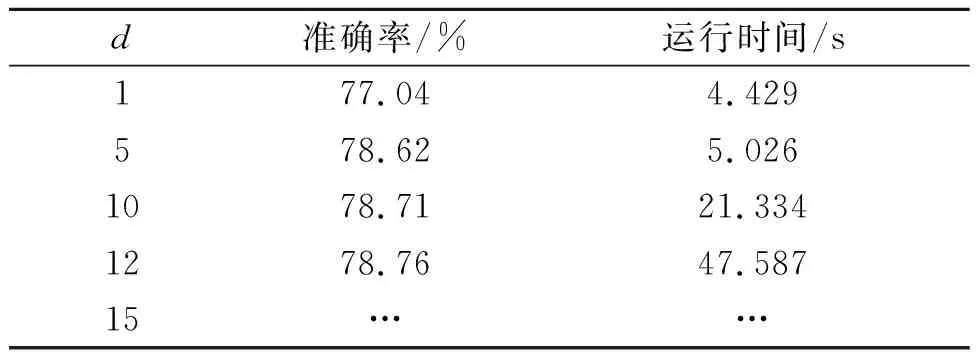
表3 多项式核函数SVM模型运行结果Table 3 Operation results of SVM model of polynomial kernel function
多项式核函数支持向量机模型不同参数预测运行时间折线如图5。

图5 多项式核函数运行时间折线图Fig.5 Graph showing polynomial kernel function operation time
多项式核函数实现将低维的输入空间映射到高维的特征空间;但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算[19]。实现将低维的输入空间映射到高维的特征空间,参数d越大,映射的维度越高,计算量就会越大,学习复杂性越高。实验结果,当参数d=1时,多项式核函数退化为线性核函数,与线性核函数的实验结果相同。随着参数d的增大,多项式的次数越来越多,复杂性变高,实验的运行时间越来越长;当d=15时,运行时间过长,已经无法得到实验结果。
d.组合核函数(线性核函数+多项式核函数)分类效果及分析
组合核函数(线性核函数+多项式核函数)支持向量机(COM-SVM)模型预测的准确率为79.13%,运行时间为10.652 s。
组合核函数是将默认参数的线性核函数和多项式核函数组合在一起作为新的核函数被支持向量机使用,具有线性核函数和多项式核函数的共同特点。实验结果是分类预测准确率稍好于单个的核函数,运行时间较长。
采用ROC曲线[23]对不同核函数下的评价模型进行检验。ROC曲线越陡,说明预测结果的准确性就越高。图6就是在训练模型和分类预测完成后根据分类结果使用Python中的sklearn库画出来的4种核函数下的SVM模型的成功率曲线。从ROC曲线看出:LN-SVM模型的成功率为64.9%;PL-SVM模型的成功率为71.4%;RBF-SVM模型的成功率为81.4%;COM-SVM模型的成功率为79.6%(图6)。
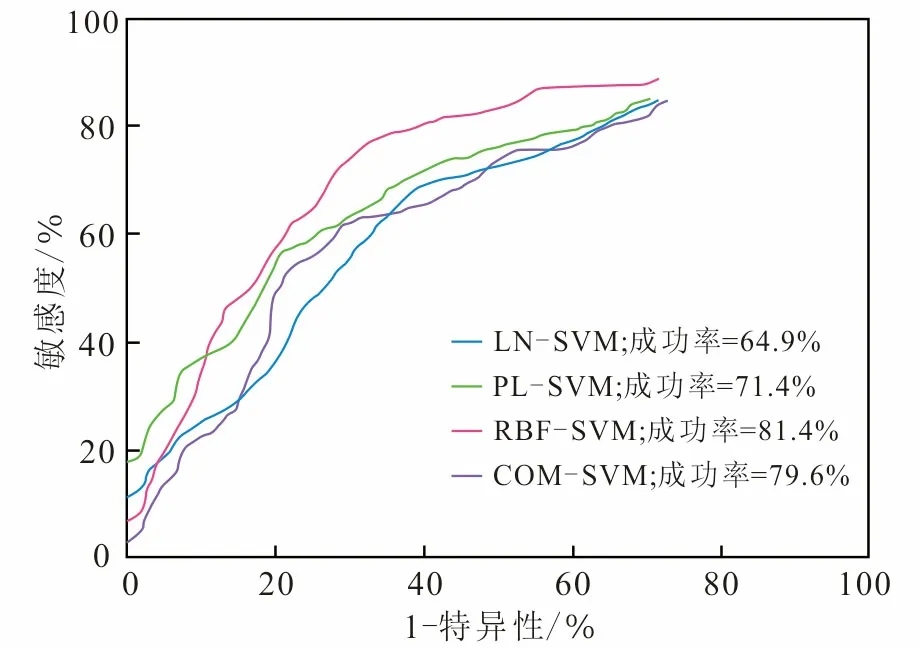
图6 不同核函数SVM模型的ROC曲线图Fig.6 ROC curve of SVM model of different kernel functions
综上所述,选取不同的核函数的支持向量机效果各异,从分类准确率、运行时间以及ROC曲线3个方面看,实验结果最好的是用高斯核函数的支持向量机。但是实验结果只能说明高斯核函数适合于本实验用的数据集,不能表明高斯核函数优于其他核函数。从其他文章[24]看,高斯核函数适用于特征较少、样本量适中的数据集,也正是本次实验使用数据集的特征。
4 结 论
构建银行信贷风险预测模型,用相似度属性约简算法对数据集进行属性约简,再用支持向量机构建分类模型,对测试集进行分类,改变支持向量机的核函数以及各自的参数,通过实验进行对比分析。实验结果,构建预测模型可有效地预测银行借贷风险,为银行借贷提供依据,也可作为理论研究基础,具有较高的实际应用价值。但是,实验中找不到核函数的最优参数使得预测准确率达到最高,结合优化方法寻找最优参数有待进一步研究。
