城市环境下基于双目视觉的移动目标检测
2022-04-01程顺生覃驭楚吕炎杰
程顺生,覃驭楚,吕炎杰
(1.中国科学院空天信息创新研究院 遥感科学国家重点实验室,北京 100101;2.中国科学院大学 电子与通信工程学院,北京 101408)
随着城市空间和内部结构的快速发展,其环境的精细观测和构建描绘成为城市化进程中的重要研究课题[1]。GPS、IMU和激光雷达等车载传感器技术的发展以及海量传感器数据的积累,为城市观测提供了丰富的位置、状态和几何角度等静态环境信息,帮助还原了城市的细部环境[2]。Google Map街景数据等大尺度的静态环境信息能实现城市的视觉还原和数字化构建,为复杂的城市规划和科学决策提供支撑数据[3-4]。然而,车载传感器在采集城市空间信息时无法避免行人、车辆等移动目标的遮挡,导致局部信息缺失,进而影响城市细部环境的整体绘制。因此,分离城市静态背景和移动目标成为城市数字化重构的关键问题。
移动目标检测是在动态视频中检测是否有物体相对于地面发生移动的图像处理技术。其目标是分离图像中的前景和背景信息,被广泛应用于智能交通、安全监控、医学和机器人视觉导航等领域[5]。传统移动目标检测方法包括帧差法、光流法和背景减法等,其中帧差法通过计算相邻帧或背景图与当前帧之间的差别来检测移动目标,但只适用于背景为静态的数据;光流法通过求解并投射目标运动过程来跟踪目标变化,但计算复杂且对噪声敏感;背景减法将当前帧与背景图像进行差分,得到运动目标区域,但需要构建一幅不含运动目标的背景底图,无法适应和更新场景变化。传统图像领域学者通过人工提取HOG[6]等图像局部不变特征进行目标检测,但仅适用于小样本检测。同时,传统移动检测只完成了图像坐标系统的位置检测,当数据源更换时,相应的图像坐标系也会发生改变,难以衡量检测效果的好坏。因此,传统检测策略难以适应海量累积的多源传感器数据和动态变化的城市街景环境。
基于深度学习的目标检测框架[7]包括卷积神经网络(CNN)[8]、R-CNN[9]、Fast R-CNN[10]、Faster R-CNN[11]、YOLO[12]和SSD[13]等,为海量样本和多类别目标检测提供了方法思路。基于深度学习的目标检测主要利用基于候选框的目标检测框架,即在预测阶段首先生成包含目标概率较大的区域,再对候选框进行特征提取、分类和回归,如R-CNN采用SS方法生成检测框,利用CNN对每个候选区域提取特征,产生过多的冗余运算;SPP-Net通过ROI Pooling层使检测网络可接收任意大小的图片输入;Fast R-CNN直接将图片归一化成CNN需要的格式,卷积层不进行候选区的特征提取,仅在最后一个池化层加入候选区域坐标信息进行特征提取,并在全连接层中实现目标分类与检测框回归微调的统一。经典的目标检测方法精度均较高,但检测框非常耗时,而Faster R-CNN在Fast R-CNN的基础上采用区域推荐网络RPN代替SS算法进行检测框的推荐,极大提升了检测框的生成速度,实现了端到端的目标检测。
同步定位与制图技术(SLAM)为移动目标检测提供了新的解决方案,从未知环境的未知位置出发,在传感器移动过程中通过重复观测到的地图特征定位当前位置和姿态[14],被快速应用于诸多城市空间重建任务中[15-16]。SLAM领域中的VINS Fusion[17]提供了一种基于通用优化的里程计估计框架,能针对多源传感器数据解算目标位姿,实现图像坐标到真实三维空间精准的坐标映射。因此,移动目标检测可划分为目标检测和位姿解算两个任务需求:①利用CNN网络检测目标,并计算图像中的位置;②利用SLAM框架将图像坐标同步定位到世界坐标系,并比较目标在城市地图不同时刻的位置,判断目标是否发生移动。然而,由于数据量巨大且位姿解算过程运算很复杂,检测时间通常较长,运算效率较低,制约了大量级移动目标检测任务。
哈希图像匹配算法可用于降低目标样本的冗余度,优化检测过程[18],对每张图片生成指纹字符串,计算汉明距离并比较不同图像的指纹信息差异性。汉明距离越小,图片之间的差异越小,图片越相似。常用的哈希算法包括均值哈希算法(aHash)、差值哈希算法(dHash)和感知哈希算法(pHash)。pHash[19]采用离散余弦变换分解图片频率,并获得左上角最低频率的8×8矩阵;再计算该矩阵像素与像素均值的哈希值,并对比该指纹。与前两种哈希算法相比,pHash的精度更高,可用于优化控制过程。
本文的创新性在于:①实现了图像坐标到真实坐标的位置映射,并基于真实三维空间坐标识别不同帧之间目标的移动状况;②通过优化控制过程,对检测效率进行改进。通过优化对城市真实坐标的计算和效率,数字化复杂环境的构建更快速准确且应用性更强。
1 技术路线与数据来源
1.1 技术路线
城市车载传感器的相机移动导致图像背景发生动态变化,移动目标与背景的相对运动无法通过图像像素的变化判断。本文结合深度神经网络和SLAM框架,在多源传感器数据集上构建了一套移动目标检测流程。其主要任务框架如图1所示。
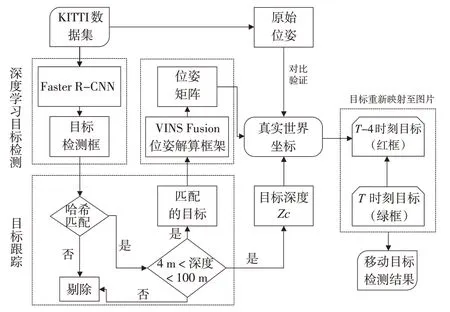
图1 移动目标检测任务流程图
1)目标检测。利用深度神经网络Faster R-CNN提取检测目标(车辆、行人等),实现城市静态场景与运动目标分离。
2)图像块匹配。为提升移动目标检测效率,利用哈希算法匹配图像帧之间的图像块,仅解算匹配成功的目标空间位置。
3)位姿解算。利用惯性导航系统VINS-Fusion计算框架解算相机位姿,构建图像坐标到真实世界坐标系的映射函数即图像外部参数,进而判断目标是否在世界坐标系中发生移动。图像与真实世界的映射关系为:

式中,zc为双目相机解算的目标检测框深度;u和v为目标框在图像上的行、列位置;K为相机内部参数;R和T为位姿数据中的旋转量和平移量,是图像的外部参数;xw、yw、zw为真实世界中的三维坐标。因此真实世界坐标矩阵可表示为目标深度、目标在图像上的位置矩阵、相机内参和位姿矩阵的映射函数。
1.2 数据来源
本文以KITTI数据集[20]为实验数据,包括市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多包含15辆车和30个行人,还有各种程度的遮挡与截断。目标检测数据集由7 481个训练图像和7 519个测试图像组成,共包括80 256个带标签的对象,数据量为12.6 GB。位姿图计算数据采用KITTI原始数据,包含21个序列数据,且每个序列都提供了同步校准后的数据、标定数据。
2 实验内容
2.1 目标检测
网络设置卷积层、区域候选网络、池化层和分类器,其中卷积层采用13个卷积、13个线性整流和4个池化操作自动提取图像特征,并用作区域候选网络和全连接层的输入参数;区域候选网络以图像特征为输入,用于生成候选区域,通过SoftMax判断该区域是否有目标,再通过边框回归函数进行边框位置修正,从而输出位置更精确的候选区域;池化层收集输入的特征图和候选区域,将其综合后提取到候选区域特征图中,再输入后续连接层判断类别;分类器利用候选区域特征图计算判断该区域的目标类别,同时采用边框回归函数进行位置修正。
本文利用Faster R-CNN对KITTI目标检测数据集进行训练,其中一张图片的目标检测结果如图2所示,绿色框线标记了相应的道路车辆和识别精度,可以看出,平均IoU大于0.83,总体损失小于0.60,能识别序列数据中92.1%的目标,较准确地识别车辆和行人。然后,将图像每一帧对应的图像块掩膜出来作为待匹配的图像块。

图2 Faster R-CNN目标检测结果
2.2 图像块匹配
对于Faster R-CNN检测得到的不同帧的目标,利用pHash算法计算的相似度对两帧目标进行匹配,仅对匹配成功的目标进行检测。这样不仅可以确保移动目标的一致性,排除大小差异较大的不同目标,而且能有效减少位姿解算过程的冗余工作量,提升检测效率。
2.3 位姿解算
在制图和定位研究中需要根据不同传感器类型选择不同的计算框架。局部传感器(相机、IMU[21]、激光雷达等)能在没有GPS信号的区域,实现良好的局部定位和制图效果,但缺乏全局约束和不同坐标系下的方差累积,限制了算法在大数据量复杂场景中的应用。全局传感器(GPS、气压计和磁力计等)可提供统一坐标系下的全局观测,但全局数据通常不平滑且存在噪声,传输速率也较低。因此,针对多传感器融合数据的算法在提升系统鲁棒性方面具有更突出的优势,但这种基于滤波器的方法也存在不同坐标系转换以及传感器时间同步等局限。
VINS Fusion[17'22]采用了基于优化的全局坐标系位姿估计框架,可支持多个全局传感器,局部传感器用于局部估计,采用现有的VO/VIO方法[23-24]来产生局部位姿;再将全局传感器转换为位姿图中的统一因子,与局部估计一起输入到全局位姿图中构造优化问题;最后生成局部精确且全局感知的六自由度位姿。该框架能融合计算双目图像、IMU、GPS等传感器,采用的IMU预积分算法能根据当前状态进行调整,有效避免重复积分,优化了计算速度。
2.4 检测目标深度优化
检测目标在图片位置中均对应各自的影像深度,深度的范围将影响位姿解算的精度。较远处目标由于物体边缘特性不明显,检测框的位置在图像上具有较大的不确定性;近处目标在不同帧相机拍摄过程中会离开小车相机的拍摄范围,导致前一帧图像上的车辆在下一帧图像上不完整或移出图像之外,目标的重心丢失。因此,对于这两种情形,本文根据目标在图像上的深度设置阈值进行剔除,从而减少在真实坐标映射过程中的误差影响。
3 实验结果
3.1 VINS Fusion位姿解算结果
VINS Fusion较好地融合了摄像机、IMU、GPS等传感器,实现了局部准确和全局感知的位姿估计。利用VINS Fusion对KITTI序列进行位姿解算的结果如图3所示,图3a为XZ轴平面的轨迹投影,图3b为位姿在X、Y、Z轴上的误差,图3c为俯仰角(rool)、滚转角(pitch)、偏航角(yaw)的误差。除了Y轴天顶方向不需要累计误差的约束外,VINS Fusion能比较准确地解算出位姿结果,并在X和Z轴方向与真实位姿的误差较小。

图3 VINS Fusion位姿解算结果
3.2 移动目标检测结果
通过目标检测、图像匹配和位姿解算,能将传感器图像识别的潜在移动目标位置解算到真实世界坐标系中,从而获得每一帧图像潜在目标的三维世界坐标。为了在图像上直观显示目标移动的结果,需要将真实世界坐标位置反算回图像位置,并标注为不同颜色。
移动目标检测结果如图4所示,其中红色方框为图像T-4时刻目标的坐标位置,绿色方框为当前T时刻目标的坐标位置。贴合地面的方框底部距离差,能反映目标在两帧拍摄时间内的移动深度。若根据真实坐标反算的检测框底边重合,则表示该物体在真实世界中未发生移动,为静止目标;若检测框底部出现偏差,则表示该物体在真实世界发生移动,即为移动目标。
为了验证基于SLAM算法的位姿检测效果,本文利用根据KITTI数据集原始位姿数据获得的移动目标检测结果进行验证。图4a为基于KITTI原始位姿数据解算的目标移动检测结果,对于路边静止停靠的汽车(如0号目标框),方框底部依然存在明显的偏差;图4b为基于SLAM VINS位姿解算的目标移动检测结果,静止的车辆底边框能较好地重合在一起,但对于马路中间移动的摩托车来说则并未丢失移动信息。对比验证结果表明,本文提出的移动目标检测方法在复杂城市街道场景下具有明显的适用性和准确性

图4 移动目标检测结果
4 结语
为了在复杂城市背景环境中有效检测出移动目标,帮助城市数字化信息提取和场景复现,本文结合深度神经网络和SLAM技术,提出了一种能适应多源传感器影像的移动目标检测技术。该技术首先利用Faster R-CNN网络对潜在移动目标进行目标识别,再利用VINS Fusion计算框架解算得到目标在三维世界中的真实坐标。为了提高检测效率,在检测过程中进行了优化控制,首先利用pHash算法去除不同帧图像中大小形状差异较大的目标,然后对目标深度进行阈值控制,进而控制检测精度。本文提出的基于SLAM的移动目标检测方法能在多源传感器影像上准确提取移动目标,同时基于真实坐标的目标位置解算也能适应不同车载传感器图像坐标系统,避免了由相机坐标不同导致的误差和方差漂移累积,有效实现了移动车载相机拍摄城市复杂街道场景下的移动目标检测。
