基于百度指数的EEMD-BES-ELM旅游客流量预测
2022-03-31王云龙彭颖
王云龙 彭颖
(重庆师范大学数学科学学院 重庆市 401331)
旅游市场各季度波动明显,建立旅游客流量预测模型,有利于旅游目的地省份的防控政策调整,优化景点资源配置。传统模型依赖于历史数据,数据滞后性高,可获取性差,难以满足预测要求。
网络搜索数据对提高预测精度发挥重要作用,但网络数据本身对预测结果带来的影响,“大数据傲慢”现象说明了利用网络搜索数据对预测结果会产生高估或低估问题,使网络数据对预测精度提升不明显,针对该问题,本文基于网络搜索数据,利用EEMD 对原始数据进行降噪处理,提升原始数据的可靠性,并使用秃鹰算法优化极限学习机对重庆国内旅游人数进行预测。
1 模型介绍
1.1 集合经验模态分解
集合经验模态分解[1,2](EEMD)是在经验模态分解(EMD)的基础上改进的降噪方法,该方法加入不同幅值的白噪声改变原始信号极值点进行辅助降噪,经平均值处理,叠加值在不同区域形成完整映射,克服EMD 存在的混叠现象,有效抑制分解结果中噪声的影响,在处理原始序列信号分解上优势明显。EEMD 具体分解步骤如下:
(1)在原始信号x(t)中加入正态白噪声序列n(t),得到
式中xn(t)为加入噪声后的序列。
根据EEMD 分解原理,任何序列信号可由本征模态函数IMF 组成,即:
式中r(t)为趋势项,代表平均趋势,对序列进行EMD分解得到IMF。
(2)计算xn(t)的所有极值点并拟合出上、下包络线u(t)和l(t)。
(3)计算均值包络、和中间函数。
(4)判断中间函数h(t)是否满足IMF 定义,满足则令c(t)=h(t),并将c(t)作为第1 阶IMF 输出,若不满足则令xm(t)=h(t),重复以上步骤,直至满足IMF 定义。
IMF 的严格定义为任何时刻m(t)为零,在实际应用中无法实现,故一般定义为满足以下条件:
式中,N为原始序列长度,k为分解次数,ε为筛选门限,通常取0.2-0.3。
(5)没得到一阶IMF,就从原始序列xm(t)除去它,直至原始序列r(t)为单调序列或常值序列。
1.2 秃鹰搜索算法
秃鹰搜索算法[3](bald eagle search,BES)具有较强的全局搜索能力,该算法综合粒子群算法和鲸鱼算法的优点,可有效解决各类复杂数值优化问题。
秃鹰在捕食时选定一个搜索空间,在该空间进行飞行,当发现合适猎物后,秃鹰改变飞行高度,快速向下俯冲,捕获猎物。BES 算法模拟秃鹰捕食的三个阶段,选择区域、搜索猎物、俯冲捕猎。
算法原理:
(1)初始化种群数量N,每只位置为P=(p1,p2,...,pD),该位置的优劣由适应函数fit(x)得出。
(2)选择阶段,秃鹰会飞行至当前最优个体附近,与只有个体的距离由全体平均位置确定。
式中,为当前个体选择的新位置,为[1.5,2]内的常数,是满足[0,1]均匀分布的随机数。为当前种群的平均位置,为当前个体的位置。若新位置优于原位置,则更新位置,否则留在原位置。
(3)搜索阶段,秃鹰围绕当前位置,以阿基米德螺旋线的方式搜索寻找最佳俯冲位置。采用极坐标方程进行位置更新,如下公式所示。
式中与为螺旋方程的极角与极径;a 为取值[5,10]中的常数,R 为取值[0.5,2]的常数,rand 为服从[0,1]均匀分布的随机数。秃鹰围绕自身飞行,飞行距离由自身与群体中心距离和自身与下一只秃鹰的距离决定。若搜索的新位置优于原位置,更新位置,否则留在原地。
(4)俯冲捕猎:秃鹰从搜索空间最佳位置快速飞向猎物,同时其他种群个体向最佳位置移动并飞向猎物,该阶段在最优位置以螺线方式搜索,具体公式如下:
式中C1 和C2 为秃鹰向最佳中心位置的运动强度,取值为(1,2)。
1.3 极限学习机
极限学习机[4](ELM)是黄广斌提出的单层前馈神经网络,传统的前馈神经网络基于梯度下降法优化网络结构,导致学习率低,易陷入局部最优或过拟合,且在不同应用场景需手动调参。ELM 随机选择隐藏节点及隐层权重和误差,通过解析计算确定输出层权值,相较于传统前馈神经网络泛化能力强,学习能力快。如图1所示。

图1:ELM 拓扑结构图
设输入层为m,隐含层为n,输出层节点为l,g(x)为激活函数,有N个样本极限学习机公式如下:
将N个样本带入公式可表达为:
式中,H表示隐含层输出矩阵,β表示输出层权值矩阵,Y表示样本目标值矩阵。在ELM 模型中输入权值和偏差随机给定,隐含层输出矩阵H变成确定的矩阵,根据求解最小二乘问题确定输出层权值矩阵:
式中,H+为H的Moore-Penrose 广义逆,在ELM 中常用正交法计算H+:
1.4 BES-ELM组合模型优化过程
ELM 相较于BP 神经网络在预测精度上有所提升,但仍存在参数任意选取的问题,从而影响预测精度,使用BES算法对ELM 模型网络参数 和 两个参数进行全局寻优,可弥补ELM 的缺点提升预测精度,优化预测过程。如图2所示。
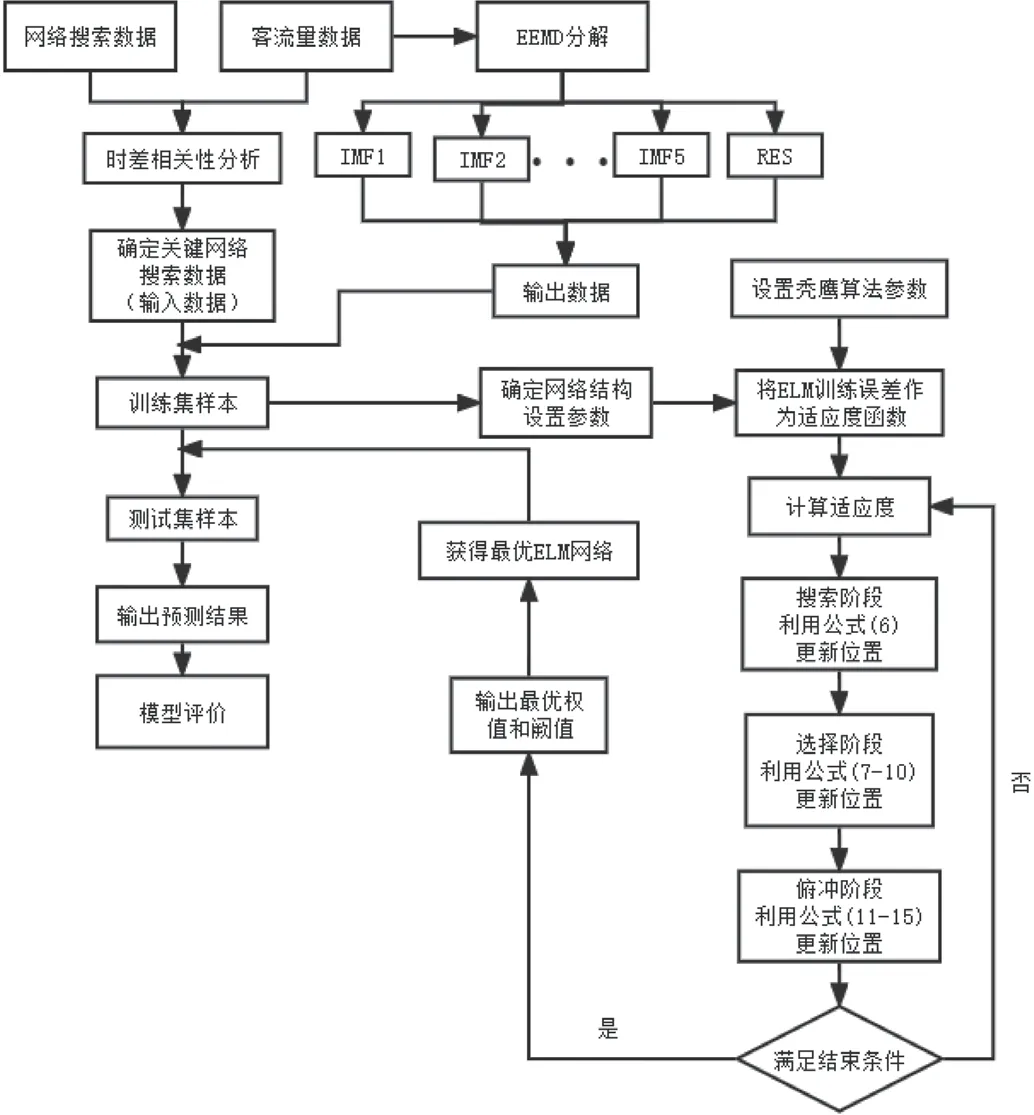
图2:BES-ELM 模型流程图
2 实证研究
2.1 数据收集
本文采用的重庆旅游客流量来源于wind 数据库,数据时间范围为2011年1月-2019年12月。网络搜索数据来源于百度指数[5-9],根据旅游决策的主要影响因素,旅游目的地景区特征、目的地美食、交通、住宿基本因素确立5 个初始关键词,并通过挖掘工具、对初始关键词长尾词、需求图谱进行处理确立了个拓展关键词,如表1所示。选取2011年1月1日至2019年年12月31日的日网络搜索数据,并分别对不同终端(电脑端:PSV,移动端:MSV)选取的关键词日平均搜索量进行处理,计算关键词的月平均搜索数据。

表1:百度指数搜索关键词
2.2 数据处理
对不同终端初始关键词数据累加可知。受限于移动端网络,2011年1月-2012年8月PC 端网络搜索量大于移动端,随着4G 网络的普及,移动端搜索逐渐便利,成为百度搜索的主要趋势,在2014年1月后移动端搜索量急速增长。如图3所示。

图3:PC 端与移动端百度指数趋势
因此,本文以2013年12月为划分点,分别对PC 端和移动端百度关键词指数序列与重庆国内旅游人数序列进行时差相关性分析,分别计算时间划分点不同终端下每个关键词与重庆旅游人数序列0-7 阶领先相关系数。
通过时差相关性分析可知,2013年12月前4G 网络未普及,作旅游决策时,人们倾向于使用PC 端进行旅游目的地信息收集,移动端因发展不成熟,在此过程中起到一定的辅助作用。2014年随着移动网络发展,PC 端百度指数数据序列与重庆国内旅游人数序列相关性降低,失去代表游客搜索行为的能力。移动网络成为游客搜索的主流。本文选取相关系数大于0.5 的关键词作为输入数据。
2.3 EEMD分解降噪
客流量数据和百度指数数据具有非线性的特点,且百度指数关键词选取较主观,尚未形成成熟的选取模型,考虑到客流量数据选取对模型性能的影响,本文使用EEMD 算法,对客流量数据进行EEMD 分解。经过分解后分别可得到5条IMF 和1 条残差。如图4所示。

图4:重庆国内旅游人数EEMD 分解图
2.4 评价指标
为评价预测结果的有效性,本文选取平均绝对误差(MAE)、平均绝对百分比误差(MAPE)和均方根误差(RMSE)对实验预测结果进行评估,其误差计算表公式如下:
2.5 结果分析
对各模型进行10 次测算,得到训练集和测试集平均评价指标如表2,通过评价指标的对比可知,BES-ELM 模型在MAE、SMAPE、RMSE 的数值均小于基准模型。
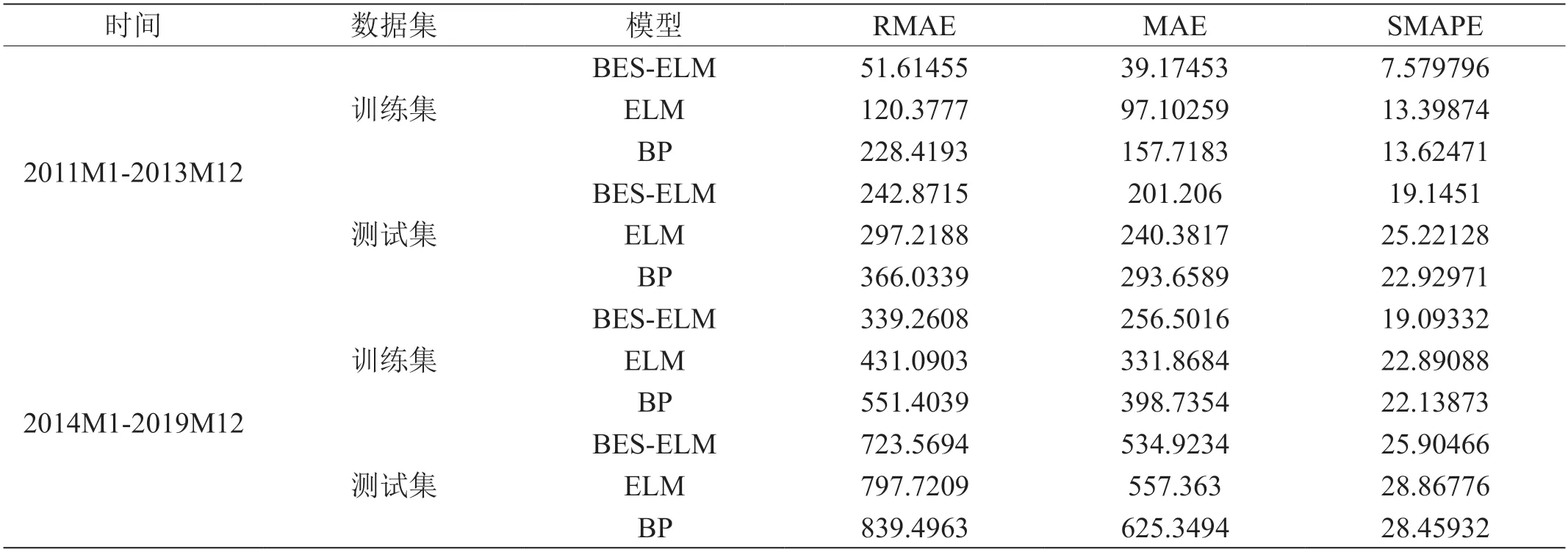
表2:训练集和测试机平均评价指标
以2014年-2019年的数据为例对不同IMF 训练集预测数据进行加总合成得BES-ELM 模型的拟合效果与预测效果。如图5所示。

图5:BES-ELM 模型训练集与测试集效果图
通过实证分析可知,测试集峰值数据预测效果较差。笔者分析存在以下原因,首先,在网络关键词选取上无科学的方法,选取较主观,本文虽对数据进行去噪,但选取关键词相关系数阈值为0.5,可能影响结果;其二,受数据限制,训练集较少,影响效果。
3 展望
本文以重庆国内旅游客流量为基础,分别采用BESELM 模型、BP 模型、ELM 模型进行测算。结果表明,BES-ELM 模型预测精度较高,在很大程度上可反映重庆旅游客流情况。较传统的前馈神经网络BP 模型更适合用于预测客流量此类时间序列数据。
因网络搜索数据本身的复杂性,深度学习模型比传统模型更适用于客流预测,拟合能力更强,预测准确更高。但数据来源限制,本文仅考虑百度网络搜索数据,考虑的外部因素较少,若能获取重庆酒店预订量、至重庆的机票、动车票销售量等因素,同时考虑爬取各旅游平台的相关数据,筛选出更多主要因素带入模型,会提升模型预测精度,取得更好的预测效果。
