基于多粒度认知的命名实体识别方法
2022-03-30李攀锋陈樱珏钟泠韵
李攀锋, 陈樱珏, 钟泠韵, 林 锋
(四川大学计算机学院, 成都 610065)
1 引 言
命名实体识别是自然语言处理领域的核心任务,其目的是从文本序列数据中识别出表示命名实体的成分,并给出其具体的实体类别.命名实体识别是将非结构化文本转化为结构化信息的关键技术,可以为上层的自然语言处理任务提供基础支撑,如知识图谱、搜索引擎、推荐系统等[1].
目前,命名实体识别通常被当作序列标注任务[2],常用的方法有基于词典和规则的模式匹配方法、基于统计机器学习的方法、基于深度学习的方法.基于模式匹配方法如University of Sheffield NLP在2012年开发的GATE框架,有着明确清晰的NER规范[3].模式匹配方法准确率高,但需要领域专家设计众多的实体抽取规则,且领域词典需要定期维护.基于统计机器学习的方法如隐马尔科夫模型、最大熵模型、条件随机场等.统计机器学习的方法受限于高质量的大规模标注语料库以及对普适性的特征模板的需要.深度学习的方法如BiLSTM、BiLSTM+CRF等[4-7].深度学习的方法引入了基于字向量或词向量的特征表示[8],无需进行额外的特征工程,在中文命名实体识别领域越发占据主导地位.
实际的场景中,某些特定领域由于样本匮乏或者受限于标注成本,可使用的训练数据较少,基于常规深度学习的方法对字词特征向量的学习效果欠佳.为此,出现了很多基于多任务学习的命名实体识别研究,如联合分词、词性标注、语义角色标注等任务[9].这些方法通过与其他相关任务的联合学习,对字词特征向量的捕捉效果有一定的提升.但需要额外进行辅助任务数据标注,在标注成本有限的场景下并不适用.
针对这个问题,本文从多粒度认知理论出发,以深度学习中经典的BiLSTM及机器学习中传统的CRF为基础模型,引入了命名实体识别与实体数量预测联合学习模式,提出了一种基于多粒度认知(MGC)的命名实体识别方法,在不产生额外标注成本的前提下,增强字嵌入特征表示,提高命名实体识别效果.
RNN(Recurrent Neural Networks) 模型由美国认知科学家Elman对Jordan Network进行了简化而提出[10],被广泛应用于自然语言处理领域,如词性标注、语义角色标注等序列问题[11].RNN网络在传统神经网络基础上增加了隐层间的信息传递机制,使得序列的历史信息可以保留并为后续时间步提供支持.常规的RNN网络结构如图1所示.
RNN网络在设计之初是为了学习长期的序列依赖性,但是实践证明,在处理长序列数据时,RNN容易产生梯度消失问题.为了解决这个问题, Hochreiter等提出了长短期记忆网络(LSTM), 用于改进传统的循环神经网络模型[12].LSTM单元由输入门、遗忘门和输出门3个模块组成,如图2所示.

图1 RNN结构图Fig.1 Structure diagram of RNN

图2 LSTM单元结构图
图2中,遗忘门决定了上一时刻的单元状态Ct-1有多少保留到当前时刻单元状态Ct;输入门决定了当前时刻的输入Xt有多少保留到了当前时刻细胞状态Ct;输出门控制单元状态Ct有多少传递到当前时刻输出Ht.LSTM单元更新过程如下.
(1) 计算遗忘门值ft.
ft=σ(Wf·[ht-1,xt]+bf)
(1)
(2) 计算输入门值it.
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3) 计算输出门值Ot.
Ot=σ(Wo·[ht-1,xt]+bo)
(3)
(4)
(5) 更新当前细胞状态Ct.
(5)
(6) 计算当前隐层输出ht.
ht=Ot*tanh(Ct)
(6)
其中,ht-1为上一时刻的输出;Ct-1为上一时刻的细胞状态;Xt为当前时刻的输入;σ、tanh为激活函数;Wf、Wi、Wo、Wc为权重矩阵[13].
针对序列处理问题,基于LSTM单元的网络模型如图3所示.

图3 LSTM网络结构图Fig.3 Structure diagram of LSTM networks
在自然语言处理领域,单向LSTM能够捕捉和记忆前驱语义信息,但无法获取后向语义信息.因此,在目前的自然语言处理相关任务上,通常使用双向的LSTM网络[14],即BiLSTM,网络结构如图4所示.

图4 BiLSTM网络结构图
条件随机场模型(CRF)由Lafferty等于2001年提出,是一种判别式概率无向图模型,是一个标准的序列标注算法[15].最常用的是线性链条件随机场,它接收一个观测序列x,输出目标序列y,如图5所示.

图5 线性链条件随机场示意图Fig.5 Diagram of linear-CRF
设P(Y|X)是线性链条件随机场,X为观测序列变量,Y为目标序列变量,用P(y|x)表示给定X的观测值x的情况下,随机变量Y取值为y的条件概率.
对于观测序列x的任意位置xi(i=1,2,3,…,n),都有K1个局部特征函数和K2个节点特征函数,共有K=K1+K2个特征函数,特征函数取值{0,1},即满足特征和不满足特征.其中,局部特征函数是关于yi-1、yi、x、i的函数,用tk表示;节点特征函数是关于yi、x、i的函数,用sk表示.其中,yi-1表示当前节点的前驱节点的目标值;yi表示当前节点的目标值[16].用hk统一表示特征函数.
(7)
其中,A={1,2,…,K1};B={K1+r};r=1, 2,…,K2.
则对于整个序列,定义全局特征函数如下.
(8)
同时定义特征函数权重系数wk如下式.
(9)
则有
(10)
其中,Z(x)为规范化因子,如下式.
(11)
将特征函数fk与权重系数wk张量化表示为
w=(w1,w2,…,wK)T
(12)
F(y,x)=(f1(y,x),…,fK(y,x))T
(13)
则P(Y|X)的内积形式为
(14)
3.1 多粒度认知
认知科学是揭示人类智能和行为的一门学科,重点研究神经系统和脑机制中,信息的表达、处理和转化过程[17].随着人工智能的发展,认知计算逐渐出现.认知计算是对新一代智能系统特点的概括,基于认知计算的智能系统具备人类的某些认知能力, 能够出色完成对数据的发现、理解、推理和决策等特定认知任务,帮助决策者从不同类型的数据中揭示潜在意义,以实现不同程度的感知、记忆、学习和其他认知活动.
人的认知往往是多层次、多视角的,依托人类处理问题时所表现出全局观和近似求解能力,多粒度认知成为了解决人工智能问题的重要手段[18].在语义理解任务中,基于篇章粒度与句子粒度实现了语义融合;在分词任务中,基于长短词层次粒度增强了分词效果.
在命名实体识别任务中,本质是对字粒度的文字序列进行标签标注,考虑到人类在对文本认知时,综合考虑文本整体,对文本有一定的全局认知.基于此,本文提出了一种结合字粒度与句子全局粒度的命名实体识别方法.在字粒度层面,模型解决命名实体识别任务,在句子全局粒度层面,模型解决命名实体数量预测任务.两个粒度认知任务联合优化,以提高命名实体识别效果.
本文提出的基于多粒度认知的命名实体识别方法,以BiLSTM+CRF为基本的命名实体识别模型,实现字粒度的序列标记任务,同时采用BiLSTM结合注意力机制,实现句子全局粒度的命名实体数量预测任务,网络结构如图6所示.
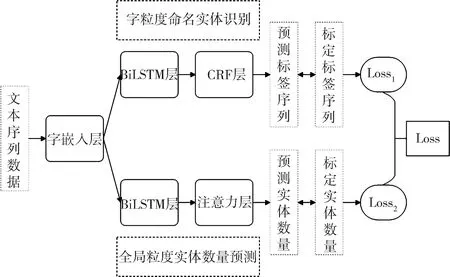
图6 MGC_NER网络结构图Fig.6 Structure diagram of MGC_NER networks
下面对图6中模型的各个部分进行说明.
(1) 字嵌入层.模型的输入为中文句子,通过预处理构建字表,将句子转化为高维的one-hot矩阵,传入字嵌入层.字嵌入层将one-hot矩阵映射为压缩的低维的字嵌入矩阵.
(2) 命名实体识别BiLSTM层.接收字嵌入后的文本矩阵,通过捕捉前后向语义信息,初步获取命名实体识别任务的标签预测概率.
(3) CRF层.以命名实体识别BiLSTM层的输出为发射矩阵,通过状态转移矩阵进一步修正命名实体识别任务的标签预测概率.
(4) 实体数量预测BiLSTM层.接收字嵌入后的文本矩阵,通过捕捉前后向语义信息,进一步获取句子的语义特征.
(5) 注意力层.接收实体数量预测BiLSTM层的输出特征矩阵,通过注意力机制获取句子全局的重要特征信息,最终预测出该句子中包含的实体数量.
总体上,字粒度的命名实体识别任务与句子全局粒度的实体数量预测任务共享字嵌入层,通过两个粒度认知任务的损失函数共同优化.
3.3 MGC_NER模型优化目标
本文提出的MGC_NER模型有两部分优化目标.
(1) 命名实体识别的优化Loss采取log似然如下式.
(15)
其中,Prealpath为在给定观测序列x的条件下,真实的目标序列yrealpath的概率;P1~Pn为在给定观测序列x的条件下,预测目标序列yn的概率.
(2) 实体数量预测的优化Loss采取交叉熵损失如下式.
(16)

为实现两个粒度联合优化,通过系数d(超参数,通过验证集调整)将Loss1与Loss2联合,得到最终模型优化目标.
Loss=Loss1+d*Loss2
(17)
4.1 实验数据
本文选取新浪财经简历数据集和人民日报数据集两个公共数据集,自行构建了涉案财物领域法律数据集,并对数据集规模进行了限制.其中,新浪财经简历数据集与涉案财物领域法律数据集为特定领域数据集,人民日报数据集为跨领域数据集.通过多领域数据集以验证本文方法的有效性.
本文的命名实体识别任务采取BIO三位序列标注法,各数据集规模及标签类别划分如表1所示.

表1 数据集信息表
本文按照5∶1∶1的比例随机划分了训练集、验证集和测试集.在各个数据集的训练集上实体数量分布情况如图7~图9所示.

图7 新浪财经数据集实体数量分布图

图8 人民日报数据集实体数量分布图
由图7~图9可知,在新浪财经简历数据集、人民日报数据集和涉案财物处置领域法律数据集上,各种实体数量类型下的句子分布差异较大,在实体数量预测任务中将产生数据偏斜问题.针对这个问题,本文通过区间划分,将实体数量区间预测作为实体数量预测的目标,避免了类别不平衡问题.

图9 涉案财物数据集实体数量分布图
4.2 实验设计
本文在BiLSTM+CRF命名实体识别模型上引入基于多粒度认知的联合优化方法(MGC_NER模型).为进一步说明本文提出的多粒度认知机制的有效性,在单纯的BiLSTM模型上引入基于多粒度认知的联合优化方法构建了对比实验.并在随机初始化字向量和载入预训练字向量两种情况下进行实验,总体设计如图10所示.

图10 实验总体设计图Fig.10 The overall design of the experiment
其中,NER组模型为常规的命名实体识别模型,引入了MGC机制的BiLSTM+CRF模型(MGC_NER)为本文提出的最终模型.特别的,引入了MGC机制的BiLSTM模型用于证明MGC机制的有效性.各组实验均在相同情况下进行,字嵌入维度300维, BiLSTM隐层维度256维,注意力隐层维度100维,实体数量预测区间数为5,粒度联合系数d为0.3.
4.3 实验结果
本文依照图10的实验结构进行了实验,评价指标采取在实体识别严格比对下的准确率(Precision)、召回率(Recall)和F1值.计算公式如下.
(18)
(19)
(20)
其中,Pcorrect表示预测正确的实体数量;Pall表示预测结果中实体数量的总和;Call表示标定数据中实体数量总和.实验结果如表2~表4所示.
其中,粗体数据为引入了本文提出的多粒度机制方法的实验数据.对比各组实验结果可知,本文提出的方法在保持基础模型的准确率不降低或基本不降低的情况下,能够显著提升召回率.总体上,在各个数据集的各项实验上,本文所提方法的F1值都高于对比方法的F1值,验证了本文方法的有效性.

表2 新浪财经数据集实验结果
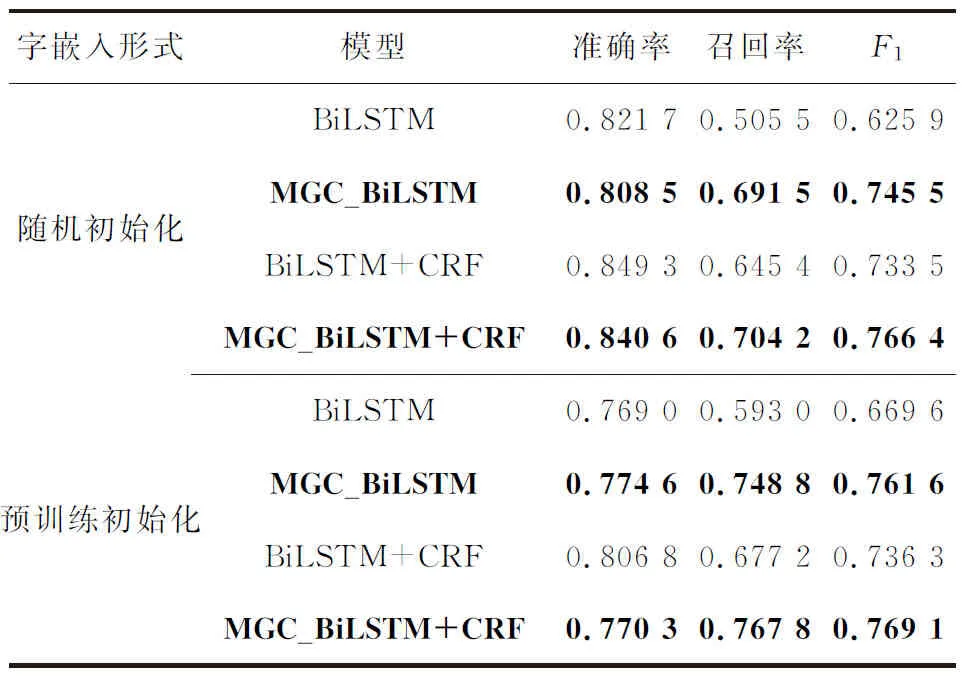
表3 人民日报数据集实验结果

表4 涉案财物数据集实验结果
此外,实验数据还表明了如下3种情况.
(1) 通过对比随机初始化字向量与预训练字向量的实验结果,说明在命名实体识别领域,预训练字向量不一定能够起到积极的效果,甚至可能起到负面作用.本文认为,预训练的字向量更侧重于语义信息,在命名实体识别任务上,信息量冗杂的预训练向量干扰了任务的进行.
(2) 通过对比BiLSTM和BiLSTM+CRF实验结果,说明CRF对于命名实体识别任务有一定的辅助作用.本文认为,由于CRF模型在训练过程中学习到了相邻字标签之间的约束关系,从而降低了命名实体识别的错误率.
(3) 在人民日报数据集上,本文的方法对比基础模型准确率有所下降,本文认为,与人民日报数据集自身特点有关.从图8可知,该数据集上实体数量为零的句子较多,为了维持区间均衡,将实体数量为零的句子与其他句子划分为一个区间,导致了实体数量预测任务中对数量为零的句子造成了干扰,从而间接影响了该数据集上命名实体识别的准确率.
5 结 论
本文提出了一种基于多粒度认知的命名实体识别方法,从多粒度认知理论出发,基于BiLSTM和CRF构建了命名实体识别与实体数量预测联合模型,通过共同优化字嵌入表达,提高句子语义信息捕捉能力.本文在3个数据集上进行了多组实验,实验表明,引入多粒度认知机制有助于改善命名实体识别效果,证明了本文方法的有效性.后续将对实体数量预测中实体数量区间的划分进行深入研究,细化区间划分,有望进一步提升模型效果.
