基于Python的高职院校教务系统BI画像研究
2022-03-26林德智张柳
林德智,张柳
(北海职业学校,广西 北海 536009)
0 引言
随着大数据技术和应用不断创新突破,人们渐渐认识到大数据对于产业的升级和经济结构调整的重要支撑作用。对于教育行业来说,大数据的引入推动了教育教学方式的改革,以数字化手段实现教育信息化。根据中共中央国务院印发的《深化新时代教育评价改革总体方案》的要求,学校要“创新评价工具,利用人工智能、大数据等现代信息籍数,探索开展学生各年级学习情况全过程纵向评价、德智体美劳全要素横向评价”。各高校积极响应了国家的号召,利用大数据技术不断全面深化教育改革,包括教育教学、教育管理中信息化系统的建设[1]。Picciano在他的论文中表示,大数据能帮助导师分析学生的学习情况,了解他们是否能掌握所学知识[2]。与此同时,大数据的发展推动了教师个体的发展[3]。为适当今信息化教学的新时代,教育工作者需要通过大数据了解学生学习情况,动态调整专业和课程的设置,以建立健全人才培养体系[4]。但是,在实际运用信息系统处理学生的数据的时候,往往因平台之间存在信息孤岛,这些数据得不到充分挖掘和利用。因此,本文旨在利用大数据分析技术分析整合从教务系统中提取一学年的学生学习成绩为例,通过使用python进行分析,评估学生对知识的掌握情况,进而引导各专业团队针对大数据分析的结果提升专业和课程建设的成效。
1 数据获取
1.1 数据来源
本文通过该校的教务系统获取了全校学生2019-2020学年第二学期和2020-2021学年第一学期的大数据。这部分数据存储在不同的excel表格内,不仅涵盖了教务系统本身提供的学生各项期末成绩,还包括了从其他业务系统获取的数据,例如从学工系统获取的综合测评成绩;从到梦空间获取的第二课堂积分;从易班获取的易班网薪经验值;从图书馆获取的借阅记录等。
这些数据种类繁多,单独分析并不能全面评价一个学生的在校表现情况,容易造成“一刀切”“唯分数论”的教育教学局面。因此要秉承尊重学生个体差异的理念,注重“德智体美劳”的育人方向。从全局的高度利用大数据分析技术汇总、清洗和分析学生的各项数据,朝着个性化教育的方向思考[5]。
1.2 整合数据集
工欲善其事必先利其器。由于教务系统中存储的信息来自各个业务系统,因此导出来的原始数据的大小、类型和结构可能不尽相同,需要数据整合来对不同类型的数据进行整合。Python的Pandas函数库中提供了Join函数,依据共有数据把两个或者多个数据表格组合起来。通过pd.join指令,以学生的名字和学号作为索引,可将专业课成绩、综合测评成绩和第二课堂成绩等等合并到一个表格中。此外,本文按照分类思想将每个学生都看作一个独立的对象并制作行索引标签,而其他信息等作为他们的属性,通过loc方法获取指定对象所在的行,即可查阅对应的属性。
2 构建学生画像
2.1 数据清洗
通过调用Python的Pandas函数库先对原始数据中的缺省数据进行处理。因为教务系统中学生个人信息的数据采自数据中心,而数据中心的数据是人为录入的,期间难免会出现漏填或错填的情况。再加上学生在校期间可能会停学、休学和入伍,而数据中心是按学年为周期采集数据的,这样一来就可能出现这部分数据栏为空的情况。这部分数据并不能反映客观情况,故我们应该把它们当缺省值处理。使用Pandas中的np.NaN 表示缺省值,通过pd.isnull()和pd.notnull()来判断原始数据中存在缺省的字段,再通过筛选删除掉对应行。
2.2 设置数据模型和算法
早在20世纪60年代,国外许多大型教育机构(PISA、TIMSS)就开始采用多层线性模型、回归模型、因子分析以及Apriori算法在内的多种方式研究影响学生成绩的因素。杨琴在2016年通过建立时空特征模型来分析采集自校园WIFI的学生行为数据[6]。因此为了最终实现可视化,首先要为标准化的数据设置数据模型和算法。逻辑回归(Logistic Regression)是机械学习中的一种分类模型,是解决二分类问题的利器。以学生的易班网薪经验值为例,设定默认输出的概率值为0.5,假设我们设定大于80分的概率值为属于A(1)这个类别的概率值。现在有一个样本的输入到逻辑回归的输出结果是0.55,那么这个概率超过0.5,那么我们可以预测这个样本就是A(1)类别。反之,如果输出的值为0.3,那么预测结果我们可以归为B(0)类别。
线性回归算法(Linear Regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。线性回归算法有两种,一种是线性关系,另一种是非线性关系。我们用线性回归算法处理专业课(PEC和PCC)。
PEC=a×ER+b×UP
PCC=a×ER+b×UP
其中,ER为考试成绩Examination Result,UP为平时成绩Usual Performance,由此我们通过设置权重a和b即可建立特征值ER和UP与目标值PEC和PCC的关系。
聚类算法是一种典型的无监督学习算法,主要用于将类似的样本自动归类到一个类别中。在聚类算法中根据样本之间的相似性,将样本划分到不同类别中,对于不同的相似度计算,会得到不同结果,常用的相似度计算方法有欧式距离算法。在这里我们主要通过聚类算法实现数据的筛选排序。使用聚类算法可以筛选出经过缺省处理过的数据进行删除;另外还可以实现将信息按学年、学院、专业等等字段分类显示,方便使用Matplotlib获取对应字段进行可视化[7]。
2.2 可视化
数据可视化是指直观展现数据,它是数据处理过程的一部分。借助数据可视化,能更直观地理解数据,有助于解释数据中隐藏的模式,做分析时可以利用这些模式选择模型。Matplotlib是Python变成语言的开源绘图库。它是Python可视化软件包中最突出的,使用最广泛的工具,可以创建主流的可视化类型-折线图、散点图、直方图、条形图、误差图、饼图、箱型图等。通过Matplotlib得到专业必修课和专业选修课的正态分布图。
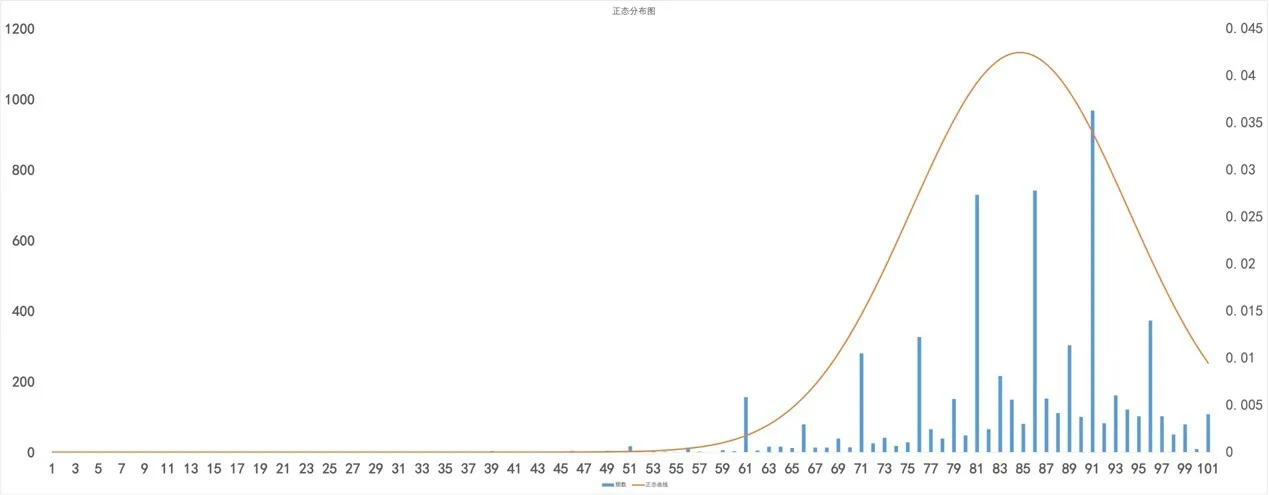
图1 专业必修课的正态分布图
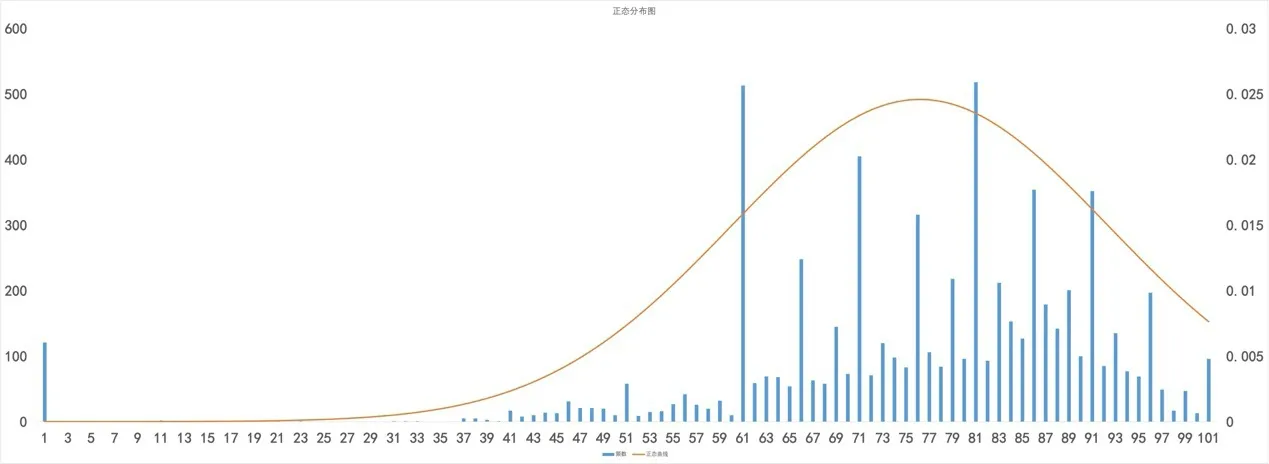
图2 专业选修课的正态分布图
3 结语
本文对教务系统的数据处理和可视化进行了的研究和探索,初步验证了方法的可行性和可操作性,往后的工作包括利用主成分、相关性、聚类、关联规则挖掘、多元线性回归等分析方法优化可视化图表,进一步提升此项目对专业课程建设和教学管理的指导性作用。
